Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction
摘要
MIMN是工业解决方案中第一个可以对用户序列长度达到1000的数据进行建模。但MIMN无法精确捕获给定用户兴趣的特定候选项目时,长度为用户行为序列进一步增加,比如增加10倍或更多。
本文提出的基于搜索的兴趣模型(SIM)通过两个级联搜索单元提取用户兴趣:
(i)泛搜单元GSU(General Search Unit) 负责从原始序列泛搜任意长的顺序行为数据,并获得相关的子用户行为序列(SBS)
(ii)**精搜单元ESU(Exact Search Unit)**对候选物料和SBS之间的精确关系进行建模。
这种级联搜索模式使SIM具有更好的能力,在可伸缩性和可扩展性方面更准确地建模终身序列行为,SIM对顺序用户行为数据进行建模最大长度可达54000。
1. 简介
大多数方法对用户序列行为数据进行建模的方法,一旦序列长度达到数百时,就会受计算负担的限制以及实际在线系统中的存储的限制。丰富的用户行为数据被证明具有很大的价值。23%的用户在淘宝最近5个月点击超过1000个产品。如何设计对长序列用户行为数据建模的可行方案一直是一个开放和热门的话题,吸引了双方的研究人员工业和学术。
研究的一个分支借用了NLP领域的思想,提出了基于记忆内存网络的长序列用户行为数据建模方法,并取得了一些突破。MIMN是一个典型的作品,它实现了SOTA与阿里巴巴学习算法与服务系统协同设计。MIMN是第一个可以对顺序用户建模的工业解决方案,长度扩展到1000的行为数据。具体来说,MIMN增量地将一个用户的不同兴趣嵌入到固定的大小中每个新行为都会更新的内存矩阵,这样就解耦了用户兴趣建模计算与点击率预测。因此,对于在线服务,延迟将不是问题,存储成本取决于存储矩阵的大小,这比原始行为序列要少得多。
然而,它是基于记忆网络的建模方法仍然具有挑战性。实际上,我们发现当用户行为序列的长度进一步增加时,MIMN无法精确捕捉用户对特定候选项目的兴趣,例如最多10000个序列的长度。这是因为编码所有的用户历史行为进入固定大小的内存矩阵会导致大量的噪声包含在存储单元中。
另一方面,正如在之前的工作DIN中指出,一个用户的兴趣是多样的,面对不同的候选物料时兴趣也有所不同。DIN的核心思想是从用户行为中搜索有效信息,建立用户的特殊兴趣模型用户,面对不同的候选物料。这样,我们就能解决将所有用户兴趣编码为固定大小参数的挑战。DIN确实为用户CTR建模带来了很大的改进。但是面对长顺序用户,DIN的搜索公式需要花费不可接受的计算和存储。所以,我们可以应用一个类似的搜索技巧和设计一种更有效的知识提取方法
