一、说明
上文 【计算机视觉中的 GAN 】或多或少是GANs,生成学习和计算机视觉的介绍。我们达到了在 128x128 图像中生成可区分图像特征的程度。但是,如果你真的想了解GAN在计算机视觉方面的进展,你肯定必须深入研究图像到图像的翻译。尽管这是第一个成功的模型,但他们设计GAN的原则仍然被考虑在内。
在这一部分中,我们将继续我们在计算机视觉领域的GAN之旅,检查更复杂的设计,从而获得更好的视觉结果。我们将重新讨论模式折叠、3D 对象生成、单个 RGB 图像到 3D 对象生成以及改进质量的图像到图像映射。
二、AC-GAN(使用辅助分类器GANs的条件图像合成2016)
这篇惊人的论文全面介绍了首次尝试生成详细的高分辨率图像样本(当时为 128x128),这些样本在类之间具有高度可变性(类内可变性)。正如我们已经看到的,类是条件标签。在这项工作中,训练了一个 GAN,它同时尝试生成 10 个不同的类!
众所周知,当您尝试强制模型执行其他任务(多任务学习)时,原始任务的性能可以显着提高。但是,你怎么能做到呢?使用重建损失!
2.1 辅助或重建损失
结合InfoGAN(信息正则化)和条件GAN(使用图像标签)的思想,AC-GAN是GAN的扩展,它使用侧面信息(提供图像类)。他们不只是向G和D提供条件信息,而是让D学习重建这个边信息(所谓的重建损失)。
具体来说,他们修改了D以包含一个辅助(额外)解码器网络,该网络可以利用标准分类设置中的预训练权重。辅助解码器网络输出训练数据的类标签。这样,合成图像质量就会大大提高。AC-GAN模型学习与类标签无关的噪声(z)表示,因此在生成器的推理时不需要。
此外,具体的重建目标虽然很简单,但似乎可以稳定训练。训练 100 个 AC-GAN 的集成(多个模型),其中每个模型在 10 个不同的类上进行训练,集成 AC-GAN 生成 1000 个逼真的图像类(来自 Imagenet 1K 数据集)
了解一种非常重要的常见评估技术是我们在上一部分 1 中看到的初始分数。为了自完成性,让我们简要回顾一下:您使用预先训练的模型来测量类条件生成的图像的正确分类。初始分数衡量可判别性。令人惊讶的是,作者发现合成更高分辨率的图像会增加可辨别性(高达128x128的空间分辨率)。但是样本多样性呢?
2.2 结构相似性
在计算机视觉和图像处理中,我们通常使用此指标来评估噪声和失真。SSIM是一种基于感知的模型,通过图像统计(即平均值和标准差)来考虑结构信息。SSIM结合了重要的视觉感知现象。
为了评估生成图像的多样性,采用了多尺度结构相似性(MS-SSIM)。尽管该指标最初是为图像压缩而引入的,但实验表明,它也是评估生成的图像质量的足够指标。
