TrackReferenceKeyFrame
- 使用条件:
- 运动模型为空并且imu未初始化,说明是刚初始化完第一帧跟踪,或者已经跟丢了
- 当前帧和重定位帧间隔很近,用重定位帧来恢复位姿
- 恒速云端模型跟踪失败
1.计算当前帧的描述子的Bow向量
mCurrentFrame.ComputeBoW();
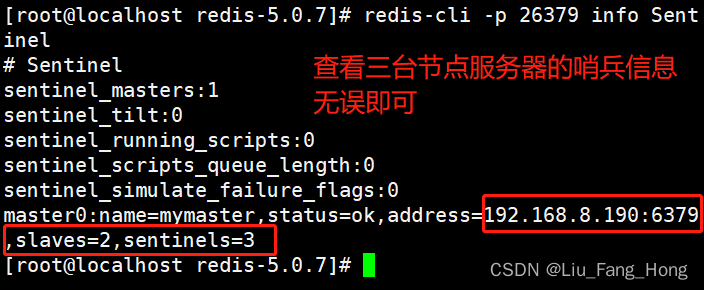
DBoW2由一棵词汇树(Vocabulary Tree)、逆向索引表(Inverse Indexes)以及一个正向索引表(Direct Indexes)三个部分构成。对于词汇树,它是由一堆图像离线训练而来的,首先对训练的图像计算ORB特征点,然后把这些特征点放在一起,通过K-means对它们聚类, 将之分为k类。然后对每簇,再次通过K-means进行聚类。如此重复L次,就得到了深度为L的树,除了叶子之外,每个节点都有k个子节点。
ComputeBoW主要是通过transform函数将当前帧的描述子mDescriptors转换为mBowVec和mFeatVec,其中:
mBowVec:[单词的Id,权重]std::map<WordId, WordValue>- 单词的
Id:为词汇树中距离最近的叶子节点的id - 权重:对于同一个单词,权重累加
mFeatVec:[Node的Id,对应的图像feature的Ids]std::map<NodeId, std::vector<unsigned int> >- Node的
Id:距离叶子节点深度为level up对应的node的Id - 对应的图像
feature的Id:该节点下所有叶子节点对应的feature的id
level up确定搜素范围:- 如果
level up越大,那么featureVec的size越大,搜索的范围越广,速度越慢; - 如果
level up越小,那么featureVec的size越小,搜索的范围越小,速度越快。
- 如果
template<class TDescriptor, class F>
void TemplatedVocabulary<TDescriptor,F>::transform(const TDescriptor &feature,
WordId &word_id, WordValue &weight, NodeId *nid, int levelsup) const
{
// propagate the feature down the tree
vector<NodeId> nodes;
typename vector<NodeId>::const_iterator nit;
// level at which the node must be stored in nid, if given
const int nid_level = m_L - levelsup;
if(nid_level <= 0 && nid != NULL) *nid = 0; // root
NodeId final_id = 0; // root
int current_level = 0;
do
{
++current_level;
nodes = m_nodes[final_id].children;
final_id = nodes[0];
double best_d = F::distance(feature, m_nodes[final_id].descriptor);
for(nit = nodes.begin() + 1; nit != nodes.end(); ++nit)
{
NodeId id = *nit;
double d = F::distance(feature, m_nodes[id].descriptor);
if(d < best_d)
{
best_d = d;
final_id = id;
}
}
if(nid != NULL && current_level == nid_level)
*nid = final_id;
} while( !m_nodes[final_id].isLeaf() );
// turn node id into word id
word_id = m_nodes[final_id].word_id;
weight = m_nodes[final_id].weight;
}
2.通过SearchByBoW加速当前帧与参考帧之间的特征匹配
- 构造旋转直方图
// 特征点角度旋转差统计用的直方图
vector<int> rotHist[HISTO_LENGTH];
for(int i=0;i<HISTO_LENGTH;i++)
rotHist[i].reserve(500);