从长序列的用户行为数据。
在本文中,我们通过设计一个新的模型模型来解决这个挑战,我们将其命名为基于搜索的兴趣模型SIM(Search-based Interest Model)。SIM采用DIN的思想,只捕获用户对特定候选物料相关的兴趣。在SIM中,用户通过两个级联搜索单元提取兴趣:
(i)泛搜单元(GSU) 从原始和任意长顺序行为数据中进行常规搜索,使用候选物料从中查询,并获得子用户行为序列SBS(Sub user Behavior Sequence)。根据我们的经验,SBS长度可以降至数百个,原始行为数据中的噪声信息可以被过滤掉。
(ii)精搜单元(ESU) 对候选对象之间的精确关系进行建模,。这里我们可以很容易地应用DIN或者DIEN所提出的类似方法。
总结:
• 提出了一种新的SIM模型来建模长序列原始用户行为数据。两级级联的搜索机制使SIM具有更好的长序列建模能力及可扩展性和准确性。
2. 相关工作
用户兴趣模型 基于深度学习的方法已经实现,在CTR预测任务中取得了巨大成功。大多数文章使用深度神经网络进行捕获不同领域特征之间的相互作用,使工程师可以摆脱无聊的特征工程工作。最近,一系列称之为“用户兴趣模型”的作品,专注于学习从历史行为中表示潜在的用户兴趣,使用不同的神经网络架构,如CNN,RNN、Transformer、Capsule等。DIN强调用户兴趣是多样化的,DIN引入注意机制,以捕捉用户对不同物料的不同兴趣。DIEN指出了历史行为之间的关系对建模用户兴趣进化很重要,DIEN设计了一种基于GRU的兴趣抽取层。MIND认为使用单个向量表示一个用户不足以捕获用户的兴趣,MIND引入了胶囊网络与动态路由方法来表示用户的多个兴趣向量。此外,受自我注意力结构在序列到序列学习任务中的成功启发,有文章引入了Transformer来模拟用户跨会话和在会话内的兴趣。
长期用户兴趣建模 在用户兴趣模型中考虑长期历史行为序列可以显著提高CTR模型的性能。虽然长用户行为序列为用户带来了更多有用的信息,但是极大地增加了延迟和存储的负担。一系列文章聚焦于解决长期用户兴趣建模的挑战,有文章提出终身序列的分层周期记忆网络建模与个性化记忆的序列模式,有文章选择一个基于注意力的框架进行组合用户的长期和短期偏好。他们采用了注意不对称SVD范式来模拟长期兴趣。MIMN提出了一种基于内存记忆的架构,将用户的长期兴趣嵌入到固定大小的内存中,记忆网络解决了用户行为数据的大量存储问题,并设计了UIC模块来记录新用户的行为,增量地处理延迟限制。但是MIMN记忆网络中放弃了目标物料的信息,而这个信息对用户兴趣建模非常重要。
3. 基于搜索的兴趣建模