从字面上看,较高的多样性导致较低的平均MS-SSIM分数。理想情况下,我们希望同类生成的图像具有低相似性 - >高多样性!为了增加直观理解,我们只将MS-SSIM称为相似性。
重要的是要了解结构信息与图像统计密切相关。我们知道像素具有很强的相互依赖性,尤其是当它们在空间上接近时(这就是为什么我们设计了图像卷积并且无论如何都😊工作得非常好)。
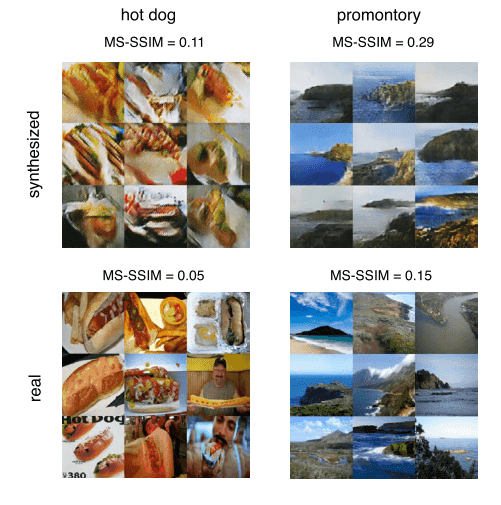
取自 AC-GAN
如图所示,合成数据没有训练样本的多样性,因为它们具有更高的分数。尽管如此,他们肯定朝着正确的方向前进。总而言之,尽管这个指标相对容易计算,但它是生成输出的感知多样性的重要度量,以确保模型没有记住训练数据。但是,正如我们将看到的,还有很多其他方法可以验证这一点。
2.3 讨论要点
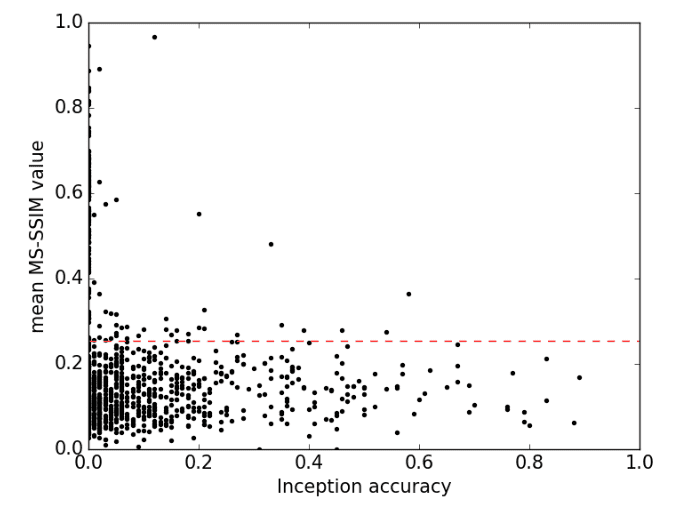
- 仅仅引入指标是不够的,还要通过指标了解数据之间的关系。下面,我们可以看到一个超级直观的相似性图(MS-SSIM)和准确性。红线是真实数据的平均多样性。大多数高相似性类不会提高准确性,而大多数低相似性(高类内多样性)产生 1% 到 20% 之间的准确性。这个分数可能听起来很低,但请记住,即使是真实数据在 ImageNet 中的初始分数也有 ~77%。这一发现与一般印象相矛盾,即GAN以牺牲该时期的可变性为代价来实现高样本质量。不过,对于高达 128x128 的图像!由此可见AC-GAN的强大学习能力。
- 条件和噪声(或更好地行走潜在空间):当生成模型过度拟合真实分布时,人们能够在采样图像中观察到尖锐和离散的过渡。此外,潜在空间中通常存在与有意义的内容不对应的区域。在下图中,如果从左到右看,您可以看到样本噪声相同但具有 8 个鸟类类别的不同类别条件的样本。重要的是要了解与图像结构相关的非相关结构得到维护。相反,查看列的内容可以观察到具有不同噪声矢量的相同类样本。在不同的噪声样本中,与类相关的特性是一致的。

-
目前尚不清楚划分生成模型的数据集以仅学习类子集的最佳方法是什么。但是,将类的数量从 1000 限制为 10 可以提高质量,即使单个类生成模型可能确实不稳定。在前面的教程中,我们通过在一个 CIFAR10 类中训练 DCGAN 来证明这一点,其中我们观察到模式崩溃。
-
最后,由于生成器不需要类信息来提供样本,因此AC-GAN可以在半监督设置中非常简单地使用。
三、3D-GAN(通过3D生成对抗建模学习对象形状的概率潜在空间2017)
