参考资料:
《旅行商问题(TSP)、车辆路径问题(VRP,MDVRP,VRPTW)模型介绍》
本文对《基于GA算法解决VRPTW》的分析和思考.具体的代码可以参考
《Python实现(MD)VRPTW常见求解算法——遗传算法(GA)》 .
文章目录
- 壹、VRPTW
- 一. 定义类
- 二、数据读取
- 三. 构造初始解空间
- 四、计算任意两点间的距离
- 四、VRPTW的解的解码
- 五. VRPTW的解码的代码
- 六、计算适应度
- 七、二元锦标赛
- 八、基因的交叉和变异
- 九、主程序
壹、VRPTW
由于VRP问题的持续发展,考虑需求点对于车辆到达的时间有所要求之下,在车辆途程问题之中加入时窗的限制,便成为带时间窗车辆路径问题(VRP with Time Windows, VRPTW)。带时间窗车辆路径问题(VRPTW)是在VRP上加上了客户的被访问的时间窗约束。在VRPTW问题中,除了行驶成本之外, 成本函数还要包括由于早到某个客户而引起的等待时间和客户需要的服务时间。在VRPTW中,车辆除了要满足VRP问题的限制之外,还必须要满足需求点的时窗限制,而需求点的时窗限制可以分为两种,一种是硬时窗(Hard Time Window),硬时窗要求车辆必须要在时窗内到达,早到必须等待,而迟到则拒收;另一种是软时窗(Soft Time Window),不一定要在时窗内到达,但是在时窗之外到达必须要处罚,以处罚替代等待与拒收是软时窗与硬时窗最大的不同
模型参考1


举例: 假设有一个仓库(会分隔为起始仓库和终点仓库,用0和n+1表示映射的ID),有多个快递员配备相同的车(车辆的容量为Q)。车辆的映射ID是从 1 , 2 , . . . k 1,2,...k 1,2,...k。对 n n n个顾客去配送物品,顾客的映射ID为从 1 , 2... n 1,2...n 1,2...n,每个顾客的需求为 q i q_i qi。每个顾客可以接受快递的时间窗口为 [ a i , b i ] [a_i,b_i] [ai,bi]。任意两个节点之间的成本总 c i j c_{ij} cij表示。
- 顾客集合: 即需求节点的集合
- n+1:终点仓库; 0:起点仓库;(本质是同一个,为了区分方向而设)
- 所有的顶点: 顾客集合(多个需求节点)+depot(单个)
- 车辆集合: 所有运货的车辆
- 顾客时间窗口: 需求节点(被服务的时间), 类似于上门取件(快递)定在8-9点某个时间段.
- 路径成本: 可能是距离成本,也可能是时间成本
- y i k y_{ik} yik表示顾客 i i i制定给车辆 k k k服务.或者说由车辆 k k k配送节点 i i i的需求
☀️约束条件
- 每个节点只能访问一次(对应公式3.3)
- 对于车辆某k,除了终点仓库的其他任意节点到达节点 h h h的次数应等于节点 h h h到达除了起始仓库以外的任意节点的次数. (即出入节点 h h h的次数应该相等,对应公式3.4)–车不在任意需求节点停留。车总会返回仓库
- 对于车辆某k, 其服务的所有站点的所消耗车辆的空间容量应小于Q.(车容量限制,对应公式3.5)
- 车辆k在站点i到达的时间+节点i到节点j的时间+…<到达节点j的时间。(时间上的顺序性?),对应公式3.6
- 对于车辆k在节点i的到达时间,要满足硬时窗的约束。对应公式3.7
☀️目标函数:所有车辆轨迹的成本
☀️思考:
- 解空间的设置,包含了解的存在性。所以,解空间一定要全。
- 解的编码,根据约束条件获得解的编码。
- 根据解码后的解,求目标函数,适应度。
- 根据基因遗传算法,逐步优化解
参考模型2

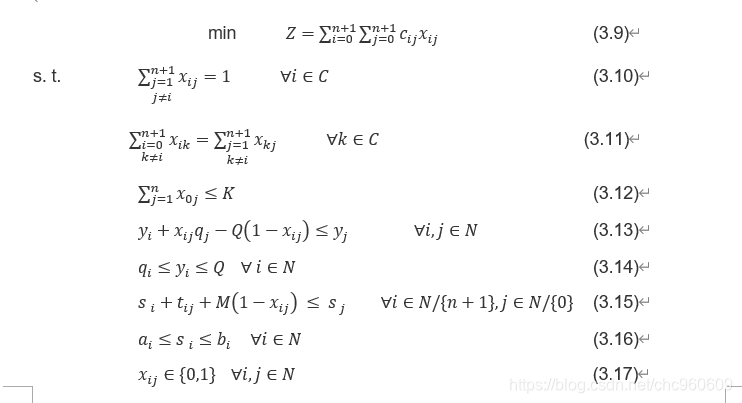
一. 定义类
定义解的结构,需求节点的结构,depot的结构,model的属性结构.
# 数据结构:解
class Sol():
def __init__(self):
self.obj=None # 目标函数值
self.fit = 0
self.node_no_seq=[] # 解的编码
self.route_list=[] # 解的解码
self.timetable_list=[] # 车辆访问各点的时间
self.route_distance = None
# 数据结构:需求节点
class Node():
def __init__(self):
self.id=0 # 节点id
self.x_coord=0 # 节点平面横坐标
self.y_cooord=0 # 节点平面纵坐标
self.demand=0 # 节点需求
self.start_time=0 # 节点开始服务时间
self.end_time=1440 # 节点结束服务时间
self.service_time=0 # 单次服务时长
self.vehicle_speed = 0 # 行驶速度
# 数据结构:车场节点
class Depot():
def __init__(self):
self.id=0 # 节点id
self.x_coord=0 # 节点平面横坐标
self.y_cooord=0 # 节点平面纵坐标
self.start_time=0 # 节点开始服务时间
self.end_time=1440 # 节点结束服务时间
self.v_speed = 0 # 行驶速度
self.v_cap = 80 # 车辆容量
二、数据读取
demand.csv
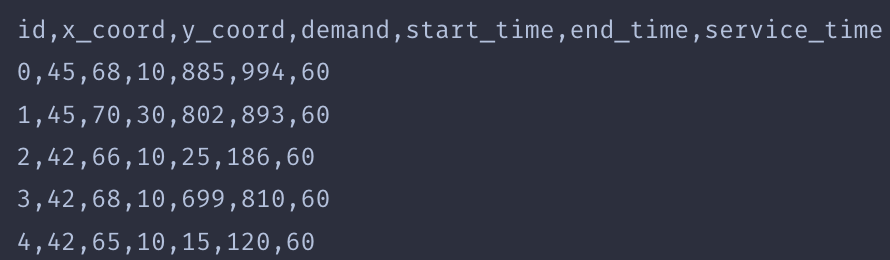
depot.csv

定义def readCSVFile(demand_file,depot_file,model):函数后.测试一下
model=Model()
demand_file="demand.csv"
depot_file="depot.csv"
readCSVFile(demand_file,depot_file,model) #运行,没有return
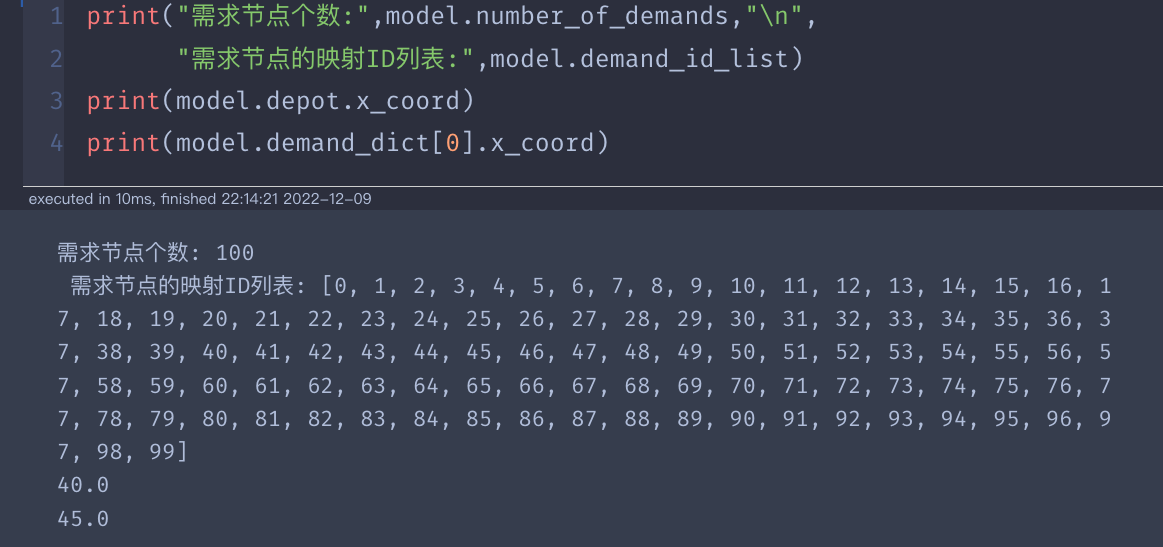
查看结果:
三. 构造初始解空间
同《实践CVRP》中的一摸一样
# 3.构造初始解
def genInitialSol(model):
node_no_seq=copy.deepcopy(model.demand_id_list)
for i in range(model.popsize):
random.shuffle(node_no_seq)
sol=Sol()
sol.node_no_seq=copy.deepcopy(node_no_seq)
model.sol_list.append(sol)
四、计算任意两点间的距离
# 4.初始化参数:计算距离矩阵时间矩阵及初始信息素
def calDistanceTimeMatrix(model):
for i in range(len(model.demand_id_list)):
from_node_id = model.demand_id_list[i]#需求节点1
for j in range(i + 1, len(model.demand_id_list)):
to_node_id = model.demand_id_list[j]#需求节点2
dist = math.sqrt((model.demand_dict[from_node_id].x_coord - model.demand_dict[to_node_id].x_coord) ** 2
+ (model.demand_dict[from_node_id].y_coord - model.demand_dict[to_node_id].y_coord) ** 2)
#求节点1和节点2之间的距离,并保存
model.distance_matrix[from_node_id, to_node_id] = dist
model.distance_matrix[to_node_id, from_node_id] = dist
#节点1和节点2之间的时间距离=路程距离/速度,并保存
model.time_matrix[from_node_id,to_node_id] = math.ceil(dist/model.depot.v_speed)
model.time_matrix[to_node_id,from_node_id] = math.ceil(dist/model.depot.v_speed)
# depot和节点1之间的距离,时间距离,并保存
dist = math.sqrt((model.demand_dict[from_node_id].x_coord - model.depot.x_coord) ** 2 +
(model.demand_dict[from_node_id].y_coord - model.depot.y_coord) ** 2)
model.distance_matrix[from_node_id, model.depot.id] = dist
model.distance_matrix[model.depot.id, from_node_id] = dist
model.time_matrix[from_node_id,model.depot.id] = math.ceil(dist/model.depot.v_speed)
model.time_matrix[model.depot.id,from_node_id] = math.ceil(dist/model.depot.v_speed)
四、VRPTW的解的解码
在CVRP中,我们通过对TSP解的切割,获得了CVRP的解. 那么我们如何获得VRPTW的解呢?
节点的ID序列:[3,→4,→2,→0,→1,→9→8→7→6→5] ,设depot的ID号为:d1 .这个序列(TSP的一个解)在解码后(满足相关约束条件后)得到一个总路径距离最小的(VRPTW)解.
假设该序列,就考虑满足约束条件而言,VRPTW可有(多个)路径规划.甚至会存在sol3下的极限情况(不限制回depot的情况下).换而言之,sol3是必定满足约束条件的.
- sol1=[3→4→d1,2→0→1→d1,9→8→d1,7→6→5]
- sol2=[3→d1, 4→2→0→1→d1,9→8→7→6→5]
- Sol3=[3→d1,4→d1,2→d1,0→d1,1→d1,9→d1,8→d1,7→d1,6→d1,5→d1]
因此序列,就满足约束条件而言,会存在一至多个路径规划, 我们在所有的路径规划中,选择总的路径距离最小的规划,当作我们对这列序号的解码.也就是解码存在唯一性.-----这是不限制车辆的次数的情况下.
那么思考:如果限制车辆的次数, 如果该序列在限制条件的约束下,如果找不到一个路径规划怎么办? 那么是否考虑该序列的循环情况的解呢?比如
L1=[3,→4,→2,→0,→1,→9→8→7→6→5]没有路径规划,而L2=[4,→2,→0,→1,→9→8→7→6→5–>3]存在路径规划,是否能将L1的解码后的解映射为L2的解码后的解呢??
那么如何解码呢?
1.设置解的字典Pred中所有需求节点的初始映射值为d1(depot),用于保存解的顺序结构.
2. 设置解的距离字典V={(3,inf),(4,inf),…,(5,inf)},表示该节点到结束路径规划所需要的最小距离成本(或其他成本). 这个成本的初始值为inf(正无穷),并特设v(depot)=0.
