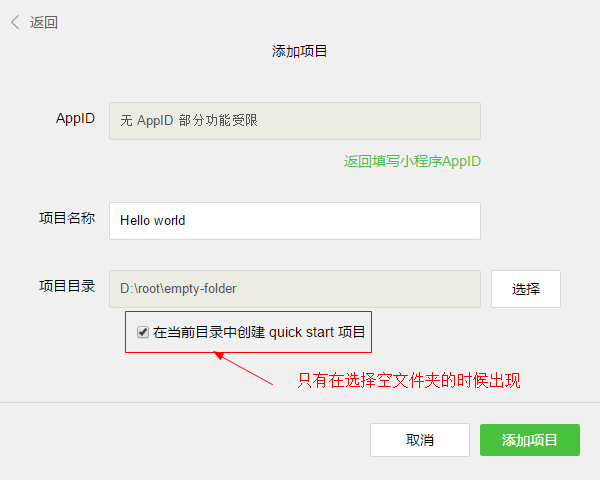
练习4-Apply函数
探索1960 - 2014 美国犯罪数据

步骤1 导入必要的库
运行以下代码
import numpy as np
import pandas as pd
步骤2 从以下地址导入数据集
运行以下代码
path4 = ‘…/input/pandas_exercise/pandas_exercise/exercise_data/US_Crime_Rates_1960_2014.csv’ # “US_Crime_Rates_1960_2014.csv”
步骤3 将数据框命名为crime
运行以下代码
crime = pd.read_csv(path4)
crime.head()
Year Population Total Violent Property Murder Forcible_Rape Robbery Aggravated_assault Burglary Larceny_Theft Vehicle_Theft
0 1960 179323175 3384200 288460 3095700 9110 17190 107840 154320 912100 1855400 328200
1 1961 182992000 3488000 289390 3198600 8740 17220 106670 156760 949600 1913000 336000
2 1962 185771000 3752200 301510 3450700 8530 17550 110860 164570 994300 2089600 366800
3 1963 188483000 4109500 316970 3792500 8640 17650 116470 174210 1086400 2297800 408300
4 1964 191141000 4564600 364220 4200400 9360 21420 130390 203050 1213200 2514400 472800
步骤4 每一列(column)的数据类型是什么样的?
运行以下代码
crime.info()
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 55 entries, 0 to 54
Data columns (total 12 columns):
Year 55 non-null int64
Population 55 non-null int64
Total 55 non-null int64
Violent 55 non-null int64
Property 55 non-null int64
Murder 55 non-null int64
Forcible_Rape 55 non-null int64
Robbery 55 non-null int64
Aggravated_assault 55 non-null int64
Burglary 55 non-null int64
Larceny_Theft 55 non-null int64
Vehicle_Theft 55 non-null int64
dtypes: int64(12)
memory usage: 5.2 KB
注意到了吗,Year的数据类型为 int64,但是pandas有一个不同的数据类型去处理时间序列(time series),我们现在来看看。
步骤5 将Year的数据类型转换为 datetime64
运行以下代码
crime.Year = pd.to_datetime(crime.Year, format=‘%Y’)
crime.info()
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 55 entries, 0 to 54
Data columns (total 12 columns):
Year 55 non-null datetime64[ns]
Population 55 non-null int64
Total 55 non-null int64
Violent 55 non-null int64
Property 55 non-null int64
Murder 55 non-null int64
Forcible_Rape 55 non-null int64
Robbery 55 non-null int64
Aggravated_assault 55 non-null int64
Burglary 55 non-null int64
Larceny_Theft 55 non-null int64
Vehicle_Theft 55 non-null int64
dtypes: datetime64ns, int64(11)
memory usage: 5.2 KB
步骤6 将列Year设置为数据框的索引
运行以下代码
crime = crime.set_index(‘Year’, drop = True)
crime.head()
Population Total Violent Property Murder Forcible_Rape Robbery Aggravated_assault Burglary Larceny_Theft Vehicle_Theft
Year
1960-01-01 179323175 3384200 288460 3095700 9110 17190 107840 154320 912100 1855400 328200
1961-01-01 182992000 3488000 289390 3198600 8740 17220 106670 156760 949600 1913000 336000
1962-01-01 185771000 3752200 301510 3450700 8530 17550 110860 164570 994300 2089600 366800
1963-01-01 188483000 4109500 316970 3792500 8640 17650 116470 174210 1086400 2297800 408300
1964-01-01 191141000 4564600 364220 4200400 9360 21420 130390 203050 1213200 2514400 472800