// 将0~360的数转换到0~HISTO_LENGTH的系数
//! 原作者代码是 const float factor = 1.0f/HISTO_LENGTH; 是错误的,更改为下面代码
// const float factor = HISTO_LENGTH/360.0f;
const float factor = 1.0f/HISTO_LENGTH;
- 对于
pKF与F的FeatureVector,对属于同一节点的ORB特征进行匹配
为什么用FeatureVector能加快搜索?从词汇树中可以看出,Node相对于Word为更加抽象的簇,一个Node下包含了许多的相似的Word。如果想比较两个东西,那么先用抽象特征进行粗筛,然后再逐步到具体的特征。两帧图像特征匹配类似,先对比FeatureVector中的Node,如果Node为同一节点,再用节点下features进行匹配,这样避免了所有特征点之间的两两匹配
// 取出关键帧的词袋特征向量
const DBoW2::FeatureVector &vFeatVecKF = pKF->mFeatVec;
// We perform the matching over ORB that belong to the same vocabulary node (at a certain level)
// 将属于同一节点的ORB特征进行匹配
DBoW2::FeatureVector::const_iterator KFit = vFeatVecKF.begin();
DBoW2::FeatureVector::const_iterator Fit = F.mFeatVec.begin();
DBoW2::FeatureVector::const_iterator KFend = vFeatVecKF.end();
DBoW2::FeatureVector::const_iterator Fend = F.mFeatVec.end();
while(KFit != KFend && Fit != Fend)
{
// Step 1:分别取出属于同一node的ORB特征点
if(KFit->first == Fit->first)
{
...
KFit++;
Fit++;
}
else if(KFit->first < Fit->first)
{
// 对齐
KFit = vFeatVecKF.lower_bound(Fit->first);
}
else
{
// 对齐
Fit = F.mFeatVec.lower_bound(KFit->first);
}
}
- 对同一node,用
KF中地图点对应的ORB特征点与F中的ORB特征点两两匹配,其条件:- 不能重复匹配
vpMapPointMatches:如果vpMapPointMatches[realIdxF]非NULL,说明已有匹配了,则不能再匹配 - 最佳匹配距离小于阈值
TH_LOW - 最佳匹配距离与次佳匹配距离的比值小于阈值
mfNNratio
- 不能重复匹配
// second 是该node内存储的feature index
const vector<unsigned int> vIndicesKF = KFit->second;
const vector<unsigned int> vIndicesF = Fit->second;
// Step 2:遍历KF中属于该node的特征点
for(size_t iKF=0; iKF<vIndicesKF.size(); iKF++)
{
// 关键帧该节点中特征点的索引
const unsigned int realIdxKF = vIndicesKF[iKF];
// 取出KF中该特征对应的地图点
MapPoint* pMP = vpMapPointsKF[realIdxKF];
if(!pMP)
continue;
if(pMP->isBad())
continue;
// 取出关键帧KF中该特征对应的描述子
const cv::Mat &dKF= pKF->mDescriptors.row(realIdxKF);
int bestDist1=256; // 最好的距离(最小距离)
int bestIdxF =-1 ;
int bestDist2=256; // 次好距离(倒数第二小距离)
int bestDist1R=256;
int bestIdxFR =-1 ;
int bestDist2R=256;
// Step 3:遍历F中属于该node的特征点,寻找最佳匹配点
for(size_t iF=0; iF<vIndicesF.size(); iF++)
{
if(F.Nleft == -1){
