LIFT: Learned Invariant Feature Transform
Paper: LIFT: Learned Invariant Feature Transform | SpringerLink
Code: GitHub - cvlab-epfl/LIFT: Code release for the ECCV 2016 paper
文章目录
- Abstract
- 思路来源
- LIFT文献来源
- 方法:LIFT
- Pipeline
- 网络架构
- 训练流程
- 概述
- 创建训练数据集
- Descriptor
- Orientation Estimator
- Detector
- 测试流程
- 实验结果
- 定性结果
- 定量结果
- 单独部分的性能
- 附作者所用的对比算法
- 参考文献
Abstract
我们介绍了一种新颖的深度网络架构,实现了完整的特征点处理pipeline,即检测、方向估计和特征描述。虽然以前的工作已经成功地单独解决了这些问题中的每一个,但我们将展示如何学习以统一的方式处理所有三个问题,同时保持端到端可微性。然后,我们证明了我们的Deep pipeline在许多基准数据集上优于最先进的方法,而不需要再训练。
思路来源
技术背景:局部特征在大量计算机视觉应用中扮演着重要角色,在图像中检测和匹配这些特征成为大量研究的主题。传统依赖于精心设计的手工特征(hand-crafted features)的方法已经取得很好的性能。近年来,机器学习,特别是深度学习,在CV领域表现出超过传统方法的性能。
问题:目前基于深度学习的算法只用于处理单一的步骤,不能保证每个步骤都优化地很好。
解决方案:提出统一处理三个步骤(特征检测、方向估计、特征描述)的深度框架LIFT(Learned Invariant Feature Transform)。
LIFT文献来源
特征点检测(Feature Point Detectors)
特征点检测关注于找到可靠估计尺度和旋转的特殊位置(distinctive locations),例如FAST检测角点(corner points)、SIFT检测斑点(blobs)、MESR检测区域(regions)。
与这些专注于更好的工程设计的方法相比,在学习检测器上早期的尝试方法[1-3]展现出检测器是可以被学习到的,且具有更优的性能。
本文中,作者利用可学习的分段卷积滤波器检测在光照和季节变换下都鲁棒的特征点。同时,作者也将多尺度多视角变化融入到自己的pipeline中。
方向估计(Orientation Estimation)
方向估计主要是为了保持旋转不变性。方向估计虽然在特征点匹配中扮演中重要的作用,但是研究人员很少关注这一部分,因为SIFT方法已经成为标准。
文献[4]提出基于深度学习的方法预测稳定的方向,其产生了更优的结果。本文也将这种结构融入到自己的pipeline中。
特征描述(Feature Descriptors)
特征描述符旨在提供显著图像patch的鉴别表示,同时对视角、光照等变换具有鲁棒性。SIFT的出现使得这一领域达到成熟,它通过梯度方向直方图计算特征描述符。DAISY依赖于方向梯度的卷积图近似直方图。
但是,基于CNN的方法直接从原始图像patch中提取特征变成一种趋势。例如,MatchNet[5]训练孪生CNN学习特征表示,使用一个全连接层学习比较度量。DeepCompare[6]展示出关注于图像中心可以提高性能。DeepDesc[7]使用难负例挖掘用于学习紧凑描述符,其使用欧式距离来度量相似性。
由于欧式距离的广泛适用性,作者采用DeepDesc[7]的网络构建自己的pipeline。
方法:LIFT
Pipeline
整个pipeline如图1所示,由三个主要部分组成:DET(检测器,Detector)、ORI(方向估计器,Orientation Estimator)、DESC(描述器,Descriptor)。每个都是基于CNN。为了校正DET和ORI的输出图像patch(即保持尺度和方向不变性),使用空间转换(Spatial Transformers)[8]。同时,使用soft argmax函数[9]代替非局部极大值抑制(non-local maximum suppression, NMS),即保证端对端可微(可反向传播训练)。