步骤7 删除名为Total的列
运行以下代码
del crime[‘Total’]
crime.head()
Population Violent Property Murder Forcible_Rape Robbery Aggravated_assault Burglary Larceny_Theft Vehicle_Theft
Year
1960-01-01 179323175 288460 3095700 9110 17190 107840 154320 912100 1855400 328200
1961-01-01 182992000 289390 3198600 8740 17220 106670 156760 949600 1913000 336000
1962-01-01 185771000 301510 3450700 8530 17550 110860 164570 994300 2089600 366800
1963-01-01 188483000 316970 3792500 8640 17650 116470 174210 1086400 2297800 408300
1964-01-01 191141000 364220 4200400 9360 21420 130390 203050 1213200 2514400 472800
crime.resample(‘10AS’).sum()
Population Violent Property Murder Forcible_Rape Robbery Aggravated_assault Burglary Larceny_Theft Vehicle_Theft
Year
1960-01-01 1915053175 4134930 45160900 106180 236720 1633510 2158520 13321100 26547700 5292100
1970-01-01 2121193298 9607930 91383800 192230 554570 4159020 4702120 28486000 53157800 9739900
1980-01-01 2371370069 14074328 117048900 206439 865639 5383109 7619130 33073494 72040253 11935411
1990-01-01 2612825258 17527048 119053499 211664 998827 5748930 10568963 26750015 77679366 14624418
2000-01-01 2947969117 13968056 100944369 163068 922499 4230366 8652124 21565176 67970291 11412834
2010-01-01 1570146307 6072017 44095950 72867 421059 1749809 3764142 10125170 30401698 3569080
步骤8 按照Year对数据框进行分组并求和
注意Population这一列,若直接对其求和,是不正确的*
更多关于 .resample 的介绍
(https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.resample.html)
更多关于 Offset Aliases的介绍
(http://pandas.pydata.org/pandas-docs/stable/timeseries.html#offset-aliases)
运行以下代码
crimes = crime.resample(‘10AS’).sum() # resample a time series per decades
用resample去得到“Population”列的最大值
population = crime[‘Population’].resample(‘10AS’).max()
更新 “Population”
crimes[‘Population’] = population
crimes
Population Violent Property Murder Forcible_Rape Robbery Aggravated_assault Burglary Larceny_Theft Vehicle_Theft
Year
1960-01-01 201385000 4134930 45160900 106180 236720 1633510 2158520 13321100 26547700 5292100
1970-01-01 220099000 9607930 91383800 192230 554570 4159020 4702120 28486000 53157800 9739900
1980-01-01 248239000 14074328 117048900 206439 865639 5383109 7619130 33073494 72040253 11935411
1990-01-01 272690813 17527048 119053499 211664 998827 5748930 10568963 26750015 77679366 14624418
2000-01-01 307006550 13968056 100944369 163068 922499 4230366 8652124 21565176 67970291 11412834
2010-01-01 318857056 6072017 44095950 72867 421059 1749809 3764142 10125170 30401698 3569080
步骤9 何时是美国历史上生存最危险的年代?
运行以下代码
crime.idxmax(0)
Population 2014-01-01
Violent 1992-01-01
Property 1991-01-01
Murder 1991-01-01
Forcible_Rape 1992-01-01
Robbery 1991-01-01
Aggravated_assault 1993-01-01
Burglary 1980-01-01
Larceny_Theft 1991-01-01
Vehicle_Theft 1991-01-01
dtype: datetime64[ns]