目录
- 前言
- 1. CNN分类器
- 2. 补充知识
- 2.1 知识点
- 2.2 智能指针封装
- 总结
前言
杜老师推出的 tensorRT从零起步高性能部署 课程,之前有看过一遍,但是没有做笔记,很多东西也忘了。这次重新撸一遍,顺便记记笔记。
本次课程学习 tensorRT 高级-第一个完整的分类器程序
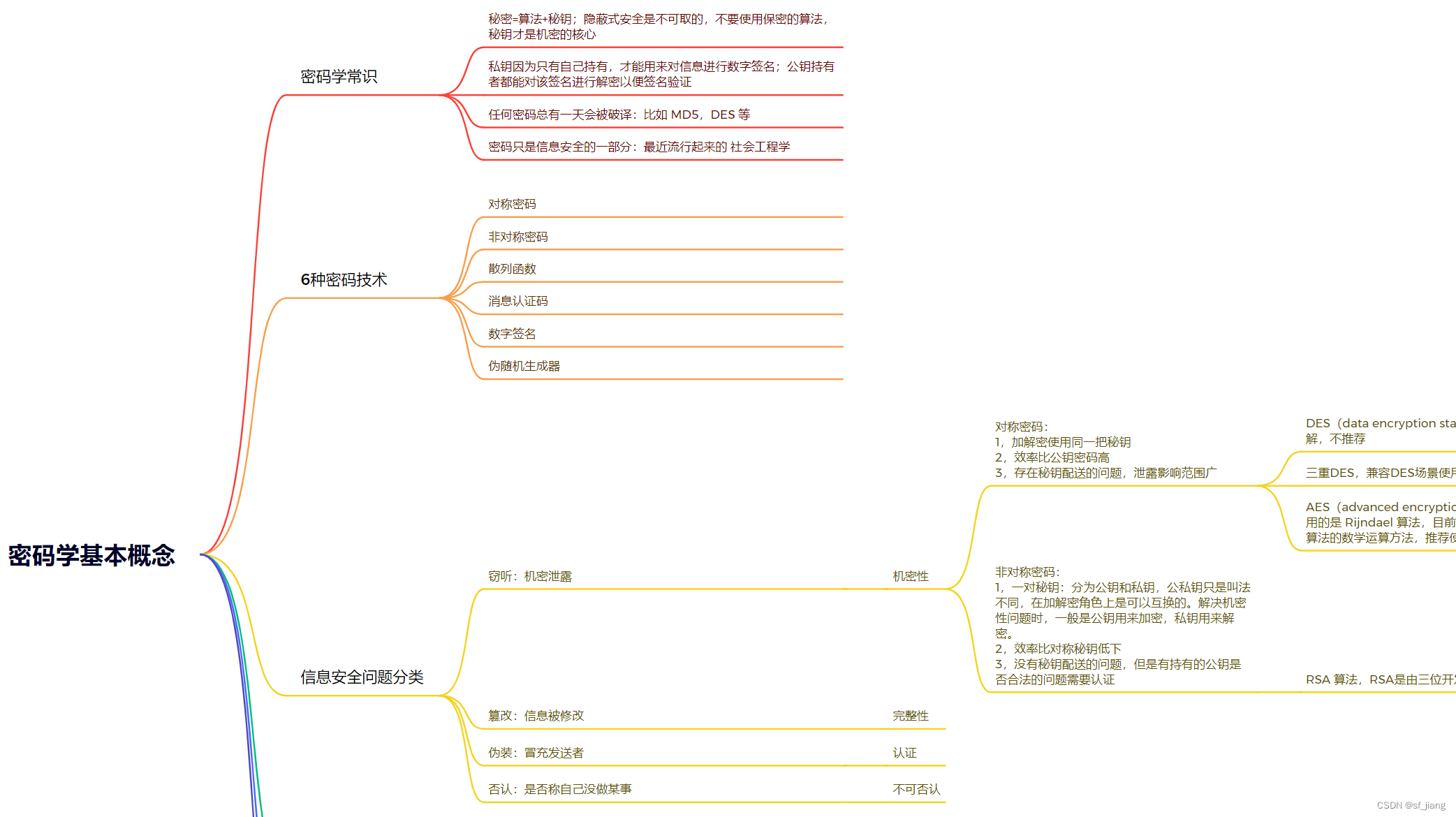
课程大纲可看下面的思维导图

1. CNN分类器
这节课我们学习 tensorRT 高级篇案例——CNN分类器
先来看下代码,gen_onnx.py 是推理一个 resnet18 的 ImageNet 分类器模型,打印其推理结果,并导出 onnx 模型,其具体内容如下:
import torch
import torchvision
import cv2
import numpy as np
class Classifier(torch.nn.Module):
def __init__(self):
super().__init__()
#使用torchvision自带的与训练模型, 更多模型请参考:https://tensorvision.readthedocs.io/en/master/
self.backbone = torchvision.models.resnet18(pretrained=True)
def forward(self, x):
feature = self.backbone(x)
probability = torch.softmax(feature, dim=1)
return probability
# 对每个通道进行归一化有助于模型的训练
imagenet_mean = [0.485, 0.456, 0.406]
imagenet_std = [0.229, 0.224, 0.225]
image = cv2.imread("workspace/dog.jpg")
image = cv2.resize(image, (224, 224)) # resize
image = image[..., ::-1] # BGR -> RGB
image = image / 255.0
image = (image - imagenet_mean) / imagenet_std # normalize
image = image.astype(np.float32) # float64 -> float32
image = image.transpose(2, 0, 1) # HWC -> CHW
image = np.ascontiguousarray(image) # contiguous array memory
image = image[None, ...] # CHW -> 1CHW
image = torch.from_numpy(image) # numpy -> torch
model = Classifier().eval()
with torch.no_grad():
probability = model(image)
predict_class = probability.argmax(dim=1).item()
confidence = probability[0, predict_class]
labels = open("workspace/labels.imagenet.txt").readlines()
labels = [item.strip() for item in labels]
print(f"Predict: {predict_class}, {confidence}, {labels[predict_class]}")
dummy = torch.zeros(1, 3, 224, 224)
torch.onnx.export(
model, (dummy,), "workspace/classifier.onnx",
input_names=["image"],
output_names=["prob"],
dynamic_axes={"image": {0: "batch"}, "prob": {0: "batch"}},
opset_version=11
)
我们使用的 resnet18 来自于 torchvision.models,它的输出值并不是一个概率值,需要再加上一个 softmax 函数才行,因此我们自己实现了一个类顺便把 softmax 操作也添加进去,减少后处理的复杂度,导出的 onnx 包含后处理直接输出概率值
接下来就是对输入图像进行预处理操作,得到一个 image 的 tensor 放到网络中推理,前面有提到图像预处理的操作可以用 warpAffine 来实现,一个核函数解决所有操作,使得其性能足够高,效果足够好
值的注意的是,在 onnx 导出时有两个细节,一个是输入和输出的动态维度都只指定 batch 动态,宽高不动态,另一个是 optset 的版本指定为 11
运行效果如下:

我们接下来到 C++ 里面看下 tensorRT 是怎么处理 CNN 分类器的推理过程的,代码如下:
// tensorRT include
// 编译用的头文件
#include <NvInfer.h>
// onnx解析器的头文件
#include <onnx-tensorrt/NvOnnxParser.h>
// 推理用的运行时头文件
#include <NvInferRuntime.h>
// cuda include
#include <cuda_runtime.h>
// system include
#include <stdio.h>
#include <math.h>
#include <iostream>
#include <fstream>
#include <vector>
#include <memory>
#include <functional>
#include <unistd.h>
#include <chrono>
#include <opencv2/opencv.hpp>
using namespace std;
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
inline const char* severity_string(nvinfer1::ILogger::Severity t){
switch(t){
case nvinfer1::ILogger::Severity::kINTERNAL_ERROR: return "internal_error";
case nvinfer1::ILogger::Severity::kERROR: return "error";
case nvinfer1::ILogger::Severity::kWARNING: return "warning";
case nvinfer1::ILogger::Severity::kINFO: return "info";
case nvinfer1::ILogger::Severity::kVERBOSE: return "verbose";
default: return "unknow";
}
}
class TRTLogger : public nvinfer1::ILogger{
public:
virtual void log(Severity severity, nvinfer1::AsciiChar const* msg) noexcept override{
if(severity <= Severity::kINFO){
// 打印带颜色的字符,格式如下:
// printf("\033[47;33m打印的文本\033[0m");
// 其中 \033[ 是起始标记
// 47 是背景颜色
// ; 分隔符
// 33 文字颜色
// m 开始标记结束
// \033[0m 是终止标记
// 其中背景颜色或者文字颜色可不写
// 部分颜色代码 https://blog.csdn.net/ericbar/article/details/79652086
if(severity == Severity::kWARNING){
printf("\033[33m%s: %s\033[0m\n", severity_string(severity), msg);
}
else if(severity <= Severity::kERROR){
printf("\033[31m%s: %s\033[0m\n", severity_string(severity), msg);
}
else{
printf("%s: %s\n", severity_string(severity), msg);
}
}
}
} logger;
// 通过智能指针管理nv返回的指针参数
// 内存自动释放,避免泄漏
template<typename _T>
shared_ptr<_T> make_nvshared(_T* ptr){
return shared_ptr<_T>(ptr, [](_T* p){p->destroy();});
}
bool exists(const string& path){
#ifdef _WIN32
return ::PathFileExistsA(path.c_str());
#else
return access(path.c_str(), R_OK) == 0;
#endif
}
// 上一节的代码
bool build_model(){
if(exists("engine.trtmodel")){
printf("Engine.trtmodel has exists.\n");
return true;
}
TRTLogger logger;
// 这是基本需要的组件
auto builder = make_nvshared(nvinfer1::createInferBuilder(logger));
auto config = make_nvshared(builder->createBuilderConfig());
auto network = make_nvshared(builder->createNetworkV2(1));
// 通过onnxparser解析器解析的结果会填充到network中,类似addConv的方式添加进去
auto parser = make_nvshared(nvonnxparser::createParser(*network, logger));
if(!parser->parseFromFile("classifier.onnx", 1)){
printf("Failed to parse classifier.onnx\n");
// 注意这里的几个指针还没有释放,是有内存泄漏的,后面考虑更优雅的解决
return false;
}
int maxBatchSize = 10;
printf("Workspace Size = %.2f MB\n", (1 << 28) / 1024.0f / 1024.0f);
config->setMaxWorkspaceSize(1 << 28);
// 如果模型有多个输入,则必须多个profile
auto profile = builder->createOptimizationProfile();
auto input_tensor = network->getInput(0);
auto input_dims = input_tensor->getDimensions();
// 配置最小、最优、最大范围
input_dims.d[0] = 1;
profile->setDimensions(input_tensor->getName(), nvinfer1::OptProfileSelector::kMIN, input_dims);
profile->setDimensions(input_tensor->getName(), nvinfer1::OptProfileSelector::kOPT, input_dims);
input_dims.d[0] = maxBatchSize;
profile->setDimensions(input_tensor->getName(), nvinfer1::OptProfileSelector::kMAX, input_dims);
config->addOptimizationProfile(profile);
auto engine = make_nvshared(builder->buildEngineWithConfig(*network, *config));
if(engine == nullptr){
printf("Build engine failed.\n");
return false;
}
// 将模型序列化,并储存为文件
auto model_data = make_nvshared(engine->serialize());
FILE* f = fopen("engine.trtmodel", "wb");
fwrite(model_data->data(), 1, model_data->size(), f);
fclose(f);
// 卸载顺序按照构建顺序倒序
printf("Done.\n");
return true;
}
///
vector<unsigned char> load_file(const string& file){
ifstream in(file, ios::in | ios::binary);
if (!in.is_open())
return {};
in.seekg(0, ios::end);
size_t length = in.tellg();
std::vector<uint8_t> data;
if (length > 0){
in.seekg(0, ios::beg);
data.resize(length);
in.read((char*)&data[0], length);
}
in.close();
return data;
}
vector<string> load_labels(const char* file){
vector<string> lines;
ifstream in(file, ios::in | ios::binary);
if (!in.is_open()){
printf("open %d failed.\n", file);
return lines;
}
string line;
while(getline(in, line)){
lines.push_back(line);
}
in.close();
return lines;
}
void inference(){
TRTLogger logger;
auto engine_data = load_file("engine.trtmodel");
auto runtime = make_nvshared(nvinfer1::createInferRuntime(logger));
auto engine = make_nvshared(runtime->deserializeCudaEngine(engine_data.data(), engine_data.size()));
if(engine == nullptr){
printf("Deserialize cuda engine failed.\n");
runtime->destroy();
return;
}
cudaStream_t stream = nullptr;
checkRuntime(cudaStreamCreate(&stream));
auto execution_context = make_nvshared(engine->createExecutionContext());
int input_batch = 1;
int input_channel = 3;
int input_height = 224;
int input_width = 224;
int input_numel = input_batch * input_channel * input_height * input_width;
float* input_data_host = nullptr;
float* input_data_device = nullptr;
checkRuntime(cudaMallocHost(&input_data_host, input_numel * sizeof(float)));
checkRuntime(cudaMalloc(&input_data_device, input_numel * sizeof(float)));
///
// image to float
auto image = cv::imread("dog.jpg");
float mean[] = {0.406, 0.456, 0.485};
float std[] = {0.225, 0.224, 0.229};
// 对应于pytorch的代码部分
cv::resize(image, image, cv::Size(input_width, input_height));
int image_area = image.cols * image.rows;
unsigned char* pimage = image.data;
float* phost_b = input_data_host + image_area * 0;
float* phost_g = input_data_host + image_area * 1;
float* phost_r = input_data_host + image_area * 2;
for(int i = 0; i < image_area; ++i, pimage += 3){
// 注意这里的顺序rgb调换了
*phost_r++ = (pimage[0] / 255.0f - mean[0]) / std[0];
*phost_g++ = (pimage[1] / 255.0f - mean[1]) / std[1];
*phost_b++ = (pimage[2] / 255.0f - mean[2]) / std[2];
}
///
checkRuntime(cudaMemcpyAsync(input_data_device, input_data_host, input_numel * sizeof(float), cudaMemcpyHostToDevice, stream));
// 3x3输入,对应3x3输出
const int num_classes = 1000;
float output_data_host[num_classes];
float* output_data_device = nullptr;
checkRuntime(cudaMalloc(&output_data_device, sizeof(output_data_host)));
// 明确当前推理时,使用的数据输入大小
auto input_dims = execution_context->getBindingDimensions(0);
input_dims.d[0] = input_batch;
// 设置当前推理时,input大小
execution_context->setBindingDimensions(0, input_dims);
float* bindings[] = {input_data_device, output_data_device};
bool success = execution_context->enqueueV2((void**)bindings, stream, nullptr);
checkRuntime(cudaMemcpyAsync(output_data_host, output_data_device, sizeof(output_data_host), cudaMemcpyDeviceToHost, stream));
checkRuntime(cudaStreamSynchronize(stream));
float* prob = output_data_host;
int predict_label = std::max_element(prob, prob + num_classes) - prob; // 确定预测类别的下标
auto labels = load_labels("labels.imagenet.txt");
auto predict_name = labels[predict_label];
float confidence = prob[predict_label]; // 获得预测值的置信度
printf("Predict: %s, confidence = %f, label = %d\n", predict_name.c_str(), confidence, predict_label);
checkRuntime(cudaStreamDestroy(stream));
checkRuntime(cudaFreeHost(input_data_host));
checkRuntime(cudaFree(input_data_device));
checkRuntime(cudaFree(output_data_device));
}
int main(){
if(!build_model()){
return -1;
}
inference();
return 0;
}
由于是通过 onnx 模型构建网络,因此要包含 NvOnnxParser,依然使用的是我们自定义的源代码,而不是通过 libnvonnxparser.so 库文件来解析
先来看模型构建 build_model 与之前不同的是对于 tensorRT API 的指针我们又套了一层,通过 make_nvshared() 函数来实现创建 tensorRT 对象的智能指针,它可以自动管理其所指向的对象的生命周期,实现内存的自动释放,这是 make_nvshared 完成的工作,其它流程与之前都一样
再来看下 inference,之前的输入都是手动给的,这次需要给定一张图像,首先需要根据输入图像的大小分配 Host 和 Device 的大小,接下来需要读取图片完成与 pytorch 一致的预处理过程
预处理代码如下:
// BGR -> RGB
// (pixel / 255.0 - mean) / std
// to tensor -> BGRBGRBGR -> BBBGGGRRR
cv::resize(image, image, cv::Size(input_width, input_height));
int image_area = image.cols * image.rows;
unsigned char* pimage = image.data;
float* phost_b = input_data_host + image_area * 0;
float* phost_g = input_data_host + image_area * 1;
float* phost_r = input_data_host + image_area * 2;
for(int i = 0; i < image_area; ++i, pimage += 3){
// 注意这里的顺序rgb调换了
*phost_r++ = (pimage[0] / 255.0f - mean[0]) / std[0];
*phost_g++ = (pimage[1] / 255.0f - mean[1]) / std[1];
*phost_b++ = (pimage[2] / 255.0f - mean[2]) / std[2];
}
它具体是如何实现的呢?我们可以看下图:

opencv 的图像格式如左边的图所示,BGRBGRBGR… 这样连续的,而我们实际想要的是右边的效果就是一个通道一个通道的排列起来
那你可能有所困惑,右图中 phost_b 的地址中为什么填充的都是 R 像素值,而反观 phost_r 的地址中填充的都是 B 像素值?是不是画错了?那是没有画错的,在程序中它其实是有故意把 R 像素值填充到 b 通道的,而把 B 像素值填充到 r 通道的,这样做的目的当然就是 bgr2rgb 这个预处理操作啦
我们需要转换的首地址当然就是 input_data_host,先取得 b 通道的首地址 phost_b,然后通过图像面积的偏移量分别获取 phost_g、phost_r,然后将 opencv 对应的 b,g,r 分别塞到对应的地方就行,在这个过程中由于是直接对像素进行操作,因此非常容易实现诸如 BRG2RGB、/255.0、减均值除标准差等各种预处理操作,简单且高效,非常值得学习。
input_data_host 的处理完成后可以将预处理好的图像数据拷贝到 input_data_device 上面,input_data_device 准备好了之后,可以开始准备 output_device 了,根据模型预测的 1000 个类别数分配一个 output_data_device 的空间,分配好之后,可以指定下推理的 batch 数目,然后指定下 bingding 的输入和输出,把它塞到 enqueueV2 中就可以去进行推理了,推理完成之后将推理结果从 output_data_device 拷贝到 output_data_host 上面,接下来做一个流同步,等待所有操作结束就好了。
整个流程图如下所示:

从上面流程可以看到整个过程非常清晰,而典型的 CUDA 核函数程序的执行流程和上述差不多,无非是包含以下几个步骤:
1. 分配 host 内存,并进行数据的初始化
2. 分配 device 内存,并从 host 将数据拷贝到 device 上
3. 调用 CUDA 的核函数在 device 上完成指定的计算
4. 将 device 上的运算结果拷贝到 host 上
5. 释放 device 和 host 上分配的内存
最终的 output_data_host 就是我们想要的概率值,通过 1000 个类别的概率值可以拿到最大概率值对应的标签,然后将其打印出来,输出结果如下:

可以看到和 python 结果一致,说明我们整个中间过程没有任何问题,这就是分类器这个案例,上述代码的重点是预处理,对预处理的理解有利于后续实现 CUDA 核上的并发方式
2. 补充知识
对于上述代码的分析,你需要知道:
1. 模型里面没有 softmax 操作,在这里采用包裹一层加上 softmax 节点后再导出模型,这样使得后处理得到的直接就是概率值,避免后处理上再做 softmax
2. 在 c++ 代码中,则充分采用指针偏移的方式,提升 cpu 上预处理的效率
3. 对于 bgr->rgb 也避免使用 cvtColor 实现,而是简单的改变赋值时的索引,提升效率
2.1 知识点
关于分类器案例的知识点:(from 杜老师)
1. 使用智能指针,对 tensorrt 返回值做封装,使得内存安全不会泄露
template<typename _T>
shared_ptr<_T> make_nvshared(_T* ptr){
return shared_ptr<_T>(ptr, [](_T* p){p->destroy();});
}
// [](_T* p){p->destroy();} 这里用 lambda 表达式的形式来表示 destroy 的方式
// 因为它常常需要 destroy 进行释放
2. 使用 cudaMallocHost 对输入的 host 进行分配,使得主机内存复制到设备效率更高
3. 注意推理时的预处理,指定了 rgb 与 bgr 对调
4. 如果需要多个图像推理,需要:
- 在编译时,指定 maxbatchsize 为多个图
- 在推理时,指定输入的 bindings shape 的 batch 维度为使用的图像数,要求小于等于 maxbatchsize
- 在收取结果的时候,tensor 的 shape 是 input 指定的 batch 大小,按照 batch 处理即可
2.2 智能指针封装
我们来简单聊下智能指针的封装,代码如下:
template<typename _T>
shared_ptr<_T> make_nvshared(_T* ptr){
return shared_ptr<_T>(ptr, [](_T* p){p->destroy();});
}
上述代码实现了一个模板函数,用于创建一个包含 NVIDIA TensorRT 对象的智能指针(例如 nvinfer1::ICudaEngine, nvinfer1::IExecutionContext 等)。这个智能指针的特点是,当它超出作用域或者没有任何引用时,它会自动删除其所指向的对象,从而避免内存泄漏。这是通过 C++ 的 std::shared_ptr 来实现的。
我们来具体分析下这段代码:
1. template<typename _T>:这是一个模板声明,表示这个函数可以接受任何类型的参数。_T 是一个占位符,表示函数接受的函数类型。_T 只是一种常见的命名约定,用于表示模板参数,你甚至可以起名叫做 ABC,这都没关系
2. shared_ptr<_T> make_nvshared(_T* ptr):这是函数声明,函数名为 make_nvshared,它接受一个指向 _T 类型的指针 ptr,并返回一个模板类 std::shared_ptr<_T>,它是一个智能指针,可以自动管理其所指向的对象的生命周期
3. return shared_ptr<_T>(ptr, [](_T* p){p->destroy();});:这是函数的主体部分,它创建并返回一个智能指针实例对象 std::shared_ptr<_T>。std::shared_ptr<_T> 的构造函数接受两个参数:第一个参数是它应该管理的对象的指针,第二个参数是一个删除器。删除器是一个函数或者可调用对象,当智能指针不再需要其所指向的对象时,它会调用删除器来删除这个对象。在这里,删除器是一个 lambda 表达式 [](_T p){p->destroy();}*,当智能指针不再需要其所指向的对象时,它会调用这个对象的 destroy 成员函数来删除它。
所以,这段代码的作用是创建一个智能指针,这个智能指针会自动删除其所指向的对象,从而避免内存泄漏。这是通过使用 std::shared_ptr 的删除器来实现的,删除器是一个 lambda 表达式,它调用对象的 destroy 成员函数来删除对象。
简单来说,上述代码实现了一个函数,接收一个指针,返回对应类型的智能指针实例对象。
有关共享智能指针相关的知识看参考苏老师的 shared_ptr
总结
本次课程学习了 tensorRT 高级篇的第一个案例-CNN分类器,在高级篇里面就要有高级篇的做法,因此我们使用智能指针对 tensorrt 对象的返回值进行了封装,防止内存的泄露。同时我们在 CPU 上也实现了一个高性能的预处理方法,直接对像素进行操作,可以同时把几个预处理操作都做了,对 CPU 的图像预处理操作的理解有利于我们后续实现 warpAffine CUDA 核函数。