// 这里的realIdxF是指普通帧该节点中特征点的索引
const unsigned int realIdxF = vIndicesF[iF];
// 如果地图点存在,说明这个点已经被匹配过了,不再匹配,加快速度
if(vpMapPointMatches[realIdxF])
continue;
// 取出普通帧F中该特征对应的描述子
const cv::Mat &dF = F.mDescriptors.row(realIdxF);
// 计算描述子的距离
const int dist = DescriptorDistance(dKF,dF);
// 遍历,记录最佳距离、最佳距离对应的索引、次佳距离等
// 如果 dist < bestDist1 < bestDist2,更新bestDist1 bestDist2
if(dist<bestDist1)
{
bestDist2=bestDist1;
bestDist1=dist;
bestIdxF=realIdxF;
}
// 如果bestDist1 < dist < bestDist2,更新bestDist2
else if(dist<bestDist2)
{
bestDist2=dist;
}
}
else{
const unsigned int realIdxF = vIndicesF[iF];
if(vpMapPointMatches[realIdxF])
continue;
const cv::Mat &dF = F.mDescriptors.row(realIdxF);
const int dist = DescriptorDistance(dKF,dF);
if(realIdxF < F.Nleft && dist<bestDist1){
bestDist2=bestDist1;
bestDist1=dist;
bestIdxF=realIdxF;
}
else if(realIdxF < F.Nleft && dist<bestDist2){
bestDist2=dist;
}
if(realIdxF >= F.Nleft && dist<bestDist1R){
bestDist2R=bestDist1R;
bestDist1R=dist;
bestIdxFR=realIdxF;
}
else if(realIdxF >= F.Nleft && dist<bestDist2R){
bestDist2R=dist;
}
}
}
// Step 4:根据阈值 和 角度投票剔除误匹配
// Step 4.1:第一关筛选:匹配距离必须小于设定阈值
if(bestDist1<=TH_LOW)
{
// Step 4.2:第二关筛选:最佳匹配比次佳匹配明显要好,那么最佳匹配才真正靠谱
if(static_cast<float>(bestDist1)<mfNNratio*static_cast<float>(bestDist2))
{
// Step 4.3:记录成功匹配特征点的对应的地图点(来自关键帧)
vpMapPointMatches[bestIdxF]=pMP;
// 这里的realIdxKF是当前遍历到的关键帧的特征点id
const cv::KeyPoint &kp =
(!pKF->mpCamera2) ? pKF->mvKeysUn[realIdxKF] :
(realIdxKF >= pKF -> NLeft) ? pKF -> mvKeysRight[realIdxKF - pKF -> NLeft]
: pKF -> mvKeys[realIdxKF];
// Step 4.4:计算匹配点旋转角度差所在的直方图
if(mbCheckOrientation)
{
cv::KeyPoint &Fkp =
(!pKF->mpCamera2 || F.Nleft == -1) ? F.mvKeys[bestIdxF] :
(bestIdxF >= F.Nleft) ? F.mvKeysRight[bestIdxF - F.Nleft]
: F.mvKeys[bestIdxF];
// 所有的特征点的角度变化应该是一致的,通过直方图统计得到最准确的角度变化值
float rot = kp.angle-Fkp.angle;
if(rot<0.0)
rot+=360.0f;
int bin = round(rot*factor);// 将rot分配到bin组, 四舍五入, 其实就是离散到对应的直方图组中
if(bin==HISTO_LENGTH)
bin=0;
assert(bin>=0 && bin<HISTO_LENGTH);
rotHist[bin].push_back(bestIdxF);
}
nmatches++;
