BS4
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库, 它能够通过你喜欢的转换器实现惯用的文档导航、查找、修改文档的方 式。
Beautiful Soup 4
官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
帮助手册:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
一、安装Beautiful Soup
命令行:pip3 install beautifulsoup4
或者:
File--》setting--》Project:xxx--》右侧 “+” ==》查找 Bs4 ==》左下角
install ==>apply ==>确定
二、安装解析器lxml (第三方的解析器,推荐用lxml,速度快,文档容错能 力强)
pip3 install lxml
三、使用
创建bs对象
# 打开本地HTML文件的方式来创建对象
soup = BeautifulSoup(open('xxxx.html')) # 创建Beautiful Sou对象
#打开网上在线HTML文件
url = 'https://jobs.51job.com/ruanjian/'
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text, 'lxml')
其中
soup = BeautifulSoup(html, "lxml") # 指定lxml解析器
或者
soup = BeautifulSoup(url, 'html.parser') # 内置默认html解析器
格式化输出soup对象内容
print(soup.prettify())
四大对象:
Beautiful Soup将复杂HTML文档转换成一个不复杂的树形结构,
每个节点都是Python对象,所有对象可以归纳为4种:
Tag 标签 bs4.element.Tag
NavigableString 字符串 bs4.element.NavigableString BeautifulSoup 整体页面 bs4.BeautifulSoup
Comment 注释 bs4.element.Comment


Tag:是HTML 中的一个个标签

上面的 title a 等等 HTML 标签加上里面包括的内容就是 Tag。
一般标签都是成对出现,结尾的有 /标示
下面用 Beautiful Soup 来方便地获取 Tags print soup.title

对于 Tag,它有两个重要的属性,是 name 和 attrs
print soup.name
print soup.head.name
#[document]
#head
soup 对象本身比较特殊,它的 name 即为 [document],
对于其他内部标签,输出的值便为标签本身的名称。
print soup.p.attrs
#{'class': ['title'], 'name': 'dromouse'}
如果我们想要单独获取某个属性,可以这样,例如我们获取它的 class 叫什 么
print soup.p['class']
#['title']
还可以这样,利用get方法,传入属性的名称,二者是等价的
print soup.p.get('class')
#['title']
NavigableString: ##可以遍历的字符串
既然我们已经得到了标签的内容,那么问题来了,
我们要想获取标签内部的文字怎么办呢?很简单,用 .string 即可,
例如:
print soup.p.string
#The Dormouse's story
检查一下它的类型
print type(soup.p.string)
![]()
BeautifulSoup ##表示的是一个文档的全部内容.大部分时候,
可以把它当作 Tag 对象,是一个特殊的 Tag
获取它的类型,名称,以及属性
print type(soup.name)
![]()
print soup.name
#[document]
print soup.attrs
#{} 空字典
Comment ##特殊类型的 NavigableString 对象,输出的内容仍然不包 括注释符号
print soup.a
print soup.a.string
print type(soup.a.string)
运行结果如下


其他操作: 遍历文档树 以head标签为例
![]()
# .content 属性可以将tag的子节点以列表的方式输出
print(soup.head.contents)
![]()
print(soup.head.contents[1]) # 获取列表中某一元素,0 是页面上的换行符 号,1才是真值
# .children 返回的是一个list生成器对象
print(soup.head.children)
# .string 返回最里面的内容
print(soup.head.string)
print(soup.title.string) # 两个输出是一样的
搜索文档树 ==》find_all() select()
find_all(name, attrs, recursive, text, **kwargs)
# find用法相同,只返回一个
# name参数可以查找所有名字为 name 的tag,可以是字符串,正则表达 式,列表
print(soup.find_all('a'))
print(soup.find_all(["a" , "b"]))
#recursive 递归查找相同名称标签
# keyword参数直接匹配属性对应的值
print(soup.find_all(class_= "sister"))
# 因为class在python中已经有了,为了防止冲突,所以是class_
print(soup.find_all(id= 'link2'))
# text参数搜索文档中的字符串内容,与name参数的可选值一样,text参数 接受字符串,正则表达式,列表
print(soup.find_all(text= "Elsie")) #严格匹配
print(soup.find_all(text=["Tillie" , "Elsie" , "Lacie"])) #找多个
print(soup.find_all(text=re.compile("Dormouse"))) #正则查找
五:使用演练

