非线性优化的数值方法小结——梯度下降法,牛顿法,高斯牛顿法,LM法
在非线性优化领域中,我们常采用一系列数值方法对构造的问题进行求解,各方法彼此联系,本文将对这些数值处理方法进行梳理构造。
问题描述
非线性优化问题有很多种,本文将用最常见的非线性优化问题——也是高斯牛顿法和LM法能处理的唯一问题——最小二乘问题展开分析:
最小二乘问题,即让误差函数的绝对值最小,我们设误差函数为f(x),则我们的目标是:
min
F
(
x
)
=
1
2
∥
f
(
x
)
∥
2
2
\min F(x)=\frac{1}{2}\|f(x)\|_2^2
minF(x)=21∥f(x)∥22
使得F(x)最小化。如何解决这个问题呢?
梯度下降法
梯度下降法的思路是给定一个函数,在每次迭代让自变量x沿着负梯度方向前进一步,就可以让函数F(x)减小。最终函数将收敛至无法减小,也就是梯度为0的地方,也就是局部最小值。
F
(
x
)
=
1
2
∥
f
(
x
)
∥
2
2
=
1
2
f
(
x
)
T
f
(
x
)
F(x) = \frac{1}{2}\|f(x)\|_2^2=\frac{1}{2}f(x)^Tf(x)
F(x)=21∥f(x)∥22=21f(x)Tf(x)
F
(
x
)
′
=
f
(
x
)
T
′
f
(
x
)
F(x)^{\prime} = f(x)^{T{\prime}}f(x)
F(x)′=f(x)T′f(x)
我们令
J
=
f
(
x
)
T
′
J=f(x)^{T{\prime}}
J=f(x)T′,梯度下降法的假设是让x沿着负梯度的方向运动:
x
k
+
1
=
x
k
−
α
J
x_{k+1} = x_{k} - {\alpha}J
xk+1=xk−αJ
α
{\alpha}
α是步长,常取0到1之间的值,这就是梯度下降法。另一种常用的方法最速下降法与梯度下降法形式相同,区别在于,梯度下降法中
α
{\alpha}
α是人工设定的经验值,最速下降法中,
α
{\alpha}
α是求解优化问题:
α
k
=
argmin
α
k
f
(
x
i
−
α
k
J
)
\alpha_k=\operatorname{argmin}_{\alpha_k} f\left(x_i-\alpha_k J\right)
αk=argminαkf(xi−αkJ)
计算得到的。这个优化问题怎么求呢?最直观的方法,通过二分法不断搜索
α
k
{\alpha_k}
αk的值取最优。
性质分析
1、梯度下降法是线性收敛的,由于没有用到函数本身的信息,收敛较慢。
2、对于强凸函数,具有全局收敛性。
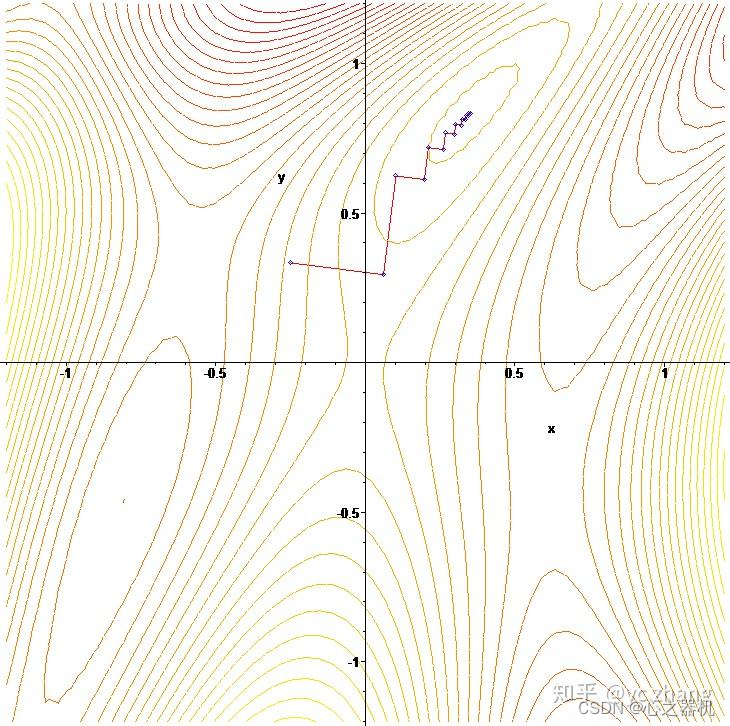
3、由于每次都朝梯度方向运动,因此轨迹常呈锯齿状:
牛顿法
牛顿法是一种用于求解方程:
f
(
x
)
=
0
f(x) = 0
f(x)=0
的方法。其思路是,对于迭代过程中的值