}
if(bestDist1R<=TH_LOW)
{
if(static_cast<float>(bestDist1R)<mfNNratio*static_cast<float>(bestDist2R) || true)
{
vpMapPointMatches[bestIdxFR]=pMP;
const cv::KeyPoint &kp =
(!pKF->mpCamera2) ? pKF->mvKeysUn[realIdxKF] :
(realIdxKF >= pKF -> NLeft) ? pKF -> mvKeysRight[realIdxKF - pKF -> NLeft]
: pKF -> mvKeys[realIdxKF];
if(mbCheckOrientation)
{
cv::KeyPoint &Fkp =
(!F.mpCamera2) ? F.mvKeys[bestIdxFR] :
(bestIdxFR >= F.Nleft) ? F.mvKeysRight[bestIdxFR - F.Nleft]
: F.mvKeys[bestIdxFR];
float rot = kp.angle-Fkp.angle;
if(rot<0.0)
rot+=360.0f;
int bin = round(rot*factor);
if(bin==HISTO_LENGTH)
bin=0;
assert(bin>=0 && bin<HISTO_LENGTH);
rotHist[bin].push_back(bestIdxFR);
}
nmatches++;
}
}
}
}
- 旋转一致检测,剔除不一致的匹配
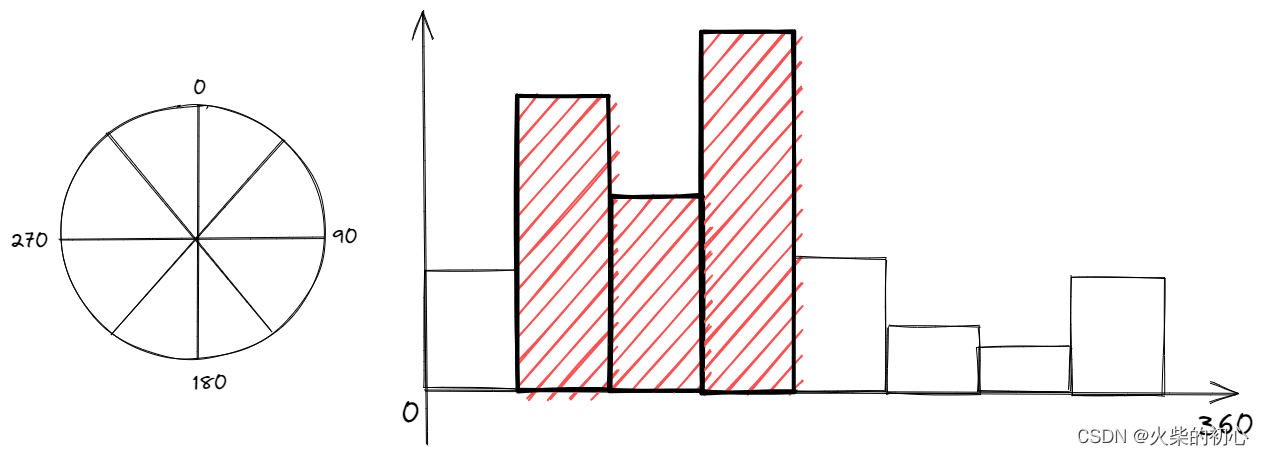
// Step 5 根据方向剔除误匹配的点
if(mbCheckOrientation)
{
// index
int ind1=-1;
int ind2=-1;
int ind3=-1;
// 筛选出在旋转角度差落在在直方图区间内数量最多的前三个bin的索引
ComputeThreeMaxima(rotHist,HISTO_LENGTH,ind1,ind2,ind3);
for(int i=0; i<HISTO_LENGTH; i++)
{
// 如果特征点的旋转角度变化量属于这三个组,则保留
if(i==ind1 || i==ind2 || i==ind3)
continue;
// 剔除掉不在前三的匹配对,因为他们不符合“主流旋转方向”
for(size_t j=0, jend=rotHist[i].size(); j<jend; j++)
{
vpMapPointMatches[rotHist[i][j]]=static_cast<MapPoint*>(NULL);
nmatches--;
}
}
}
3.将上一帧的位姿作为当前帧的位姿的初值
mCurrentFrame.mvpMapPoints = vpMapPointMatches;
mCurrentFrame.SetPose(mLastFrame.GetPose());
4.通过最小化重投影误差优化当前帧位姿
Optimizer::PoseOptimization(&mCurrentFrame);
参考ORB_SLAM3 TrackWithMotionModel中的PoseOptimization
5.剔除优化后匹配中的外点
int nmatchesMap = 0;
for(int i =0; i<mCurrentFrame.N; i++)
{
if(mCurrentFrame.mvpMapPoints[i])
{
// 如果对应到的某个特征点是外点
if(mCurrentFrame.mvbOutlier[i])
{
MapPoint* pMP = mCurrentFrame.mvpMapPoints[i];
mCurrentFrame.mvpMapPoints[i]=static_cast<MapPoint*>(NULL);
mCurrentFrame.mvbOutlier[i]=false;
if(i < mCurrentFrame.Nleft){
pMP->mbTrackInView = false;
}
else{
pMP->mbTrackInViewR = false;
}
pMP->mbTrackInView = false;
pMP->mnLastFrameSeen = mCurrentFrame.mnId;
nmatches--;
}
else if(mCurrentFrame.mvpMapPoints[i]->Observations()>0)
// 匹配的内点计数++
nmatchesMap++;
}
}