文章目录
- kube-proxy的工作原理
- netfilter的运行机制
- ipvs和iptables有什么区别?
- iptables在网络栈的hook点更多,而ipvs的hook点很少
- iptables的hook点
- ipvs的hook点
- 如何切换?
- ipvs安装
- 为何推荐ipvs?
- 为什么iptables或者ipvs在每个节点上都是全量呢?
kube-proxy的工作原理
每台机器上都运行一个kube-proxy服务’它监听API server中service和endpoint的变化情 况,并通过iptables等来为服务配置负载均衡(仅支持TCP和UDP)
kube-proxy可以直接运行在物理机上,也可以以static pod或者DaemonSet的方式运行。 kube-proxy当前支持一下几种实现
•userspace:最早的负载均衡方案,它在用户空间监听一个端口,所有服务通过iptables 转发到这个端口,然后在其内部负载均衡到实际的Pod。该方式最主要的问题是效率低, 有明显的性能瓶颈。
•iptables:目前推荐的方案,完全以iptables规则的方式来实现service负载均衡。该方式 最主要的问题是在服务多的时候产生太多的iptables规则,非增量式更新会引入一定的时 延,大规模情况下有明显的性能问题
•ipvs:为解决iptables模式的性能问题,vl.8新增了ipvs模式,采用增量式更新,并可以 保证service更新期间连接保持不断开
•winuserspace:同userspace,但仅工作在windows上
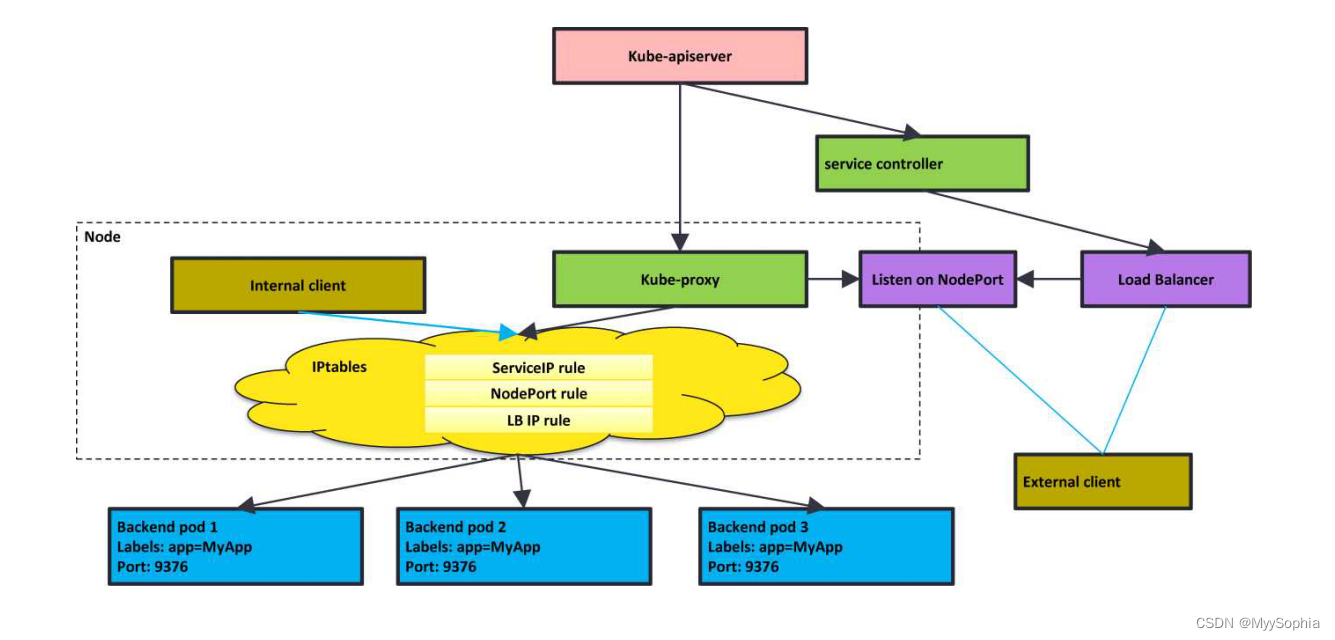
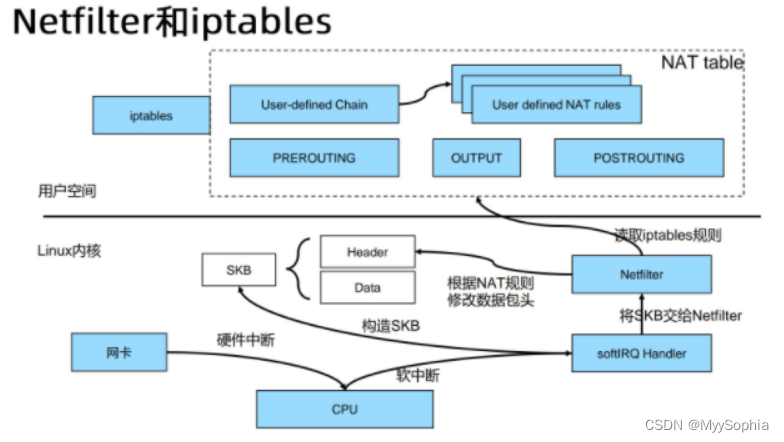
netfilter的运行机制
ipvs和iptables有什么区别?
