文章目录
- 每篇前言
- 1. duplicated()
- 2. drop_duplicates()
- 3. isnull()
- 4. notnull()
- 5. dropna()
- 6. fillna()
- 7. ffill()
- 8. bfill()
- 9. replace()
- 10. str.replace()
- 11. str.split.str()
每篇前言
🏆🏆作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6
- 🔥🔥本文已收录于Python全栈系列专栏:《100天精通Python从入门到就业》
- 📝📝此专栏文章是专门针对Python零基础小白所准备的一套完整教学,从0到100的不断进阶深入的学习,各知识点环环相扣
- 🎉🎉订阅专栏后续可以阅读Python从入门到就业100篇文章;还可私聊进两百人Python全栈交流群(手把手教学,问题解答); 进群可领取80GPython全栈教程视频 + 300本计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!
1. duplicated()
判断序列元素是否重复
语法格式:
DataFrame.duplicated(subset=None,keep='first')
参数说明:
-
subset:列标签,可选, 默认使用所有列,只考虑某些列来识别重复项传入列标签或者列标签的序列
-
keep:{‘first’,‘last’,False},默认’first’
-
first:删除第一次出现的重复项。
-
last:删除重复项,除了最后一次出现。
-
false:删除所有重复项
-
返回布尔型Series表示每行是否为重复行
示例代码:
import numpy as np
import pandas as pd
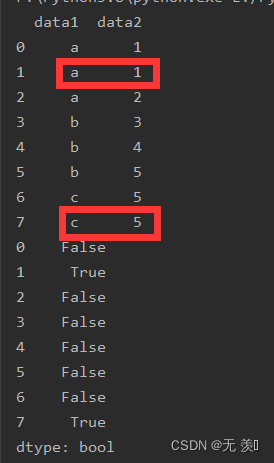
df_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, 4, 5, 5, 5]})
print(df_obj)
print(df_obj.duplicated())
运行结果:
2. drop_duplicates()
删除重复行,默认判断全部列,可指定按某些列判断
语法格式:
DataFrame.drop_duplicates(
self,
subset: Hashable | Sequence[Hashable] | None = None,
keep: Literal["first"] | Literal["last"] | Literal[False] = "first",
inplace: bool = False,
ignore_index: bool = False,
) -> DataFrame | None
参数说明:
-
subset:列标签,可选, 默认使用所有列,只考虑某些列来识别重复项传入列标签或者列标签的序列
-
keep:{‘first’,‘last’,False},默认’first’
-
first:删除第一次出现的重复项。
-
last:删除重复项,除了最后一次出现。
-
false:删除所有重复项
-
-
inplace:是否替换原数据,默认是False,生成新的对象,可以复制到新的DataFrame
-
ignore_index:bool,默认为False,如果为True,则生成的轴将标记为0,1,…,n-1。
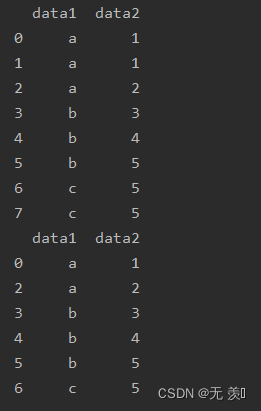
(1)判断所有列
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, 4, 5, 5, 5]})
print(df_obj)
print(df_obj.drop_duplicates())
运行结果:
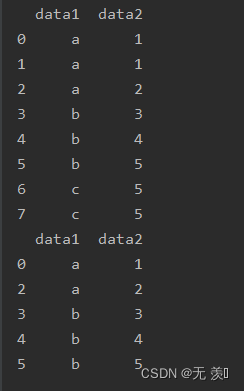
(2) 按照指定列进行判断
print(df_obj.drop_duplicates('data2'))
运行结果:
3. isnull()
判断序列元素是否为缺失(返回与序列长度一样的bool值)
示例代码:
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, 4, 5, 5, 5],
'data3':np.NaN})
print(df_obj)
print(df_obj.isnull())
运行结果:

4. notnull()
判断序列元素是否不为缺失(返回与序列长度一样的bool值)
print(df_obj.notnull())
运行结果:

5. dropna()
删除缺失值
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, np.NaN, 5, 5, np.NaN]})
print(df_obj)
print(df_obj.dropna())
运行结果:

