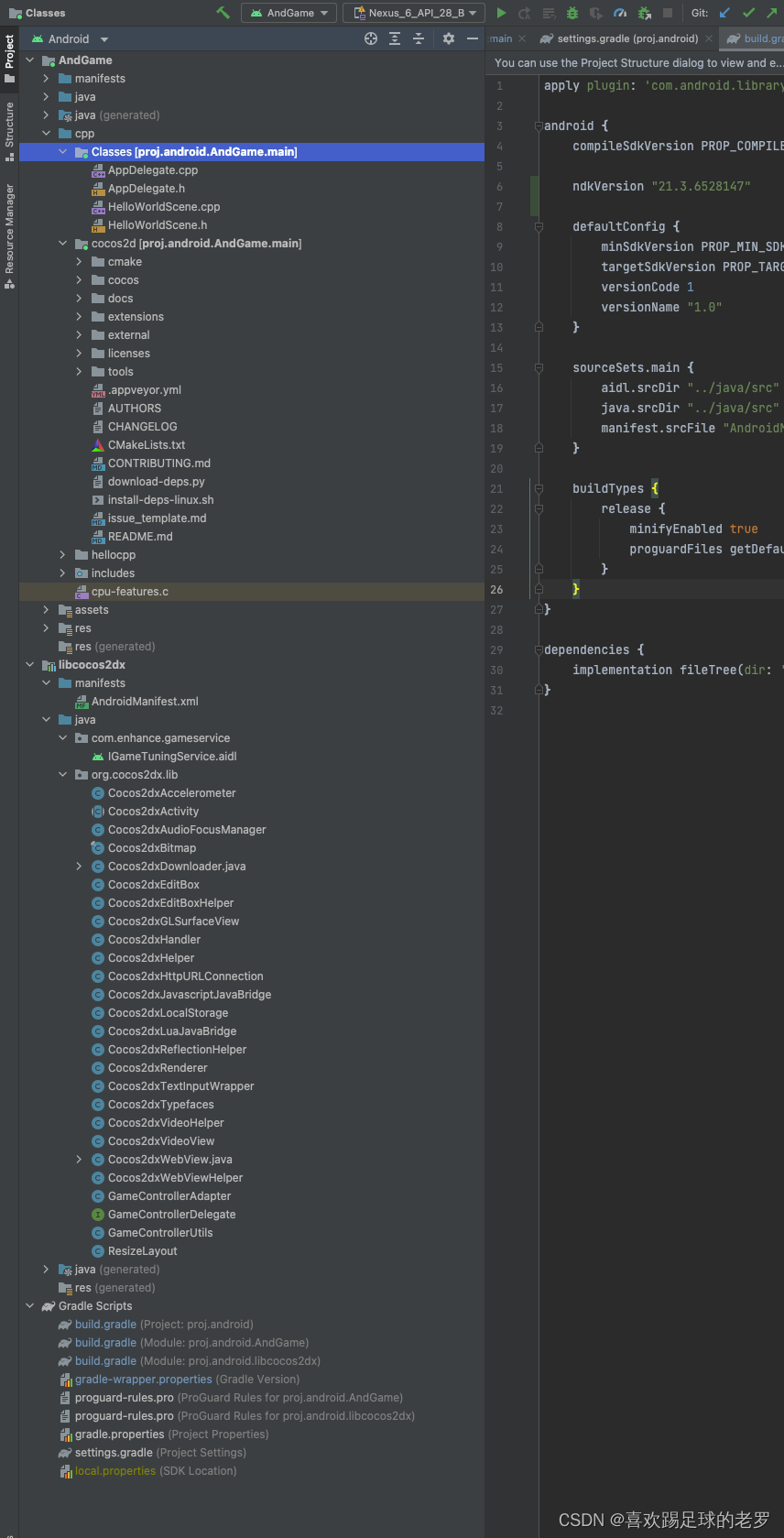
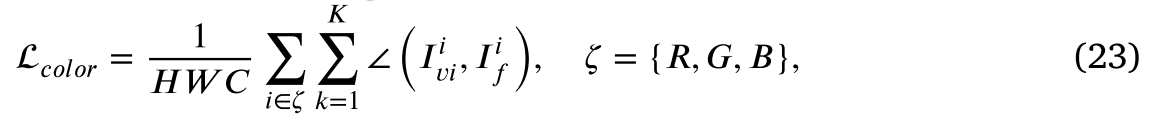code link: https://github.com/openai/guided-diffusion.
文章目录
- Overview
- What problem is addressed in the paper?
- What is the key to the solution?
- What is the main contribution?
- Potential fundamental flaws; how this work can be improved?
- Contents
- Diffusion model
- 背景
- 延用改进
- 采样品质标准
- 架构改进
- Classifer guidance
- Conditional Reverse Noising Process
- Conditional Sampling for DDIM
- Scaling Classifier Gradients
- Results
- Limitations
- Conclusion
Overview
What problem is addressed in the paper?
We show that diffusion models can achieve image sample quality superior to the current state-of-the-art generative models.
What is the key to the solution?
we further improve sample quality with classifier guidance
What is the main contribution?
We achieve an FID of 2.97 on ImageNet 128×128, 4.59 on ImageNet 256×256, and 7.72 on ImageNet 512×512, and we match BigGAN-deep even with as few as 25 forward passes per sample, all while maintaining better coverage of the distribution.
Finally, we find that classifier guidance combines well with upsampling diffusion models, further improving FID to 3.94 on ImageNet 256×256 and 3.85 on ImageNet 512×512. W