iptables是Linux操作系统中的一种防火墙技术,它能够通过配置规则来控制网络流量,从而保护网络安全。iptables能够支持多种网络负载均衡算法,但它并不能实现高性能的负载均衡,适用于对性能要求较低的场景。
ipvs是Linux操作系统中的一种内核级别的负载均衡技术,它能够在内核中实现负载均衡,从而提高网络服务的性能和可用性。ipvs能够支持多种负载均衡算法,并且具有高性能、高可用性和高可扩展性的特点。适用于对性能要求较高的场景。
总的来说,iptables更适用于控制网络流量和保护网络安全,而ipvs更适用于提高网络服务的性能和可用性。它们在功能上有所不同,但也可以结合使用,以实现更加完善的网络负载均衡。
from chatGPT
iptables在网络栈的hook点更多,而ipvs的hook点很少
我的理解: k8s为何要使用iptables? 主要是做负载均衡的,而iptables的链路较长hook较多。当iptables规则较多时会有性能问题,因此ipvs横空出世,解决了iptables的性能问题还基于netfilter对svc进行负载。
k8s的svc的雄心是做一个开箱即用的分布式负载均衡,而不像springcloud针对java做的哪一套.
iptables的hook点
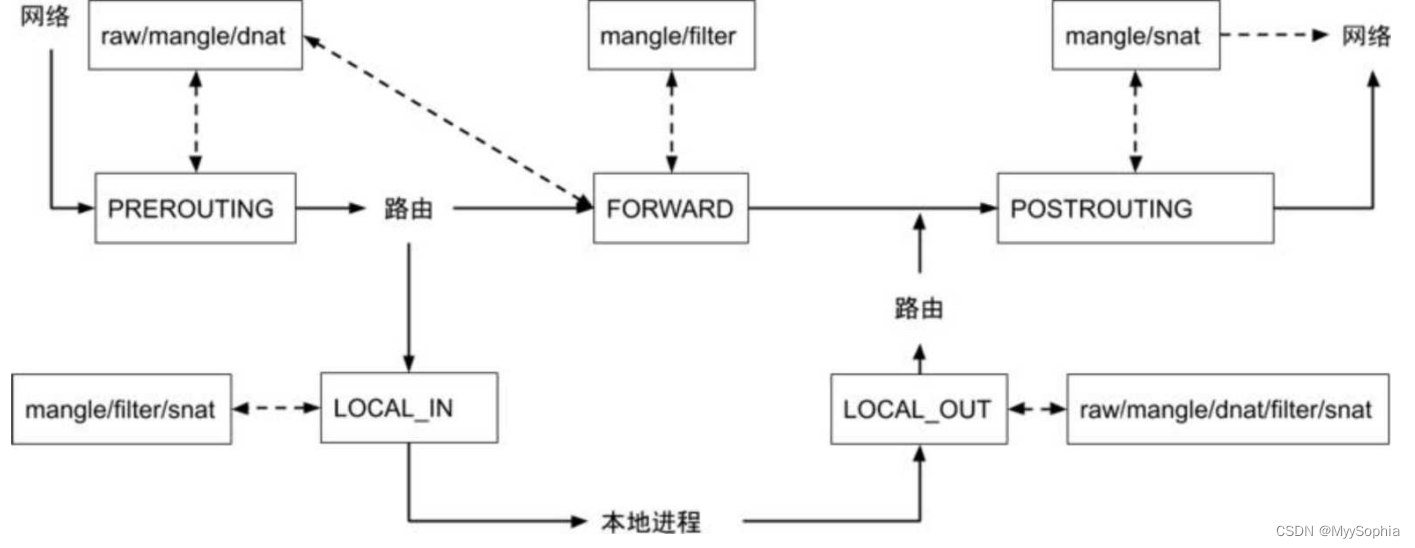
ipvs的hook点
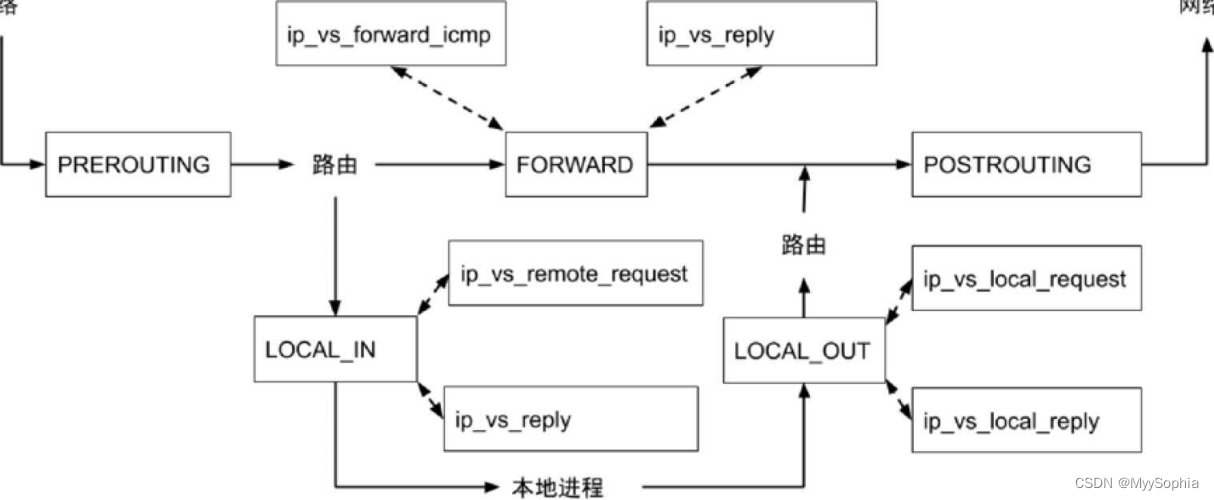
IPVS支持的锚点和核心函数

如何切换?
kube-proxy 的实现方式可以是ipvs或者iptables.
mode字段进行切换,如果使用ipvs需要加载相应的内核模块.
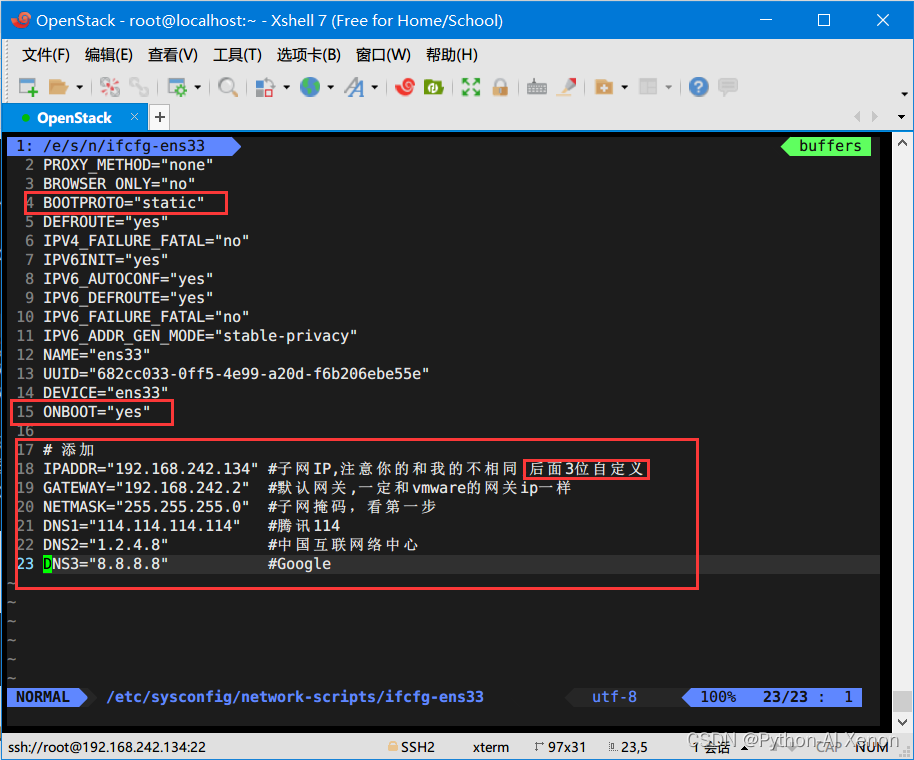
#] more /etc/kubernetes/kube-proxy.yaml
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 10.50.10.31
clientConnection:
kubeconfig: /etc/kubernetes/kube-proxy.kubeconfig
clusterCIDR: 10.244.0.0/16
healthzBindAddress: 10.50.10.31:10256
kind: KubeProxyConfiguration