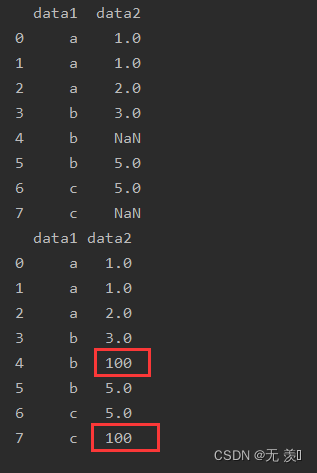
6. fillna()
缺失值填充
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, np.NaN, 5, 5, np.NaN]})
print(df_obj)
print(df_obj.fillna('100'))
运行结果:
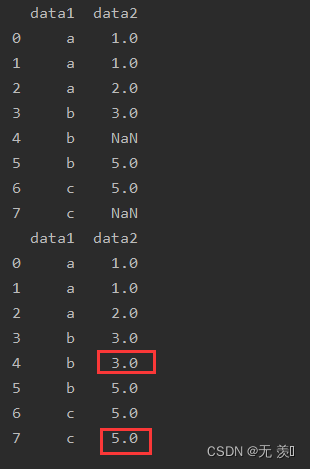
7. ffill()
前向后填充缺失值,用缺失值的前一个元素填充
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, np.NaN, 5, 5, np.NaN]})
print(df_obj)
print(df_obj.ffill())
8. bfill()
后向填充缺失值,用缺失值的后一个元素填充
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, np.NaN, 5, 5, np.NaN]})
print(df_obj)
print(df_obj.bfill())
9. replace()
替换元素,可以使用正则表达式
语法格式:
replace(
self,
to_replace=None,
value=None,
inplace: bool = False,
limit=None,
regex: bool = False,
method: str = "pad",
)
参数说明:
-
to_replace: 需要替换的值
-
value:替换后的值
-
inplace: 是否在原数据表上更改,默认 inplace=False
-
limit:向前或向后填充的最大尺寸间隙,用于填充缺失值
-
regex: 是否模糊查询,用于正则表达式查找,默认 regex=False
-
method: 填充方式,用于填充缺失值
- pad: 向前填充
- ffill: 向前填充
- bfill: 向后填充
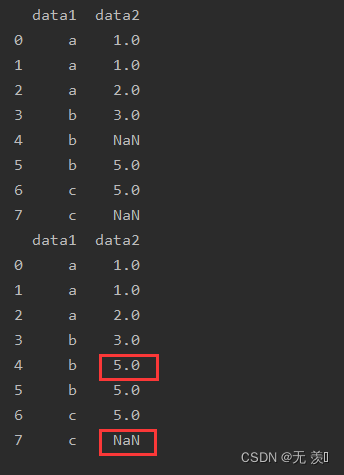
(1) 单个值替换
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, np.NaN, 5, 5, np.NaN]})
print(df_obj)
print(df_obj.replace('a',"A"))
运行结果:
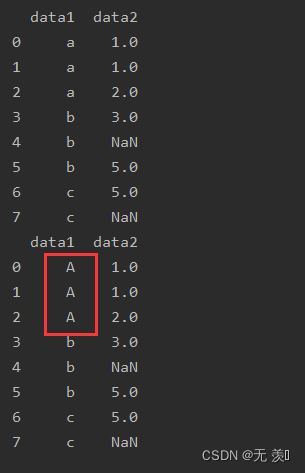
(2) 多个值替换一个值
print(df_obj.replace([1, 2], -100))
运行结果:
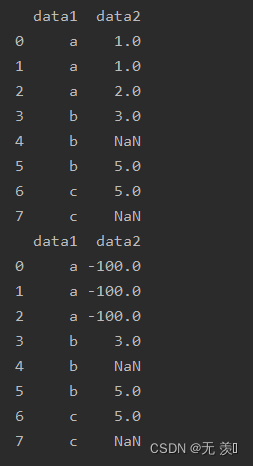
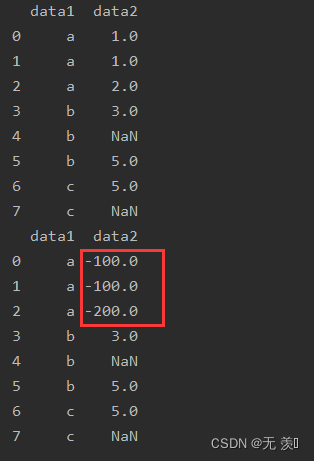
(3)多个值替换多个值
print(df_obj.replace([1, 2], [-100, -200]))
运行结果:
(4)使用正则表达式:
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1': ['ab', 'abc', 'aaa', 'b', 'b', 'b', 'c', 'c'],
'data2': [1, 1, 2, 3, np.NaN, 5, 5, np.NaN]})
print(df_obj)
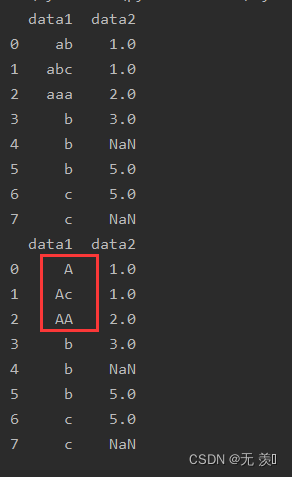
# 替换a开头的
print(df_obj.replace('a.?',"A",regex=True))
运行结果:
10. str.replace()
替换元素,可使用正则表达式
import numpy as np
import pandas as pd
s = pd.Series(['foo', 'fuz', np.nan])
print(s)
print(s.str.replace('f.', 'ba', regex=True))
运行结果:

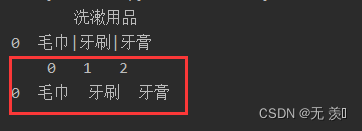
11. str.split.str()
以指定字符切割列
import numpy as np
import pandas as pd
data = {'洗漱用品':['毛巾|牙刷|牙膏']}
df = pd.DataFrame(data)
print(df)
print(df['洗漱用品'].str.split('|',expand=True))
运行结果:







![[附源码]Python计算机毕业设计Django云南美食管理系统](https://img-blog.csdnimg.cn/2d3c9ec5b1ba42088bca0b13da62a9bd.png)
![[附源码]Python计算机毕业设计大学生兼职管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/c281eadc32e14349a88ae8e64e2e5c73.png)
![[附源码]Python计算机毕业设计宠物短期寄养平台Django(程序+LW)](https://img-blog.csdnimg.cn/72a10c8a04a64523afe9e020d0df2980.png)