Potential fundamental flaws; how this work can be improved?
The samples from the single step model are not yet competitive with GANs。
In the future, our method could be extended to unlabeled data by clustering samples to produce synthetic labels [ 36] or by training discriminative models to predict when samples are in the true data distribution or from the sampling distribution.
Contents
Diffusion model
扩散模型是一类基于可能性的模型,最近被证明可以产生高质量的图像[56,59,25],同时提供理想的属性,如分布覆盖、固定的训练目标和易于扩展。这些模型通过从信号中逐渐去除噪声来生成样本,其训练目标可以表示为重加权变分下界[25]。
我们假设扩散模型和GANs之间的差距源于至少两个因素:
- 首先,最近的GAN文献中使用的模型架构已经被大量探索和改进;
- 第二,GANs能够在多样性和保真度之间进行权衡,产生高质量的样本,但不能覆盖整个分布。
目标:
- 改进模型架构,
- 通过设计一个方案来权衡多样性和保真度。
通过这些改进,我们实现了新的最先进的技术,在几个不同的指标和数据集上超过了GANs。
背景
在高水平上,扩散模型通过逆转一个逐渐的噪声过程从分布中取样。特别地,采样从噪声xT开始,并产生噪声逐渐减少的样本xT−1,xT−2,…直到最终样本x0。每个时间步长t对应一定的噪声水平,而xt可以被认为是信号x0与一些噪声的混合物,其中的信噪比由时间步长t决定。在本文的其余部分,我们假设噪声来自一个对角高斯分布,这对自然图像很好,并简化了各种推导。
在DDPM的基础上,模型可以被参数化为 ,表示预测样本xt 对应的t时刻的噪音。
,表示预测样本xt 对应的t时刻的噪音。
为了训练模型,通过随机采样
x
0
,
t
x_0,t
x0,t噪音产生样本,他们共同产生一个有噪音的样本xt,训练的目标是 ,也就是真实噪声和预测噪声之间的简单均方误差损失。具体如下:
,也就是真实噪声和预测噪声之间的简单均方误差损失。具体如下:

DDPM在合理的假设下,将给定xt情况下xt-1的分布 建模对数高斯
建模对数高斯 ,其中,均值
,其中,均值 可以通过计算
可以通过计算 得到。具体如下:
得到。具体如下:

方差则被固定为一个已知常数。
延用改进
最近的几篇论文提出了对扩散模型的改进。在这里,我们描述了一些用于我们的模型的改进。
【43】认为,固定方差在扩散步骤较少的时候是一个次优的方案,并且提出了参数化方差。

其中v是一个神经网络的输出。两个
β
\beta
β的定义来源于DDPM,具体的,


【43】还提出了一个加权loss的训练,混合训练方差和权重。
用混合目标学习反向过程方差可以使抽样步骤更少而样品质量没有很大下降。我们采用了这个目标和参数化,并在整个实验中使用它。
DDIM 制定了一个替代的非马尔可夫噪声过程,具有与DDPM相同的正向边缘,但允许通过改变反向噪声的方差产生不同的反向采样器。通过将该噪声设置为0,他们提供了一种将任何模型转换为从潜在对象到图像的确定性映射的方法,并发现这提供了一种步骤更少的抽样替代方法。当使用少于50个抽样步骤时,我们采用这种抽样方法
采样品质标准
- IS:它衡量了一个模型捕获完整ImageNet类分布的程度,同时仍然生成单个样本,这些样本是单个类的令人信服的示例。这个指标的一个缺点是,它不能覆盖整个分布或捕获类内的多样性,并且记住完整数据集的一小部分的模型仍然具有较高的is
- FID:提供了Inception-V3[62]潜空间中两个图像分布之间距离的对称度量。
- sFID:使用空间特征而不是标准集合特征的FID版本。他们发现,这种度量可以更好地捕捉空间关系,以连贯的高层结构奖励图像分布。
- 改进的精度和召回度量,以分别测量样本保真度(作为落入数据歧管的模型样本的分数(精度))和多样性(作为落入样本歧管的数据样本的分数)(召回)
我们使用FID作为总体样本质量比较的默认度量,因为它同时捕捉多样性和保真度,并且已经成为最先进生成建模工作的事实标准度量。我们使用精度或IS来测量保真度,使用召回来测量多样性或分布覆盖率。
架构改进
DDPM 架构:
UNet模型使用残差层和下采样卷积的堆栈,然后使用上采样卷积的残差层堆栈,并使用跳跃连接连接具有相同空间大小的层。此外,他们使用具有单个头部的16×16分辨率的全局关注层,并将时间步长嵌入的投影添加到每个残差块中。
我们探讨了以下架构更改:
- 增加深度与宽度,保持模型尺寸相对恒定。
- 增加关注点的数量。
- 在32×32、16×16和8×8分辨率下使用注意力,而不是仅在16×16分辨率下使用。
- 使用BigGAN[5]残差块对激活进行上采样和下采样,遵循[60]。
- 重新缩放剩余连接√2,遵循[60,27,28]。
在本文的其余部分中,我们使用这个最终改进的模型架构作为我们的默认:可变宽度,每个分辨率有2个残差块,多个磁头,每个磁头有64个通道,32、16和8分辨率的注意力,用于上采样和下采样的BigGAN残差块,以及用于将时间步长和类嵌入到残差块中的自适应组标准化。
Classifer guidance
具体的,我们在噪音样本xt上训练一个分类器 ,并且用梯度
,并且用梯度 来引导diffusion sampling process想任意标签类别y靠近。
来引导diffusion sampling process想任意标签类别y靠近。
为了简洁表达: 注意,对于每个时间步t,它们指的是单独的函数,并且在训练时,模型必须以输入t为条件。
注意,对于每个时间步t,它们指的是单独的函数,并且在训练时,模型必须以输入t为条件。
Conditional Reverse Noising Process
unconditional reverse noising process 。
。
加上条件y之后,

其中Z是常数项,算法1总结了相应的采样算法。

Conditional Sampling for DDIM
我们把上述过程称为stochastic diffusion sampling process(随机扩散采样过程),conditional sampling 也可用于deterministic sampling methods like DDIM(确定性扩散采样过程)。
如果我们有一个模型 来预测添加到样本中的噪声,那么这可以用来推导得分函数:
来预测添加到样本中的噪声,那么这可以用来推导得分函数:

带入 后
后

最后,我们可以定义对应于联合分布得分的新的预测 :
:

算法2总结了相应的采样算法:

Scaling Classifier Gradients

 当s>1时,此分布变得比p(y|x)更尖锐,因为较大的值会被指数放大。换言之,使用更大的梯度尺度更侧重于分类器的模式,这对于产生更高保真度(但不太多样化)的样本是潜在的期望。
当s>1时,此分布变得比p(y|x)更尖锐,因为较大的值会被指数放大。换言之,使用更大的梯度尺度更侧重于分类器的模式,这对于产生更高保真度(但不太多样化)的样本是潜在的期望。
在上述推导中,我们假设基础扩散模型是无条件的,即p(x)模型。也可以训练条件扩散模型p(x|y),并以完全相同的方式使用分类器指导。表4显示,无条件和有条件模型的样本质量都可以通过分类器指导大大提高。我们看到,在足够高的尺度下,引导无条件模型可以非常接近非引导条件模型的FID,尽管直接使用类标签进行训练仍然有帮助。指导条件模型进一步改进FID。

Results


Limitations
- 采样时仍比GAN慢
- 我们提出的分类器引导技术目前仅限于标记的数据集,并且我们没有提供有效的策略来权衡未标记数据集的多样性和保真度。未来,我们的方法可以通过聚类样本以产生合成标签[36]或通过训练判别模型来预测样本何时处于真实数据分布或来自采样分布,从而扩展到未标记的数据。
Conclusion
我们已经表明,扩散模型是一类具有固定训练目标的基于似然的模型,可以获得比最先进的GAN更好的样本质量。我们改进的架构足以在无条件图像生成任务上实现这一点,而我们的分类器引导技术允许我们在类条件任务上做到这一点。在后一种情况下,我们发现可以调整分类器梯度的比例,以平衡多样性和保真度。这些引导扩散模型可以减少GAN和扩散模型之间的采样时间间隔,尽管扩散模型在采样期间仍然需要多次正向通过。最后,通过将引导与上采样相结合,我们可以进一步提高高分辨率条件图像合成的样本质量。