网络架构
作者采用DeepDesc中的孪生网络构建整个网络,如图2所示。

网络为4分支的孪生网络,每个分支包含三个不同的CNN,即Detector、Orientation Estimator、Descriptor。
训练流程
概述
在不同视角和光照条件下捕获下的场景图像中运用SfM(Structure-of-Motion)算法生成特征点。
训练时,采用四组图像patch。
Patch P 1 P^1 P1和 P 2 P^2 P2(blue),对应于相同3D点的不同视角的patch,作为正例训练Descriptor;
Patch P 3 P^3 P3(green)包含不同的3D点,作为负例训练Descriptor;
Patch P 4 P^4 P4(red)不包含任何显著特征点,作为负例训练Detector。
为了实现端对端可微,每个分支的组件按如下方式连接:
- 给定输入图像patch P P P,Detector输出一个得分图 S S S;
- 对 S S S 执行soft argmax,返回单个潜在点的位置 x;
- 使用Spatial Transformer later Crop在 x 的中心提取更小的patch p p p;
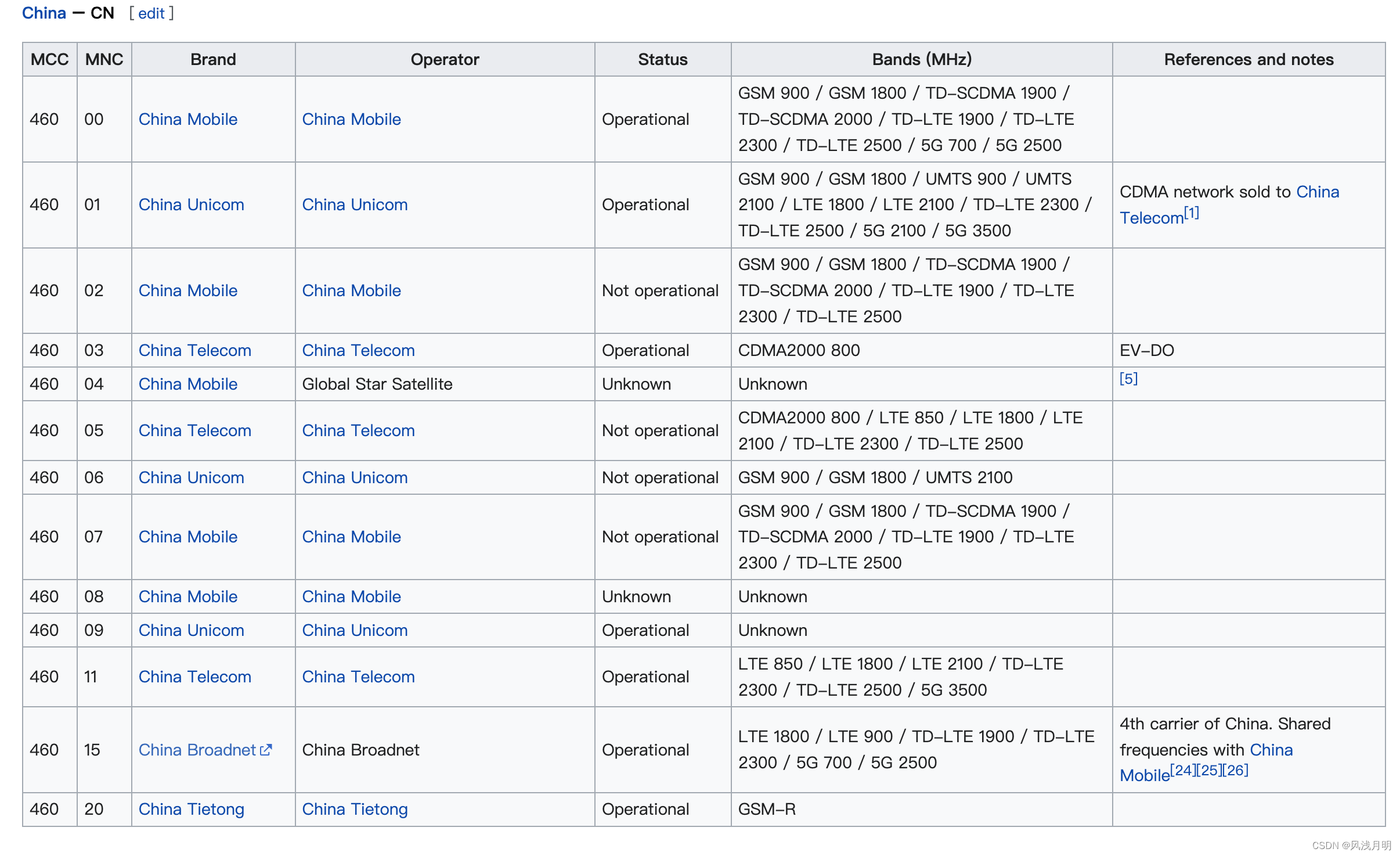
- 将 p p p 输入到Orientation Estimator,输出 p p p 的方向 θ \theta θ;
- 使用Spatial Transformer later Rot旋转 p p p ,输出旋转后的patch p θ p_{\theta} pθ;
- 最后, p θ p_{\theta} pθ被送入描述器处理,输出描述符 d d d。
注意Spatial Transformer只用于操作图像patch,同时保留可微性,这其中没有可学习的模块。
由于各个组件(DET、ORI、DESC)是针对不同的目标进行优化,因此从头开始训练整个网络是不可能的。作者早期尝试过从头开始训练整个网络,但没成功。因此,作者设计了针对特点问题(problem-specific)的学习方法,即从后往前训练:
先训练Descriptor,然后在给定描述符的情况下训练Orientation Estimator,最后在上述两者都给定的情况下,训练Detector。
创建训练数据集
有一些数据集用于训练特征描述器[10]和方向估计器[4]。TILDE[1展示了如何训练关键点检测器,但它的数据集不存在任何视角变换。
采用摄影旅游图像集[11]:来自伦敦皮卡迪利(Piccadilly)广场和古罗马城市广场(Roman-Forum)。作者利用基于SIFT特征的VisualSFM方法[12]使用这些图像集进行3D重建。
Piccadilly包含3384张图像,重建有59k个唯一点,每个点平均6.5个观测值。Roman-Forum包含1658张图像和51k个独特点,平均每个点有5.2个观测值。如图3展示了一些例子。