metricsBindAddress: 10.50.10.31:10249
mode: "ipvs"
ipvs安装
如果模块未安装kube-proxy会自动回退到iptables
# 1.安装ipset和ipvsadm
[root@master ~]# yum install ipset ipvsadmin -y
# 2.添加需要加载的模块写入脚本文件
[root@master ~]# cat <<EOF> /etc/sysconfig/modules/ipvs.modules
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
# 3.为脚本添加执行权限
[root@master ~]# chmod +x /etc/sysconfig/modules/ipvs.modules
# 4.执行脚本文件
[root@master ~]# /bin/bash /etc/sysconfig/modules/ipvs.modules
# 5.查看对应的模块是否加载成功
[root@master ~]# lsmod | grep -e ip_vs -e nf_conntrack_ipv4
为何推荐ipvs?
iptables模式 如果有1000个pod,首个包过来以千分一的概率撞到,因此首包的延迟较高。另外一个原因是iptables是不做增量处理,每次都做全量改变,当iptables很大的时候会很慢.
而ipvs 进行了分层. 只会在iptables中增加一条iptables 规则 KUBE-NODE-PORT-TCP ,ipset 会把相同的规则(ip + 端口)放在ipset这简化了iptables。
-A KUBE-MARK-DROP -j MARK --set-xmark 0x8000/0x8000
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE -A KUBE-SEP-55QZ6T7MF3AHPOOB -s 10.244.1.6/32 -m comment --comment "default/http:" -j KUBE-MARK-MASQ -A KUBE-SEP-55QZ6T7MF3AHPOOB -p tcp -m comment --comment "default/http:" -m tcp -j DNAT --to-destination 10.244.1.6:80 -A KUBE-SEP-KJZJRL2KRWMXNR3J -s 10.244.1.5/32 -m comment --comment "default/http:" -j KUBE-MARK-MASQ -A KUBE-SEP-KJZJRL2KRWMXNR3J -p tcp -m comment --comment "default/http:" -m tcp -j DNAT --to-destination 10.244.1.5:80 -A KUBE-SERVICES -d 10.101.85.234/32 -p tcp -m comment --comment "default/http: cluster IP" -m tcp --dport 80 -j KUBE-SVC-7IMAZDGB2ONQNK4Z
-A KUBE-SVC-7IMAZDGB2ONQNK4Z -m comment --comment "default/http:" -m statistic --mode random -probability 0.50000000000 -j KUBE-SEP-KJZJRL2KRWMXNR3J
-A KUBE-SVC-7IMAZDGB2ONQNK4Z -m comment --comment "default/http:" -j KUBE-SEP-55QZ6T7MF3AHPOOB
•iptables: 完全以iptables规则的方式来实现service负载均衡。该方式 最主要的问题是在服务多的时候产生太多的iptables规则,非增量式更新会引入一定的时 延,大规模情况下有明显的性能问题
•ipvs:为解决iptables模式的性能问题,vl.8新增了ipvs模式,采用增量式更新,并可以 保证service更新期间连接保持不断开
为什么iptables或者ipvs在每个节点上都是全量呢?
执行如下命令你会发现在所有节点上都会这个clusterip 10.96.70.31 的ipvs规则。这是为何呢?
ansible k8s-all -m shell -a 'ipvsadm -l -n | grep -C 5 '10.96.70.31''
想一下之前那种集中式的负载均衡,所有流量过来都要经过那台负载均衡,而k8s直接将负载均衡做到了每一个节点上,这和svc的设计结合起来就是一个分布式的负载均衡.