在AI内容生成领域,有三种常见的AI模型技术:GAN、VAE、Diffusion。其中,Diffusion是较新的技术,相关资料较为稀缺。VAE通常更多用于压缩任务,而GAN由于其问世较早,相关的开源项目和科普文章也更加全面,适合入门学习。
博主从入门和学习角度用Tensorflow跑通了DCGAN,本文对其进行记录以及分享。
1.简介
GAN(Generative Adversarial Network)是一种用于生成模型的机器学习框架。其原理基于两个主要组件:生成器(Generator)和判别器(Discriminator),二者通过对抗学习的方式相互竞争和提升。
从2014年左右发展至今,GAN目前有很多分支:
- GAN 朴素GAN,最原始版本
- DCGAN 卷积神经网络GAN
- CGAN 条件GAN,训练时传入额外条件,例如通过不同的mask区域生成不同内容,可控制的生成
- SeqGAN 使用GAN生成某些风格的句子,但不能进行对答
- Cycle GAN 可实现图像风格迁移,其实现略复杂
- 省略
2.原理介绍
先来看图
生成器(Generator)和判别器(Discriminator)是GAN的两个主要模型,生成器在上图中用缩写G表示,判别器用缩写D表示。
生成器G输入[N]的一维噪声,即InputNoise。输出[W * H * RGB](大致类似)的张量
判别器D输入一张图像,输出[1]的张量,即一个浮点数,通过0-1的值得到图像是真还是假
判别器需要尽可能的认出造假图片,生成器需要尽可能的骗过判别器,两者会在这2个目标上不断的通过反向传播进行学习,从而达到生成器和判别器的纳什均衡,最终输出质量很高的生成图像。
2.2 重点1
在训练中,判别器返回一个0-1区间的浮点数(如[0]=0.63,[0]=0.21)作为判断结果,值越高也越认为是真实图片。由于判别器也是一个神经网络模型,因此可以将输出层的梯度一直传递回输入层,然后将输入层的梯度作为生成器的梯度继续反向传播,从而完成一次训练。
然而,很多文章并没有提到这一点。如果没有接触过这种多模型梯度传递训练方法,可能会认为使用一个数学方法或者计算机视觉方法来构建判别器也可以让整个模型正常运行。但事实上,这种方法是不可行的(通常情况下)。
2.3 重点2
使用更多的层可以增强模型的推理能力。例如,在训练过程中,如果模型生成出眉毛 A 的特征,则有鼻子 B、C 和 D 相关的备选项;而如果生成出眉毛 E 的特征,则有鼻子 F 和 G 相关的备选项。
这也是为什么生成器需要使用三个隐层的原因(博主的观点)。通过增加隐层的数量,模型可以捕捉到更多的特征和抽象概念,从而提高生成器的表现能力和推理能力。更深层次的网络结构能够帮助模型学习更复杂的模式和关联,使其在生成结果时更加准确和多样化。
上图生成器部分的激活函数用的是LeakyReLU,实际上就单隐层神经网络来说,ReLU要比Sigmoid能多解决很多类型问题,Sigmoid更适合分类问题,遇到一些奇怪的问题不容易收敛,而LeakyReLU激活函数即和ReLU逻辑一样也可以返回负数信息,这是博主觉得采用这个激活函数的原因。
而至于tanH和Sigmoid的比较,它们在某种程度上相似。一般来说,网上普遍认为tanH比Sigmoid更好,主要原因是它具有较窄的数值边界范围。
2.4 重点3
对于2套样本比较损失这类问题,一般使用二分类交叉熵,这不同于分类问题。
而二分类交叉熵又是在只有2种结果(r和1-r),的情况下对公式进行的简化:
https://blog.csdn.net/grayrail/article/details/131619144
2.5 模式崩溃
训练时还会出现一种情况,即生成器始终卡在一个生成结果上,比如生成0-9数字,结果训练几轮后始终在生成数字3。
这种情况称为模式崩溃,一般增加训练样本数量并调节参数,没有比较好的办法。
3.实践准备
python库下载使用国内镜像源:
https://zhuanlan.zhihu.com/p/477179822
使用方式:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspider
github库下载耽误时间,可以缓存到gitee:

而gitee也有自己缓存好的镜像库,可以先去这里查:
https://gitcode.net/mirrors
python库查找:
https://pypi.org/
在pip中查找python库:
先 pip install pip-search 再使用命令 pip_search 搜索
4.实践
全连接神经网络版本的朴素GAN效果相对较差,而DCGAN(Deep Convolutional GAN)是卷积神经网络版本的GAN,下面以DCGAN为例使用Tensorflow进行实现:
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras import layers
# 定义生成器模型
def build_generator():
model = tf.keras.Sequential()
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256) # 注意:batch size 没有限制
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
# 定义判别器模型
def build_discriminator():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same',
input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
# 定义生成器和判别器
generator = build_generator()
discriminator = build_discriminator()
# 定义损失函数
loss_fn = tf.keras.losses.BinaryCrossentropy(from_logits=True)
# 定义生成器和判别器的优化器
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
def generator_loss(fake_output):
return loss_fn(tf.ones_like(fake_output), fake_output)
def discriminator_loss(real_output, fake_output):
real_loss = loss_fn(tf.ones_like(real_output), real_output)
fake_loss = loss_fn(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
# 定义训练循环
@tf.function
def train_step(images):
# 生成噪声向量
noise = tf.random.normal([BATCH_SIZE, 100])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
# 使用生成器生成假图片
generated_images = generator(noise, training=True)
# 使用判别器判断真假图片
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
# 计算损失函数
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
# 计算梯度并更新生成器和判别器的参数
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
def generate_and_save_images(model, epoch, test_input):
predictions = model(test_input, training=False)
print("predictions.shape:", predictions.shape)
num_images = predictions.shape[0]
rows = int(num_images ** 0.5) # 计算行数
cols = num_images // rows # 计算列数
fig = plt.figure(figsize=(8, 8))
for i in range(num_images):
plt.subplot(rows, cols, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
#plt.show()
# 加载MNIST数据集
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
# 标准化数据
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5
# 批量大小与训练次数
BATCH_SIZE = 256
EPOCHS = 50
# 数据集切分为批次并进行训练
dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(60000).batch(BATCH_SIZE)
for epoch in range(EPOCHS):
for i,image_batch in enumerate(dataset):
print("sub i",i)
train_step(image_batch)
print("------------------------------------------------------epoch:", epoch)
# 每个 epoch 结束后生成并保存一组图像
if (epoch + 1) % 5 == 0:
seed = tf.random.normal([BATCH_SIZE, 100])
generate_and_save_images(generator, epoch + 1, seed)
跑一阵子MNIST数据集后,结果如下:
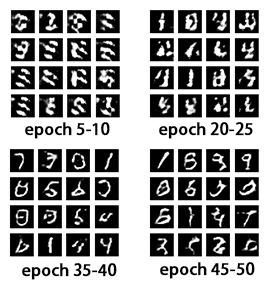
参考:
论文精读: https://www.bilibili.com/video/BV1rb4y187vD
同济子豪兄精读版本: https://www.bilibili.com/video/BV1oi4y1m7np