1.变量的实现机制
在声明一个变量时,需要指定它的数据类型和变量名,在源代码中它们都用文字来表示,这种文字形式便于人们阅读,计算机CPU无法直接识别。在C++源程序中,之所以要使用变量名,是为了把不同的变量区别开。在运行程序时,C++变量的值都存储在内存中。内存中的每个单元都有一个唯一的 编号,这个编号就是它的地址。不同的内存单元地址互不相同,因此不同名称的变量在运行时占据的内存单元具有互不相同的地址,C++的目标代码就是靠地址来区别不同的变量。
对于下面这段简单的C++代码
int a=1,b=2;
int main()
{
a++;
b++;
return 0;
}
将它编译为可执行文件之后,再反汇编,得到汇编语言代码。程序中的a++和b++两条语句,对应下面的代码(用gcc4.2以及IA-32为目标编译后的反编译结果):
incl 0x80495f8
incl 0x80495fc
反汇编:是指将机器语言代码转换成与之对应的汇编语言代码的过程。由于汇编语言与机器语言的指令具有一一对应的关系,而且汇编语言比机器语言更便于人们理解,所以观察可执行文件反汇编的代码,便于理解程序的工作机制。
汇编语言:汇编语言代码是以指令为单位的,每条指令对应于一条CPU可以直接执行的指令。每条指令都包括操作符和操作数,操作符表示这一条指令的操作类型,上面两条指令的操作符都是incl,用来执行加1的操作。操作数表示这一操作执行的对象,操作数可能是一个或多个,不同的操作符所需要的操作数数量和用途各不相同。上面两条指令的操作数分别是0x80495f8和0x80495fc,它们在这里就是表示执行incl的加1操作的内存地址。
incl 0x80495f8所执行的操作就是将从0x80495f8内存地址开始的4个字节的内容加1。0x80495f8和0x80495fc就是a和b两个变量的首地址,二者之差为4,这是因为它们都在内存中占4个字节,它们在内存中的布局如下图所示,图中清楚地显示了在目标代码中,不同变量是通过它们各自的地址来加以区别的。
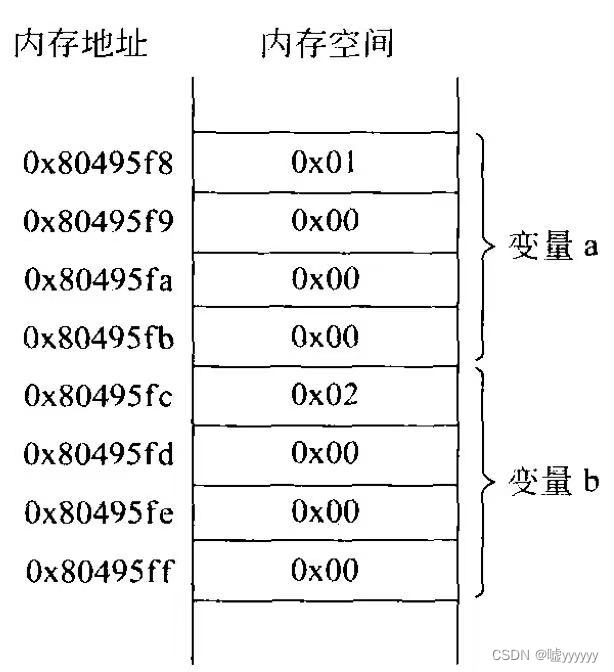
这里0x80495f8和0x80495fc其实并不是内存真实的物理地址,而是一个虚拟地址。
2.位域
各种基本数据类型中,长度最小的char和bool在内存中占据1个字节的空间,但对于某些数据只需要几个二进制位即可保存,例如下面所定义的枚举:
enum GameResult
{
WIN,LOSE,TIE,CANCLE
};
由于它只有4种取值,只需要2个二进制位就可以保存,而一个GameResult类型的变量至少占据1个字节(8个二进制位),在很多编译器中,甚至还会占据更多的空间。单一变量所浪费的空间或许并不显著,但如果在一个类中有多个这样的数据成员,那么它们所浪费的空间积累起来会更大。有一种解决办法是,将类中多个这样的数据成员“打包”,让它们不必从整字节开始,而是可以只占据某些字节的某几位。为了解决这一问题,C++允许在类中声明位域。
位域是一种允许将类中多个数据成员打包,从而使不同成员可以共享相同的字节机制。 在类定义中,位域的定义方式为:
数据类型说明符 成员名:位数;
程序员可以通过冒号(:)后的位数来指定为一个位域所占用的二进制位数。使用位域,有以下几点需要注意:
(1)C++标准规定了使用这种机制用来允许编译器将不同的位域“打包”,但这种“打包”的具体方式,C++标准并没有规定,因此不同的编译器有不同的处理方式,不同编译器下,包含位域的类所占用的空间也会有所不同。
(2)只有bool、char、int和enum的成员才能被定义为位域。
(3)位域虽然节省了内存空间,但由于打包和解包的过程中需要耗费额外的操作,所以运行时间很可能会增加。
结构体与类唯一的区别在于访问权限,因此也允许定义位域;但在联合体中,各个成员本身就共用相同的内存单元,因此没有必要也不允许定义位域。