是否有可能利用体积(3D)卷积网络以及生成对抗网络的现有进展?这部精彩的作品说,它不仅是可能的,而且也是非常有效的。
3.1 了解 3D 对象生成问题
3D 对象生成是一个比图像生成更具挑战性的问题。与2D图像的空间相比,对3D形状的空间进行建模更加困难。为了量化这一点,假设 64x64 等于 4096 像素,而 64x64x64 等于262144体素。这就是我们所说的高维性在实际意义上的意思。
为了限制越来越多的参数,作者选择仅使用卷积块。令人惊讶的是,没有池化层。所提出的模型基本上是DCGAN的扩展,具有体积卷积,如下图所示:
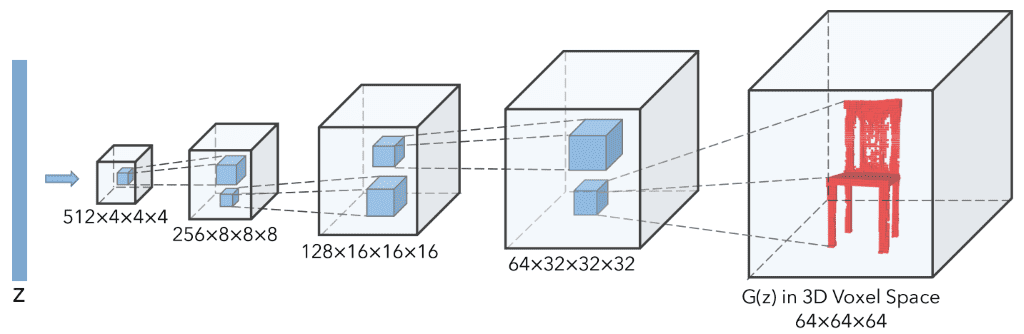
3D-GAN发生器取自这里。
如图所示,每个卷积层的内核大小为4x4x4,步幅为2。此 conv3d 图层将 3D 维度加倍,同时将要素数量减少 2 倍。与DCGAN一样,鉴别器使用对称架构,激活Leaky Relu而不是ReLU。我们Pytorch 重新实现 3D-GAN 可在此处获得
3.2 培训策略
这项工作的基本新颖部分来自培训策略。由于在 3D 体素空间中生成对象比对其进行分类更困难,因此 G 和 D 之间存在训练不平衡。可以想象,在这种情况下,D 的学习速度可能比 G 快。为了缓解这个问题,使用了三个小技巧。首先,在D中使用比G更低的学习率。其次,100的批量大小相对较大,这对于3D网络来说是巨大的!最后,只有当鉴别器在最后一批中的准确率不高于 80% 时,鉴别器才会更新。这些技巧可能很简单且由任务定义,但可以生成稳定的高质量 3D 对象。
3.3 更进一步
本系列文章中前面描述的所有方法都使用带条件或不带条件的随机噪声 (z)。但是,让我们想想如果我们能将随机噪声z设计成更有意义的东西,会发生什么。对于 3D 对象生成,从观察中推断潜在向量 z 会非常酷。让我们考虑一下!
如果我们以可训练的方式投影 2D 图像以生成 z 会怎样?这种额外的映射将导致将 2D 图像转换为体素化的 3D 对象。继VAE-GANs的成功理念之后,他们增加了一个额外的2D图像编码器,该编码器输出所需的潜在表示向量z。总而言之,总损失包括对抗性损失(二进制交叉熵)和与变分自编码器相关的另外两个损失项。VAE损失是指a)潜在表示的变分分布与先验分布之间的KL散度,以及b)从图像生成的三维对象与真实对象之间的均方误差重建损失。然而,为了训练3D-VAE-GAN,需要成对的3D图像和2D模型!
3.4 任务、结果和讨论
基于上述所有内容,所提出的模型可用于3个任务,对应于3个不同的组件:
-
使用 G 生成 3D 对象
-
使用 D 进行 3D 对象分类
-
单幅图像3D重建!