作者将数据集分为训练集和验证集。为了构建正训练样本,只考虑在SfM重建过程中匹配下来的SIFT特征点。为了提取不包含任何显著特征点的patch,随机采样不包含SIFT特征的图像区域,包括那些没有被SfM使用的图像区域。
针对特征点和非特征点图像区域,根据点的尺度 σ \sigma σ 提取灰度训练patch。Patch P P P 从这些点的 24 σ × 24 σ 24 \sigma \times 24 \sigma 24σ×24σ 支持区域中提取,然后标准化为 S × S ( S = 128 ) S\times S (S=128) S×S(S=128) ,更小的 p p p 和 p θ p_{\theta} pθ,进行裁剪和旋转后,大小减半,为 s × s ( s = 64 ) s\times s (s=64) s×s(s=64)。更小的patch能够更好的对应到SIFT描述符的12 σ \sigma σ 支持区域。为了避免数据的偏差,对patch位置施加均匀随机扰动,其范围为20% (4.8 σ \sigma σ)。最后,利用整个训练集的灰度均值和标准差对图像进行归一化。
Descriptor
对于描述器,作者使用DeepDesc的简单网络,3层卷积和一个tanh激活层、
l
2
l_2
l2 池化层和局部减归一化(local subtractive normalization)。Descriptor用
d
d
d 表示为:
d
=
h
ρ
(
p
θ
)
d = h_{\rho}(p_{\theta})
d=hρ(pθ)训练描述器时,还未对检测器和方向估计器进行训练,因此,使用SfM使用的SIFT特征点的图像位置和方向来生成图像斑patch
p
θ
p_{\theta}
pθ。训练目标为最小化配对patch  和非配对patch
和非配对patch  的总损失,其由它们描述向量之间欧氏距离的hinge embedding损失:
的总损失,其由它们描述向量之间欧氏距离的hinge embedding损失:

 表示欧式距离,C=4为embedding的边距。
表示欧式距离,C=4为embedding的边距。
同样,作者也采用DeepDsec中的难例挖掘机制。(在描述子网络中,难负样本挖掘是一种非常有效的方法,因为大量的特征点之间的差别是非常大的,很容易区分,且负样本的数量往往远远大于正样本,导致网络训练效率下降。)
Orientation Estimator
作者这部分灵感来源于文献[4],然而,这个特定的方法需要预先计算多个方向的描述向量,从而以数值计算方法参数相对于方向的雅可比矩阵。
给定检测器中输出的patch
p
p
p,方向估计器预测
p
p
p 的方向:
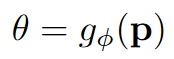
联合Detector中的位置 x 和原始图像pacth
P
P
P,经过Spatial Transformer Layer Rot后,得到旋转后的patch  。
。
在训练方向估计器时,描述器已经训练好,而特征检测器还未训练。因此,使用训练好的描述器计算描述符,Orientation Estimator的目标是最小化描述符的欧式距离:

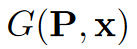 为方向校正后以x为中心的patch。配对(
P
1
P^1
P1,
P
2
P^2
P2)为相同3D点投影的图像patch,位置x1和x2表示这些3D点的重投影。与文献[4]一样,不使用对应于方向不相关的不同物理点的patch对。
为方向校正后以x为中心的patch。配对(
P
1
P^1
P1,
P
2
P^2
P2)为相同3D点投影的图像patch,位置x1和x2表示这些3D点的重投影。与文献[4]一样,不使用对应于方向不相关的不同物理点的patch对。
Detector
检测器由一层卷积和分段线性激活层组成(文献[1]),以图像patch作为输入,得分图(score map)作为输出:
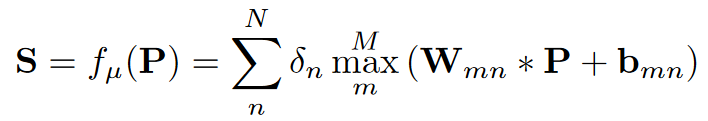
如果n是奇数,则δn为+1,否则为−1。滤波器
W
m
n
W_{mn}
Wmn和偏置
b
m
n
b_{mn}
bmn为卷积层需要去学习的参数。N和M是控制分段线性激活函数复杂度的超参数。
由得分图S,可以获得特征点的位置x:

其中softargmax是一个计算质心的函数,权重是标准softmax函数[9]的输出:

y是S中的位置,
β
=
10
\beta=10
β=10是控制softargmax平滑度的超参数。这个softargmax函数充当了非最大抑制的可微版本。
此时,方向估计器和描述器均已训练好,因此,Detector的优化目标是:最小化相同点配对patch的描述符距离,最大化相同点非配对patch的分类得分。
检测器输入为
(
P
1
,
P
2
,
P
3
,
P
4
)
(P^1, P^2, P^3, P^4)
(P1,P2,P3,P4),前两个为相同点的patch对,1和3为不同SfM点的patch对,4为非特征点patch。总损失为:

γ
\gamma
γ为平衡两项的超参数。

i=4式,yi =−1,αi =3/6,否则yi =+1, αi =1/6。Softmax是对数-均值-指数的Softmax函数。

即为经过已经训练好的方向估计器和描述器后得到描述符的欧式距离。同样,在训练检测器时,作者也使用难例挖掘机制。
实际上,由于描述符已经学习了一些不变性,检测器很难找到隐式学习的新点。理想情况下,检测器应该从它应该检测的区域开始检测,因此,首先约束与相同物理点对应的patch:  。因此, 作者采用下式代替上式预训练检测器:
。因此, 作者采用下式代替上式预训练检测器:

随后,去除上述限制,继续训练检测器,即还是用上上式训练。
测试流程
测试流程如图4所示。由于方向估计器和描述器只需要运行在局部最大值上,因此作者认为检测器可以和后两个部分解耦合,
并使用NMS替代softargmax。

具体的地,是将检测器独立应用于不同分辨率的图像,以获得尺度空间中的得分图。
实验结果
在三种数据集上进行评估:
S t r c h a Strcha Strcha[13]:包含了逐渐增加视角的两个场景的19张图片。
D T U DTU DTU[14]:包含60个具有不同视点和光照的目标序列。本文使用这个数据集在视角变化下评估LIFT。
W e b c a m Webcam Webcam[1]:包含在相同视角下强光照变化的六个场景的710张图像。本文使用这个数据集在自然光照变化下评估LIFT。
S t r c h a Strcha Strcha和 D T U DTU DTU使用提供的真实图像产生对应不同视角的图像。每张图像最多使用1000个关键点。公共视点区域的标准评估遵循文献[15]。
评估以下指标:
-
重复率(Repeatability, Rep.):特征点的可重复性,用比值表示,即特征点检测器检测出的特征点,用以衡量检测器的性能。
-
最近邻平均精度均值(Nearest Neighbor mean Average Precision, NN mAP):精度-召回率曲线下面积(Area Under Curve,AUC),采用最近邻匹配策略。该指标通过在多个描述符距离阈值处计算描述符评估描述符的鉴别度。
-
匹配分数(Matching Score, M. Score):匹配的特征点与所有标签特征点的比值。这个指标衡量网络的整体性能。
定性结果
图5为SIFT和LIFT在四个数据上的对比,使用Piccadilly数据集训练。圆圈表示描述符支持区域。