以实际例子作说明:
1、定义一个html,并使用BeautifulSoup的lxml解析
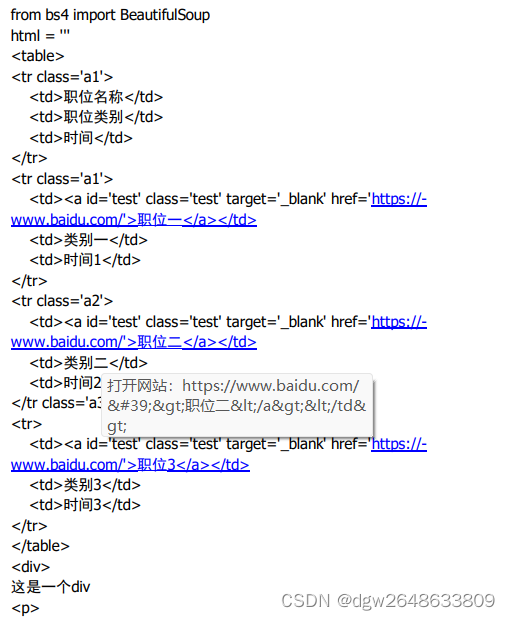

2、获取所有的tr标签
find 返回找到的第一个标签,find_all以list的形式返回找到的所有标签
trs = soup.find_all('tr') # 返回列表
n=1
for i in trs:
print('第{}个tr标签: '.format(n))
print(i)
n+=1
3、获取第二个tr标签
limit 可指定返回的标签数量
trs = soup.find_all('tr' ,limit=2)[1] # 从列表中获取第二个元素,limit 获取 标签个数
print(trs)
4、获取class= 'a1'的tr标签
a.方法一: class_
trs = soup.find_all('tr' ,class_= 'a1')
n=1
for i in trs:
print('第{}个class=''a1''的tr标签:'.format(n))
print(i)
n+=1
b.方法二:attrs 将标签属性放到一个字典中
trs = soup.find_all('tr',attrs={'class':'a1'})
n=1
for i in trs:
print('第{}个class=''a1''的tr标签:'.format(n))
print(i)
n+=1
5、提取所有id= 'test'且class= 'test'的a标签
方法一:class_
alist = soup.find_all('a' ,id= 'test' ,class_= 'test')
n=1
for i in alist:
print('第{}个id= ''test''且class= ''test''的a标签: '.format(n))
print(i)
n+=1
方法二:attrs
alist = soup.find_all('a' ,attrs={'id':'test' , 'class':'test'})
n=1
for i in alist:
print('第{}个id= ''test''且class= ''test''的a标签: '.format(n))
print(i)
n+=1
6、获取所有a标签的href属性
alist = soup.find_all('a')
#方法一:通过下标获取
for a in alist:
href = a['href']
print(href)
#方法二: 通过attrs获取
for a in alist:
href = a.attrs['href']
print(href)
7、获取所有的职位信息(所有文本信息)
string 获取标签下的非标签字符串(值), 返回字符串
注:第一个tr为标题信息,不获取。从第二个tr开始获取。
trs = soup.find_all('tr')[1:]
movies = []
for tr in trs:
move = {}
tds = tr.find_all('td')
move['td1'] = tds[0].string # string 取td的值
move['td2'] = tds[1].string
move['td3'] = tds[2].string
movies.append(move)
print(movies)
8、获取所有非标记性字符
strings 获取标签下的所有非标签字符串, 返回生成器。
trs = soup.find_all('tr')[1:]
for tr in trs:
infos = list(tr.strings) # 获取所有非标记性字符,包含换行、空格
print(infos
9、获取所有非空字符
stripped_strings 获取标签下的所有非标签字符串,并剔除空白字符,返回 生成器。
trs = soup.find_all('tr')[1:]
for tr in trs:
infos = list(tr.stripped_strings) # 获取所有非空字符,不包含换行、空 格
print(infos)
# stripped_strings 获取所有职位信息
trs = soup.find_all('tr')[1:]
movies = []
for tr in trs:
move = {}
infos = list(tr.stripped_strings)
move['职位'] = infos[0]
move['类别'] = infos[1]
move['时间'] = infos[2]
movies.append(move)
print(movies)
10、get_text 获取所有职位信息
get_text 获取标签下的所有非标签字符串,返回字符串格式
trs = soup.find_all('tr')[1]
text = trs.get_text() # 返回字符串格式
print(text)

14、提取所有a标签的href属性
# 方法一:
a = soup.select('a')
for i in a:
print(i['href'])
# 方法二:
a = soup.select('a')
for i in a:
print(i.attrs['href'])










![P5691 [NOI2001] 方程的解数(内附封面)](https://img-blog.csdnimg.cn/3ee4d81d9c3248369ee4d6177e260fab.png)