【例】设计一个结构体存储学生的成绩信息,需要包括学号、年级和成绩3项内容,学号的范围是0~99999999,年级分为freshman,sophomore,junior,senior四种,成绩包括A,B,C,D四个等级。
【分析】学号包括27个二进制位的有效信息,而年级、成绩各包括2个二进制位的有效信息。如果用整型存储学号(占4个字节),分别用枚举类型存储年级和等级(各至少占用4个字节),则总共至少占用12个字节。如果采用位域,则需要27+2+2=31个二进制位,只需要4个字节就能存下。
不采用位域的情况:
enum Level
{
FRESHMAN,
SOPHOMORE,
JUNIOR,
SENIOR
};
enum Grade
{
A,
B,
C,
D
};
class Student
{
public:
Student(unsigned number, Level level, Grade grade) :m_number(number), m_level(level), m_grade(grade){}
void Show();
private:
unsigned m_number ;//4
Level m_level ;//4
Grade m_grade ;//4
};
void Student::Show()
{
cout << "Number: " << m_number << endl;
cout << "Level: ";
switch (m_level)
{
case FRESHMAN:
cout << "freshman" << endl;
break;
case SOPHOMORE:
cout << "sophomore" << endl;
break;
case JUNIOR:
cout << "junior" << endl;
break;
case SENIOR:
cout << "senior" << endl;
break;
}
cout << "Grade: ";
switch (m_grade)
{
case A:
cout << "A" << endl;
break;
case B:
cout << "B" << endl;
break;
case C:
cout << "C" << endl;
break;
case D:
cout << "D" << endl;
break;
}
}
int main()
{
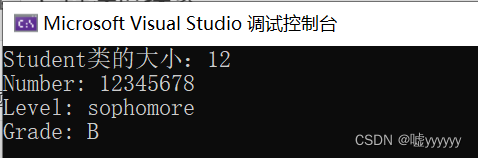
Student s(12345678, SOPHOMORE, B);
cout << "Student类的大小:" << sizeof(Student) << endl;
s.Show();
return 0;
}
运行结果:
采用位域的情况:
enum Level
{
FRESHMAN,
SOPHOMORE,
JUNIOR,
SENIOR
};
enum Grade
{
A,
B,
C,
D
};
class Student
{
public:
Student(unsigned number, Level level, Grade grade) :m_number(number), m_level(level), m_grade(grade){}
void Show();
private:
unsigned m_number : 27;
Level m_level : 2;
Grade m_grade : 2;
};
void Student::Show()
{
cout << "Number: " << m_number << endl;
cout << "Level: ";
switch (m_level)
{
case FRESHMAN:
cout << "freshman" << endl;
break;
case SOPHOMORE:
cout << "sophomore" << endl;
break;
case JUNIOR:
cout << "junior" << endl;