x
k
x_{k}
xk,过该点,沿着该点的梯度方向做直线,与横轴的交点即为
x
k
+
1
x_{k+1}
xk+1
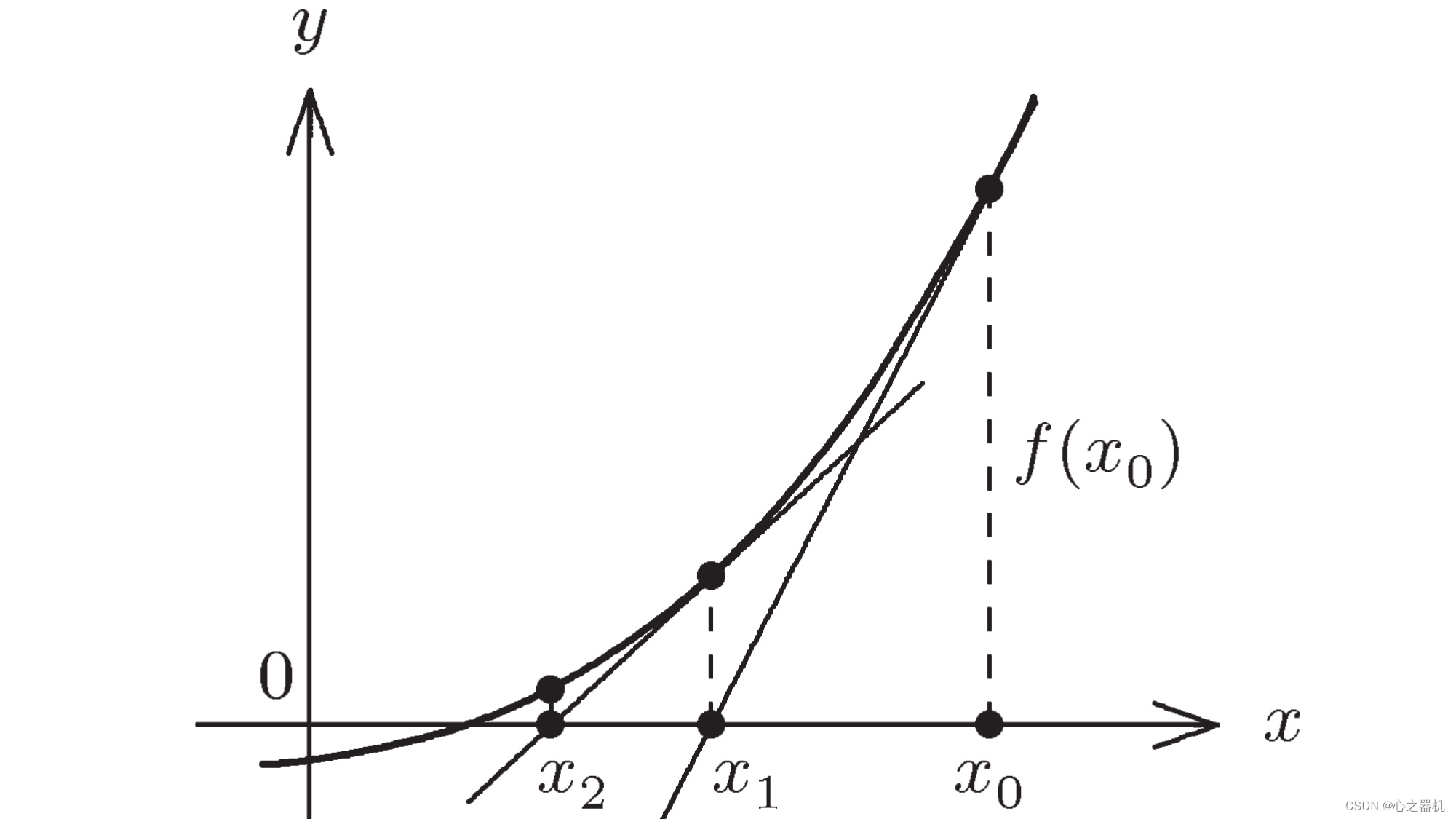
因此我们可以得到
x
k
x_{k}
xk与$x_{k+1}的关系:
f
(
x
k
+
1
)
−
f
(
x
k
)
=
f
(
x
k
)
′
(
x
k
+
1
−
x
k
)
f(x_{k+1})-f(x_{k}) = f(x_{k}) ^{\prime}(x_{k+1}-x_{k})
f(xk+1)−f(xk)=f(xk)′(xk+1−xk)
我们希望
f
(
x
k
+
1
)
=
0
f(x_{k+1})=0
f(xk+1)=0,因此,我们对
x
k
+
1
x_{k+1}
xk+1这样取值:
x
k
+
1
=
x
k
−
f
(
x
k
)
f
(
x
k
)
′
x_{k+1} = x_{k}-\frac{f(x_{k})}{f(x_{k})^{\prime}}
xk+1=xk−f(xk)′f(xk)
牛顿法可以求解任意f(x) = 0的问题,在最小二乘问题中,我们希望得到F(x)的最小值,也就是F(x)'=0,因此,实际的迭代过程是:
x
k
+
1
=
x
k
−
F
(
x
k
)
′
F
(
x
k
)
′
′
=
x
k
−
J
f
(
x
k
)
f
(
x
k
)
′
′
+
J
J
T
x_{k+1} = x_{k}-\frac{F(x_{k})^{\prime}}{F(x_{k})^{\prime\prime}} = x_{k}-\frac{Jf(x_{k})}{f(x_{k})^{\prime\prime}+JJ^{T}}
xk+1=xk−F(xk)′′F(xk)′=xk−f(xk)′′+JJTJf(xk)
在多维情况下,我们一般称
f
(
x
k
)
′
′
f(x_{k})^{\prime\prime}
f(xk)′′为海森矩阵H,也就是:
x
k
+
1
=
x
k
−
J
f
(
x
k
)
H
+
J
J
T
x_{k+1} = x_{k}-\frac{Jf(x_{k})}{H+JJ^{T}}
xk+1=xk−H+JJTJf(xk)
要注意,很多博主这块自己没弄清楚,海森矩阵和
J
J
T
JJ^{T}
JJT分不清,F(x)和f(x)分不清,导致一些模棱两可的推导。
性质分析
1、牛顿法需要求海森矩阵,在高维和规模较大的情况下计算量大,一般避免求海森矩阵。
2、牛顿法在最优点附近具有二次收敛性,比梯度法有快的多。但是,其代价是只具有局部收敛性,当初值远离最优点时,即便函数是凸的,依然有可能无解。
高斯牛顿法
从方法的名字也可以看出高斯牛顿法是高斯在牛顿法的基础上改进的,高斯发现,除了能对F(x)直接展开优化,还可以对f(x)做文章,于是他先将f(x)展开:
f
(
x
+
Δ
x
)