3. 对于序列L1中的节点,我们顺序判断,节点是否可以为所有后续节点的前导节点.而对于一个(需求)节点的后续节点,有两种分类(先假设成立):
注意到i表示节点n_1, j表示节点n_2;n_1的前一个是n_4, 而n_2的前一个是n_3
-
depot仓库节点(类似于sol2的形式):(n1_=n_2)
Depot(起点)->n_1(n_2)==>depot(终点)①时间约束:
节点的最早到达时间arrival=max(depot的开始服务时间+depot致节点的移动时间,
该节点的开始服务时间)
节点的最早离开时间departure=到达时间(上公式)+该节点的服务时间
距离成本cost=仓库到该节点的距离的2倍(一去一回)
②容量约束:
累加需求(这只该节点的需求)<车容量 且 节点离开时间<=节点服务的结束时间
③路径的最小化:采用狄利克雷最小距离的方法
前导节点(当前节点的来源):如果为depot, 则前面的行程为0,即V(d1)=0.
比较{前导节点+cost(前导,当前), 记录的当前节点的成本}
如果前者更小,则更新当前节点的成本,并更新Pred[当前节点]=前导节点第一步必定完成了depot→n_1(3)→depot. v(3)=0+cost,pred[3]=d1
-
需求节点(类似于sol1的形式):(n_1!=n_2)
Depot[n_4]→3[n_1] ==n_3[3]→n_2[4]①时间约束
后续节点到达时间arrival=max(离开时间+当前节点至后续节点的移动时间,
后续节点的服务开始时间)
后续离开时间departure=到达时间+后续节点的服务时间
距离成本=成本-当前节点返回depot的成本+当前节点至后续节点的距离成本+后续节点返回depot的成本.
②容量约束
累计需求(到当前节点的需求+后续节点的需求)< 车容量
后续节点的离开时间<=后续极点的服务结束时间
③路径的最小化:采用狄利克雷最小距离的方法.同理
五. VRPTW的解码的代码
- 根据序列列表和Pred(节点映射到前导节点), 书写其route的列表形式
# 5.根据Split结果,提取路径
def extractRoutes(node_no_seq,Pred,model):
route_list = []
route = [model.depot.id]
label = Pred[node_no_seq[0]]#初始标签为仓库标签
for node_id in node_no_seq:
# 如果需求节点的前导节点为depot,则将需求节点放入route
if Pred[node_id] == label:
route.append(node_id)
else:
# 需求界定的前导节点为depot,则将depot放入route
route.append(model.depot.id)
route_list.append(route)#将rout放入route表
route = [model.depot.id,node_id]#开创新route,放入depot和需求节点
label = Pred[node_id]#当前节点的后续接待你作为标签
route.append(model.depot.id)
route_list.append(route)
#[[-1,2,3,8,-1],
#[-1,1,0,4,6,-1],
#[-1,5,7,9,-1] ] route_list
return route_list
- 更据chapter 四的思想,对解进行解码(切割), 并获得路径的列表形式.
## 6.对某个解进行分割
def splitRoutes(node_no_seq,model):
depot=model.depot# 仓库
V={id:float('inf') for id in model.demand_id_list}
# demand_id_list:需求节点id集合
# V:将需求节点id--映射--->[成本] ,初始值为正无穷
V[depot.id]=0
Pred={id:depot.id for id in model.demand_id_list}
# Pred:需求节点id--映射-->depot,(固定值,表明可从任何需求节点返回depot)
for i in range(len(node_no_seq)):
n_1=node_no_seq[i] #节点1(ID)
demand=0
departure=0 #离开?
j=i
cost=0#成本?
while True:
n_2 = node_no_seq[j]#节点2(ID),可与节点1相同
demand = demand + model.demand_dict[n_2].demand#累加节点2的需求
if n_1 == n_2:
# 如果节点1和节点2相同
# 比较{节点1的服务开始时间, 仓库的服务开始时间+仓库到节点1的时间}的大小,从而确定节点2的最早到达时间
arrival= max(model.demand_dict[n_2].start_time,
depot.start_time+model.time_matrix[depot.id,n_2])
# 节点2的最早离开时间=最早到达时间+节点2的服务时间
departure=arrival+model.demand_dict[n_2].service_time
# depot-->n_2的距离成本
cost = model.distance_matrix[depot.id, n_2] * 2
else:
# 在节点1和节点2不相同的时候
n_3=node_no_seq[j-1]#n_2的前面索引的一个
# n_3==n_1
arrival= max(departure+model.time_matrix[n_3,n_2],#(节点1)离开时间+节点3到节点2的行驶时间
model.demand_dict[n_2].start_time)#节点2的服务时间
# 离开时间=到达时间+节点2的服务时间
departure=arrival+model.demand_dict[n_2].service_time
# 成本=原距离成本-节点3到depot的距离+节点3到节点2的距离+节点2到depot的距离
cost = cost - model.distance_matrix[n_3, depot.id] + model.distance_matrix[n_3, n_2] + \
model.distance_matrix[n_2, depot.id]
if demand<=model.depot.v_cap and departure<= model.demand_dict[n_2].end_time:
#如果累加需求<=车的容量 且 离开时间<节点2的服务结束时间
if departure+model.time_matrix[n_2,depot.id] <= depot.end_time:
# 离开时间+节点2到达仓库的时间<=仓库的结束时间
n_4=node_no_seq[i-1] if i-1>=0 else depot.id
# 如果i不是最后一个节点,则n_4为n_1的前一个节点,否则为仓库
if V[n_4]+cost <= V[n_2]:
V[n_2]=V[n_4]+cost
Pred[n_2]=i-1
j=j+1
else:
break
if j==len(node_no_seq):
break
route_list= extractRoutes(node_no_seq,Pred,model)
return route_list
六、计算适应度
- 要使路径最小话,因此对于一个规划来说,要求得其总距离.
# 7.计算路径费用
def calTravelCost(route_list,model):
#[[-1,2,3,8,-1],
#[-1,1,0,4,6,-1],
#[-1,5,7,9,-1] ] route_list,举例
timetable_list=[]
route_distance = []
total_distance=0
for route in route_list:
timetable=[]
distance = 0
for i in range(len(route)):
if i == 0:
depot_id=route[i]#每个route的第一个为depot
next_node_id=route[i+1]
travel_time=model.time_matrix[depot_id,next_node_id]#depot至后续节点的时间
departure=max(model.depot.start_time,
model.demand_dict[next_node_id].start_time-travel_time)
#离开时间=max(仓库的服务开始时间,后续节点的服务开始时间-路程时间)
timetable.append((departure,departure))
elif 1<= i <= len(route)-2:
#i:从第一个需求节点到倒数第二个需求节点
last_node_id=route[i-1]#前导节点
current_node_id=route[i]#当前节点
current_node = model.demand_dict[current_node_id]#当前节点的需求
travel_time=model.time_matrix[last_node_id,current_node_id]#移动时间距离
arrival=max(timetable[-1][1]+travel_time,current_node.start_time)
#到达时间=max([上一组的]离开时间+行驶时间, 当前节点的服务开始时间)
departure=arrival+current_node.service_time
#离开时间=到达时间+当前节点的服务时间
timetable.append((arrival,departure))
#当前节点的(到达时间,离开时间)保存
distance += model.distance_matrix[last_node_id, current_node_id]
#累计距离
else:
last_node_id = route[i - 1]#倒数第二个节点(最后一个需求节点)
depot_id=route[i]#后续节点为仓库
travel_time = model.time_matrix[last_node_id,depot_id]#行驶时间
departure = timetable[-1][1]+travel_time#离开时间
timetable.append((departure,departure))
distance +=model.distance_matrix[last_node_id,depot_id]#累计距离
total_distance += distance#总距离
route_distance.append(distance)#每段的距离保存
timetable_list.append(timetable)#每段的时间集,保存[[(,)(,)],[(,)]]
return timetable_list,total_distance,route_distance
- 计算整个种群的适应度
# 8.计算适应度
def calFit(model):
#calculate fit value:fit=Objmax-obj
max_obj=-float('inf')
best_sol=Sol()#record the local best solution
best_sol.obj=float('inf')
for sol in model.sol_list:
node_no_seq=sol.node_no_seq
sol.route_list= splitRoutes(node_no_seq, model)
sol.timetable_list,sol.obj, sol.route_distance = calTravelCost(sol.route_list, model)
if sol.obj > max_obj:
max_obj = sol.obj
if sol.obj < best_sol.obj:
best_sol = copy.deepcopy(sol)
#calculate fit value
for sol in model.sol_list:
sol.fit = max_obj-sol.obj
#update the global best solution
if best_sol.obj<model.best_sol.obj:
model.best_sol=best_sol
七、二元锦标赛
同CVRP一样
八、基因的交叉和变异
因为,交叉和变异都是基于基因的变化,而不是解码后的变化. 因此, 其函数同前面CVRP完全一样.
九、主程序
其结构顺序是基于基因遗传算法思想的,这个没有改变,则运行框架不变.