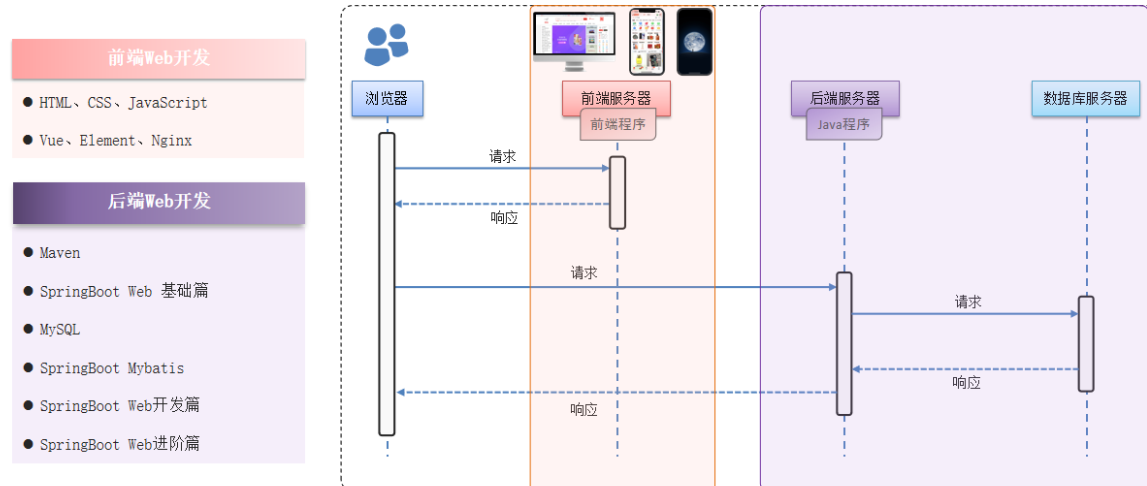
一、安装python
例如,安装路径为:C:\rtkapp\python-3.8.0
二、安装opencv

三、安装tesseract-ocr
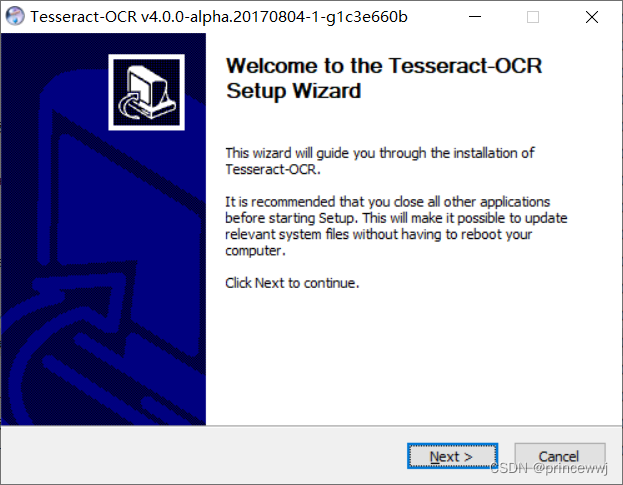
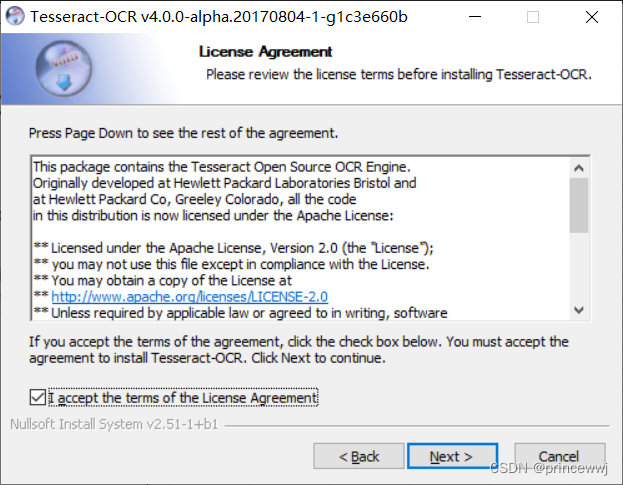


安装完成后,在系统环境变量path中,添加安装路径C:\rtkapp\Tesseract-OCR
四、打开python安装pytesseract

五、安装java运行环境
例如,安装版本为:jdk-8u191-windows-x64

添加和配置系统环境变量



六、安装jTessBoxEditor
例如,安装版本为:jTessBoxEditor1.5
七、打开jTesseBoxEditor为编辑汉字设置字体为宋体

八、用jTesBoxEditor合并选择的图片文件sample1.png
保存结果如图:

九、用命令生成box文件
例如,图片文件为:fmc.font.exp1.tif
运行命令为:tesseract.exe -l chi_sim fmc.font.exp1.tif fmc.font.exp1 batch.nochop makebox
生成的box文件为:fmc.font.exp1.box

十、浏览打开图片文件fmc.font.exp1.tif
用Box View调整X、Y、W、H使汉字正好在方框内,如汉字识别错误,在Char栏修改即可,
全部完成后,按Save保存即可,如下图:

十一、运行下面python脚本生成自定字库fmc.traineddata
import os
import cv2
import time
import pytesseract
import numpy as np
import subprocess
from PIL import Image
#Change work path
workpath="C:\\picdata";
curpath=os.getcwd();
os.chdir(workpath);
#Create a default font properties file
strcmd="echo normal 0 0 0 0 0>font_properties";
print(workpath+">"+strcmd);
print(subprocess.getoutput(strcmd)+"\n");
#Run tesseract for training
strcmd="tesseract.exe -l chi_sim fmc.font.exp1.tif fmc.font.exp1 nobatch box.train";
print(workpath+">"+strcmd);
print(subprocess.getoutput(strcmd)+"\n");
#Compute the character set
strcmd="unicharset_extractor.exe fmc.font.exp1.box";
print(workpath+">"+strcmd);
print(subprocess.getoutput(strcmd)+"\n");
strcmd="mftraining -F font_properties -U unicharset -O fmc.unicharset fmc.font.exp1.tr ";
print(workpath+">"+strcmd);
print(subprocess.getoutput(strcmd)+"\n");
#Run clustering
strcmd="cntraining.exe fmc.font.exp1.tr";
print(workpath+">"+strcmd);
print(subprocess.getoutput(strcmd)+"\n");
#Rename files
strcmd="move normproto fmc.normproto";
print(workpath+">"+strcmd);
print(subprocess.getoutput(strcmd)+"\n");
strcmd="move inttemp fmc.inttemp";
print(workpath+">"+strcmd);
print(subprocess.getoutput(strcmd)+"\n");
strcmd="move pffmtable fmc.pffmtable";
print(workpath+">"+strcmd);
print(subprocess.getoutput(strcmd)+"\n");
strcmd="move shapetable fmc.shapetable";
print(workpath+">"+strcmd);
print(subprocess.getoutput(strcmd)+"\n");
#Create tessdata
strcmd="combine_tessdata.exe fmc";
print(workpath+">"+strcmd);
print(subprocess.getoutput(strcmd)+"\n");
tessdata_path="";
strpath=os.getenv("path").split(";");
for kkk in strpath:
if kkk.lower().find("tesseract")>0:
tessdata_path=kkk+"\\tessdata";
break;
#Copy tessdata
print(tessdata_path);
#Create Tessdata
if len(tessdata_path)>0:
strcmd="copy fmc.traineddata "+tessdata_path;
print(workpath+">"+strcmd);
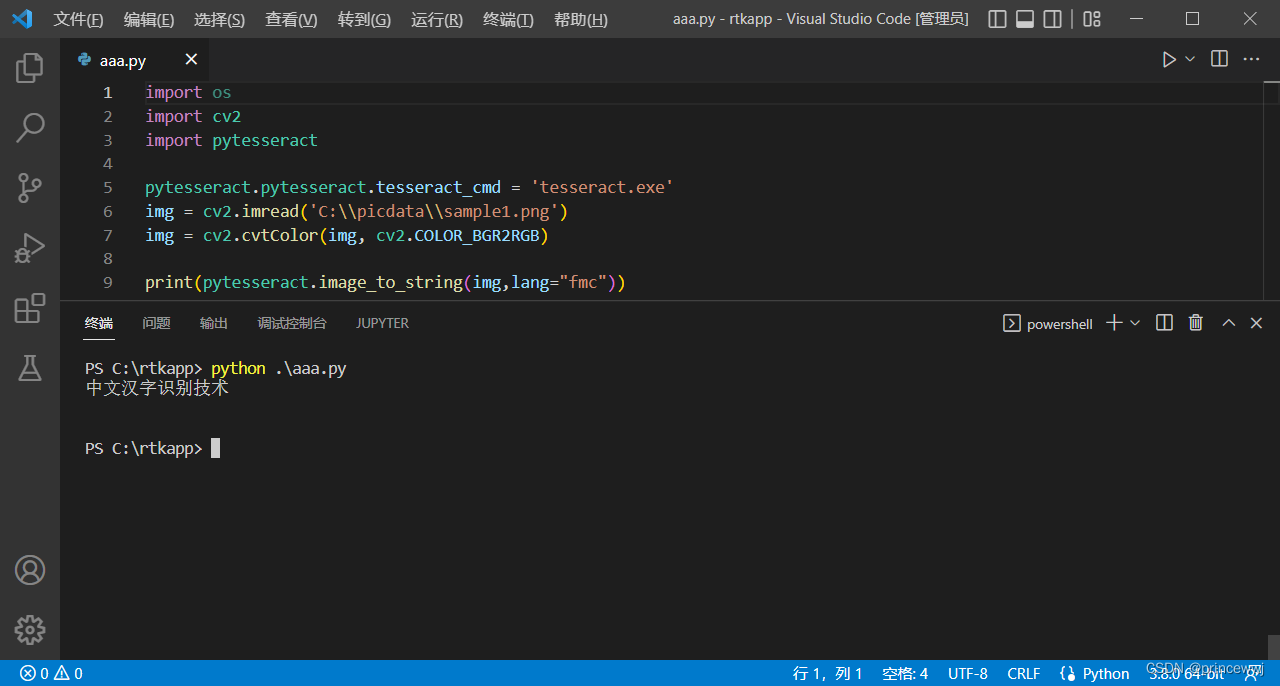
print(subprocess.getoutput(strcmd)+"\n");十二、用生成的自定义字库fmc识别图片汉字
import os
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd = 'tesseract.exe'
img = cv2.imread('C:\\picdata\\sample1.png')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
print(pytesseract.image_to_string(img,lang="fmc"))运行结果如下: