torch分布式数据并行DDPtorch.nn.parallel.DistributedDataParallel代码修改记录。(要求pytorch_version>1.0)
目录
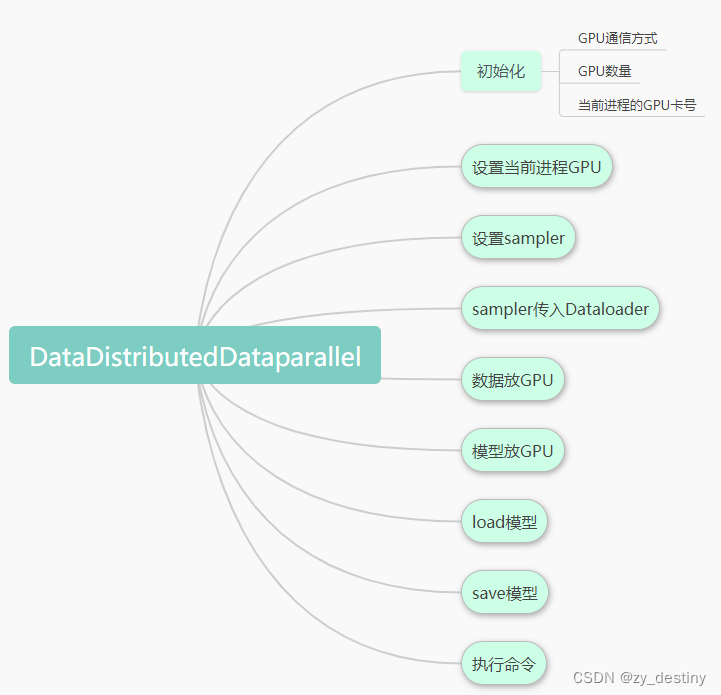
1.🍄🍄要修改的地方概览
2.✏️✏️初始化
3.✏️✏️设置当前进程GPU
4.✏️✏️设置sampler
5.✏️✏️sampler传入dataloader
6.✏️✏️数据放GPU
7.✏️✏️模型放GPU
8.✏️✏️load模型
9.✏️✏️save模型
10.✏️✏️执行命令
整理不易,欢迎一键三连!!!
1.🍄🍄要修改的地方概览
2.✏️✏️初始化
在代码最开始的地方设置初始化参数,即训练和数据组织之前。
n_gpus = args.n_gpus #自行传入
#local_rank = args.local_rank #自行传入
local_rank = int(os.environ['LOCAL_RANK']) #代码计算
torch.distributed.init_process_group('nccl', world_size=n_gpus, rank=local_rank)#初始化进程组- 指定GPU之间的通信方式'nccl'
- world_size:当前这个节点上要用多少GPU卡;(当前节点就是当前机器)
- rank: 当前进程在哪个GPU卡上,通过args.local_rank来获取,local_rank变量是通过外部指令传入的;(也可以通过环境变量来接收)
注意:自行传入的变量需要通过argparse第三方库写入,示例如下:
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--n_gpus", help="num of gpus")
parser.add_argument("-p", "--project", help="project name")
parser.add_argument('-s', '--sparse', action='store_true', default=False, help='GAT with sparse version or not.')
parser.add_argument('-d', '--seed', type=int, default=72, help='Random seed.')
parser.add_argument('-e', '--epochs', type=int, default=10000, help='Number of epochs to train.')
args = parser.parse_args()
print(args.n_gpus)
print(args.sparse)
print(args.seed)
print(args.epochs)
3.✏️✏️设置当前进程GPU
在初始化之后紧接着设置当前进程的GPU
torch.cuda.set_device(local_rank)上述指令作用相当于设置CUDA_VISBLE_DEVICES环境变量,设置当前进程要用第几张卡;
4.✏️✏️设置sampler
from torch.utils.data.distributed import DistributedSampler
train_sampler = DistributedSampler(dataset_train)
...
for epoch in range(start_epoch, total_epochs):
train_sampler.set_epoch(epoch) #为了让每张卡在每个周期中得到的数据是随机的
...此处的train_dataset为load数据的Dataset类,根据数据地址return出每个image和队形的mask,DistributedSampler返回一堆数据的索引train_sampler,根据索引去dataloader中拿数据,并且在每次epoch训练之前,加上train_sampler.set_epoch(epoch)这句,达到shuffle=True的目的。
5.✏️✏️sampler传入dataloader
from torch.utils.data import DataLoader
dataloader_train = DataLoader(
dataset_train,
batch_size=args.batch_size,
sampler = train_sampler
)
dataloader_val = DataLoader(
dataset_val,
batch_size=1,
)通过将train_sampler传入dataloader达到数据传入模型的数据格式。
6.✏️✏️数据放GPU
在每次训练过程中,设置数据放GPU里。
for img,label in dataloader_train:
inputs = img.cuda(local_rank) #数据放GPU
labels = label.cuda(local_rank) #数据放GPU
...
7.✏️✏️模型放GPU
在定义模型的地方,设置将模型放入GPU
model = XXNet()
net = torch.nn.parallel.DistributedDataParallel(model.cuda(local_rank),device_ids=[local_rank]) #模型拷贝,放入DistributedDataParallel8.✏️✏️load模型
torch.load(model_file_path, map_location = local_rank)设置 map_location指定将模型传入哪个GPU上
9.✏️✏️save模型
torch.save(net.module.state_dict(), os.path.join(ckp_savepath, ckp_name))注意,此处保存的net是net.module.state_dict
10.✏️✏️执行命令
python -m torch.distributed.launch --nproc_per_node=n_gpus --master_port 29502 train.py
- nproc_per_node:等于GPU数量
- master_port:默认为29501,如果出现address already in use,可以将其修改为其他值,比如29502
参考:视频讲解
整理不易,欢迎一键三连!!!
送你们一条美丽的--分割线--
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷🌷