R语言
R语言学习笔记——入门篇:第六章-基本图形
文章目录
- R语言
- 一、条形图
- 1.1、垂直与水平条形图
- 补——数据为因子时绘制垂直与水平条形图
- 1.2、堆砌条形图与分组条形图
- 1.3、数据整合条形图
- 1.4、条形图的微调
- 1.5、棘状图
- 二、饼图
- 三、直方图
- 四、核密度图
- 4.1、简易核密度图
- 4.2、可比较的核密度图
- 五、箱线图
- 5.1、使用并列箱线图进行跨组比较
- 5.2、小提琴图
- 六、点图
- 七、总结
一、条形图
- 概述:条形图通过垂直的或水平的条形展示了类别型变量的分布(频数)。
- 函数:barplot()
- 对象:向量或矩阵
- 语法:
barplot(heigt...)
# height是一个向量或一个矩阵
- 参数:
| 参数 | 功能 |
|---|---|
| height | 向量或矩阵,如果是矩阵,在矩阵前提下若beside=FALSE,条形分段画出,若beside=TRUE,条形依次画出 |
| width | 向量,表示条形的宽度 |
| beside | 逻辑值,默认为F。前提:height为矩阵,F,堆彻条形图,T,分组条形图 |
| col | 表示线条颜色 |
| border | 表示条形边框的颜色 |
| main | 字符,标题 |
| sub | 字符,副标题 |
| xlab | 字符,x轴的标签 |
| ylab | 字符,y轴的标签 |
| xlim | x轴的范围 |
| ylim | y轴的范围 |
| horiz | 逻辑值,设置条形的方向。F,条形从左到右垂直排列,T,条形从下到上水平排列 |
| legend | 逻辑值,legend=FALSE表示不添加图例,legend=TRUE表示添加图例 |
| cex.axis | 数值,表示坐标轴标签相对于其他文字的大小 |
| cex.names | 数值,表示坐标轴名称相对于其他文字的大小 |
1.1、垂直与水平条形图
- 参数:horiz
- 逻辑值:F,条形从左到右垂直排列,T,条形从下到上水平排列
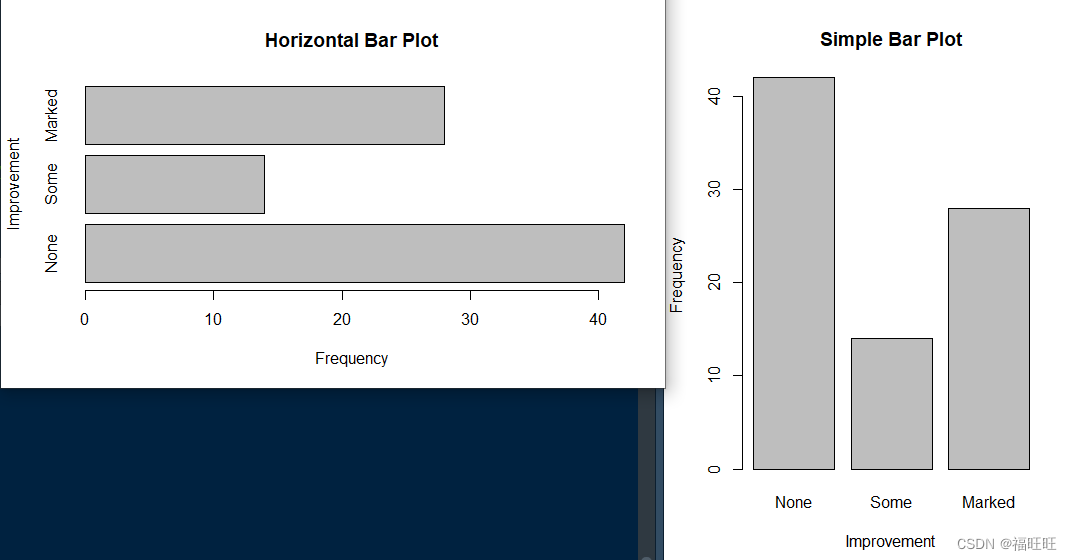
- 示例:
library(vcd)
counts <- table(Arthritis$Improved)
counts
# 这边读入lvcd包里面的Arthristis数据集
# 数据表示在接受药物治疗后有42位病人无改善,14位病人有部分改善,28位病人有明显改善
None Some Marked
42 14 28
barplot(counts,main = "Simple Bar Plot",
xlab="Improvement",ylab="Frequency")
dev.new()
barplot(counts,main = "Horizontal Bar Plot",xlab="Frequency",
ylab="Improvement",horiz = TRUE)
补——数据为因子时绘制垂直与水平条形图
- 函数:plot()
- 对象:因子
- 语法:
plot(x, y, ...)
- 示例:
# 因子型变量,直接使用plot()函数,不需要将数据用table表格化。
# 生成一样的条形图
class(Arthritis$Improved)
[1] "ordered" "factor"
plot(Arthritis$Improved,main="Simple Bar Plot",
ylab="Improved",xlab="Frequency")
plot(Arthritis$Improved,main="Simple Bar Plot",
ylab="Improved",xlab="Frequency",horiz=T)
1.2、堆砌条形图与分组条形图
- 参数:beside
- 前提:数据为矩阵
- 逻辑值:F,堆彻条形图,T,分组条形图
- 概述:
- 堆彻条形图:矩阵中的每一列都将生成图中的一个条形,各列中的值将给出堆砌子条的高度
- 分组条形图:矩阵中的每一列都代表一个分组,各列中的值将并列而不是堆砌
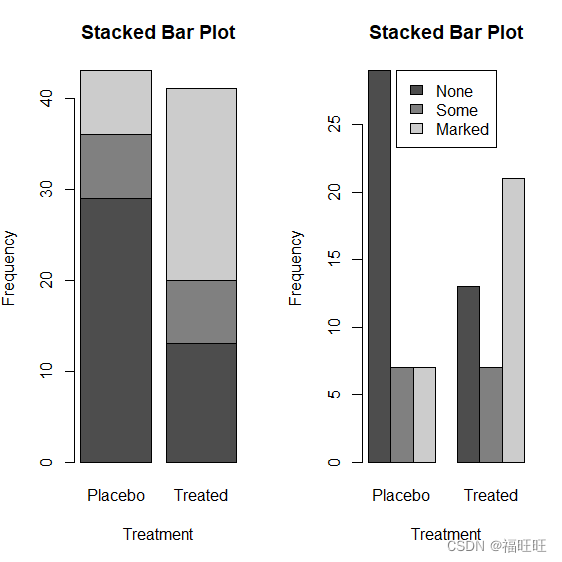
- 示例:
library(vcd)
counts <- table(Arthritis$Improved,Arthritis$Treatment)
counts
Placebo Treated
None 29 13
Some 7 7
Marked 7 21
par(mfrow=c(1,2))
barplot(counts,main="Stacked Bar Plot",xlab="Treatment",ylab="Frequency",col=c(grey(0.3),grey(.5),grey(.8))
)
barplot(counts,main="Stacked Bar Plot",xlab="Treatment",ylab="Frequency",col=c(grey(0.3),grey(.5),grey(.8)),
beside=T)
legend("top",rownames(counts),fill=c(grey(0.3),grey(.5),grey(.8)))
1.3、数据整合条形图
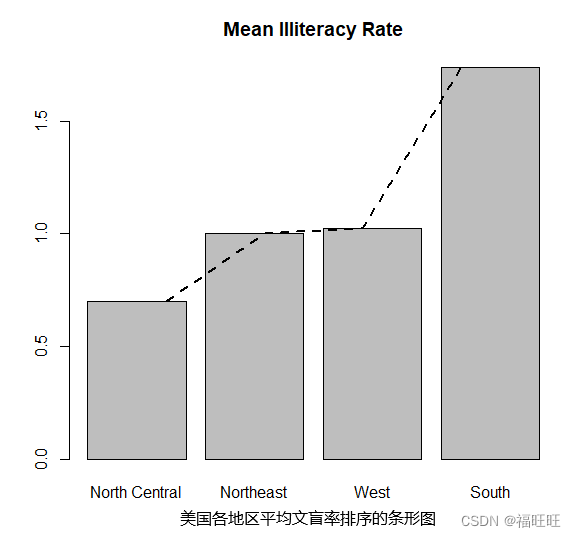
- 概述:使用数据整合函数并将结果传递给barplot()函数,来创建表示均值、中位数、标准差等的条形图。
- 示例:
library(vcd)
states <- data.frame(state.region,state.x77)
means <- aggregate(states$Illiteracy,by=list(state.region),FUN=mean)
means
Group.1 x
1 Northeast 1.000000
2 South 1.737500
3 North Central 0.700000
4 West 1.023077
means <- means[order(means$x),]
# 均值从小到大排序
means
Group.1 x
3 North Central 0.700000
1 Northeast 1.000000
4 West 1.023077
2 South 1.737500
barplot(means$x,names.arg=means$Group.1,main = "Mean Illiteracy Rate")
lines(means$x,lty=2,lwd=2)
# 辅助线虚线(lty=2),两倍宽(lwd=2)
1.4、条形图的微调
- 概述:利用par( )函数与参数来美化图形,详见 第三章。
- 示例:
library(vcd)
opar <- par(no.readonly = T)
# 备份了当前的图形参数设置
#不加参数no.readonly = T执行par( )将生成一个含有当前参数的列表,但是为只读格式,不能修改
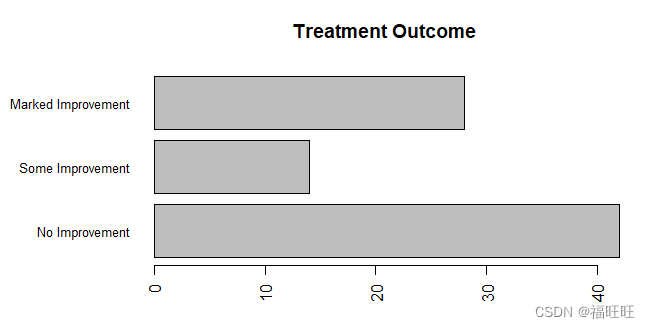
par(mar=c(5,8,4,2)) #设置边界的大小,分别为下左上右,单位为英分
par(las=2) #坐标刻度标签的方向。0表示总是平行于坐标轴,1表示总是水平的,2表示总是垂直于坐标轴
counts <- table(Arthritis$Improved)
barplot(counts,main = "Treatment Outcome",
horiz = T,# 水平条形图
cex.names=0.8,
names.arg = c("No Improvement","Some Improvement","Marked Improvement"))
par(opar)
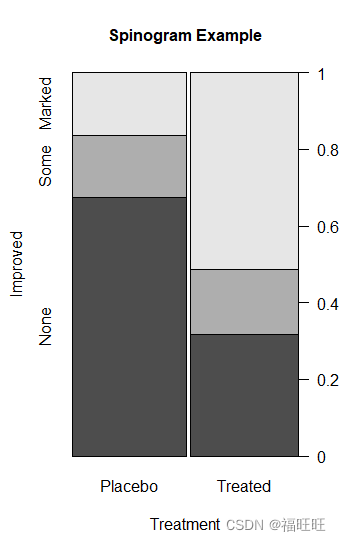
1.5、棘状图
- 概述:棘状图对堆砌条形图进行了重缩放,设置每个条形的高度均为1,每一段的高度即表示比例。
- 函数:vcd包中的函数spine( )
- 示例:
library(vcd)
attach(Arthritis)
counts <- table(Treatment,Improved)
spine(counts,main="Spinogram Example")
detach(Arthritis)
二、饼图
- 概述:饼图通过面积展示了类别型变量的分布(频数)。
- 函数:pie()
- 对象:非负值向量
- 语法:
pie(x, labels = names(x), edges = 200, radius = 0.8,
clockwise = FALSE, init.angle = if(clockwise) 90 else 0,
density = NULL, angle = 45, col = NULL, border = NULL,
lty = NULL, main = NULL, ...)
- 参数:
| 参数 | 功能 |
|---|---|
| x | 非负整数向量,表示每个扇形的面积 |
| labels | 字符串向量,生成各扇形标签的表达式 |
| edges | 数值,表示用多少条线段来绘制饼图边框(构成圆的线段数,即多边形的边数) |
| radius | 数值,表示饼图的大小(当这个值大于1时,饼图的某个部分会被裁剪掉) 饼图是画在一个方框的中心,方框的边长范围是-1到1。如果标记片的字符串很长,可能需要使用较小的半径 |
| clockwise | 逻辑值,表示分块绘制的方向是顺时针TRUE还是逆时针FALSE(默认逆时针) |
| init.angle | 数值,设置分块的起始角度(以度数为单位)的数字。逆时针时默认值为0(即3点钟方向),如果clockwise为true,即顺时针角度默认为90度(即“12点方向”) |
| density | 阴影线的密度,以每英寸线为单位。默认值NULL表示没有绘制阴影线。非正密度值也会抑制阴影线的绘制。 |
| angle | 阴影线的斜率,以角度(逆时针方向)表示 |
| col | 数值,表示每一块的颜色,默认为NULL,此时使用的是一个6色调色板 |
| border | 用于指定绘制每个分块的多边形 |
| lty | 表示分块的线条类型 |
| main | 标题 |
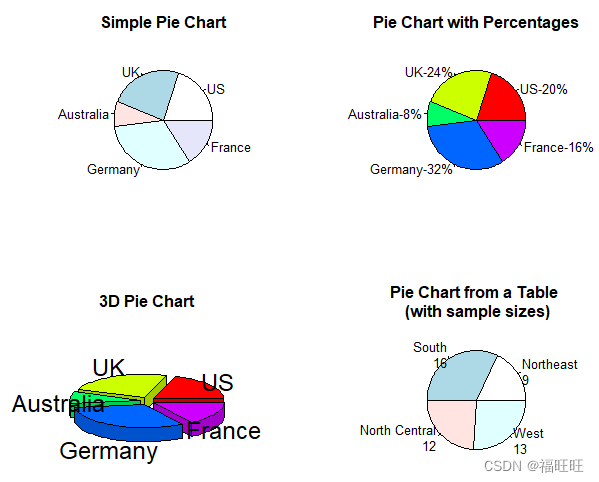
- 示例:
par(mfrow=c(2,2))
# 简单饼图
slices <- c(10,12,4,16,8)
lbls <- c("US","UK","Australia","Germany","France")
pie(slices,labels=lbls,main="Simple Pie Chart")
# 标签附带上百分比
pct <- round(slices/sum(slices)*100)
lbls2 <- paste(lbls,"-",pct,"%",sep="")
pie(slices,labels=lbls2,col=rainbow(length(lbls2)),main="Pie Chart with Percentages")
# 3D饼图
install.packages("plotrix")
library(plotrix)
pie3D(slices,labels=lbls,explode=0.1,main="3D Pie Chart")
# explode表示各扇形分开的距离
# 从表格创建饼图
library(vcd)
mytable <- table(state.region)
lbls3 <- paste(names(mytable),"\n",mytable,sep="")
pie(mytable,label=lbls3,main="Pie Chart from a Table \n (with sample sizes)")
- 缺陷:由于饼图展现的是面积,这让对比各个扇形之间的值变得困难,于是有了扇形图这种饼图变种。
- 概述:在一幅扇形图中,各个扇子相互叠加,并对半径做了修改,这样所有的扇形就都是可见的。扇形的宽度重要,半径不重要。
- 函数:plotrix包中的fan.plot()函数
- 对象:非负值向量
- 语法:
fan.plot(x,edges=200,radius=1,col=NULL,align.at=NULL,max.span=NULL,
labels=NULL,labelpos=NULL,label.radius=1.2,align="left",shrink=0.02,
main="",ticks=NULL,include.sumx=FALSE,...)
- 参数:
| 参数 | 功能 |
|---|---|
| x | 非负整数向量,表示每个扇形的面积 |
| edges | 用来画圆的边数 |
| radius | 扇区的半径 |
| col | 用来填充扇区的颜色 |
| align.at | 在哪里对齐扇区 |
| max.span | 以弧度为单位的最大扇形的角度。默认值是缩放x,使其和为2*π \piπ |
| labels | 向量,指定放置在扇形弧周围的标签 |
| labelpos | 标签的可选圆周位置 |
| label.radius | 指定标签将放置在离扇区多远的地方。可能是一个指定了每个标签的半径的向量 |
| align | 扇区对齐的位置 |
| shrink | 每个连续的扇形区域的半径要收缩多少 |
| main | 可选标题 |
| ticks | 标签刻度。默认值为无刻度,刻度数等于 x 的整数和。 |
| include.sumx | 是否将所有x值的总和作为最大扇区 |
- 示例:
library(plotrix)
slices <- c(10,12,4,16,8)
lbls <- c("US","UK","Australia","Germany","France")
fan.plot(slices,labels=lbls,main="Fan Plot")

三、直方图
- 概述:通过在x轴上将值域分割为一定数量的组,在y轴上显示相应值的频数,展示了连续型变量的分布
- 函数:hist( )
- 对象:连续型变量
- 语法:
hist(x, breaks = "Sturges",
freq = NULL, probability = !freq,
include.lowest = TRUE, right = TRUE, fuzz = 1e-7,
density = NULL, angle = 45, col = "lightgray", border = NULL,
main = paste("Histogram of" , xname),
xlim = range(breaks), ylim = NULL,
xlab = xname, ylab,
axes = TRUE, plot = TRUE, labels = FALSE,
nclass = NULL, warn.unused = TRUE, ...)
- 参数:
| 参数 | 功能 |
|---|---|
| breaks | 控制组的数量,代表 |
| freq | 逻辑值;默认为TRUE,此时直方图图形是频率的表示,即结果的计数分量;如果为 FALSE,则绘制概率密度、分量密度(以便直方图的总面积为 1)。 |
- 关于break参数:可以是下面任意一种
- 直方图单元格之间断点的向量;
- 计算断点向量的函数;
- 直方图单元格数的单个数字;
- 一个字符串,用于命名算法以计算单元格数量;
- 计算单元格数的函数。
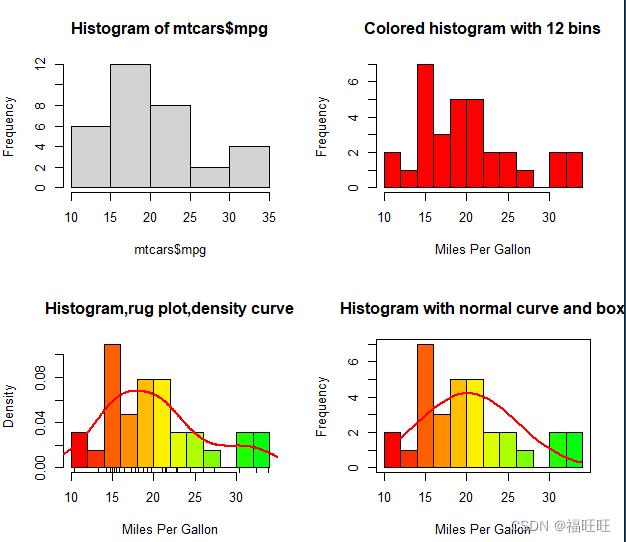
- 示例:
par(mfrow=c(2,2))
#1.简单直方图
hist(mtcars$mpg)
#2.指定组数和颜色
hist(mtcars$mpg,
breaks = 9,
col="red",
xlab="Miles Per Gallon",
main="Colored histogram with 12 bins")
#3.添加轴须图
hist(mtcars$mpg,
freq=F,
breaks = 12,
col=rainbow(length(mtcars$mpg)),
xlab="Miles Per Gallon",
main="Histogram,rug plot,density curve")
rug(jitter(mtcars$mpg))
# mycars是包自带的数据集
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3
Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3
Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4
Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2
AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4
Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
# 轴须线,轴须图是实际数据值的一种一维呈现方式.如果数据中有很多结(出现相同的值,称为结(tie))
# 利用函数rug(jitter(mtcars$mpg,amount=0.01))将轴须图的数据打散:
# 这样将向每个数据点添加一个小的随机值(一个± a m o u n t \pm amount±amount之间的均匀分布随机数),以避免重叠的点产生影响
lines(density(mtcars$mpg),col="#FF0000",lwd=2)
# 密度曲线,是一个核密度估计,为数据的分布提供了一种更加平滑的描述
# RGB模式,十六进制(0~F),六位数字,两位代表一种颜色,顺序为红绿蓝(RGB)
#4.添加正态密度曲线和外框
x <- mtcars$mpg
h <- hist(x,
breaks=12,
col=rainbow(length(mtcars$mpg)),
xlab="Miles Per Gallon",
main="Histogram with normal curve and box")
xfit <- seq(min(x),max(x),length=40)
# seq(from,to,by) 生成一个序列,从from至to,间隔by
yfit <- dnorm(xfit,mean=mean(x),sd=sd(x))
# 正态分布密度函数
yfit <- yfit*diff(h$mids[1:2])*length(x)
# mids 是每个柱子的中心点,diff()滞后差分函数
# diff(h$mids[1:2])计算每个柱子的宽度值
lines(xfit,yfit,col="#FF0000",lwd=2)
box()
# 添加外框
四、核密度图
4.1、简易核密度图
- 概述:核密度估计是用于估计随机变量概率密度函数的一种非参数方法
- 函数:plot(density(x))
- 对象:连续型变量
- 示例:
par(mfrow=c(2,1))
d <- density(mtcars$mpg)
plot(d)
plot(d,main = "Kernel Density of Miles Per Gallon")
# plot为高级绘图函数,其会绘制一份新的图形
# 如果希望在当前图片上添加核密度曲线,则使用line()函数(详见上述hist例子)
polygon(d,col="red",border = "#0000FF")
# polygon()函数根据顶点的x和y坐标(本例中由density()函数提供)绘制多边形.
# 将曲线修改为蓝色,并使用红色填充曲线下方区域
rug(mtcars$mpg,col="brown")
# 添加棕色轴须线
dev.off()

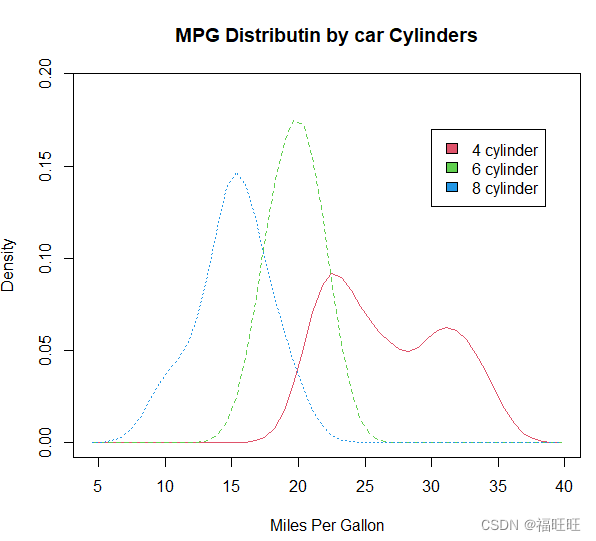
4.2、可比较的核密度图
- 概述:为了比较组间差异,需要向图像叠加两组或者更多核密度图
- 应用:在某个结果变量上进行跨组观测不组所含值的分布形状及组间重叠程度。
- 函数:sm包中的sm.density.compare()
- 对象:连续型变量
- 语法:
sm.density.compare(x,factor)
# x是一个数值型向量,factor是一个分组变量
- 示例:
install.packages("sm")
library(sm)
attach(mtcars)
# 创建分组因子
# 在数据框mtcars中,变量cyl是一个以4,6,8编码的数值型变量,这里将它转为cyl.f因子型
cyl.f <- factor(cyl,levels=c(4,6,8),
labels=c("4 cylinder","6 cylinder","8 cylinder"))
# 绘制密度图
# 数据框mtcars的变量mpg
sm.density.compare(mpg,cyl,xlab="Miles Per Gallon")
title(main="MPG Distributin by car Cylinders")
# 添加图例
# legend()函数第一个参数locator(1)表示用鼠标点击想让图例出现的位置来交互式的放置图例
# 第二个参数则是标签组成的字符向量
# 第三个参数是填充颜色
colfill <- c(2:(1+length(levels(cyl.f))))
legend(locator(1),levels(cyl.f),fill=colfill)
detach(mtcars)
五、箱线图
- 概述:亦名盒须图,总括了最小值、下四分位数(第25百分位数)、中位数(第50位百分数)、上四分位数(第75位百分位数)以及最大值,也能够显示出可能为离群点(范围为 ±1.5 × IQR以外的值,IQR表示四分位距,即上四分位数与下四分位数的差值)的观测。
- 应用:通过绘制连续型变量的五数,描述连续型变量的分布,可视化分布于组间差异(比核密度图更加常用)。
- 函数:boxplot()
- 对象:连续型变量
- 语法:
boxplot(data)
- 示例:

- 离群值:亦为异常值,由各种外界因素构成。默认情况下,箱线图两条须的延伸极限不会超过盒型各端加1.5倍四分位距的范围。此范围以外的值将以点(离群值)来表示。
- 函数:boxplot.stats() 可以显示出箱线图中的各个数据
- 语法:
boxplot.stats(x, coef=1.5, do.conf=TRUE, do.out=TRUE)
# x为数值向量(NA、NaN值将被忽略);coef为盒须的长度为几倍的IQR(盒长),默认为1.5;
# do.conf和do.out设置是否输出conf和out
- 示例:
> boxplot.stats(Combat_rld)
$stats # 五数,最小值,下四分位数,中位数,上四分位数,最大值
[1] -2.305218 1.141073 5.659526 8.189390 18.687386
$n # 数据总量
[1] 700452
$conf # 中位数的95%置信区间
[1] 5.646219 5.672832
$out # 离群值
[1] 21.26141 21.31163 21.27449 21.40439 21.62409 21.69400 21.63428 21.56632 21.57835 21.69951
[11] 21.64128 21.62036 21.94358 21.62000 21.75788 21.56576 21.30368 21.14933 21.42601 21.25827
[21] 21.68388 21.72883 21.14791 21.55909 21.30488 21.30970 21.25854 20.93438 21.09886 20.44625
[31] 20.63351 20.44111 20.86753 21.12430 21.04442 20.72934
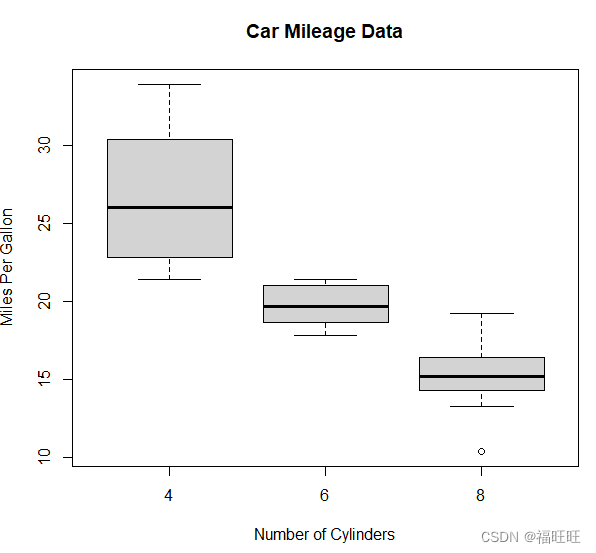
5.1、使用并列箱线图进行跨组比较
- 概述:展示单个变量或分组变量
- 应用:可视化连续型输出变量组件差异。
- 函数:boxplot()
- 对象:连续型变量
- 语法:
boxplot(formula, data = dataframe)
# formula是一个公式,dataframe代表提供数据的数据框(或列表).
# 添加参数varwidth=TRUE将使箱线图的宽度与其样本大小的平方根成正比.
# 参数horizontal = TRUE可以反转坐标轴的方向.
- 示例1:
boxplot(mpg~cyl,data=mtcars,main="Car Mileage Data",
xlab = "Number of Cylinders",
ylab = "Miles Per Gallon")
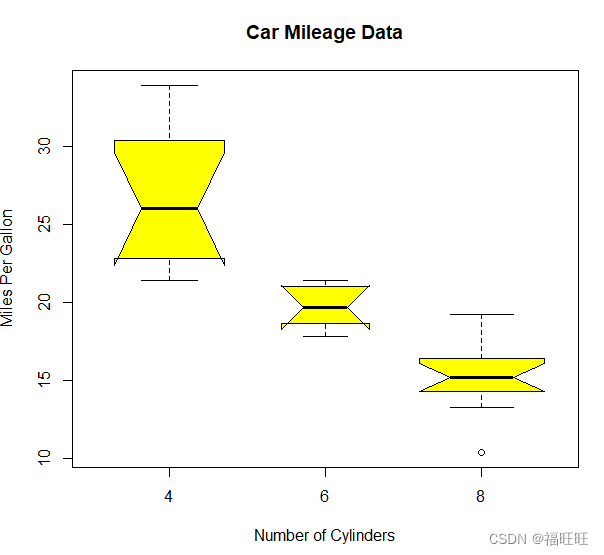
- 示例2:通过添加notch=TRUE,可以得到含凹槽的箱线图.若两个箱的凹槽互不重叠,则表明它们的中位数有显著的差异
boxplot(mpg~cyl,data=mtcars,main="Car Mileage Data",
xlab = "Number of Cylinders",
ylab = "Miles Per Gallon")
boxplot(mpg~cyl,data=mtcars,
col="yellow",
notch=TRUE,
# varwidth=T使箱线图的宽度与各自的样本大小成正比
varwidth=T,
main="Car Mileage Data",
xlab = "Number of Cylinders",
ylab = "Miles Per Gallon")
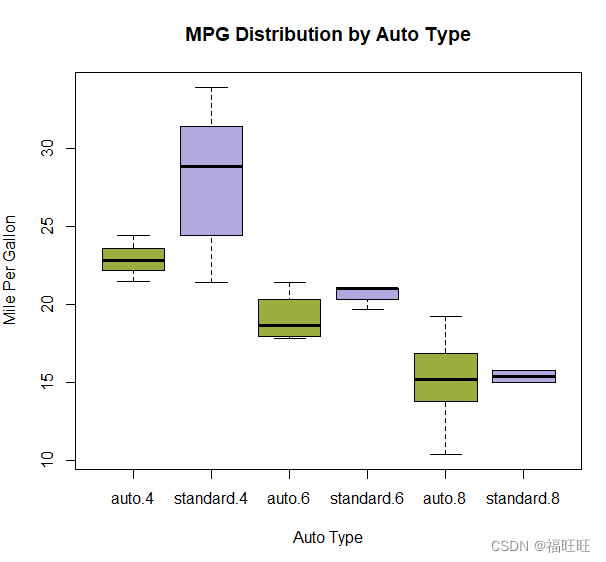
- 示例3:为多个分组因子绘制箱线图
# 两个交叉因子的箱线图
#创建汽缸数量的因子
mtcars$cyl.f <- factor(mtcars$cyl,
levels=c(4,6,8),
labels=c("4","6","8"))
#创建变速箱类型的因子
mtcars$am.f <- factor(mtcars$am,
levels=c(0,1),
labels=c("auto","standard"))
#生成箱线图
boxplot(mpg ~ am.f*cyl.f,
data=mtcars,
col=c("#9DAC3F","#B0A9DF"),
main="MPG Distribution by Auto Type",
xlab="Auto Type",ylab="Mile Per Gallon")
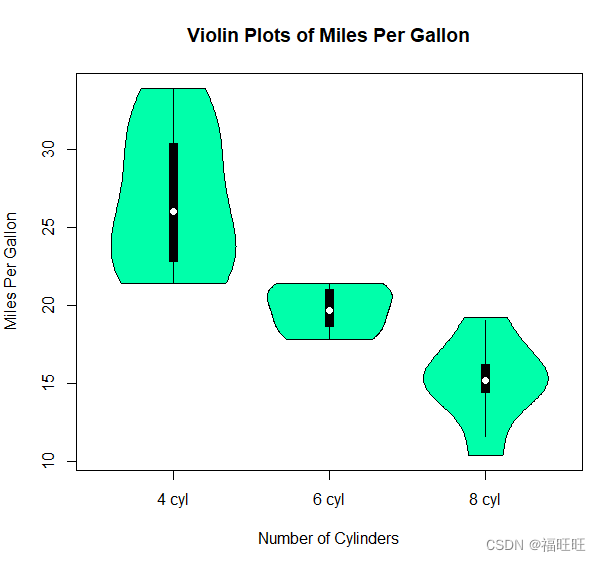
5.2、小提琴图
- 概述:核密度图以镜像的方式在箱线图上的叠加,属于箱线图的变种。
- 函数:vioplot包中的vioplot()函数
- 对象:连续型变量
- 语法:
vioplot(x1,x2,...,names=,col=)
# x1,x2,...表示要绘制的一个或多个数值向量(将为每个向量绘制一幅小提琴图)
# 参数names是小提琴图中标签的字符向量,而col是一个为每幅小提琴图指定颜色的向量.
- 示例:
install.packages("vioplot")
library(vioplot)
attach(mtcars)
x1 <- mpg[cyl == 4]
x2 <- mpg[cyl == 6]
x3 <- mpg[cyl == 8]
vioplot(x1,x2,x3,
names=c("4 cyl","6 cyl","8 cyl"),
col="#00FFAA")
# vioplot()函数要求将要绘制的不同组分离到不同的变量中
title("Violin Plots of Miles Per Gallon",ylab="Miles Per Gallon",
xlab="Number of Cylinders")
detach(mtcars)
# 图中,白点是中位数,黑色盒型的范围是下四分位点到上四分位点,细黑线表示须.外部形状即为核密度估计
六、点图
- 概述:在简单水平刻度上绘制大量有标签值。
- 应用:每个点都有自己的标签与含义,可以获得全局数据,所以适用于小数据量。
- 函数:dotchart()
- 对象:连续型变量
- 语法:
dotchart(x,labels=)
# x是一个数值向量,而labels则是由每个点标签组成的向量
# 可以通过添加参数groups来选定一个因子,用以指定x中元素的分组方式
# 参数gcolor可以控制不同组标签的颜色.cex可以控制标签的大小
- 示例1:
dotchart(mtcars$mpg,labels=row.names(mtcars),cex=1.2,
main="Gas Mileage for Car Models",
xlab="Miles Per Gallon")

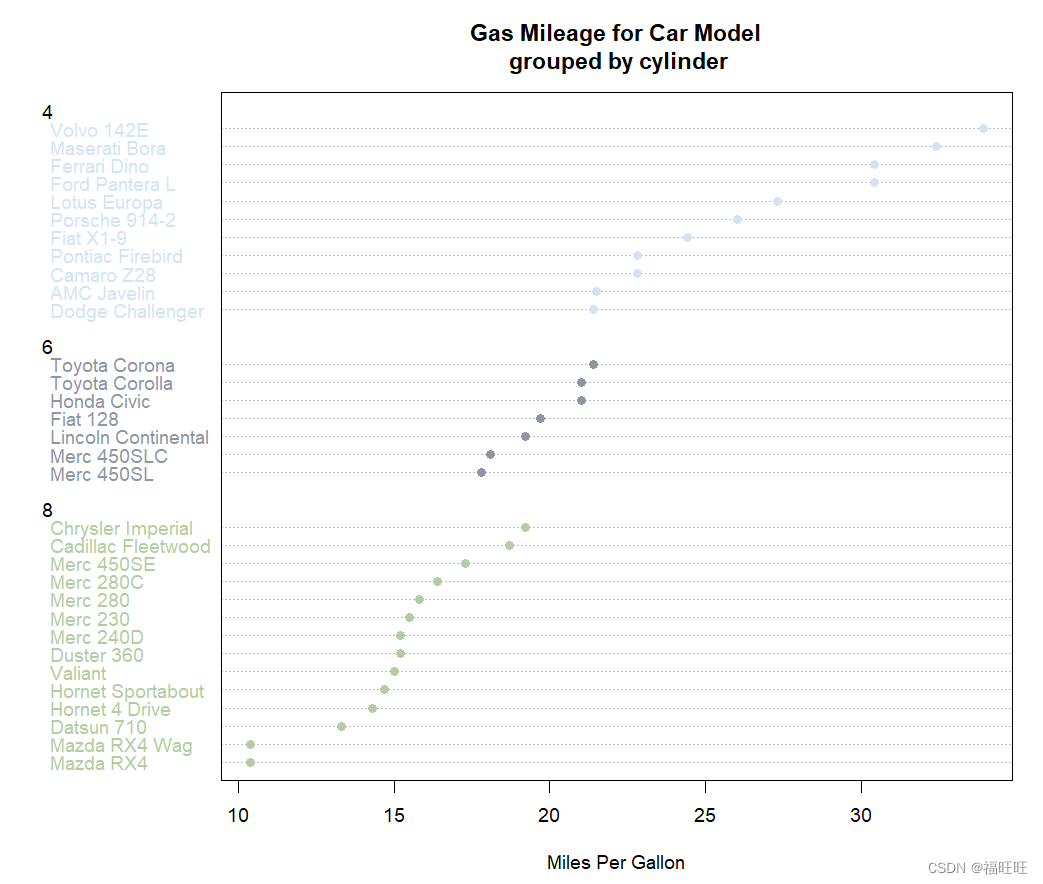
- 示例2:示例1中数据散乱,此示例对数据进行排序并且以不同的符号和颜色将分组变量区分开
# 分组、排序、着色后的点图 ------------------------------------------------------------
#根据每加仑汽油行驶英里数(从低到高)对数据框mtcars进行排序,结果2保存为数据框x
x <- mtcars[order(mtcars$mpg),]
#将数值向量cyl转换为一个因子
x$cyl <- factor(x$cyl)
#添加一个字符型向量(color)到数据框x中,根据cyl的值,取不同的颜色值
x$color[x$cyl == 4] <- "#D1E3F5"
x$color[x$cyl == 6] <- "#8B97A3"
x$color[x$cyl == 8] <- "#B1CDA1"
dotchart(x$mpg,
labels=row.names(mtcars),#各数据点的标签取自数据框的行名(车辆型号)
cex=1.2,
group=x$cyl,#数据点根据汽缸数量分组
gcolor = "black",#数字4、6、8以黑色来显示
color = x$color,#点和标签的颜色向量来自向量color
pch=19,
main="Gas Mileage for Car Model\n grouped by cylinder",
xlab="Miles Per Gallon"
)
七、总结
- 可视化类别型变量分布:条形图,饼图
- 可视化连续型变量分布:直方图,核密度图,箱线图,轴须图,点图(小数据量)
- 可视化连续型输出变量组件差异:叠加的核密度图,并列箱线图,分组点图


![[附源码]计算机毕业设计海南与东北的美食文化差异及做法的研究展示平台Springboot程序](https://img-blog.csdnimg.cn/b554991cdeaf45e490590041c6ccc595.png)




![[附源码]Python计算机毕业设计SSM基于的楼盘销售系统(程序+LW)](https://img-blog.csdnimg.cn/83ca8fcb8dda4f2b8f7c0ae2ec4404e8.png)