我们只会展示后者的结果,因为它是最有吸引力的任务和视觉吸引力。有关更多演示,还有一个有趣的视频。对于我们心爱的铁杆软件工程师,官方存储库也可以在这里获得,尽管我不推荐它。

基于3D-VAE-GANs的原创作品
理解 GAN 的结果真的很美,这篇文章真正关注的是。我们已经讨论了在潜在空间中“行走”以及观察生成的样本之间有意义的解决方案模式。顺便说一下,官方术语是插入对象向量之间的潜在空间。
我个人在GANs领域喜欢的一个更伟大的例子是潜在空间算术。从本质上讲,这包括简单的对象向量算术运算可以对 3D 体素空间产生有意义的影响的想法。事实证明,您可以添加或减去与吸引人的 3D 对象相对应的不同 z 向量,从而生成抽象地共享高维空间中低维空间算术运算的新 z 向量。在InfoGAN的解开表示中说明了类似的方法。在这里,它进一步推广到潜在空间中的算术运算,导致 3D 空间中的高度语义内容。

Based on the original work of 3D-VAE-GANs-2
四、PacGAN (The power of two samples in generative adversarial networks 2016)
这项工作解决了模式崩溃的问题。其他几种方法依赖于修改后的架构、损失函数和优化来解决这个问题。但是,目前尚不清楚提议的更改与模式崩溃的关系。这项工作引入了一些基础数学,基于二元假设检验,可以有效地解释和解决模式崩溃。我想说的是,这项工作采用了论文《训练 GAN 的改进技术》(2016 年)中的小批量歧视的想法,我们将进一步分析20 个步骤。
4.1 核心理念
作者不使用鉴别器 D(x) 将单个输入映射到单个标签,而是使用修改后的鉴别器 D(x1,x2, . . . ,xn),将 n 个样本映射在一起,独立于其源域(真实或虚假,但不是它们的混合)。这些样本独立于相同的分布(真实分布或生成)绘制。请务必了解此方法与批量大小训练无关。
抽取的样品相当串联,并被分配一个标签,即所谓的包装。串联在基于卷积的鉴别器的通道维度中执行。为了解决这个问题,唯一的修改是通过增加卷积内核的大小在 D 的输入处执行的。
4.2 直觉和一些结果
更直观的是,打包通过向鉴别器提供一组图像而不是单个图像来帮助鉴别器。据信,通过这种方式D能够检测到模式坍缩,因为缺乏多样性更为明显。从数学上讲,这种方法允许鉴别器根据分布的乘积进行二元假设检验。

图像取自原始论文。
如图所示,包装显著提高了样品的多样性。如图所示,从DCGAN和PacDCGAN2生成的图像更加多样化和清晰,参数数量大致相同。最后,可以在此处找到正式发布的代码。
五、像素2像素GAN(使用条件对抗网络的图像到图像转换 2016)
在这篇手稿中,作者从噪声到图像(有或没有条件)到图像到图像,现在作为配对图像翻译任务处理。简单地说,条件是一个图像,输出是另一个图像。以前提供随机性和可变性所需的噪声采样被删除,因此模型学习几乎确定性的映射。这几乎源于他们在测试时保留了 dropout 和批量归一化层的训练行为。但是,此方法不提供很大的可变性。此外,鉴别器现在可以访问图像对(条件输入图像+真实或生成)。
5.1 Unet 形状生成器
重要的是要了解他们为什么使用这个生成器。实际上,生成器的设计是基于这样的假设,即两个输入输出图像都是相同底层结构(即边缘)的渲染。这意味着存在共享的低级信息,因此在 unet 样式架构中,编码器和生成器的解码器之间实现了对称跳过连接。
此外,它们在生成的图像和基本事实之间提供了额外的L1损失(绝对差异的总和)。通过这种方式,他们认为图像质量会更高,因为L1损失比L2损失导致更少的模糊。尽管我们讨论过这个没有对抗性术语的错误是无效的,但在这项工作中,它们一起使用。让我们看看他们为什么带回这个想法!!
5.2 带补丁鉴别器
直观地,L1和L2损耗能够准确捕获低频(即边沿)。因此,通过这种方式,GAN鉴别器仅限于主要建模高频细节和结构。如前所述,高频建模与局部信息有关,这些信息可以在我们称为补丁的小图像子区域中找到。为此,他们选择了一个卷积鉴别器,该鉴别器接收多个生成的图像补丁并平均预测以提供 D 的标量输出。这就是为什么它被称为PatchGAN!现在,让我们看看一些结果!

图片取自原始论文。在上图中可以直观地观察到所讨论的细节。增加L1损耗可提高图像质量,捕获低电平频率。
六、Cycle-GAN(使用周期一致性对抗网络的未配对图像到图像转换 2017)
前面描述的所有条件图像生成架构都需要训练对。这项工作引入了不成对条件图像生成的第一个突破。与以前的方法相反,该模型学习从一组(集合)图像到另一组图像的映射。当然,这可以通过假设集合包含可以学习的重复模式和特征来解决。问题是,在没有配对示例的情况下,是否有可能学习如此酷的映射(将图像转换为图像)。尽管存在两个集合之间必须存在某种相关性的假设,但这仍然是一项具有挑战性的任务!从现在开始,我们分别调用图像的输入和输出集集合,域 X 和 Y。以这种方式表述问题,我们的新任务是域映射!
6.1 域映射的坏消息
一般来说,这种方法有一个固有的问题。我们想要学习的映射(G)并不能保证个人层面的一致性。具体来说,我们没有任何约束,即域 X 的单个输入图像和域 Y 的生成图像有意义地配对。前面描述的观察结果源于这样一个事实,即存在无限映射 G 将提供相同的输出,这与以前方法的单个映射不同。直觉上,我们正在看一个更加抽象和复杂的世界(潜在空间)。正如预期的那样,这个伟大作品引入了这个世界的第一个实验,通过遇到不稳定和模式崩溃来验证复杂性!
6.2 域映射的好消息:引入循环一致性
泛化到域映射带来了新的挑战。为此,作者利用了学习翻译应该是“循环一致”的属性。让我们更深入地了解这个想法。
除了学习单一映射G:X -->Y,我们还可以学习称为F的逆域映射,这样F:Y -->X。 单独学习此映射对我们有何帮助?它约束G吗?答案是否定的!至少不是一个人。
但是,还有更好的一面。我们可以利用这些来映射和制作域“周期”。让我们首先获取条件图像 x(在 X 域中),并使用 G 将其转换回所需的 Y 域。现在最大的问题来了:如果我们把这个应该存在于域Y中的生成的图像y再次应用映射F会怎样。现在的输出是什么?和这个帮助数字一起考虑一下。
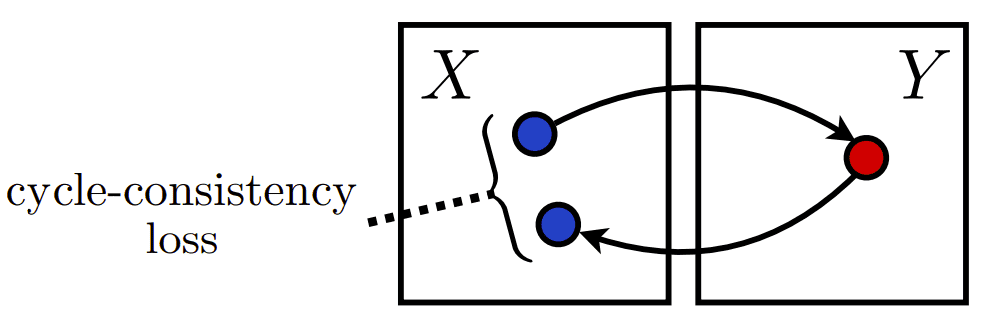
在域X中循环,借用原始工作以直观理解。
所以,如果我们生活在一个理想的世界里,我可以向你保证,我们会得到输入的条件图像。这是这篇精彩论文的核心思想!在数学上,F(G(x)) = x 和 G(F(y)) = y。令人惊讶的是,这与您在基本微积分中学到的 1x-1 函数的想法相同!
由于我们没有理想的映射,因为我们不在理想的世界中,让我们最小化这些数量之间的距离。也就是说,让我们最小化 F(G(x)) 和 x 以及 G(F(y)) = y 的 L1 距离。当然,有很多方法可以最小化单个域集之间的距离。产生最佳结果的最直接的度量是第一个范数:绝对差异的总和定义为:
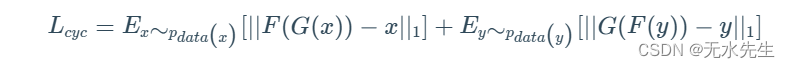
使用期望值是因为 GAN 的随机性,这通常来自随机噪声(但在这项工作中不是!因此,让我们教两个 GAN(4 个深度网络)来学习这些映射,将它们的对抗性损失与图示的周期一致性约束相结合。将 2 个对抗损失与建议的周期损失相加,加上另一个标量超参数,就可以获得完整的训练目标。在某些特定于应用程序的情况下,我们需要保留域之间的颜色组合,因此将身份损失项添加到等式中。Cycle-GAN和Pix2Pix的实现可以在这里这个维护良好的GitHub存储库中找到。
七、结果和讨论
如您所见,结果当然令人印象深刻。在第一个图中,说明了两种映射都是学习的。图像中有一些模糊,但您必须考虑问题的复杂性。
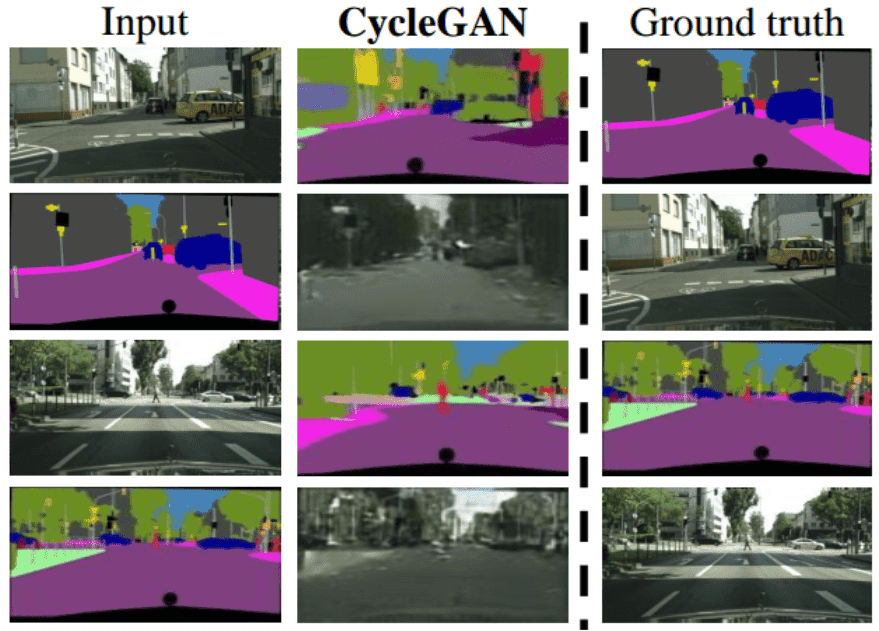
图片取自原文
即使与配对方法(这显然是不公平的比较)相比,例如pix2pix,我们也可以看到结果更差,但仍然具有竞争力。

图片取自原文
以我的拙见,看到这样的顶级作品清楚地暴露了自己方法的局限性,是令人兴奋的。这是我钦佩的高质量深度学习研究中的难得资产!总的来说,结果给该领域带来了很大的希望。但是,对于需要大量几何变化的任务,这种方法已被证明成功有限。一个原因可能是此方法捕获了域的更多全局特征。这可以解释为学习全局特征是域映射的第一步。此外,没有明确的配对指导来实现本地信息提取。简单地说,模型在这方面不受约束。
其他目视观察到的失败情况是由训练数据集中可能存在的分布特性引起的。这种预期的观察结果与所描述的域之间重复模式和特征的假设有关。尽管如此,配对的图像到图像转换仍然是未配对方法的上限。最后,可以使用此方法使用大量可用的未配对图像。
7.1 循环GAN训练方案伪Python代码,直观理解
我们决定,由于我们有 2 个 GAN,因此可能会混淆这种模型的训练如何工作。这就是为什么我们为您带来了一个实际的python代码,有助于理解训练过程。重要的是要澄清代码是从原始存储库借来的,尽管为了最大限度地理解概念而进行了大量更改。有注释,以便您可以阅读代码。某些功能没有填充以保持大小限制,同时专注于新的重要方面。因此,您将看到某些部分是抽象定义的。
import torch
import itertools
class CycleGAN():
def init(lr_g, lr_d, beta1, fake_pool_X, fake_pool_Y, criterionGAN, criterionCycle):
"""
Define any G image-to-image model and any D image-to-scalar in [0,1]
"""
self.netG_X = generator()
self.netG_Y = generator()
self.netD_X = discriminator()
self.netD_Y = discriminator()
# Unify generator optimizers
self.optimizer_G = torch.optim.Adam(itertools.chain(self.netG_X.parameters(),
self.netG_Y.parameters()), lr=lr_g, betas=(beta1, 0.999))
# Unify discriminator optimizers
self.optimizer_D = torch.optim.Adam(itertools.chain(self.netD_A.parameters(),
self.netD_B.parameters()), lr=lr_d, betas=(beta1, 0.999))
self.hyperparameters = (lambda_X,lambda_Y)
# Abstractly defined Image-pooling and criteria
# for code-compactness and understanding
self.fake_pool_X = fake_pool_X
self.fake_pool_Y = fake_pool_Y
self.criterionGAN = criterionGAN
self.criterionCycle = criterionCycle
def training_cyclye_gan_scheme(real_X_data, real_Y_data):
"""
real_X_data is a bunch(mini-set) of images from domain X.
real_Y_data is a bunch(mini-set) of images from domain Y
shape is [batch, (mini-set), channels=3, height, width]
"""
# we make input data available as class member to be in the scope of all classes
self.real_X_data = real_X_data
self.real_Y_data = real_Y_data
# 1st cycle starting from Domain X
# G_X(x) --> in Y domain
self.fake_Y = self.netG_X(real_X_data)
# G_Y(G_X(x)) --> in X domain, ideally G_Y(G_X(x))=x
self.reconstructed_X = self.netG_B(fake_Y)
# 2nd cycle starting from Domain Y
# G_Y(y) --> in X domain
self.fake_X = self.netG_Y(real_Y_data)
# G_X(G_Y(y)) --> in Y domain, ideally G_X(G_Y(y))=y
self.reconstructed_Y = self.netG_X(fake_X)
# Train netG_X and netG_B
# To do that, we need to disable gradients for discriminators
# because discriminators require no gradients when optimizing Generators
self.set_requires_grad([self.netD_X, self.netD_Y], requires_grad=False)
self.optimizer_G.zero_grad()
# calculate losses and gradients for G_A and G_B and update
self.backward_G()
self.optimizer_G.step()
# Train netD_A and netD_B
self.set_requires_grad([self.netD_A, self.netD_B], requires_grad=True)
self.optimizer_D.zero_grad()
self.backward_D()
self.optimizer_D.step()
def set_requires_grad(self, nets, requires_grad=False):
"""
Set requies_grad=Fasle for all the networks to avoid unnecessary computations
Parameters:
nets (network list) -- a list of networks
requires_grad (bool) -- whether the networks require gradients or not
"""
for net in nets:
for param in net.parameters():
param.requires_grad = requires_grad
def backward_G(self):
"""
Calculate the loss for generators G_A and G_B
Identity loss is skipped for educational purposes!
"""
lambda_X, lambda_Y = self.hyperparameters
# GAN loss D_X(G_X(x))
loss_G_X = self.criterionGAN(self.netD_X(self.fake_Y_data))
# GAN loss D_Y(G_Y(y))
loss_G_Y = self.criterionGAN(self.netD_Y(self.fake_X_data))
# Forward cycle loss || G_Y(G_X(x)) - x||
loss_cycle_X = self.criterionCycle(self.reconstructed_X, self.real_X_data) * lambda_X
# Backward cycle loss || G_X(G_Y(y)) - y||
loss_cycle_Y = self.criterionCycle(self.reconstructed_Y, self.real_Y_data) * lambda_Y
# combined loss and calculate gradients
loss_G = loss_G_X + loss_G_Y + loss_cycle_X + loss_cycle_Y
loss_G.backward()
def backward_D(self):
"""Calculate adverserial loss for the discriminator"""
pred_real = netD_X(self.real_X_data)
loss_D_real = self.criterionGAN(pred_real, target=True)
# Fake
pred_fake = netD_X(self.fake_X_data.detach())
loss_D_fake = self.criterionGAN(pred_fake, target=False)
# Combined adverserial losses and calculate gradients
loss_D_X = (loss_D_real + loss_D_fake) * 0.5
loss_D_X.backward()
# the same for the other model
pred_real = netD_Y(self.real_Y_data)
loss_D_real = self.criterionGAN(pred_real, target=True)
pred_fake = netD_Y(self.fake_Y_data.detach())
loss_D_fake = self.criterionGAN(pred_fake, target=False)
# Combined adverserial loss and calculate gradients
loss_D_Y = (loss_D_real + loss_D_fake) * 0.5
loss_D_Y.backward()
return loss_D八、结论
在本文中,我们采用了我们之前分析的早期开发的 GAN,并了解它们如何演变为出色的计算机视觉解决方案。我们首先在大规模数据集上组合条件类信息。之后,我们转向3D空间和对象生成,甚至可以使用VAE-GAN3D从单个RGB图像开始!
然后,我们通过调整 D 解决了模式崩溃等常见问题。更有趣的是,我们看到了如何通过精心设计G和D来分别对全局和局部结构进行建模来生成高质量的配对图像映射。最后,在没有训练图像对的情况下,我们将单个图像到图像的转换推广到通过循环GANs进行域映射。在一个教程中可以介绍很多漂亮的概念。我知道!而且,我们甚至没有完成。
引用:
- Odena,A.,Olah,C.和Shlens,J.(2017年34月)。使用辅助分类器 gan 的条件图像合成。第 70 届机器学习国际会议论文集-第 2642 卷(第 2651-<> 页)。JMLR。组织。
- Wu, J., Zhang, C., Xue, T., Freeman, B., & Tenenbaum, J. (2016).通过 3D 生成对抗建模学习对象形状的概率潜在空间。神经信息处理系统进展(第82-90页)。
- Lin, Z., Khetan, A., Fanti, G., & Oh, S. (2018).Pacgan:生成对抗网络中两个样本的力量。神经信息处理系统进展(第1498-1507页)。
- Isola, P., Zhu, J. Y., Zhou, T., & Efros, A. A. (2017).使用条件对抗网络进行图像到图像转换。在IEEE计算机视觉和模式识别会议记录(第1125-1134页)。
- Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017).使用周期一致的对抗网络进行非配对的图像到图像转换。IEEE计算机视觉国际会议论文集(第2223-2232页)。
GANs in computer vision - Conditional image synthesis and 3D object generation | AI Summer (theaisummer.com)