问题描述
训练模型时,分阶段训练,第二阶段加载第一阶段训练好的模型的参数,接着训练
第一阶段训练,含有代码
if (train_on_gpu):
if torch.cuda.device_count() > 1:
net = nn.DataParallel(net)
net = net.to(device)
第二阶段训练,含有代码
if (train_on_gpu):
if torch.cuda.device_count() > 1:
netT = nn.DataParallel(netT)
netS = nn.DataParallel(netS)
netT = netT.to(device)
netS = netS.to(device)
-----
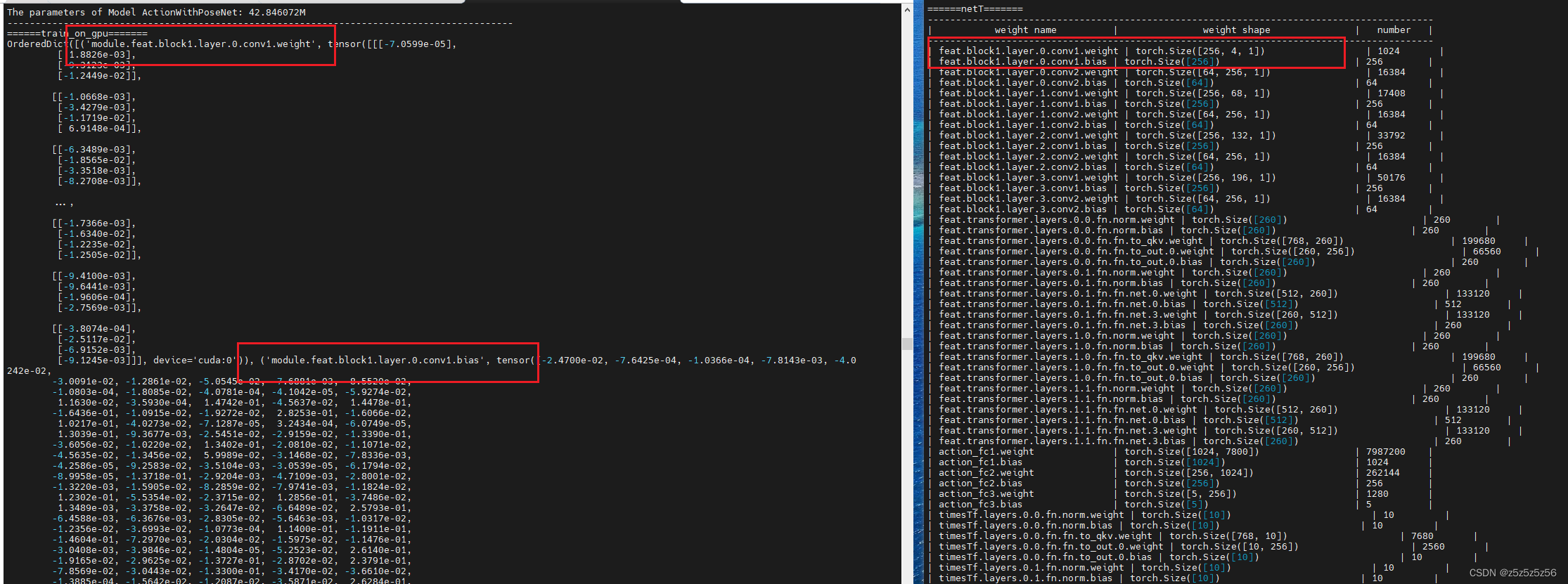
orig_state_dict = torch.load("../models/model.pth")['net']
new_state_dict = OrderedDict()
for k, v in orig_state_dict.items():
name = k.replace('module.', '')
new_state_dict[name] = v
netT.load_state_dict(new_state_dict)
-----
for param in netS.parameters():
param.requires_grad = True
#对源模型 netS 的 pose_fc1 层所有参数都设置为不需要进行反向传播更新。
for param in netS.pose_fc1.parameters():
param.requires_grad = False
结果报错
RuntimeError: Error(s) in loading state_dict for DataParallel: Missing key(s) in state_dict: "module.feat.block1.layer.0.conv1.weight", ...........
解决方案:
注释掉nn.DataParallel()
if (train_on_gpu):
if torch.cuda.device_count() > 1:
pass
#netT = nn.DataParallel(netT)
#netS = nn.DataParallel(netS)
netT = netT.to(device)
netS = netS.to(device)
-----
orig_state_dict = torch.load("../models/model.pth")['net']
new_state_dict = OrderedDict()
for k, v in orig_state_dict.items():
name = k.replace('module.', '')
new_state_dict[name] = v
netT.load_state_dict(new_state_dict)
-----
for param in netS.parameters():
param.requires_grad = True
#对源模型 netS 的 pose_fc1 层所有参数都设置为不需要进行反向传播更新。
for param in netS.pose_fc1.parameters():
param.requires_grad = False
原因分析
可能是模型在第一阶段和第二阶段训练设置不一致导致的问题,比如第一阶段用双卡训练,第二阶段用单卡训练
这时不能第一阶段和第二阶段都用nn.DataParallel()
net加载的网络结构没有"module",而第一阶段保存的模型因为使用了net = nn.DataParallel(net),保存的参数的key有"module",
这个时候如果我们执行 netT.load_state_dict(new_state_dict)
会报错missing keys .....Unexpected key(s) in state_dict: "module.features.......
于是按网络教程加一个False, netT.load_state_dict(new_state_dict,False)
于是就报错题目中的问题了解决AttributeError: ‘DataParallel‘ object has no attribute ‘xxxx‘
在这里实际上第二阶段加载的时候就要把key前面的"module"去掉,才能正确加载模型参数到网络里面,继续训练
另外注释掉nn.DataParallel()即可