目录
前言:
1.概述
2.下载安装、集群搭建
3.消息模型
4.如何保证吞吐量
4.1.消息存储
4.1.1顺序读写
4.1.2.异步刷盘
4.1.3.零拷贝
4.2.网络传输
前言:
RocketMQ的代码示例在安装目录下有全套详细demo,所以本文不侧重于讲API这种死的东西,而是侧重于讲解RocketMQ的特性。消息中间件无非需要关注三点:吞吐量、消息可靠性、消息模型。任何消息中间件的异同点就体现在这三个方面。本文也会从这三个方面来讲解RocketMQ。
本文是作者RocketMQ系列文章的最后一篇,一些基础的概念、下载安装、集群、基本消息模型等,前面都已经有单独的文章讲过,每篇都很深入浅出,单篇阅读花不了两三分钟,所以这些内容会直接贴上链接。
1.概述
RocketMQ 是一款开源的分布式消息中间件,最初由阿里巴巴集团开发并开源。它旨在为分布式系统提供可靠、高性能、可扩展的消息通信能力。RocketMQ和RabbitMQ、KAFKA一起并列为现在主流的三大消息中间件。
RocketMQ的基本概念+架构:
RocketMQ基础概念__BugMan的博客-CSDN博客
2.下载安装、集群搭建
RocketMQ的下载安装教程+集群搭建教程:
RocketMQ下载安装、集群搭建保姆级教程_安装rocketmq集群__BugMan的博客-CSDN博客
3.消息模型
RocketMQ的消息模型有以下几种:
- 顺序消息,消费者按照生产者的发送顺序进行消费。
- 广播消息,一条消息被多个消费者消费。
- 延迟消息,驻留时间,消费者才能消费到消息。
- 批量消息,支持生产者批量发送消息。
- 过滤消息,通过tag,消费者可以消费同一个topic下自己感兴趣的消息。
- 事务消息,生产者的消息生产支持事务回退。
RocketMQ消息模型详解:
详解RocketMQ使用__BugMan的博客-CSDN博客
4.如何保证吞吐量
4.1.消息存储
RocketMQ最大的特点概括起来其实就一句话:
既保证了消息的可靠性,又保证了吞吐量。
可靠性和吞吐量其实是互斥的两点,为了保证可靠性,消息就一定要落在磁盘存储防止断电丢失。落在磁盘存储后,读这条消息的时候的磁盘IO就会拉低吞吐量。所以RocketMQ的核心其实就是数据落磁盘,然后想尽一切办法来提高吞吐量。
RocketMQ的生产消费过程:
-
收到生产者发送的消息,将其存起来
-
向消费者推送一条消息后,等待消费者的ACK,收到ACK后将消息标记为已消费。
-
定期删除一些已经过期的消息。
RocketMQ用来提高吞吐量的手段:
-
顺序写
-
异步刷盘
-
零拷贝
4.1.1顺序读写
磁盘的顺序读写性能要远好于随机读写。因为每次从磁盘读数据时需要先寻址,找到数据在磁盘上的物理位置。对于机械硬盘来说,就是移动磁头,会消耗时间。 顺序读写相比于随机读写省去了大部分的寻址时间,它只需要寻址一次就可以连续读写下去,所以性能比随机读写好很多。
RocketMQ 利用了这个特性。它所有的消息数据都存放在一个无限增长的文件队列 CommitLog 中,CommitLog 是由一组 1G 内存映射文件队列组成的。 写入时就从一个固定位置一直写下去,一个文件写满了就开启一个新文件顺序读写下去。
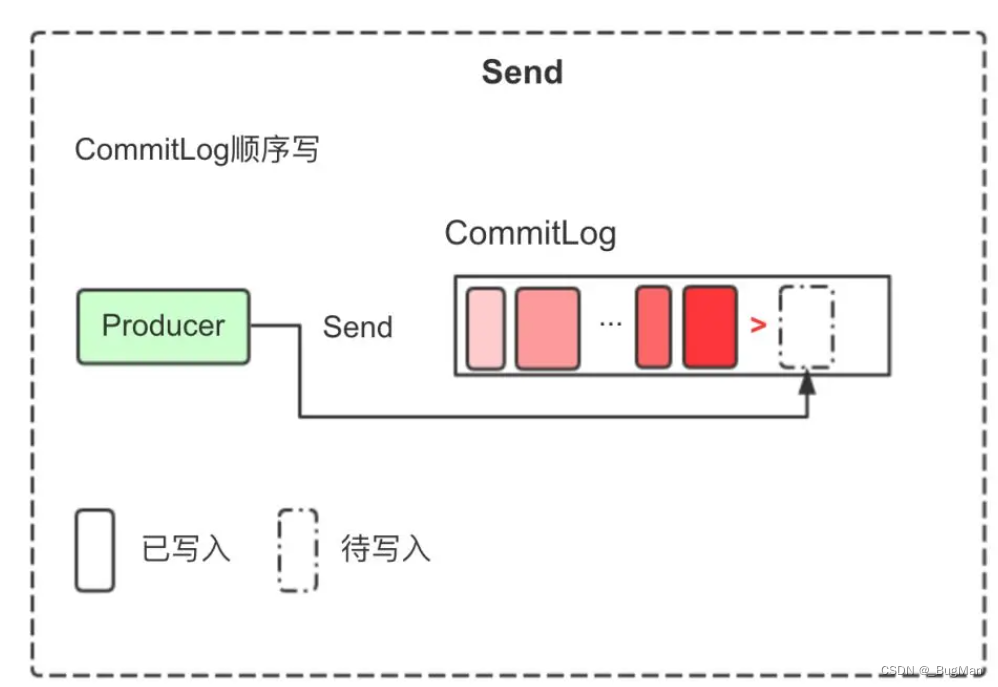
RocketMQ顺序写盘的过程如下:
-
生产者发送消息到 RocketMQ Broker。Broker 接收到消息后,将消息按照顺序写入内存中的 Page Cache(页面缓存)中。
-
消息在内存的 Page Cache 中形成连续的数据块。由于 RocketMQ 的顺序写盘策略,相同 Topic 和 Queue ID 的消息会按照发送的先后顺序排列成一批,形成连续的数据块,而不是随机地散落在磁盘上。
-