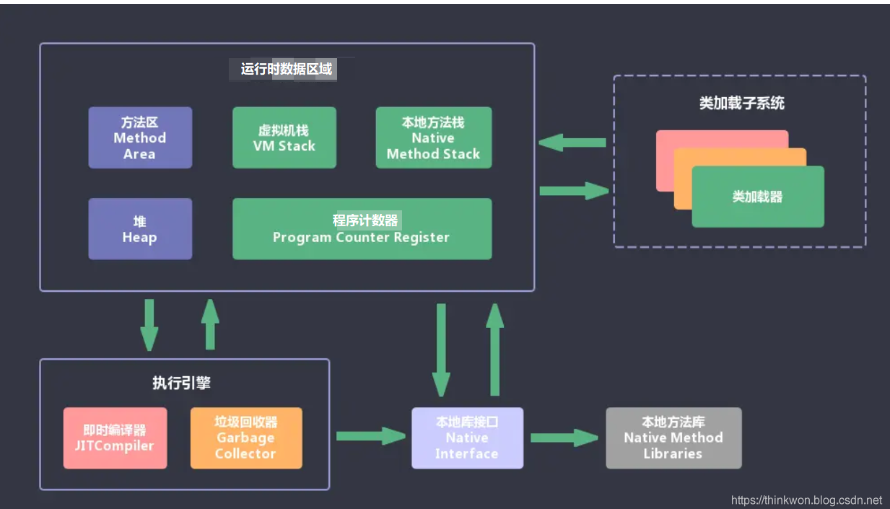
通过对用户行为数据进行建模,已被证明是有效的。通常,基于注意力的点击率模型,如DIN和DIEN,设计复杂的模型结构,并通过涉及注意机制来捕捉用户不同的兴趣,根据不同候选物料从用户行为序列中搜索有效知识。但在现实世界中,这些模型只能处理短期行为序列数据,其中长度通常小于150。另一方面,长期的用户行为数据是有价值的,对用户长期兴趣进行建模可能会带来更多样化的推荐结果。我们似乎陷入了两难境地,我们无法在现实世界系统中地处理有价值的终身用户行为数据。为了应对这一挑战,我们提出了一种新的建模范式,该模型被称为基于搜索的兴趣模型(SIM)。SIM是一个两阶段的搜索策略,可以处理长期的用户行为以一种有效的方式排列。在本节中,我们将介绍首先介绍了SIM的总体工作流程,然后介绍了两者的提出。
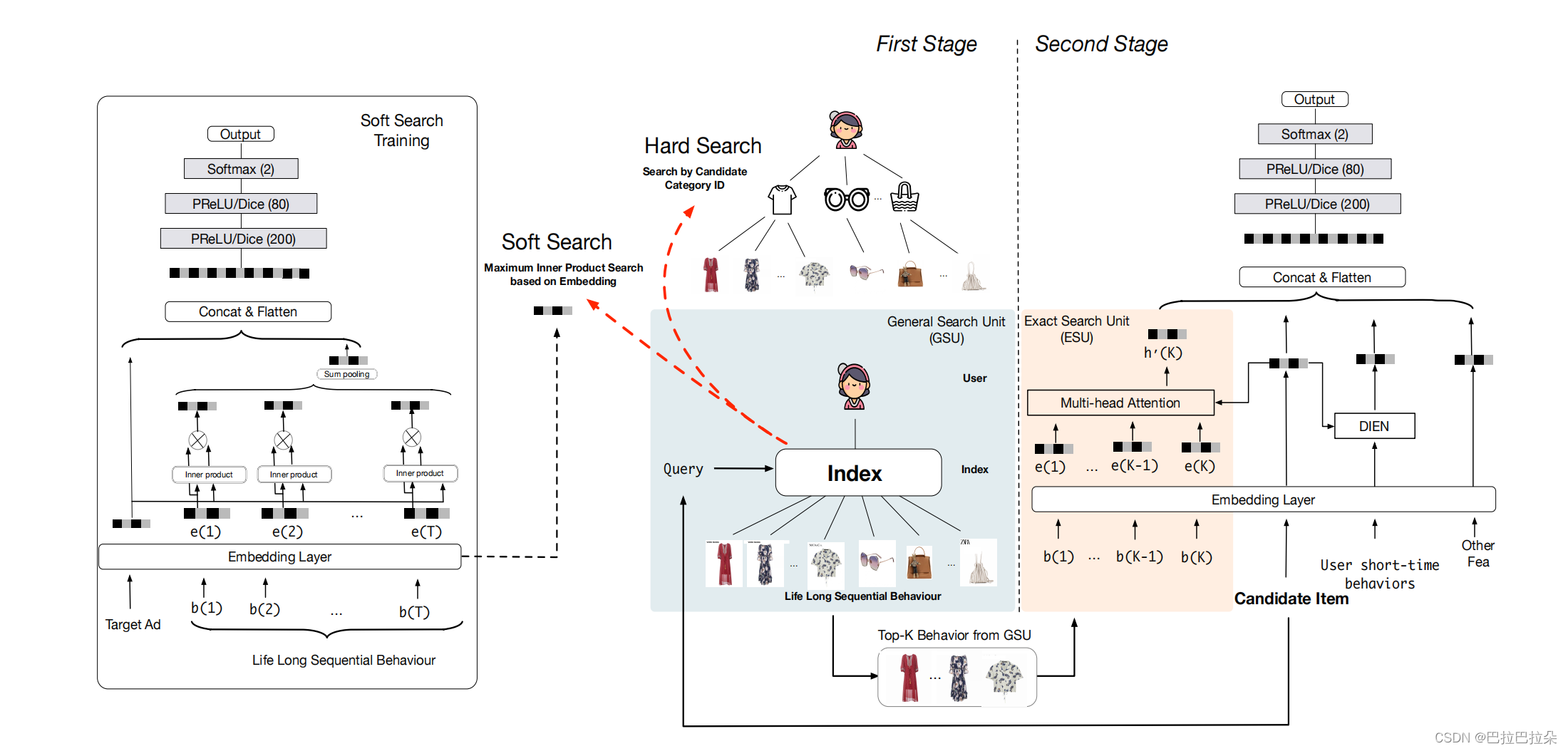
在第一阶段,利用泛搜单元(GSU),进行搜索top-K相关子行为序列,从原始的长期具有次线性时间复杂度的行为序列。这里K通常比行为序列的原始长度短得多。在时间和计算量的限制下,能够搜索到相关行为,是一种有效的搜索方法。在第3.2节中,我们提供了GSU的两种直接实现:软搜索和硬搜索。GSU需要一个普通但有效的截断原始序列行为的策略,满足了时间和计算资源的严格限制。
在第二阶段,精搜单元(ESU),它需要将过滤后的子序列用户行为作为输入引入进一步捕捉精确的用户兴趣。这是一个复杂的模型结构复杂的,如DIN和DIEN,因为长期行为的数量缩短到了数百个。
虽然我们分别介绍了这两个阶段,但实际上实际上它们是一起训练的。
3.2 泛搜单元(General Search Unit)
给定一个候选目标物料,只有一部分用户行为是有价值的。这部分用户的行为与最终的用户决策密切相关。挑选这些
相关用户行为有助于用户兴趣建模。使用整个用户行为序列来直接建模用户兴趣将带来巨大的资源使用和响应延迟,这在实际应用中通常是不可接受的。为此,我们建议用泛搜单位来削减用户兴趣建模中用户行为的输入数量。在这里
我们介绍了两种通用的搜索单元:硬搜索和软搜索。
给定用户行为序列列表 B = [ b 1 ; b 2 ; . . . , b T ] B=[b_1;b_2;...,b_T] B=[b1;b2;...,bT],其中 b i b_i bi表示第 i i i个序列行为, T T T表示序列长度。泛搜单元就是计算每个行为和目标物料的相关性得分 r i r_i ri,然后选择topK的序列子集 B ∗ B^* B∗。软搜索和硬搜索是计算相关性的方式不同