=
f
(
x
)
+
J
Δ
x
+
o
(
Δ
x
)
f(x+\Delta x) = f(x) + J\Delta x + o(\Delta x)
f(x+Δx)=f(x)+JΔx+o(Δx)
我们可以求变量
Δ
x
\Delta x
Δx的最优值来让F(x)最小:
G
(
Δ
x
)
=
F
(
x
+
Δ
x
)
=
1
2
∥
f
(
x
+
Δ
x
)
∥
2
2
=
1
2
f
(
x
+
Δ
x
)
T
f
(
x
+
Δ
x
)
G(\Delta x) = F(x+\Delta x) = \frac{1}{2}\|f(x+\Delta x)\|_2^2=\frac{1}{2}f(x+\Delta x)^Tf(x+\Delta x)
G(Δx)=F(x+Δx)=21∥f(x+Δx)∥22=21f(x+Δx)Tf(x+Δx)
=
1
2
(
f
(
x
)
+
J
Δ
x
)
T
(
f
(
x
)
+
J
Δ
x
)
=
1
2
f
(
x
)
T
f
(
x
)
+
f
(
x
)
J
Δ
x
+
Δ
x
T
J
T
J
Δ
x
=\frac{1}{2}(f(x)+J\Delta x)^T(f(x)+J\Delta x)= \frac{1}{2}f(x)^Tf(x) + f(x)J \Delta x + \Delta x^{T}J^{T}J\Delta x
=21(f(x)+JΔx)T(f(x)+JΔx)=21f(x)Tf(x)+f(x)JΔx+ΔxTJTJΔx
该函数对\Delta x求导,得:
G
(
Δ
x
)
′
=
J
f
(
x
)
+
J
T
J
Δ
x
G(\Delta x)^{\prime} = Jf(x) + J^{T}J \Delta x
G(Δx)′=Jf(x)+JTJΔx
当
G
(
Δ
)
x
′
=
0
G(\Delta )x^{\prime} =0
G(Δ)x′=0时,F(x+\Delta x) 取值达到了最小。因此,我们令:
Δ
x
=
−
J
f
(
x
)
J
T
J
\Delta x = -\frac{Jf(x)}{ J^{T}J}
Δx=−JTJJf(x)
有人也把
J
T
J
{ J^{T}J}
JTJ写作
H
H
H,要注意这里的H并非海森矩阵。
性质分析
1、高斯牛顿法最大的改进在于不需要求海森矩阵,减少了计算量。
2、
J
T
J
{ J^{T}J}
JTJ只能保证半正定,而其作为分母时需要是正定的。这导致算法可能出现奇异或接近奇异时稳定性差
3、和牛顿法的收敛性一样,高斯牛顿法也有局部二阶收敛性。
4、当求解出的步长
Δ
x
\Delta x
Δx太大时,会导致局部近似不精确,甚至不收敛。牛顿法也有类似问题。
LM(列文伯格-马夸特)法
为了解决高斯牛顿法的不收敛性问题(顺便解决了歧义性问题),又诞生了LM方法。LM方法的核心思路是,引入一个迭代步长的信赖域
μ
\mu
μ,认为当
Δ
x
<
μ
\Delta x < \mu
Δx<μ时,这次迭代才是可以信赖的。即:
min
F
(
x
)
=
m
i
n
1
2
∥
f
(
x
)
+
J
Δ
x
∥
s.t
∥
D
Δ
x
<
μ
∥
2
\min F(x) = min \frac{1}{2}\left\|f(x)+J \Delta x\right\| \quad \text { s.t } \quad\|D \Delta x<\mu\|_2
minF(x)=min21∥f(x)+JΔx∥ s.t ∥DΔx<μ∥2
用拉格朗日法,将有约束问题转化为无约束问题:
L
(
Δ
x
,
λ
)
=
1
2
∥
f
(
x
)
+
J
Δ
x
∥
2
+
λ
2
(
∥
D
Δ
x
∥
2
−
μ
)
L(\Delta x, \lambda)=\frac{1}{2}\left\|f(x)+J \Delta x\right\|^2+\frac{\lambda}{2}\left(\|D \Delta x\|^2-\mu\right)
L(Δx,λ)=21∥f(x)+JΔx∥2+2λ(∥DΔx∥2−μ)
求导并让导数为0,有:
(
J
J
T
+
λ
D
T
D
)
Δ
x
=
−
J
f
(
x
)
\left(J J^T+\lambda D^T D\right) \Delta x=-J f(x)
(JJT+λDTD)Δx=−Jf(x)
我们把
J
T
J
{ J^{T}J}
JTJ写作
H
H
H,令D取单位矩阵I得:
Δ
x
=
−
J
f
(
x
)
H
+
λ
I
\Delta x = -\frac{Jf(x)}{H+\lambda I}
Δx=−H+λIJf(x)
在实际使用中\lambda 是通过迭代计算得到的值。我们发现,当\lambda较小时,该方法和高斯牛顿法相同,当lambda较大时,
Δ
x
=
−
J
f
(
x
)
λ
\Delta x = -\frac{Jf(x)}{\lambda}
Δx=−λJf(x),和梯度下降法形式i相同。可以认为LM方法是梯度方法和高斯牛顿法的结合,那么
λ
\lambda
λ如何计算呢?
一般,我们取一个较小的处置
λ
0
\lambda_{0}
λ0,之后进行迭代,我们需要计算这次迭代的近似效果(也就是信赖程度):
ρ
=
f
(
x
+
Δ
x
)
−
f
(
x
)
J
T
Δ
x
\rho=\frac{f(x+\Delta x)-f(x)}{J^{T}\Delta x}
ρ=JTΔxf(x+Δx)−f(x)
当
ρ
\rho
ρ较大时,表示这次拟合程度较好,可以适当扩大信赖域,当
ρ
\rho
ρ较小时,表示拟合程度较差,需要缩小信赖域。
性质分析
1、LM法通过添加阻尼项(信赖域项),控制了
Δ
x
\Delta x
Δx的大小,解决了高斯牛顿法收敛性差的问题。
2、阻尼项也解决了奇异的问题,保证了分母的正定性。