论文:https://arxiv.org/abs/2208.04534
代码:https://github.com/yhcc/CNN_Nested_NER/tree/master
文章目录
- 有关工作
- 前期介绍
- CNN-NER
- 模型介绍
- 代码讲解
- 主类
- 多头biaffine
- CNN
- Loss
- 解码
- 数据传入格式
- 参考资料
有关工作
前期介绍
过去一共主要有四类方式用来解决嵌套命名实体识别的任务:
- 基于序列标注(sequence labeling)
- 基于超图(hypergraph)
- 基于序列到序列(Seq2Seq)
- 基于片段分类(span classification)
本文跟进了《Named Entity Recognition as Dependency Parsing》这一论文的工作,同样采用基于片段分类的方案。
该论文提出采用起始、结束词来指明对应的片段,并利用双仿射(Biaffine Decoder)来得到一个评分矩阵,其元素(i,j)代表对应片段(开始位置为第i个词,结束位置为第j个词)为实体的分数,这一基于片段的方法在计算上易于并行,因此得到了广泛的采用
下图给出一个直观的例子理解评分矩阵。这里由概率可得span(start=2,end=4)=“New York University”最可能是ORG实体
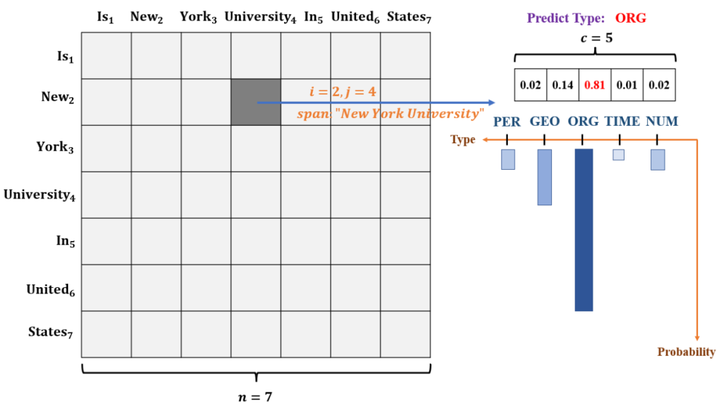
CNN-NER
作者在此基础上注意到了过往的工作忽视了相邻片段间的彼此联系,并通过对评分矩阵的观察分析发现了临近的片段具有非常明显的空间关联。如下图所示

- o:中心的span
- a:后端的字符序列与中心span冲突
- b:前端的字符序列与中心span冲突
- c:包含中心span
- d:被中心span包含
- e:无冲突
针对左上角第一个矩阵:o(2-4),New York University
a(1-3),Is New York
c(1-4),Is New York University
c(1-5),Is New York University in
d(2-3),New York
c(2-5),New York University in
d(3-3),York
d(3-4),York University
b(3-5),York University in
针对右下角第二个矩阵:o(6-6),United
e(5-5),in
c(5-6),in United
c(5-7),in United States
c(6-5),in United
c(6-7),United States
c(7-5),in United States
c(7-6),United States
c(7-7),States
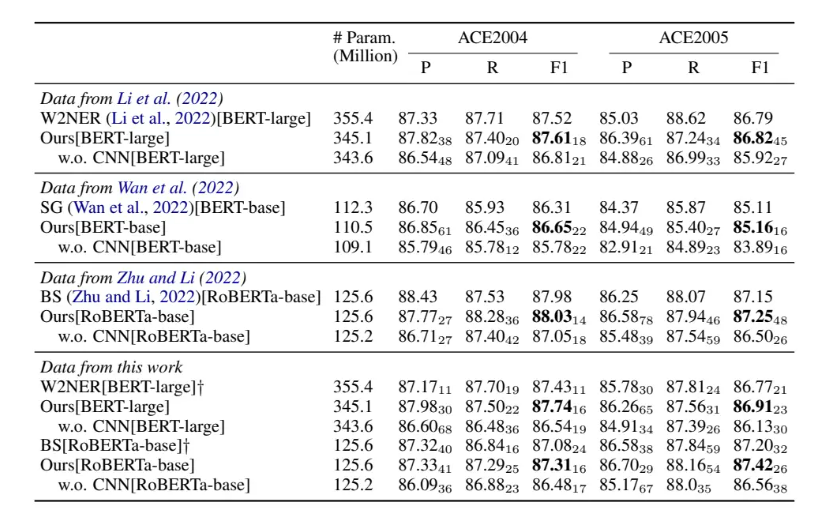
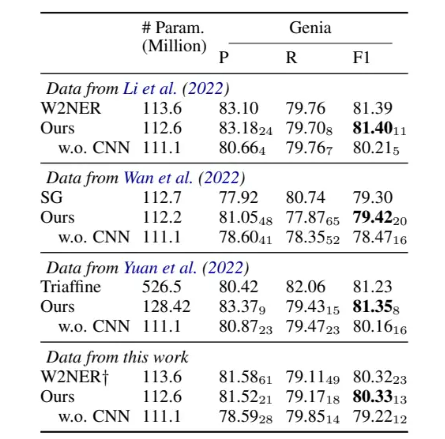
作者把这种针对每一个中心span的张量理解成一种通道数,进一步采用了计算机视觉领域常用的卷积神经网络(CNN)来建模这种空间联系,最终得到一个简单但颇具竞争力的嵌套命名实体解决方案,将其命名为CNN-NER
模型介绍
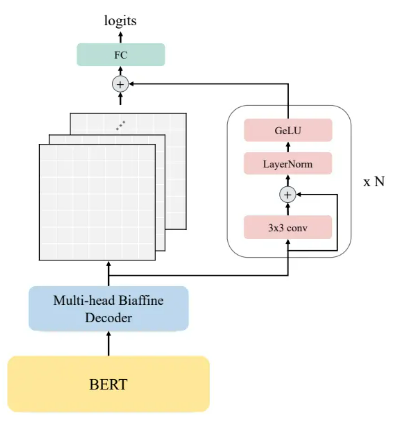
首先使用编码器(BERT-Encoder)对输入序列进行编码。在获得上下文有关的词嵌入(embedding)后,过去的工作通常将其与静态的词嵌入以及字符级别的嵌入拼接起来送入BiLSTM中获得聚合的词表示,但本文为了让模型架构比较简单,就没有采用更多的嵌入也没有额外引入LSTM层。
然后仿照之前的工作,采用双头仿射解码器(multi-head Biaffine Decoder)获取表示所有可能的片段对应的特征矩阵。
接下来,从维度上考察特征矩阵,将其视作多通道的图片,采用若干个常见的卷积块提取特征矩阵的空间特征。
最后通过FC和sigmoid函数预测对应片段是命名实体的“概率”。训练的损失函数采用的是常见的二元交叉熵(BCE)
本文使用了与之前工作相同的方法解码模型输出的概率,即采用如下的贪心选择:首先丢弃所有预测概率低于0.5的片段,然后按照预测概率从高到低对片段进行排序,依次选择当前预测概率最高的片段,如果其不与之前已经解码出的命名实体冲突,则将该片段解码成一个新的命名实体,否则将其丢弃。如此迭代进行就得到了模型预测的输入序列的所有互不冲突的命名实体

代码讲解
主类
class CNNNer(BaseModel):
def __init__(self, num_ner_tag, cnn_dim=200, biaffine_size=200,
size_embed_dim=0, logit_drop=0, kernel_size=3, n_head=4, cnn_depth=3):
super(CNNNer, self).__init__()
self.pretrain_model = build_transformer_model(config_path=config_path, checkpoint_path=checkpoint_path, segment_vocab_size=0)
hidden_size = self.pretrain_model.configs['hidden_size']
if size_embed_dim!=0:
n_pos = 30
self.size_embedding = torch.nn.Embedding(n_pos, size_embed_dim)
_span_size_ids = torch.arange(512) - torch.arange(512).unsqueeze(-1)
_span_size_ids.masked_fill_(_span_size_ids < -n_pos/2, -n_pos/2)
_span_size_ids = _span_size_ids.masked_fill(_span_size_ids >= n_pos/2, n_pos/2-1) + n_pos/2
self.register_buffer('span_size_ids', _span_size_ids.long())
hsz = biaffine_size*2 + size_embed_dim + 2
else:
hsz = biaffine_size*2+2
biaffine_input_size = hidden_size
self.head_mlp = nn.Sequential(
nn.Dropout(0.4),
nn.Linear(biaffine_input_size, biaffine_size),
nn.LeakyReLU(),
)
self.tail_mlp = nn.Sequential(
nn.Dropout(0.4),
nn.Linear(biaffine_input_size, biaffine_size),
nn.LeakyReLU(),
)
self.dropout = nn.Dropout(0.4)
if n_head>0:
self.multi_head_biaffine = MultiHeadBiaffine(biaffine_size, cnn_dim, n_head=n_head)
else:
self.U = nn.Parameter(torch.randn(cnn_dim, biaffine_size, biaffine_size))
torch.nn.init.xavier_normal_(self.U.data)
self.W = torch.nn.Parameter(torch.empty(cnn_dim, hsz))
torch.nn.init.xavier_normal_(self.W.data)
if cnn_depth>0:
self.cnn = MaskCNN(cnn_dim, cnn_dim, kernel_size=kernel_size, depth=cnn_depth)
self.down_fc = nn.Linear(cnn_dim, num_ner_tag)
self.logit_drop = logit_drop
def forward(self, input_ids, indexes):
last_hidden_states = self.pretrain_model([input_ids])
state = scatter_max(last_hidden_states, index=indexes, dim=1)[0][:, 1:] # b * l * hidden_size
lengths, _ = indexes.max(dim=-1)
head_state = self.head_mlp(state)# b * l * l * biaffine_size
tail_state = self.tail_mlp(state)# b * l * l * biaffine_size
if hasattr(self, 'U'):
scores1 = torch.einsum('bxi, oij, byj -> boxy', head_state, self.U, tail_state)
else:
scores1 = self.multi_head_biaffine(head_state, tail_state)#b * cnn_dim * l * l
head_state = torch.cat([head_state, torch.ones_like(head_state[..., :1])], dim=-1)# b * l * l * biaffine_size + 1
tail_state = torch.cat([tail_state, torch.ones_like(tail_state[..., :1])], dim=-1)# b * l * l * biaffine_size + 1
affined_cat = torch.cat([self.dropout(head_state).unsqueeze(2).expand(-1, -1, tail_state.size(1), -1),
self.dropout(tail_state).unsqueeze(1).expand(-1, head_state.size(1), -1, -1)], dim=-1)## b * l * l * 2(biaffine_size + 1)
if hasattr(self, 'size_embedding'):
size_embedded = self.size_embedding(self.span_size_ids[:state.size(1), :state.size(1)])# l * l * size_embed_dim
affined_cat = torch.cat([affined_cat, self.dropout(size_embedded).unsqueeze(0).expand(state.size(0), -1, -1, -1)], dim=-1)# b * l * l * (2(biaffine_size + 1) + size_embed_dim)
scores2 = torch.einsum('bmnh,kh->bkmn', affined_cat, self.W) # b x cnn_dim x L x L
scores = scores2 + scores1# b x cnn_dim x L x L
if hasattr(self, 'cnn'):
batch_size = lengths.shape[0]
broad_cast_seq_len = torch.arange(int(lengths.max())).expand(batch_size, -1).to(lengths)
mask = broad_cast_seq_len < lengths.unsqueeze(1)
mask = mask[:, None] * mask.unsqueeze(-1)
pad_mask = mask[:, None].eq(0)
u_scores = scores.masked_fill(pad_mask, 0)
if self.logit_drop != 0:
u_scores = F.dropout(u_scores, p=self.logit_drop, training=self.training)
u_scores = self.cnn(u_scores, pad_mask)# b x cnn_dim x L x L
scores = u_scores + scores
scores = self.down_fc(scores.permute(0, 2, 3, 1))
return scores # b * L * L * num_ner_tag
多头biaffine
class MultiHeadBiaffine(nn.Module):
def __init__(self, dim, out=None, n_head=4):
super(MultiHeadBiaffine, self).__init__()
assert dim%n_head==0
in_head_dim = dim//n_head
out = dim if out is None else out
assert out%n_head == 0
out_head_dim = out//n_head
self.n_head = n_head
self.W = nn.Parameter(nn.init.xavier_normal_(torch.randn(self.n_head, out_head_dim, in_head_dim, in_head_dim)))
self.out_dim = out
def forward(self, h, v):
"""
:param h: bsz x max_len x dim
:param v: bsz x max_len x dim
:return: bsz x max_len x max_len x out_dim
"""
bsz, max_len, dim = h.size()
h = h.reshape(bsz, max_len, self.n_head, -1)
v = v.reshape(bsz, max_len, self.n_head, -1)
w = torch.einsum('blhx,hdxy,bkhy->bhdlk', h, self.W, v)
w = w.reshape(bsz, self.out_dim, max_len, max_len)
return w
CNN
class MaskConv2d(nn.Module):
def __init__(self, in_ch, out_ch, kernel_size=3, padding=1, groups=1):
super(MaskConv2d, self).__init__()
self.conv2d = nn.Conv2d(in_ch, out_ch, kernel_size=kernel_size, padding=padding, bias=False, groups=groups)
def forward(self, x, mask):
x = x.masked_fill(mask, 0)
_x = self.conv2d(x)
return _x
class MaskCNN(nn.Module):
def __init__(self, input_channels, output_channels, kernel_size=3, depth=3):
super(MaskCNN, self).__init__()
layers = []
for _ in range(depth):
layers.extend([
MaskConv2d(input_channels, input_channels, kernel_size=kernel_size, padding=kernel_size//2),
LayerNorm((1, input_channels, 1, 1), dim_index=1),
nn.GELU()])
layers.append(MaskConv2d(input_channels, output_channels, kernel_size=3, padding=3//2))
self.cnns = nn.ModuleList(layers)
def forward(self, x, mask):
_x = x # 用作residual
for layer in self.cnns:
if isinstance(layer, LayerNorm):
x = x + _x
x = layer(x)
_x = x
elif not isinstance(layer, nn.GELU):
x = layer(x, mask)
else:
x = layer(x)
return _x
Loss
class Loss(object):
def __call__(self, scores, y_true):
matrix, _ = y_true
assert scores.shape[-1] == matrix.shape[-1]
flat_scores = scores.reshape(-1)
flat_matrix = matrix.reshape(-1)
mask = flat_matrix.ne(-100).float().view(scores.size(0), -1)
flat_loss = F.binary_cross_entropy_with_logits(flat_scores, flat_matrix.float(), reduction='none')
loss = ((flat_loss.view(scores.size(0), -1)*mask).sum(dim=-1)).mean()
return loss
解码
class Evaluator(Callback):
"""评估与保存
"""
def __init__(self):
self.best_val_f1 = 0.
def on_epoch_end(self, steps, epoch, logs=None):
f1, p, r, e_f1, e_p, e_r = self.evaluate(valid_dataloader)
if e_f1 > self.best_val_f1:
self.best_val_f1 = e_f1
# model.save_weights('best_model.pt')
print(f'[val-token level] f1: {f1:.5f}, p: {p:.5f} r: {r:.5f}')
print(f'[val-entity level] f1: {e_f1:.5f}, p: {e_p:.5f} r: {e_r:.5f} best_f1: {self.best_val_f1:.5f}\n')
def evaluate(self, data_loader, threshold=0.5):
def cal_f1(c, p, r):
if r == 0 or p == 0:
return 0, 0, 0
r = c / r if r else 0
p = c / p if p else 0
if r and p:
return 2 * p * r / (p + r), p, r
return 0, p, r
pred_result = []
label_result = []
total_ent_r = 0
total_ent_p = 0
total_ent_c = 0
for data_batch in tqdm(data_loader, desc='Evaluate'):
(tokens_ids, indexes), (matrix, ent_target) = data_batch
scores = torch.sigmoid(model.predict([tokens_ids, indexes])).gt(threshold).long()
scores = scores.masked_fill(matrix.eq(-100), 0) # mask掉padding部分
# token粒度
mask = matrix.reshape(-1).ne(-100)
label_result.append(matrix.reshape(-1).masked_select(mask).cpu())
pred_result.append(scores.reshape(-1).masked_select(mask).cpu())
# 实体粒度
ent_c, ent_p, ent_r = self.decode(scores.cpu().numpy(), ent_target)
total_ent_r += ent_r
total_ent_p += ent_p
total_ent_c += ent_c
label_result = torch.cat(label_result)
pred_result = torch.cat(pred_result)
p, r, f1, _ = precision_recall_fscore_support(label_result.numpy(), pred_result.numpy(), average="macro")
e_f1, e_p, e_r = cal_f1(total_ent_c, total_ent_p, total_ent_r)
return f1, p, r, e_f1, e_p, e_r
def decode(self, outputs, ent_target):
ent_c, ent_p, ent_r = 0, 0, 0
for pred, label in zip(outputs, ent_target):
ent_r += len(label)
pred_tuple = []
for item in range(pred.shape[-1]):
if pred[:, :, item].sum() > 0:
_index = np.where(pred[:, :, item]>0)
tmp = [(i, j, item) if j >= i else (j, i, item) for i, j in zip(*_index)]
pred_tuple.extend(list(set(tmp)))
ent_p += len(pred_tuple)
ent_c += len(set(label).intersection(set(pred_tuple)))
return ent_c, ent_p, ent_r
数据传入格式
初步处理
class MyDataset(ListDataset):
@staticmethod
def get_new_ins(bpes, spans, indexes):
bpes.append(tokenizer._token_end_id)
cur_word_idx = indexes[-1]
indexes.append(0)
# int8范围-128~127
matrix = np.zeros((cur_word_idx, cur_word_idx, len(label2idx)), dtype=np.int8)