break;
case SENIOR:
cout << "senior" << endl;
break;
}
cout << "Grade: ";
switch (m_grade)
{
case A:
cout << "A" << endl;
break;
case B:
cout << "B" << endl;
break;
case C:
cout << "C" << endl;
break;
case D:
cout << "D" << endl;
break;
}
}
int main()
{
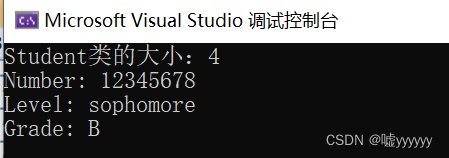
Student s(12345678, SOPHOMORE, B);
cout << "Student类的大小:" << sizeof(Student) << endl;
s.Show();
return 0;
}
运行结果:
Student类中各类数据成员所占的空间分布:

3.用构造函数定义类型转换
(1)用构造函数定义的类型转换
用户可以为类类型定义类型转换。在很多时候,一个对象的类型转换,需要通过创建一个无名的临时对象来完成。因此,先了解临时对象。
当一个函数的娥返回类型为类类型时,函数调用返回后,一个无名的临时对象会被创建,这种创建不是由用户显式指定的,而是隐含发生的。事实上,临时对象也可以显式创建,方法是直接使用类名调用这个类的构造函数。例如,如果希望使用Point和Line两个类来计算一个线段的长度,可以不创建有名的点对象和线段对象,而用这种方式:
cout<<Line(Point(1),Point(2)).getLen()<<endl;
这里以参数1(以及一个默认的参数0)调用Point的构造函数创建一个Point的临时对象,又以参数2(以及一个默认的参数0)调用Point的构造函数创建另一个Point的临时对象,然后以这两个Point的临时对象为参数调用Line的构造函数,创建一个Line的临时对象,最后以这个临时对象为目的对象,调用Line类的getLen()函数,得到线段长度。
【注意】临时对象的生存期很短,在它所在的表达式被执行完之后,就会被销毁。
这里用Point(1),Point(2)创建了两个临时对象,这正是类型转换——将整型数据转换为Point类型对象的显式类型转换。
C++中可以通过构造函数,来自定义类型之间的转换。一个构造函数,只要可以用一个参数调用,那么它就设定了一种从参数类型到这个类类型的类型转换。由于是类型转换,所以上面一行代码也可以写成下面两种等效形式:
cout<<Line(static_cast<Point>(1),static_cast<Point>(2)).getLen()<<endl;
或
cout<<Line((Point)1,(Point)2).getLen()<<endl;
这里的类型转换操作符可以省去,因为默认情况下,类的构造函数所规定的类型转换,允许通过隐含类型转换进行,也就是说可以写成这种形式:
cout<<Line(1,2).getLen()<<endl;
无论把类型转换写成哪种形式,程序执行时,都会通过调用Point类的构造函数来建立Point类的临时对象。类型转换的结果就是这个临时对象。
(2)只允许显式执行的类型转换
有时并不希望类型转换隐含地发生,例如上面的写法Line(1,2)中,把1和2作为Line构造函数的两个参数的含义很不明确。如果调用Line时传递了类型错误的参数,而自动发生的隐含转换却会使编译系统无法将错误报告出来。因此,C++允许避免这种隐含转换的发生。只要在构造函数前加上关键字explicit,以这个构造函数定义的类型转换,只能通过显式转换的方式完成。就像这样:
explicit Point(int xx=0,int yy=0)
{
x=xx;
y=yy;
}