然后,后台线程会定期将 Page Cache 中的连续数据块顺序写入磁盘上的存储文件中,称为 "CommitLog"。由于数据是连续写入,因此磁盘的写入操作变得高效,减少了寻道时间和磁盘的碎片化,提高了写入性能。
需要注意的是,顺序写盘并不是说所有消息都按照先后顺序写入,而是相同 Topic 和 Queue ID 的消息会按照发送的先后顺序形成连续的数据块写入磁盘。对于不同 Topic 和 Queue ID 的消息,它们可能在磁盘上是交错存储的。
4.1.2.异步刷盘
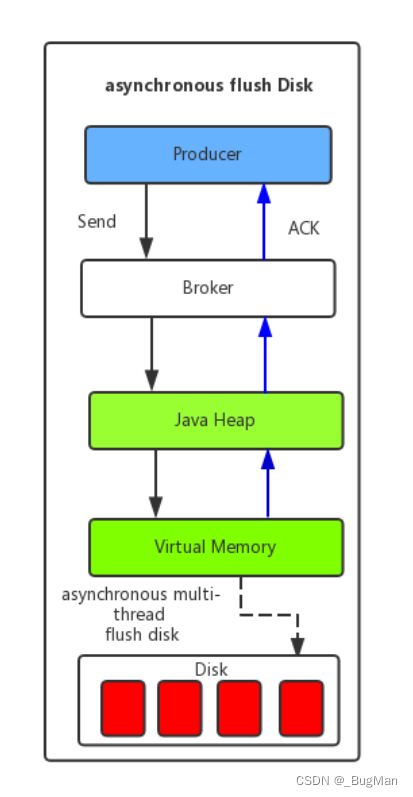
RocketMQ 的异步刷盘(Async Flush)是一种优化手段,用于提高消息的写入性能和吞吐量。在消息存储上,RocketMQ 遵循了写入先落盘再返回的策略,即在消息写入磁盘之前,会先将消息写入操作系统的 Page Cache(页面缓存)中,并立即返回写入成功的响应给生产者,然后由后台线程异步地将 Page Cache 中的数据刷写到磁盘中。
4.1.3.零拷贝
零拷贝(Zero-Copy)是一种优化技术,旨在提高数据传输的效率和性能,特别是在文件传输和网络数据传输中。传统的数据传输方式涉及多次数据拷贝,而零拷贝通过避免不必要的数据拷贝操作,减少了数据传输的开销,从而提高系统的性能。
在传统的数据传输中,例如从磁盘读取文件并通过网络发送,通常涉及以下步骤:
- 将数据从磁盘读取到内核空间(Kernel Buffer)。
- 将数据从内核空间拷贝到用户空间(User Buffer)。
- 将数据从用户空间拷贝到网络缓冲区(Network Buffer)。
- 最终数据通过网络发送。
这种传统的数据传输方式涉及多次数据拷贝,每次拷贝都需要 CPU 参与,并且需要在内核空间和用户空间之间进行数据复制,导致了额外的开销和延迟。
零拷贝技术的主要思想是避免不必要的数据拷贝,通过直接在内核空间和用户空间之间传输数据,从而减少 CPU 和内存的使用。
关于0拷贝更详细的内容异步博主的另一篇文章:
全网最清晰的零拷贝详解,看一遍就会__BugMan的博客-CSDN博客
4.2.网络传输
关于序列化,以及为什么要用序列化,不是很清楚的同学可以移步博主的另一篇文章:
详解JAVA序列化__BugMan的博客-CSDN博客
RocketMQ的报文使用了序列化,序列化和反序列化由生产者端和消费者端的SDK来实现。
RocketMQ目前支持的序列化方式有:
-
RocketMQ 自定义序列化:RocketMQ 使用自定义的序列化协议进行消息的编码和解码。这个序列化协议被称为 Remoting Command Protocol。该协议采用了二进制格式,对消息进行高效的编解码处理,以实现高性能和低延迟。
-
JSON 序列化:RocketMQ 支持将消息转换为 JSON 格式进行传输。JSON 序列化方式适合处理复杂结构的消息,易于阅读和调试,但相比二进制格式会增加一定的传输开销。
-
Java 原生序列化:RocketMQ 还支持使用 Java 原生的序列化方式(Java Serialization)。Java 原生序列化是 Java 标准库提供的一种序列化方式,但在性能方面可能不如其他序列化框架。
-
Hessian 序列化:Hessian 是一种二进制序列化框架,支持多种编程语言。RocketMQ 支持使用 Hessian 将消息序列化为二进制数据进行传输。




![[CrackMe]damn.exe的逆向及注册机编写](https://img-blog.csdnimg.cn/31d5480024d741e5a9e0839ad87fab2e.png)






![[NLP]LLM高效微调(PEFT)--LoRA](https://img-blog.csdnimg.cn/ca73a8eb85aa43b782100ca6210f34e9.png)