ent_target = []
for _ner in spans:
s, e, t = _ner
matrix[s, e, t] = 1
matrix[e, s, t] = 1
ent_target.append((s, e, t))
assert len(bpes)<=maxlen, len(bpes)
return [bpes, indexes, matrix, ent_target]
def load_data(self, filename):
D = []
word2bpes = {}
with open(filename, encoding='utf-8') as f:
f = f.read()
for l in tqdm(f.split('\n\n'), desc='Load data'):
if not l:
continue
_raw_words, _raw_ents = [], []
for i, c in enumerate(l.split('\n')):
char, flag = c.split(' ')
_raw_words += char
if flag[0] == 'B':
_raw_ents.append([i, i, flag[2:]])
elif flag[0] == 'I':
_raw_ents[-1][1] = i
if len(_raw_words) > maxlen - 2:
continue
bpes = [tokenizer._token_start_id]
indexes = [0]
spans = []
ins_lst = []
_indexes = []
_bpes = []
for idx, word in enumerate(_raw_words, start=0):
if word in word2bpes:
__bpes = word2bpes[word]
else:
__bpes = tokenizer.encode(word)[0][1:-1]
word2bpes[word] = __bpes
_indexes.extend([idx]*len(__bpes))
_bpes.extend(__bpes)
next_word_idx = indexes[-1]+1
if len(bpes) + len(_bpes) <= maxlen:
bpes = bpes + _bpes
indexes += [i + next_word_idx for i in _indexes]
spans += [(s+next_word_idx-1, e+next_word_idx-1, label2idx.get(t), ) for s, e, t in _raw_ents]
else:
new_ins = self.get_new_ins(bpes, spans, indexes)
ins_lst.append(new_ins)
indexes = [0] + [i + 1 for i in _indexes]
spans = [(s, e, label2idx.get(t), ) for s, e, t in _raw_ents]
bpes = [tokenizer._token_start_id] + _bpes
D.append(self.get_new_ins(bpes, spans, indexes))
return D
传入的是:
- bpes:对应input_ids
- indexes:“CLS”、"SEP"为0,其他字符按照所在句子的位置的索引
- matrix:[cur_word_idx, cur_word_idx, len(label2idx)],第三个维度表明若是某个实体,则设为1
- ent_target:在当前句子中存在实体的的[start,ent,ent_type]
def collate_fn(data):
tokens_ids, indexes, matrix, ent_target = map(list, zip(*data))
tokens_ids = torch.tensor(sequence_padding(tokens_ids), dtype=torch.long, device=device)
indexes = torch.tensor(sequence_padding(indexes), dtype=torch.long, device=device)
seq_len = max([i.shape[0] for i in matrix])
matrix_new = np.ones((len(tokens_ids), seq_len, seq_len, len(label2idx)), dtype=np.int8) * -100
for i in range(len(tokens_ids)):
matrix_new[i, :len(matrix[i][0]), :len(matrix[i][0]), :] = matrix[i]
matrix = torch.tensor(matrix_new, dtype=torch.long, device=device)
return [tokens_ids, indexes], [matrix, ent_target]
- 对tokens_ids、indexes进行填充为0
- 对matrix填充为-100
参考资料
https://zhuanlan.zhihu.com/p/565824221
参照代码:
https://github.com/Tongjilibo/bert4torch/blob/master/examples/sequence_labeling/task_sequence_labeling_ner_CNN_Nested_NER.py