code links:dreamfusion3d.github.io
文章目录
- Overview
- What problem is addressed in the paper?
- What is the key to the solution?
- What is the main contribution?
- What can we learn from ablation studies?
- Potential fundamental flaws; how this work can be improved?
- Contents
- Diffusion model
- 我们如何在参数空间而不是像素空间中采样?
- THE DREAMFUSION ALGORITHM
- NeRF渲染过程
- TEXT-TO-3D SYNTHESIS
Overview
What problem is addressed in the paper?
we circumvent these limitations by using a pretrained 2D text-to-image diffusion model to perform text-to-3D synthesis.
What is the key to the solution?
We introduce a loss based on probability density distillation that enables the use of a 2D diffusion model as a prior for optimization of a parametric image generator. Using this loss in a DeepDream-like procedure, we optimize a randomly-initialized 3D model (a Neural Radiance Field, or NeRF) via gradient descent such that its 2D renderings from random angles achieve a low loss.
What is the main contribution?
By combining SDS with a NeRF variant tailored to this 3D generation task, DreamFusion generates high-fidelity coherent 3D objects and scenes for a diverse set of user-provided text prompts.
What can we learn from ablation studies?
Potential fundamental flaws; how this work can be improved?
Contents
和Dreamfields的不同:我们采用了类似于Dream Fields的方法,但将CLIP替换为2D扩散模型蒸馏产生的损失。
Diffusion model
扩散模型是一种潜在的变量生成模型,它学习将样本从可控制的噪声分布逐渐转换为数据分布
- 前向过程q:向x中添加噪声。
- 反向过程p:从噪音中恢复图像结构
前向过程是典型地高斯分布,从之前的时间步t的低噪声潜到时间步t + 1的高噪声。
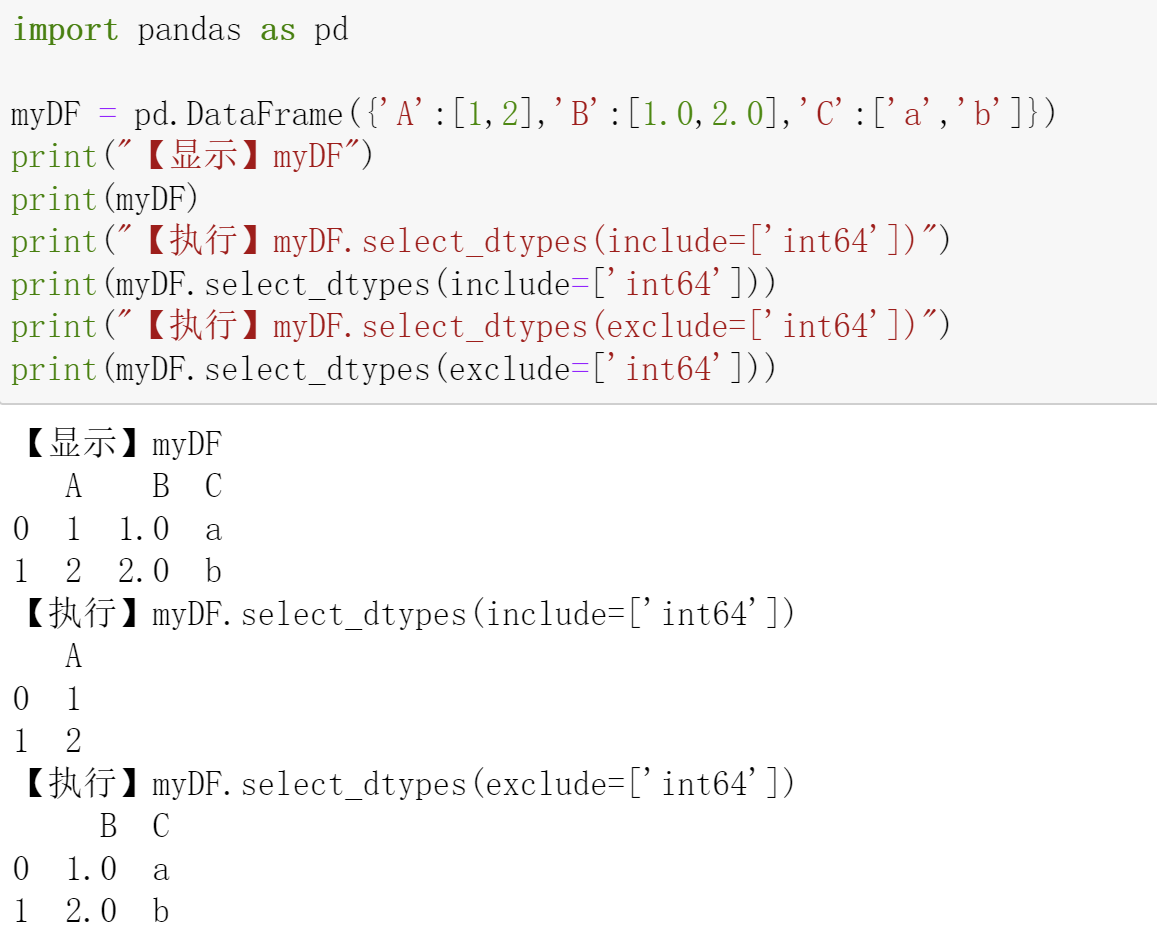
在给定初始数据点x的情况下,通过对中间时间步积分,我们可以计算出潜伏变量在时间步t处的边际分布 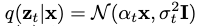
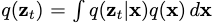
初期,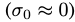 ,到最后
,到最后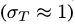 。
。
训练生成模型p从随机噪声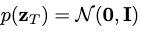 开始缓慢添加结构。 理论上,如果有足够的时间步长,最优反向处理步长也是高斯分布的,并且与最优MSE去噪器相关。 转换公式表达为:
开始缓慢添加结构。 理论上,如果有足够的时间步长,最优反向处理步长也是高斯分布的,并且与最优MSE去噪器相关。 转换公式表达为:
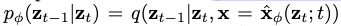 。其中
。其中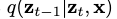 是从前向过程中得到的后验分布。
是从前向过程中得到的后验分布。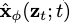 是最有去噪器学习的近似值。
是最有去噪器学习的近似值。
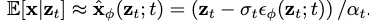
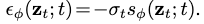
DDPM的loss:
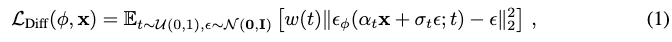
其中w是权重函数。因此,扩散模型训练可以被视为学习潜变量模型 或者学习与数据的噪声版本相对应的得分函数序列。
我们用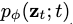 来表示近似的边缘分布,其得分函数由
来表示近似的边缘分布,其得分函数由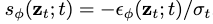 给出。
给出。
我们的工作建立在文本到图像的扩散模型上,在文本嵌入y的基础上学习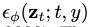 ,这些模型使用了classifer-free guidance,即通过guidance scale参数w:
,这些模型使用了classifer-free guidance,即通过guidance scale参数w: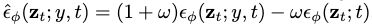 来联合学习一个无条件模型使得生成质量提高。当w>0时,可以牺牲多样性为代价来提高样本的保真度。
来联合学习一个无条件模型使得生成质量提高。当w>0时,可以牺牲多样性为代价来提高样本的保真度。
我们分别用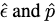 来表示噪音预测和边缘分布。
来表示噪音预测和边缘分布。
我们如何在参数空间而不是像素空间中采样?
在像素上训练的扩散模型传统上只用于采样像素。相反,我们希望创建3D模型,当从随机角度渲染时,看起来像好的图像。
For 3D, we let θ be parameters of a 3D volume and g a volumetric renderer. To learn these parameters, we require a loss function that can be applied to diffusion models.
We optimize over parameters θ such thatx = g(θ) looks like a sample from the frozen diffusion model.
通过一个模型生成样本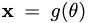 ,最小化diffusion的训练损失来更新
,最小化diffusion的训练损失来更新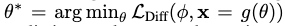 并不是那么有效,并且很难调参。
并不是那么有效,并且很难调参。
损失的梯度如下:

我们发现,省略U-Net雅可比矩阵项可以得到一个有效的梯度来优化扩散模型的dip:
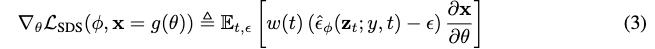
我们使用从扩散模型中学习到的分数函数表明它是加权概率密度蒸馏损失的梯度(van den Oord等人,2018)。 我们将我们的采样方法命名为Score Distillation Sampling(SDS),因为它与蒸馏有关,但使用评分函数而不是密度。由于扩散模型直接预测更新方向,我们不需要通过扩散模型反向传播;该模型就像一个高效的、固定的评论家,可以预测图像空间的编辑。
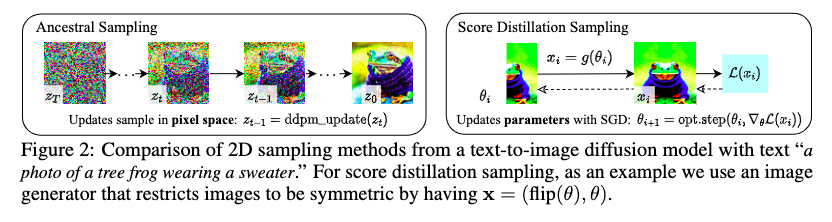
图2 证明SDS可以生成具有合理质量的约束图像。
THE DREAMFUSION ALGORITHM
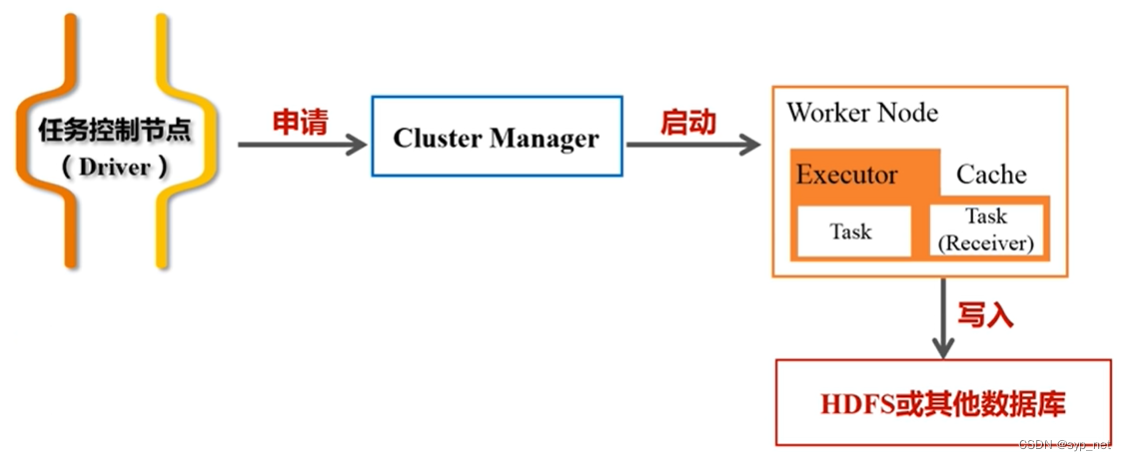
为了从文本合成一个场景,我们初始化一个具有随机权重的NeRF类模型,然后从随机的摄像机位置和角度重复渲染该NeRF的视图,使用这些渲染作为封装在Imagen周围的得分提取损失函数的输入。
图3 是方法概述
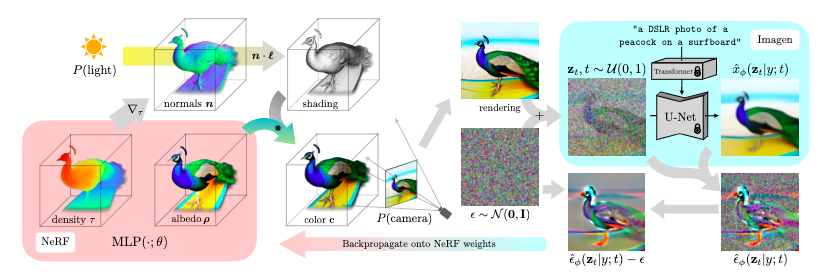
- 场景由一个神经辐射场表示,该场为每个标题随机初始化和从头训练。
- 我们的NeRF用MLP参数化体积密度和反照率(颜色)
- 我们从随机摄影机渲染NERF,使用从密度梯度计算的法线以随机照明方向对场景进行着色。
- 明暗处理显示了从单个视点看不清楚的几何细节
- 为了计算参数更新,DreamFusion扩散渲染并使用(冻结的)条件Imagen模型重建渲染,以预测注入的噪声
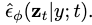
- 减去注入的噪波会产生低方差的更新方向
![STOPGRID[NERF−]](https://img-blog.csdnimg.cn/a624d550431440529891a7c80ea1b8c6.png) ,该方向将通过渲染过程反向传播以更新ˆφMLP参数。
,该方向将通过渲染过程反向传播以更新ˆφMLP参数。
NeRF渲染过程
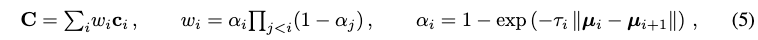
Our model is built upon mip-NeRF 360 (Barron et al., 2022):
Shading.
传统的NeRF模型发射辐射,这是RGB颜色条件下的射线方向的3D点被观察。相反,我们的MLP参数化了表面本身的颜色,然后通过我们控制的照明来照亮它(这个过程通常称为“着色”)。
We use an RGB albedo ρ (the color of the material) for each point:

where τ is volumetric density. 计算3D点的最终阴影输出颜色需要一个法向量,该法向量指示物体几何形状的局部方向。这个表面法向量可以通过将密度τ相对于三维坐标μ的负梯度归一化来计算:
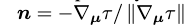
我们使用漫反射来渲染沿着射线的每个点的颜色:
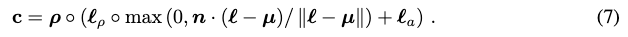
we find it beneficial to randomly replace the albedo color ρ with white (1, 1, 1) to produce a “textureless” shaded output : 这可以防止模型产生退化的解决方案,其中场景内容被绘制到平面几何上以满足文本条件。
Scene Structure.
We composite the rendered ray color on top of this background color using the accumulated alpha value. This prevents the NeRF model from filling up space with density very close to the camera while still allowing it to paint an appropriate color or backdrop behind the generated scene. For generating single objects instead of scenes, a reduced bounding sphere can be useful.
Geometry regularizers.
We include a regularization penalty on the opacity along each ray similar to Jain et al. (2022) to prevent unneccesarily filling in of empty space.
TEXT-TO-3D SYNTHESIS
For each text prompt, we train a randomly initialized NeRF from scratch. Each iteration of DreamFusion optimization performs the following:
- (1) randomly sample a camera and light,
- (2) render an image of the NeRF from that camera and shade with the light,
- (3) compute gradients of the SDS loss with respect to the NeRF parameters,
- (4) update the NeRF parameters using an optimizer.
We detail each of these steps below, and present pseudocode in Appendix 8




![[go]汇编语言](https://img-blog.csdnimg.cn/6e96d7b0a8c94d1397d0c2fd4bd25ad0.png#pic_center)