0.摘要
弱监督语义分割(WSSS)在不需要密集注释的情况下对对象进行分割。然而,生成的伪掩码存在明显的噪声像素,这导致在这些伪掩码上训练的分割模型表现不佳。但是,很少有研究注意到或解决这个问题,即使在改进了伪掩码后这些噪声像素仍然是不可避免的。因此,我们试图改进WSSS的噪声抑制方面。我们观察到许多噪声像素具有很高的置信度,特别是当响应范围过宽或过窄时,表现出不确定的状态。因此,在本文中,我们通过多次缩放预测图来模拟响应的噪声变化,以估计不确定性。然后,利用这种不确定性来加权分割损失,以减轻噪声监督信号。我们将这种方法称为URN(Uncertainty estimation via Response scaling for Noise mitigation)。实验证实了URN的益处,我们的方法在PASCAL VOC 2012和MS COCO 2014数据集上分别达到了71.2%和41.5%的最先进结果,而无需额外的模型,如显著性检测。代码可在https://github.com/XMed-Lab/URN获得。
1.引言
语义分割是计算机视觉中的基础任务之一。其中一个主要挑战是获取密集的像素级注释来监督模型训练的成本过高。为了降低注释成本,研究人员利用弱注释替代了密集的像素级注释,如涂鸦(Lin et al.2016;Tang et al.2018)、边界框(Xu, Schwing 和 Urtasun 2015;Dai, He 和 Sun 2015;Khoreva et al.2017)、点(Bearman et al.2016)和图像级标签(Kolesnikov 和 Lampert 2016;Pathak, Krahenbuhl 和 Darrell 2015;Pinheiro 和 Collobert 2015;Ahn 和 Kwak 2018)。本文旨在基于仅图像级类别标签开发一种新的弱监督语义分割(WSSS)方法。
大多数现有的弱监督语义分割方法(Wang et al.2020;Zhang et al.2020;Li et al.2021)遵循常见的流程,首先生成伪掩码,然后以全监督的方式使用伪掩码训练分割模型。这些方法通过解决Class Activation Map(Zhou et al.2016)的低激活问题来提高伪掩码的质量,就像这些论文(Kolesnikov and Lampert 2016;Jiang et al.2019;Chang et al.2020)所提到的,还使用AffinityNet(Ahn and Kwak 2018)或显著性(Yao and Gong 2020;Fan et al.2020)来区分前景和背景。但是,在应用这些方法后,噪声像素是不可避免的。据我们所知,只有PMM(Li et al.2021)尝试减轻噪声的影响。然而,它无法用于精细的伪掩码和COCO数据集,并且无法确定噪声像素的位置。因此,在本文中,我们以更有效的方式减轻噪声。
我们观察到噪声像素主要可以分为漏检的正样本和误检的负样本。具体来说,如果响应范围(激活区域的范围)比较窄,漏检的正样本占主导地位;而如果响应范围较宽,误检的负样本则成为大多数,如图2所示。由于响应尺度的变化,会产生许多置信度较高的错误像素(噪声),而这种现象恰好属于不确定性。因此,在本文中,我们通过不确定性估计来定位噪声。
在弱监督语义分割的设置中,不确定性估计需要为每个图像生成多个预测结果,因此如何生成这些预测结果并反映噪声是很重要的。通过观察图2中置信度较高的错误像素,我们发现不确定像素与响应尺度密切相关。因此,我们通过概率缩放来模拟不同激活尺度下的响应图。此外,在缩放方案后,我们将稠密条件随机场(Zheng et al.2015)添加到响应图中,形成伪掩码。经过上述操作后,我们利用这些缩放后的响应来估计不确定性,并建立不确定性与噪声之间的关联。
通过响应缩放进行不确定性估计后,我们对不确定性进行归一化,并将其转化为优化中的损失权重,以减轻噪声的影响。我们观察到,不确定性较高的像素更有可能是噪声,如图1所示。因此,我们采用较低的损失权重来减轻其不良影响。我们将权重图和损失图进行均值操作,以得到优化中的最终损失。
整个过程被称为URN,即通过响应缩放进行噪声缓解的不确定性估计。URN对于具有来自弱监督的噪声伪掩码的分割是实用且有效的。我们在流行的数据集PASCAL VOC 2012(Everingham et al.2010)和具有图像级监督的挑战性数据集MS COCO 2014上验证了提出的URN与基准方法PMM(Li et al.2021)。在VOC上,我们获得了新的mIoU最佳结果71.2%,在COCO上为41.5%。
我们总结如下的贡献:
- 我们观察到高置信度的错误像素(噪声)与响应范围的尺度相关,并通过响应缩放来定位这些不确定像素。
- 我们首次通过不确定性的损失权重,在弱监督语义分割的优化中缓解噪声的影响。
- 在弱监督语义分割的主要数据集上,我们取得了新的最先进的结果。

图1:通过响应缩放估计的不确定性与伪掩码的错误像素(噪声)呈正相关关系。左:真实标签。中间:带有噪声的伪掩码。右:归一化后的不确定性图。
2.相关工作
弱监督语义分割。近年来,人们在开发标签效率高的语义分割方法上投入了大量的努力(Lin et al.2016;Tang et al.2018;Xu, Schwing和Urtasun 2015;Dai, He和Sun 2015;Khoreva et al.2017;Kolesnikov和Lampert 2016;Pathak, Krahenbuhl和Darrell 2015;Pinheiro和Collobert 2015;Ahn和Kwak 2018;Wang et al.2020;Yu et al.2019a;Li et al.2020a,2018)。在这些方法中,图像级别的类别标签需要的注释成本最低。现有的弱监督语义分割方法主要采用两个阶段的流程。第一阶段通过一个多标签分类网络优化类激活图(CAMs)(Zhou et al.2016)来生成伪地面真值。第二阶段是通过伪地面真值训练一个完全监督的语义分割网络。为了改进弱监督语义分割,大多数算法都集中在通过将部分响应区域扩展到整个前景区域(Kolesnikov和Lampert 2016;Jiang et al.2019;Chang et al.2020)来提高CAMs的质量。一些方法通过自监督方法(Ahn和Kwak 2018;Ahn, Cho和Kwak 2019)或引入额外的信息,如显著性检测模型(Lee et al.2019;Yao和Gong 2020;Jiang et al.2019;Yao和Gong 2020;Li et al.2020b;Fan et al.2020)和对象提议(Liu et al.2020)来区分前景和背景,以提高CAMs的质量。
在弱监督语义分割中,研究人员主要关注生成高质量的伪标签以提高性能,而对如何利用这些不完美的标签来改进分割模型的注意力较少。在本文中,我们意识到由于噪声像素是不可避免的,适当的方式是缓解不确定像素的损害。
分割中的不确定性。深度神经网络为每个预测提供了一个概率,但有时即使概率很高,也可能是错误的。在论文(Kendall和Gal 2017)中,这种现象被称为模型本身产生的认知不确定性。早期的工作使用蒙特卡洛Dropout(Kendall,Badrinarayanan和Cipolla 2015;Gal和Ghahramani 2016a;Blundell等人2015;Gal和Ghahramani 2016b)来近似后验分布以进行不确定性估计,此外,还使用了Ensemble(Lakshminarayanan,Pritzel和Blundell 2017)和多头(Lee等人2015,2016;Rupprecht等人2017)。后续的研究者主要集中在提出改进的方法来获得更好的输出不确定性图。在这里,基于推理的方法(Kendall和Gal 2017;Tanno等人2017;Jungo,Balsiger和Reyes 2020)主要利用贝叶斯推理或随机推理来提高不确定性图的质量,同时基于自编码器的方法(Kingma和Welling 2014;Sohn,Lee和Yan 2015)引入重建来获得更好的不确定性图的空间精度。这些论文主要预测不确定性掩码以便于人类判断,例如在医学图像分割场景中。然而,先前的方法主要强调改善不确定性图的质量,但很少探索如何通过不确定性来提高分割精度。相反,它们组合预测以获得更好的结果。不同于以前的估计不确定性用于可视化或注释的工作,我们利用不确定性来减轻分割优化中的噪声,以获得更好的性能。并且这种不确定性是基于对弱监督语义分割中噪声特征的观察而估计得出的。
学习中的噪声标签。本文的重点是减轻弱监督语义分割中的噪声标签。这里,我们讨论一些与学习噪声标签相关的工作。现有的学习噪声标签的方法可以分为四类。 1)标签校正方法通过使用复杂的噪声预测模型(如图形模型(Xiao等人2015)、条件随机场(Vahdat 2017)和神经网络(Lee等人2017;Veit等人2017))提出通过应用标签校正来改善标签的质量。 2)标签加权损失方法在训练过程中修改损失函数,基于标签相关的权重(Natarajan等人2013;Goldberger和Ben-Reuven 2017;Sukhbaatar等人2014)或估计的噪声转换矩阵,该矩阵定义了将一个类别误标为另一个类别的概率(Han等人2018a;Patrini等人2017;Reed等人2014;Pereyra等人2017)。例如,Xu等人(2019)引入了互信息(MI)损失,用于对CE预训练模型进行稳健微调。 3)在训练中进行细粒度标签校正的方法设计了更加稳健的自适应训练策略,这些方法主要通过师生蒸馏(Jiang等人2018;Yu等人2019b;Kumar和Ithapu 2019)来纠正标签,并在并行模型之间应用联合训练或学习互补机制(Han等人2018b;Tanaka等人2018;Kim等人2019)。 4)鲁棒损失函数也被提出作为更通用的鲁棒学习解决方案,通过提出和证明新的损失函数,例如均方绝对误差(MAE)损失(Ghosh,Kumar和Sastry 2017),梯度饱和MAE(Zhang和Sabuncu 2018),广义交叉熵(GCE)损失(Zhang和Sabuncu 2018)和对称交叉熵(SCE)(Wang等人2019c)。直接修改损失梯度大小的经验验证方法也是一个活跃的研究方向(Wang等人2019a,b)。 这些方法通过提出不同的策略和损失函数来应对噪声标签问题,并取得了一定的效果。
与基于概率的先前的重新加权方法不同,存在许多具有不确定状态的伪掩模高置信度的像素。因此,我们首次在弱监督语义分割中提出了一种新的方法来估计不确定性,以确定可能的噪声并进行减轻。此外,我们还提出了一种基于伪掩模的蒸馏方案。
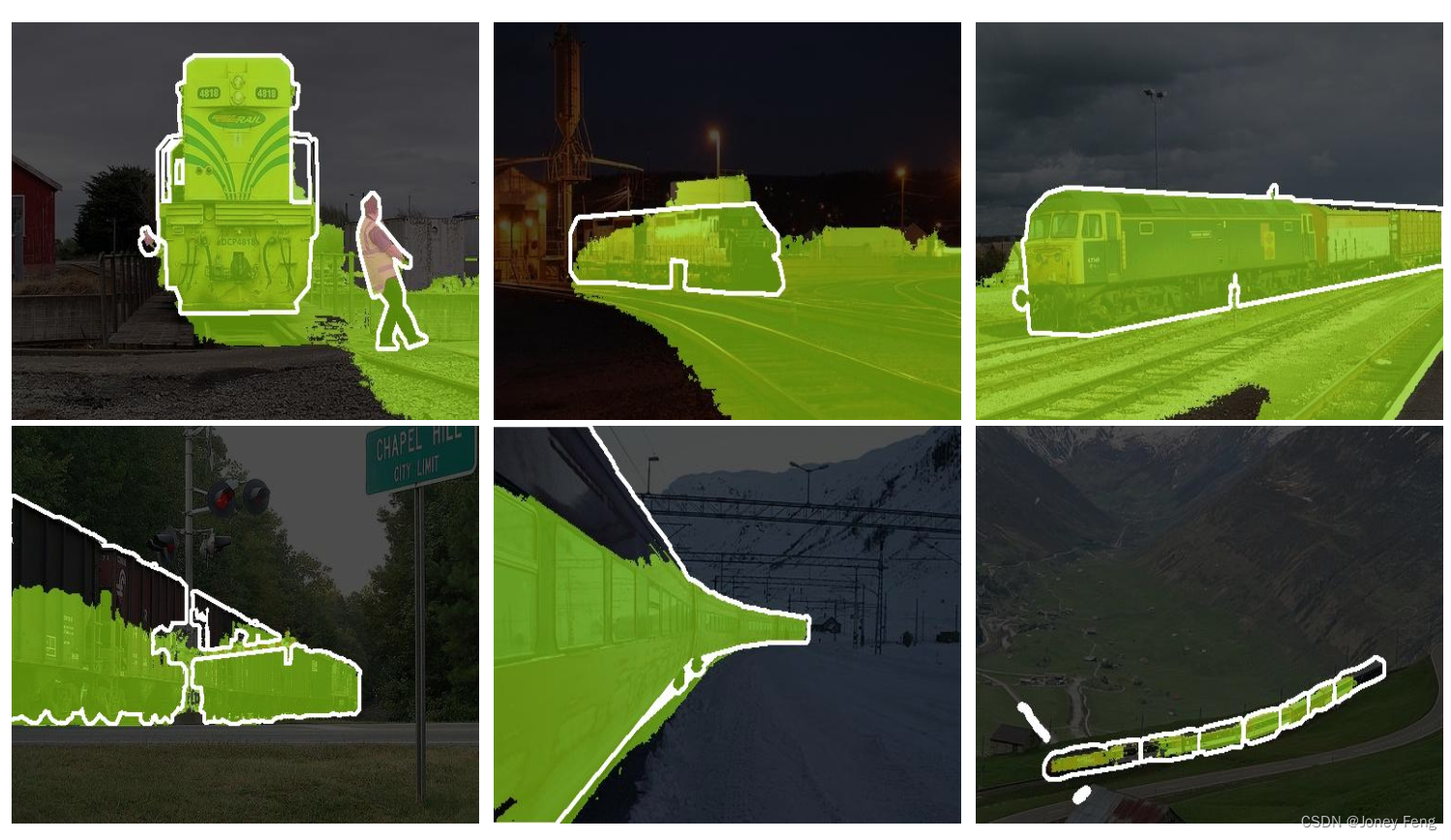
图2:最先进的弱监督语义分割方法(Li等,2021)中伪掩模中的错误像素(噪声)。顶部:宽响应尺度导致误报。底部:窄响应尺度导致漏报。白线是真实标注的边界。
3.方法论
在本节中,我们首先介绍了弱监督语义分割的流程以及我们的方法的应用位置。然后我们详细阐述了通过响应缩放进行的不确定性估计的方法。最后,我们描述了从不确定性到损失权重的转换。为了更好地理解,我们将整个过程绘制成图3。让我们定义图像I(2 RH×W)的分割函数为FS(I),该函数是从伪掩模M(2 RH×W)训练得到的。它的预测结果X(∈RC×H×W)是提出的方法“通过响应缩放进行噪声减轻的不确定性估计”(URN)的输入。URN(X)的输出C(X)是用于分割优化中噪声减轻的损失权重Y(∈RC×H×W)。
弱监督语义分割中的URN(通过响应缩放进行噪声减轻)最新的弱监督语义分割包括三个主要组件,即分类、伪掩模改进和分割。我们分别将它们命名为FC(I;L)、FR(M;I)和FS(I;M)。需要注意的是,第一个变量是推理的输入,第二个变量是训练中的真实标注。FC是使用图像级标注A进行训练的,通过操作Cam将图像I转换为类激活图CAM(∈RC×H×W),如公式1所示。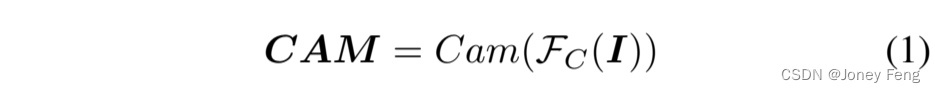
然后,CAM通过FR进行细化,得到伪掩模M。在大多数方法中,FR是密集条件随机场(dense-CRF),而在我们的基线方法中,它是PPMG(Li等,2021)。在文献(Ahn和Kwak,2018)中,它是通过随机游走的亲和网络(AffinityNet)来学习前景和背景。我们将它们统称为FR。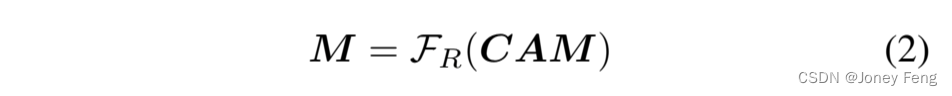
在本文中,我们专注于最后一个阶段FS,它是从M训练并与图像进行推理的。我们的改进是通过响应缩放进行的不确定性估计,通过一个转换操作添加了一个损失权重Y。我们将这些操作总结为URN。
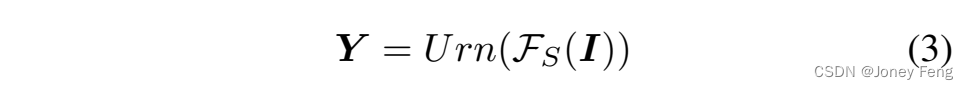
在计算了权重掩模之后,使用循环伪掩模Mc(在PMM中)对F¯S进行训练,同时使用图像I和权重掩模Y进行最终的部署。
通过响应缩放进行的不确定性估计。通过响应缩放进行的不确定性估计贝叶斯神经网络(Denker和LeCun 1990;MacKay 1992)通过学习预测的分布将深度模型转化为概率模型。然而,贝叶斯神经网络的预测很难获得。因此,它们应用不同的推理方法来通过dropout近似模型的后验分布,例如蒙特卡洛dropout(Kendall和Gal 2017)或集成方法。
在弱监督语义分割中,我们的目标是测量由于伪掩模上不可避免的噪声而产生的伪掩模的方差。但是,通过dropout或不同模型得出的预测不能直接获得伪掩模的噪声行为。激活范围可能同时过窄或过宽,因为操作目标是网络权重而不是响应本身。我们观察到,分割中伪掩模的噪声总是与前景的响应范围有关。受到这一观察的启发,我们提出了通过响应缩放进行不确定性估计的方法来减轻噪声。CRF中的缩放操作可以模拟噪声伪掩模的真实行为。在这里,这些噪声伪掩模在真实分布中的方差是反映伪掩模中真实噪声方差的不确定性。
我们从由伪掩模训练的分割模型FS开始估计,我们将其预测特征图表示为: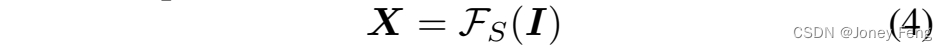
我们首先记录伪掩模M中存在的标签,并将这些标签对应于通道维度上X的索引RC¯。我们只保留正样本通道进行下一步处理。我们将选择后的特征图表示为X¯: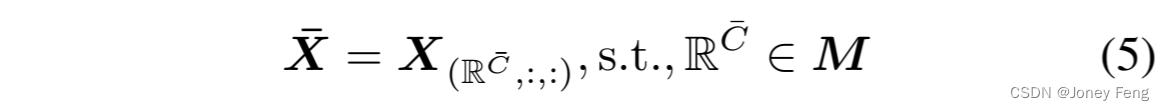
然后,我们通过指数函数和不同的幂因子S∈RN对目标通道的X¯应用缩放方案,生成不同的响应图。在这个过程中,其他通道保持不变。当缩放因子大于1时,目标类别的响应尺度下降,误报减少。如果缩放因子小于1,则尺度扩大,漏报的正像素较少。对于RC¯中的每个标签,我们调整一个通道的尺度,并保持其他通道不变,以实现特定类别的变化。对于每个类别和尺度,我们得到了缩放后的预测P ∈RC¯×N×C¯×H×W: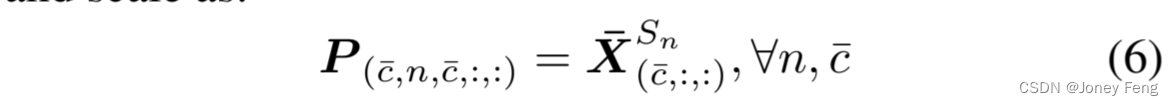
由于我们想要估计由分割预测产生的伪掩模的不确定性,我们引入了密集CRF函数Crf和argmax Arg,以生成不同尺度的伪掩模,如下所示:
在密集CRF之后,P¯表示缩放后的预测结果,然后通过argmax将第三个类别通道(从0开始排序)减少,我们得到了不同尺度和类别的伪掩模M¯∈RC¯×N×H×W: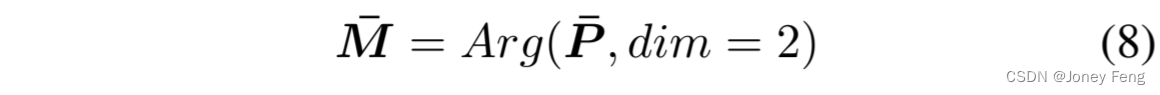
在获得尺度伪掩模之后,我们开始估计不确定性,我们选择方差σ^2 ∈RC¯×H×W作为衡量不确定性的指标,因为它简单且多用途。我们针对每个前景类别在第二维度(尺度因子)N上计算方差Var: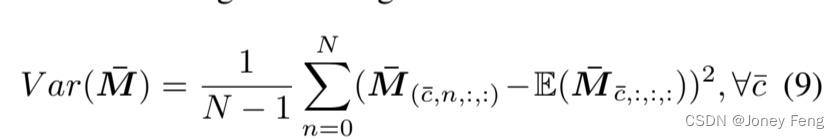
最后,我们在类别维度上应用最大操作来获得类别不可知的不确定性图U ∈RH×W,用于后续的损失重权重,使用最小-最大归一化进行规范化。
优化中的噪声缓解。在优化重权重方案中,噪声缓解被广泛应用于计算机视觉任务,如分类和检测,以平衡类别或调整某种样本的重要性。根据这种机制,我们根据通过响应缩放估计的不确定性,为可能的噪声像素部署较低的损失权重,以减轻训练中噪声的损害。由于具有高不确定性的像素应该具有较低的损失权重,以限制其影响力。我们将初始权重掩码W ∈RH×W设置为: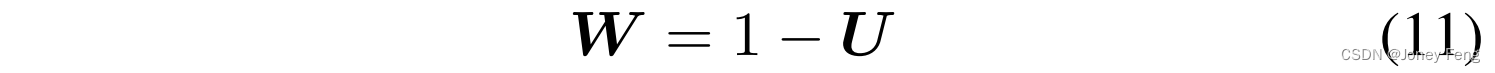
为了使权重掩码更可控,我们通过由W引导的阈值t来分配特定像素和不确定像素。我们通过较低的损失权重来减轻可能噪声的影响。我们将最终的权重掩码Y定义为: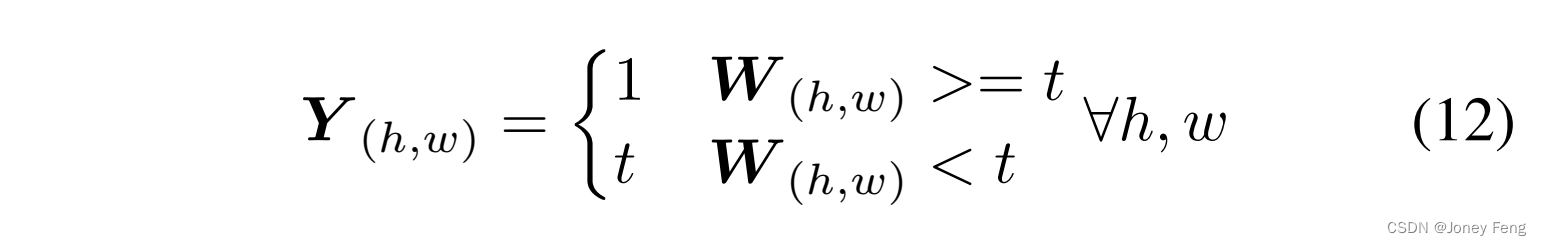
最终,我们将权重掩码Y与来自目标循环伪掩码Mc和预测图X的交叉熵损失的损失掩码L ∈ RH×W 相乘。我们得到了公式(13)中的分割损失。

图3:URN的过程。输出是权重掩码Y和带有紫色边框的循环掩码Mc。蓝色数组表示CNN的训练输入,橙色数组属于URN的操作。FR、CRF和PPMG是可选的后处理步骤。在这张图片中,权重掩码看起来像是伪蒙版和循环掩码之间的中间结果。
4.实验
4.1.数据集
PASCAL VOC 2012:这是弱监督语义分割中最常见的数据集,因为它具有适中的难度和数量。具体而言,它由20个前景类别和一个背景类别组成,分别划分为训练集、验证集和测试集,数量分别为1464张图像、1449张图像和1456张图像。除了原始数据外,还使用来自SBD(Hariharan等人,2011)的额外图像和注释,这被称为trainaug集,共有10582张图像。在弱监督语义分割中,所有像素级别的注释都在分类阶段转换为图像级别的多标签注释。
MS COCO 2012:MS COCO是目标检测的主要数据集,一些弱监督语义分割的工作也会在2012年的版本上报告结果。这是一个具有挑战性的数据集,提供的类别比PASCAL VOC更多,并且平均物体大小较小。MS COCO 14数据集的范围从0到90,其中80个类别是有效的前景类别,一个类别是背景类别,其他10个类别没有进行评估。训练集包含82081张图像,验证集的数量为40137张。与PASCAL VOC 2012相比,评估指标是平均交并比(mIoU)。
4.2.实现细节
基线:我们将我们的方法应用于PMM(Li等人,2021)。它改进了基于SEAM(Wang等人,2020)的伪掩码的生成和利用。主干网络是ResNet-38(Wu,Shen和Van Den Hengel,2019),除此之外,PMM还使用了Res2Net-101(Gao等人,2019)和ScaleNet-101(Li等人,2019),在VOC和COCO上取得了最先进的结果。在本文中,我们在这三个主干网络和ResNet-101(He等人,2016)上验证了我们的方法。我们的设置与PMM相同。不同之处在于,我们在这个分割代码库中添加了我们的URN。具体而言,代码库是MMSegmentation(MMlab,2020),PMM使用PSPnet(Zhao等人,2017)来获得SEAM论文中报告的相同结果。对于VOC,批大小为16,在8个GPU上以学习率0.005进行20000次迭代的ploy策略。训练COCO需要32个GPU,批大小为64,学习率为0.02。迭代次数为40000。对于数据增强,训练时调整后的图像大小在512到2048之间,并使用512×512的裁剪大小。此外,还应用了随机翻转和畸变作为转换。测试阶段的裁剪大小与训练阶段相同,并使用密集-CRF进行后处理。对于分类部分,使用原始的代码,因为我们只关注分割阶段。请注意,所有模型都是从ImageNet预训练的。
URN:为了节省存储空间,权重掩码以PNG格式离线保存。为了方便实现,我们将伪掩码和权重掩码连接到一个图像中,以避免多个Ground Truth和多次预处理。在重新加权过程中,我们拆分权重掩码并将其范围从0恢复到1。在VOC中,方程(7)中的比例因子S设置为{0.15,0.2,0.25,4,5,6},在COCO中设置为{0.4,0.5,0.6,2,3,4}。具体的数字通过可视化进行设置,没有严格的要求。将不确定和确定像素分开的最小损失值t通过实验确定为0.05。
伪掩码蒸馏:由于分割模型FS不是最终的部署模型,它返回预测特征图和循环掩码。因此,我们基于循环伪掩码提出了一种实用且有效的蒸馏方案。如果我们有一个预测质量较高的教师分割模型FS,其预测为Mc,我们可以通过使用这个伪掩码来训练学生模型,以获得更好的指导。在本文中,我们在VOC中将Res2Net-101设置为教师模型,在COCO中将ScaleNet-101设置为教师模型。我们还在表4中分析了伪掩码蒸馏的收益。
4.3.与当前最先进方法的比较
我们在PASCAL VOC 2012和MS COCO 2014上进行了实验,如表1所示。顶部部分的结果都是通过图像级注释进行训练的。中部部分的工作引入了额外的模型或数据集。除了(Khoreva等人,2017)之外,我们没有列出使用边界框进行监督的方法,因为我们关注的是图像级监督方法。我们按数据集整理结果,并将我们的方法与之前的最先进方法进行比较,如下所示。
PASCAL VOC 2012:我们列出了在VOC的验证集和测试集上的结果。最常用的主干网络是ResNet-101,因此我们通过颜色将这些结果与其他结果区分开来。对于ResNet-101,我们的URN在验证集上的表现超过了2020年的作品超过3%,达到了69.5%。另一个常见的主干网络是比ResNet-101更宽的ResNet-38。我们在这个主干网络上的结果在测试集上为70.6%。比我们的基线PMM高出1.6%,比在分类和分割上都迭代3次的CONTA高出约4%,也比SEAM高出4.9%。对于两个更强的主干网络ScaleNet-101和Res2Net-101,我们分别达到了70.1%和71.2%的准确率。
MS COCO 2014:与VOC相比,COCO更具挑战性。它有4倍的类别和8倍的训练图像数量,而且物体的大小比VOC更小。由于这些困难,只有少数的工作在COCO上报告了结果,而且之前只有验证集的结果。对于ResNet-38,SEAM的结果为31.7%,PMM为36.7%,而我们的URN在40.5%的准确率上实现了SOTA。对于其他的主干网络,我们的结果都高于40.5%,其中最好的mIoU为41.5%。
与使用额外信息的方法的比较:在表1的中间部分,我们列出了一些基于显著性、物体提议或额外数据集的最新方法。我们可以看到,这些方法的平均结果比没有额外信息的方法要高。但是我们的结果在每个数据集和主干网络上仍然超过它们。尤其是,在COCO上,URN在ResNet-101上比SGAN高出7.1%,这证明了我们方法的强大有效性。
表1:与VOC 2012和COCO 2014上最先进的弱监督语义分割方法的性能比较。中间部分列出了具有额外监督的方法。I,S,D分别表示图像级别标签,显著性,检测的监督。SOP表示基于分割的物体提议。其他额外信息涉及数据。y表示VGG的主干网络。对于每个主干网络,第二个结果有一个下划线,最佳结果在右下角以加粗字体标示。

4.4.消融研究
URN的有效性:为了验证我们方法的有效性,我们基于当前最先进的基线PMM进行了实验。我们想要表明,即使在一个高基线上,我们的方法也能很好地工作。我们使用评估数据集PASCAL VOC 2012的验证集和mIoU指标进行比较。在表3中,我们比较了基线和我们方法在四个主干网络上的结果。结果显示,我们的方法在所有主干网络上都取得了显著的改进。我们将之前的最先进结果从70.0%提升到了71.2%,其中在ResNet-101和ResNet-38上的提升分别为1.4%和0.9%。其中,ScaleNet-101的提升最大,增长了2.9%。这些结果表明我们的方法是有效的,并且在不同的主干网络上表现良好。
权重阈值:URN中有一个重要的超参数,用于控制重新加权的强度。为了选择Eq.(12)中t的最佳值,我们通过实验进行了搜索,如表3所示。主干网络是Res2Net,数据集是PASCAL VOC 2012的验证集。如果t设置为1,权重与原始权重相同,而0表示放弃所有不确定像素。实验结果表明,不确定区域下的像素是有用的,因此放弃所有不确定像素是不明智的。0.05是最佳值,它意味着确定像素的权重是不确定像素的20倍,且效果最好。
伪蒙版蒸馏:蒸馏是一种广泛使用的技术。在本文中,我们通过一种非常简单但实用的方式应用了这种机制。我们选择质量最好的伪蒙版作为教师,并通过它们来训练其他的学生模型。由于学生模型是部署的模型,它们能够从教师蒙版中学习知识而不增加推理时间。我们在表4中验证了伪蒙版蒸馏的增益。我们可以看到,在没有伪蒙版蒸馏的情况下,ScaleNet-101和Res2Net-101在应用URN后都提高了1.2%。而通过伪蒙版蒸馏,ScaleNet-101的提升达到了1.8%。请注意,在VOC中,Res2Net是教师模型,因此没有使用PD的结果。
概率与不确定性:由于不确定性估计依赖于分割的预测,并且一些重新加权方法在像分类这样的任务中使用概率作为度量标准,我们尝试将概率作为损失权重进行比较。具体而言,我们分离出预测的特征图,并应用softmax将概率作为损失权重。如表5所示,在相同的设置下,VOC验证集上的mIoU为70.5%,而我们的URN为71.2%。因此,概率与噪声存在正相关,但是URN效果更好。因为在WSSS中,有许多具有较高概率的错误像素。
表3:在Eq.(12)中选择阈值t。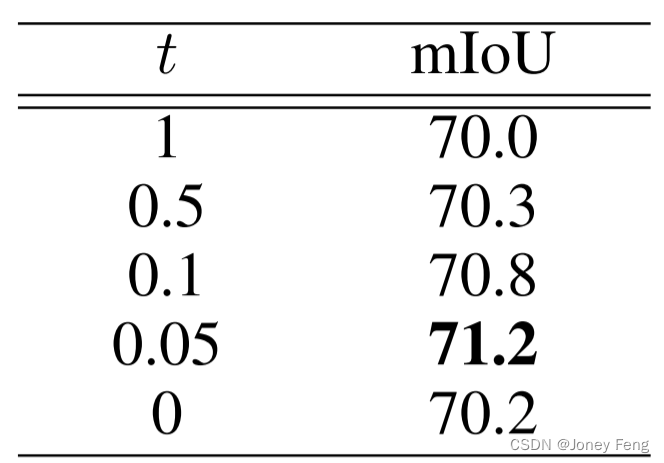
表4:伪蒙版蒸馏(PD)的结果。注:Res2Net是没有进行PD的教师模型。
4.5.视觉比较
为了验证我们方法的有效性,我们在图4中将我们的结果与SEAM和PMM在VOC12验证集上进行了比较,并在图5中展示了COCO的可视化结果。从这两个图中,我们可以看到我们的方法表现优于这两个基线方法。
5.结论
总结起来,噪声与响应尺度密切相关,我们通过响应缩放来估计不确定性,以模拟不同的响应尺度。然后我们利用从缩放中获得的不确定性来减轻分割优化中的噪声。此外,我们还提出了伪蒙版蒸馏来应对实现中较弱的主干网络。通过实验证明了我们方法的改进,并将我们的结果与之前的最新方法进行了比较,证明了我们方法的有效性。
表5:两种重新加权方案的比较。

图4:在PASCAL VOC 2012验证集上的视觉比较。
图5:在MS COCO 2014验证集上的视觉比较。