r
i
=
{
S
i
g
n
(
C
i
=
C
a
)
h
a
r
d
−
s
e
a
r
c
h
(
W
b
e
i
)
⊙
(
W
a
e
a
)
s
o
f
t
−
s
e
a
r
c
h
r_i=\left\{ \begin{aligned} Sign(C_i = C_a) \ \ \ \ hard-search \\ (W_be_i )\odot (W_ae_a) \ \ \ soft-search \end{aligned} \right.
ri={Sign(Ci=Ca) hard−search(Wbei)⊙(Waea) soft−search
Hard-search 硬搜索模型是非参数的,只有行为与候选项目属于同一类别机就会被选择并聚合为要发送的子行为序列
到确精搜单位。这里
C
a
C_a
Ca和
C
i
C_i
Ci表示的是的目标物料类目和第
i
i
i个行为所属类目。硬搜索很简单,但稍后我们将在第4节中展示它非常适合在线服务。
Soft-search。在软搜索模型中,行为 b t b_t bt首先编码为一个one-hot向量,然后嵌入到低维向量 E = [ e 1 , e 2 , . . . , e T ] E=[e_1,e_2,...,e_T] E=[e1,e2,...,eT], W b W_b Wb和 W a W_a Wa分别表示行为 b t b_t bt和目标物料的权重。 e a e_a ea和 e i e_i ei表示目标物料和行为的向量。使用ALSH等ANN类方法可以进一步加快top-K搜索。
需要注意的是,长期和短期数据的分布是不同的。因此,直接使用学到的参数从短期用户兴趣建模的软搜索模型可能
误导长期用户兴趣建模。在本文中,这些权重参数在一个辅助CTR损失中训练。
用户行为表示计算如下
U
r
=
∑
i
=
1
T
r
i
e
i
U_r = \sum_{i=1}^T r_ie_i
Ur=i=1∑Triei
用户行为表示
U
r
U_r
Ur和目标物料向量表示
e
a
e_a
ea一起Concat后进入MLP网络。
3.3 精搜单元(Exact Search Unit)
泛搜单元选出来的topK的子序列
B
∗
B^*
B∗,作为基于注意力的模型精搜单元输入。考虑到用户序列行为跨度很长,引入每个序列行为距离到当前的时间间隔,
D
=
[
Δ
1
;
Δ
2
;
.
.
.
;
Δ
K
]
D=[\Delta_1;\Delta_2;...;\Delta_K]
D=[Δ1;Δ2;...;ΔK],子序列及时间间隔的向量表示为
E
∗
=
[
e
1
∗
,
e
2
∗
,
.
.
.
,
e
K
∗
]
E^*=[e^*_1, e^*_2, ..., e^*_K]
E∗=[e1∗,e2∗,...,eK∗]和
E
t
=
[
e
1
t
,
e
2
t
,
.
.
.
,
e
K
t
]
E_t = [e^t_1, e^t_2, ..., e^t_K]
Et=[e1t,e2t,...,eKt]。子序列和时间序列concat到一起表示最终的用户序列向量
z
j
=
c
o
n
c
a
t
(
e
j
∗
,
e
j
t
)
z_j = concat(e^*_j, e^t_j)
zj=concat(ej∗,ejt);使用multi-head来捕获用户的多样化兴趣。
a
t
t
s
c
o
r
e
i
=
S
o
f
t
m
a
x
(
W
i
j
z
j
,
W
a
j
,
e
a
)
att^i_{score} = Softmax(W_{ij}z_j, W_{aj}, e_a)
attscorei=Softmax(Wijzj,Waj,ea)
h
e
a
d
i
=
a
t
t
s
c
o
r
e
i
z
j
head_i = att^i_{score}z_j
headi=attscoreizj
最终用户的多样化兴趣表示为
U
l
t
=
c
o
n
c
a
t
(
h
e
a
d
1
,
h
e
a
d
2
,
.
.
.
,
h
e
a
d
q
)
U_{lt} = concat(head_1, head_2, ..., head_q)
Ult=concat(head1,head2,...,headq)
然后送入到MLP网络,进行CTR预估。
损失函数
L
=
α
L
G
S
U
+
β
L
E
S
U
L = \alpha L_{GSU} + \beta L_{ESU}
L=αLGSU+βLESU
如果GSU是软搜索, α = β = 1 \alpha=\beta=1 α=β=1,如果GSU是硬搜索方式, α = 0 , β = 1 \alpha=0,\beta=1 α=0,β=1
4. 线上实现
4.1 线上实现的挑战

峰值时请求量超过每条一百万,存储和耗时限制是巨大挑战。
4.2 线上的SIM
离线验证表明基于软搜索和硬搜索的结果几乎一致,也就是软搜索出来的物料的类目和目标物料的类目基本一致,所以线上选择了更简单的硬搜索方式。
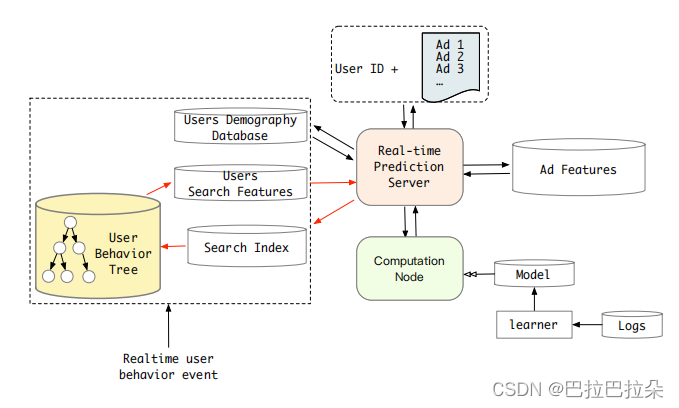
离线构建了一个二级索引结构,实际是个Key-Key-Value的结构,对应userid-category-behaviors,存储到线上,占用22T。通过GSU后,候选序列从万级缩减到上百。
5. 实验
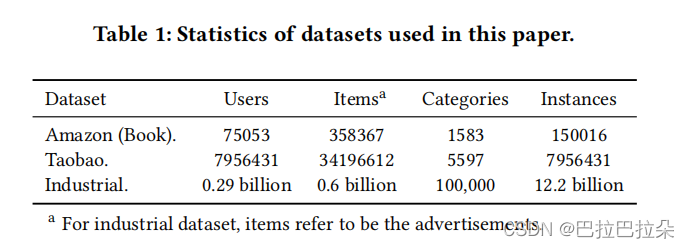
数据
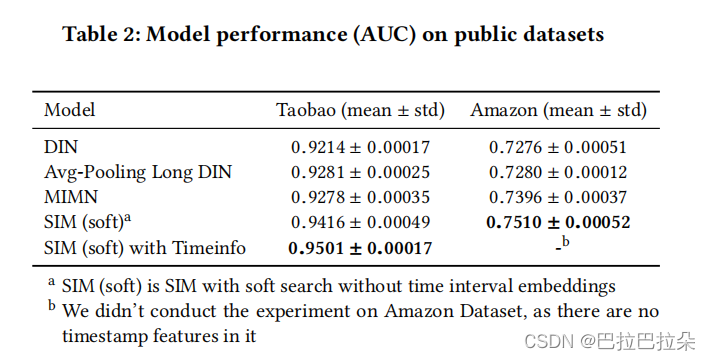
实验结果
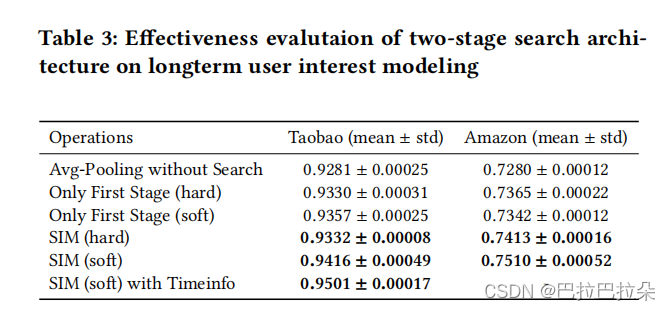
消融实验
两阶段的有效性
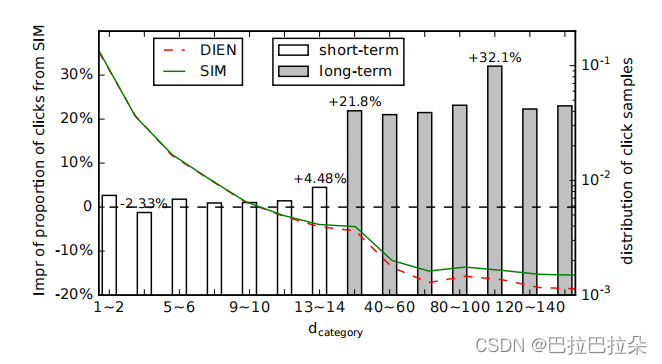
工业数据实践
定义. Days till Last Same Category Behavior (
d
c
a
t
e
д
o
r
y
d_{cateдory}
dcateдory)表示当前点击的物料的类目和最近历史用户点击序列的类目相同的时间间隔天数。比如说用户现在点击的类目是c1,用户最近一次点击c1是5天前,那么
d
c
a
t
e
д
o
r
y
d_{cateдory}
dcateдory=5。这个指标表示的是模型能学习到长期兴趣的能力。这里划分长期和短期是按照最近1-14天为短期,14天以上是长期。下图可以看到SIM能显著学习到用户长期兴趣。
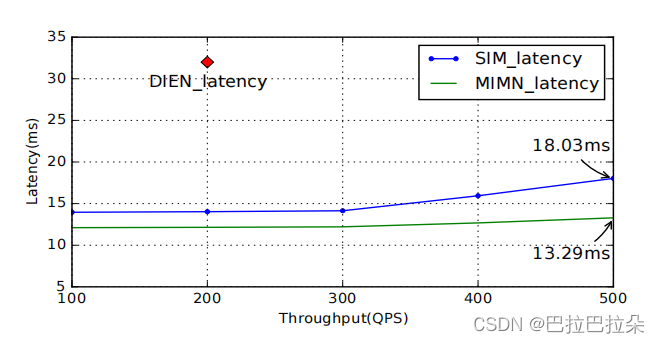
耗时比较
6. 总结
本文提出的基于搜索的兴趣模型(SIM)通过两个级联搜索单元提取用户兴趣,泛搜提前离线准备好,选出数百个相关候选,精搜在选出的候选中再使用attention建模。