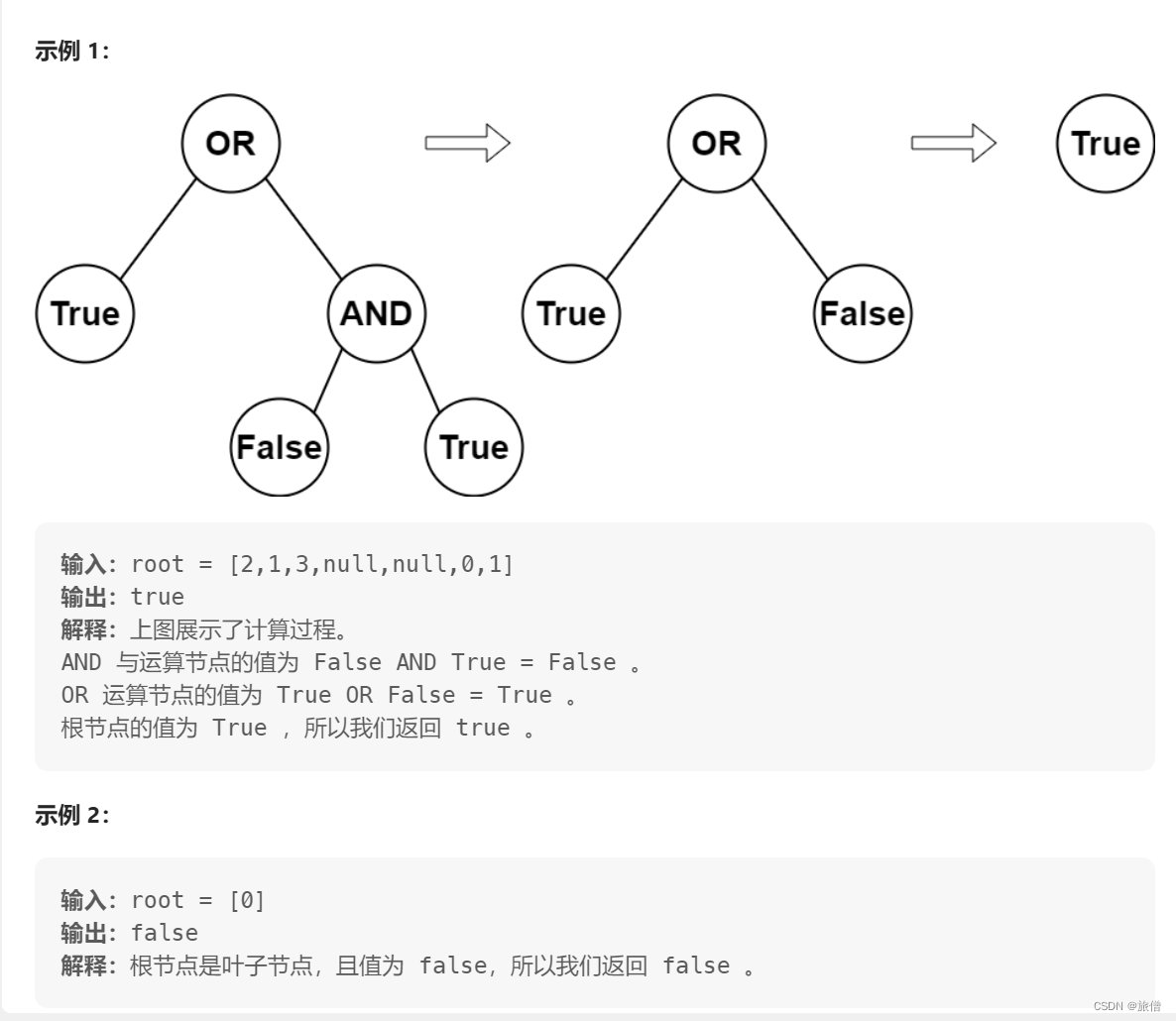
一个典型的CUDA编程结构包括5个主要步骤。
- 分配GPU内存。
- 从CPU内存中拷贝数据到GPU内存。
- 调用CUDA内核函数来完成程序指定的运算。
- 将数据从GPU拷回CPU内存。
- 释放GPU内存空间。
这里先理一理如何分配gpu内存。
目录
1. 内存管理函数
1.1 分别内存
1.2 数据拷贝
2. gpu内存结构
3. 小栗子
1. 内存管理函数
4种内存管理函数,用途和标准的c语言可以一一对应。区别就是一个在cpu上管理分配和释放,一个是在gpu上操作。

1.1 分别内存
cudaError_t cudaMalloc (void** devPtr, size_t size)设备端(gpu)分配size字节的线性内存。
1.2 数据拷贝
cudaError_t cudaMemcpy(void* dst, const void* src, size_t count, cudaMemcpyKind kind)这里的数据拷贝,用来在主机端和设备端之间传输count字节数据。传输方向由kind指定,kind有以下4种。

这个函数以同步方式执行,因为在cudaMemcpy函数返回以及传输操作完成之前主机应用程序是阻塞的。
其中,可以将上面返回的cudaError_t解释成可读的错误信息。
char* cudaGetErrorString(cudaError_t e)该功能和c语言的strerror类似。
2. gpu内存结构

gpu中最主要的两种内存是全局内存和共享内存。全局内存类似于cpu中的系统内存,而共享内存类似于cpu缓存。
3. 小栗子
功能:数组a中数字和数组b相加,存放到数组c
3.1 纯c编写(只在cpu上相加)
#include <time.h>
#include <stdlib.h> // srand
// cpu
void sumArraysOnHost(float* a, float* b, float* c, const int N)
{
for (int i = 0; i < N; i++)
{
c[i] = a[i] + b[i];
}
}
void initialData(float* p, const int N)
{
//generate different seed from random number
time_t t;
srand((unsigned int)time(&t)); // 生成种子
for (int i = 0; i < N; i++)
{
p[i] = (float)(rand() & 0xFF) / 10.0f; // 随机数
}
}
int main(void)
{
// 1 分配内存
int nElem = 1024;
size_t nBytes = nElem * sizeof(nElem);
float* h_a, * h_b, * h_c;
h_a = (float*)malloc(nBytes);
h_b = (float*)malloc(nBytes);
h_c = (float*)malloc(nBytes);
// 初始化
initialData(h_a, nElem);
initialData(h_b, nElem);
// 2 直接在cpu上相加
sumArraysOnHost(h_a, h_b, h_c, nElem);
// 3 释放内存
free(h_a);
free(h_b);
free(h_c);
return 0;
}3.2 cuda编写(在gpu上相加)
将相加操作放到gpu上操作。下面是完整典型的cuda编程结构。
3.2.1 线程层次结构
线程层次结构。一个grid包含很多块Block,一个Block包含很多Thread.

由一个内核启动所产生的所有线程统称为一个网格。同一网格中的所有线程共享相同的全局内存空间(相当于系统内存)。blockIdx(线程块在线程格内的索引),threadIdx(块内的线程索引)。
当执行一个核函数时,CUDA运行时为每个线程分配坐标变量blockIdx和threadIdx(自动生成的变量)。
3.2.2 定义
定义块的尺寸,并基于块和数据的大小计算网格尺寸。比如有6个数据
int nElem = 6;
// 定义一维数组线程块
dim3 block(3); // 块内有3个线程组
// 定义一维数组网格. 有两个块。即网格大小是块大小的倍数。
dim3 grid((nElem + block.x - 1) / block.x); // (6+3-1)/3 = 2注意:网格大小是块大小的倍数。因为块大小*网格大小 == 数据个数。
待续。。。
![[每日习题] 完全数计算 扑克牌大小 ——牛客习题](https://img-blog.csdnimg.cn/a7b5574efe99464797d2d4645d49545c.png)