定量结果
图6为所有三个数据集的平均匹配得分。

表1中LIFT-pic和LIFT-rf分别为在Piccadilly和Roman-Forum上训练的模型。

单独部分的性能
- Fine-Tuning the Detector
前面所述,先预训练检测器,然后再训练方向估计器和描述器。结果如表2所示。
we pre-train the detector and then finalize the training with the Orientation Estimator and the Descriptor. (in paper)
由于新的pair损失项被设计用来模拟理想描述符的行为,预训练(Pre-trained)的检测器已经表现良好。然而,完整的训练(Fully-trained)会略微提高性能。
【疑问】这里我不太明白,Pre-trained和Fully-trained到底区别是什么?按作者的意思,是从后往前训练(描述器->方向估计器->检测器),这是完整的流程,即这里说的Fully-trained;那这里的预训练阶段说:先预训练检测器,然后再训练方向估计器和描述器(上面高亮部分),这不是和Fully-trained的训练流程完全相反么?

仔细观察表2可以发现,Piccadilly数据集的整体性能大于Roman-Forum。这可能是由于Roman-Forum没有很多非特征点区域。事实上,在Roman-Forum数据集上进行了几次迭代后,网络开始快速过拟合。当进一步尝试对整个Pipeline进行微调时,也会网络过快过拟合,这表明所提的学习策略已经提供了一个很好的全局(global)解决方案。
- Performance of Individual Components
作者这里研究了将DET、Ori、Desc三个部分分别用SIFT替代,在三个指标上评估其性能。

附作者所用的对比算法
这些前期的算法还是值得一看的,特别是SIFT、SURF、ORB、Harris-affine、BRISK、DeepDesc、PN-Net、MatchNet
| 算法 | 关键点检测器 | 文献 |
|---|---|---|
| SIFT | - | Distinctive image features from scale-invariant keypoints,IJCV2004 |
| SURF | - | SURF: speeded up robust features,CVIV2008 |
| KAZE | - | KAZE features,ECCV2012 |
| ORB | - | ORB: an efficient alternative to SIFT or SURF,ICCV2011 |
| Daisy | SIFT | Daisy: an efficient dense descriptor applied to wide baseline stereo,TPAMI2010 |
| sGLOH | Harris-affine | Improving sift-based descriptors stability to rotations,ICPR2010 [Harris-affine]Scale and affine invariant interest point detectors,IJCV2010 |
| MROGH | Harris-affine | Aggregating gradient distributions into intensity orders: a novel local image descriptor,,CVPR2011 |
| LIOP | Harris-affine | Local intensity order pattern for feature description,ICCV2011 |
| BiCE | Edge Foci | Binary coherent edge descriptors,ECCV2010 [Edge Foci]Edge foci interest points,ICCV2011 |
| BRISK | - | BRISK: binary robust invariant scalable keypoints,ICCV2011 |
| FREAK | BRISK | Vandergheynst, P.: FREAK: fast retina keypoint,CVPR2012 |
| VGG | SIFT | Learning local feature descriptors using convex optimisation,TPAMI2014 |
| DeepDesc | SIFT | Discriminative learning of deep convolutional feature point descriptors,ICCV2015 |
| PN-Net | SIFT | PN-Net: conjoined triple deep network for learning local image descriptors,arXiv2016 |
| MatchNet | SIFT | MatchNet: unifying feature and metric learning for patch-based matching,CVPR2015 |
参考文献
- TILDE: a temporally invariant learned DEtector,CVPR2015
- Learning a fast emulator of a binary decision process,ACCV2007
- Using evolution to learn how to perform interest point detection,ICPR2006
- Learning to assign orientations to feature points,CVPR2016
- MatchNet: unifying feature and metric learning for patch-based matching,CVPR2015
- Learning to compare image patches via convolutional neural networks,CVPR2015
- Discriminative learning of deep convolutional feature point descriptors,ICCV2015
- Spatial transformer networks,NeurIPS2015
- Gradient descent optimization of smoothed information retrieval metrics,Information Retrieval 2010
- Learning local image descriptors,CVPR2007
- Robust global translations with 1DSfM,ECCV2014
- Towards linear-time incremental structure from motion,2013 International Conference on 3D Vision
- On benchmarking camera calibration and multi-view stereo for high resolution imagery,CVPR2008
- Interesting interest points,IJCV2012
- A performance evaluation of local descriptors,CVPR2003