【注意】如果函数的实现与函数在类定义中的声明是分离的,那么explicit关键字应该写在类定义中的函数原型声明处,而不能写在类定义外的函数实现处——因为explicit是用来约束这个构造函数被调用的方式的,属于一个类的对外接口的一部分,而是否加explicit关键字与函数实现代码的生成无关。
如果Point的构造函数添加了explicit关键字,那么下面的语句就是非法的:
cout<<Line(1,2).getLen()<<endl;
但是另外几种显式类型转换的写法是合法的。
【注意】如果一个构造函数可以只用一个参数调用,并且由此定义的类型转换没有明确的意义,那么应当对这个构造函数使用explicit关键字,避免类型转换被误用。
4.对象作为函数参数的返回值的传递方式
函数调用时传递基本类型的数据是通过运行栈,传递对象也一样是通过运行栈。运行栈中,在主调函数和被调函数之间,有一块二者都要访问的公共区域,主调函数把实参值写入其中,函数调用发生后,被调函数通过读取这段区域就可以得到形参值。需要传递的对象,只要建立在运行栈的这段区域上即可。传递基本数据类型与传递对象的不同之处在于,将实参值复制到这段区域上时,对于基本数据类型的参数,做一般的内存写操作即可,但是对于对象参数,则需要调用拷贝构造函数。例如,以下程序中,在main函数中调用f(b)这个函数:
#include<iostream>
using namespace std;
class Point
{
public:
Point(int xx = 0, int yy = 0) :x(xx), y(yy)
{
}
Point(Point& p);
int getX()
{
return x;
}
int getY()
{
return y;
}
private:
int x, y;
};
Point::Point(Point& p) :x(p.x), y(p.y)
{
cout << "调用拷贝构造函数" << endl;
}
void f(Point p)
{
cout << p.getX() << endl;
}
Point g()
{
Point a(1, 2);
return a;//函数的返回值是类的对象,返回函数值时,拷贝构造函数被调用
}
int main()
{
Point a(1, 2);
Point b(a);//用对象a初始化对象b,拷贝构造函数被调用
cout << b.getX() << endl;
f(b);//函数的形参为类的对象,调用函数时,拷贝构造函数被调用
b =g();
cout << b.getX() << endl;
return 0;
}
调用f(b)函数时,就要调用Point的拷贝构造函数,使用b对象在运行栈的传参区域上构造一个临时对象。这个对象在主调函数main中无名,但却在被调函数f中有名(就是f函数的参数p)。在main中虽然无名,但地址却可以计算,因此编译器能够生产代码调用Point的拷贝构造函数,为这个对象初始化。对象参数的拷贝构造函数的调用在跳转到f函数的入口地址之前完成。
有时传递对象参数时,编译器会做出适当优化,使得拷贝构造函数不必被调用。例如,使用Point型的临时对象作为f函数的参数,对它进行调用:
f(Point(1,2));
最直接的做法是,先构造一个Point类型的临时对象,再以这个对象为参数调用拷贝构造函数,在运行栈的传参区域上生成一个临时对象,再执行f函数的代码。但是,构造两个临时对象有点多余,更好的做法是使用Point类的构造函数,再运行栈的传参区域上建立临时对象,这样就免去了一次拷贝构造函数的调用,如下图所示:
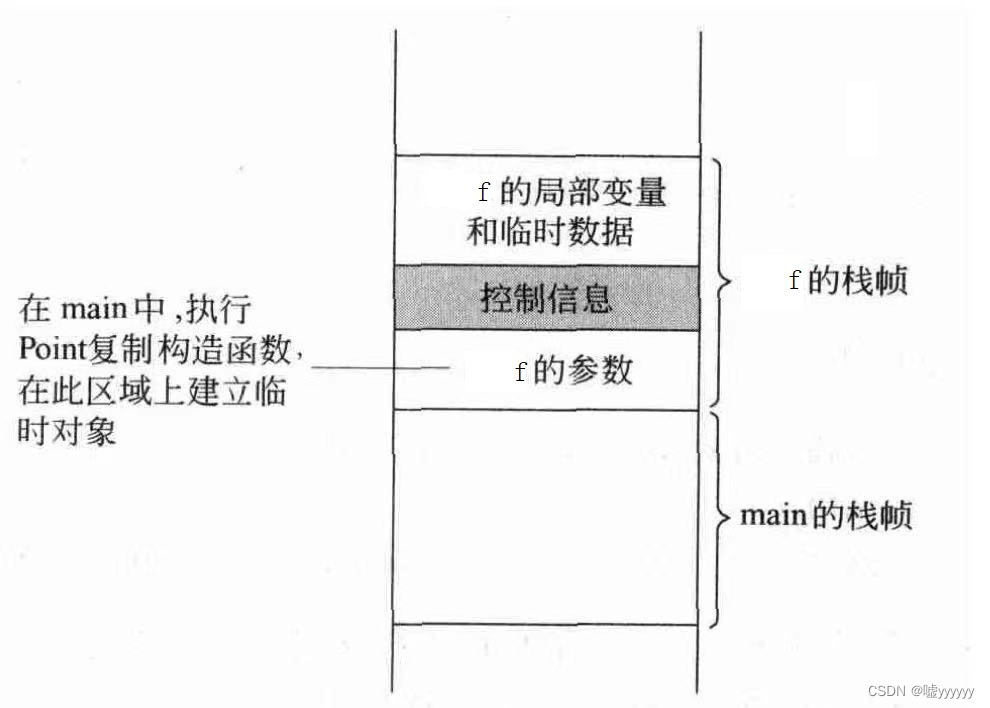
如果在传参时发生由构造函数所定义的类型转换,拷贝构造函数的调用同样可以避免。例如,使用下面的代码调用f函数:
f(1);
f函数接收Point类型的参数,因此需要执行从int型到Point型的隐含类型转换,而类型转换的本质是调用Point的构造函数创建临时对象。由于该临时对象同样可以直接建立在运行栈的传参区域上,因此也无须再调用一次拷贝构造函数。