本期我们来学习C++模板的进价内容,没有看过初阶的同学建议先看看初阶内容
(26条消息) C++模板初阶_KLZUQ的博客-CSDN博客
目录
非类型模板参数
模板特化
函数模板特化
类模板特化
模板分离编译
模板总结
我们之前一直说我们写模板时,typename和class没什么区别,所以下面我们就来看一个有区别的例子
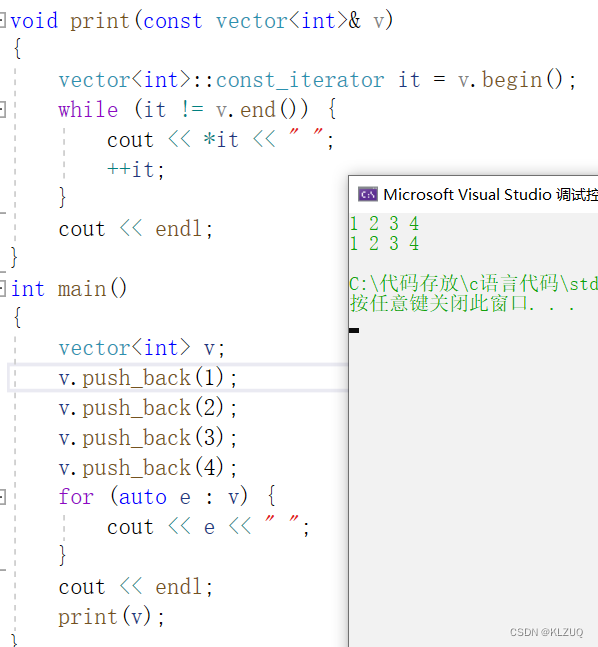
我们这里有一段输出的代码,如果我们想要一个可以针对各种容器使用的print该怎么办呢?
所以我们想到了模板
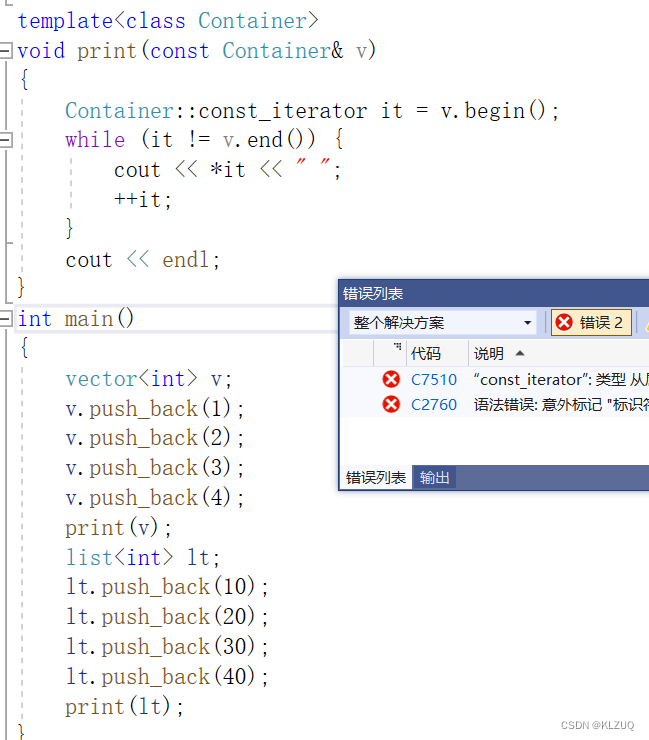
但是我们写出来后发现编译不通过
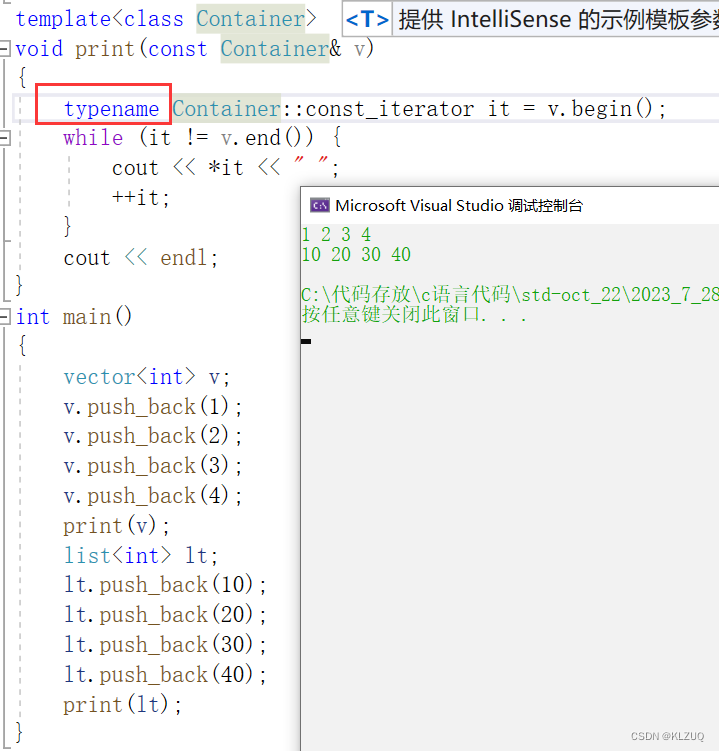
我们要在这里加一个typename,不能用class
编译器从上往下走,container没有实例化,编译器是不知道他是什么类型的,我们之前是明确告诉它是vector<int>类型,vector<int>已经被实例化,去vector<int>实例化出来的类里就能找到const_iterator,而container这里是不知道的,那此时就有两种可能,一种就是这里是静态成员变量,或者对象,因为静态成员可以直接由类域去访问,所以const_iterator可能是类里面的静态成员,也有可能是container里typedef的,或者是内部类,也就是说,Container::const_iterator到底是类型还是对象,这里分不清,所以要求在这里加一个typename,告诉这里就是一个类型

如果大家注意的话,这里也是一样的情况
只要取类模板里面的内嵌类型,类模板没有实例化,就不能区分,就要加typename
非类型模板参数

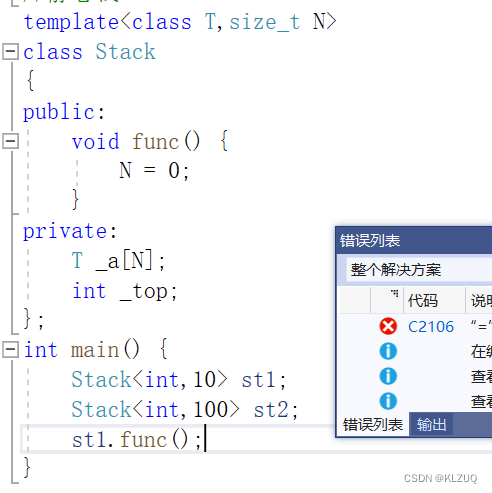
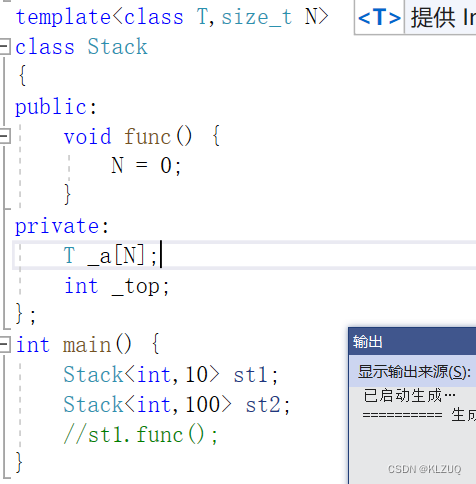
比如这里,假设我们定义了静态栈,st1我们要存10个数据,但是st2我们要存100个数据,该怎么办?

所以我们就引入了非类型模板参数,这样就可以解决问题
这里的N一定是常量
是不能修改的
还有一个点,这里如果不调用就不会报错,不同编译器下可能不一样,有的编译器可能会报错
这里是按需实例化 ,意思是这个函数如果没有调用,就不生成它的指令,也就不会去检查他的语法,也就是调用了才会去实例化
我们回过头来继续看,非类型模板参数的限制非常多
首先,必须是常量,然后必须是整形
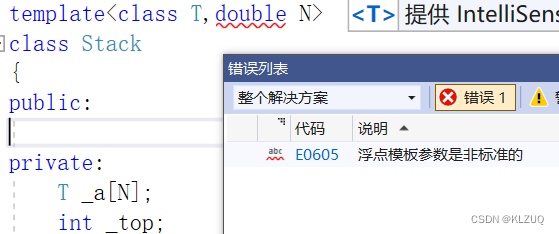
(另外,char是整形家族的,这点要牢记)
 array是一个定长数组,这里就使用了非类型模板参数
array是一个定长数组,这里就使用了非类型模板参数
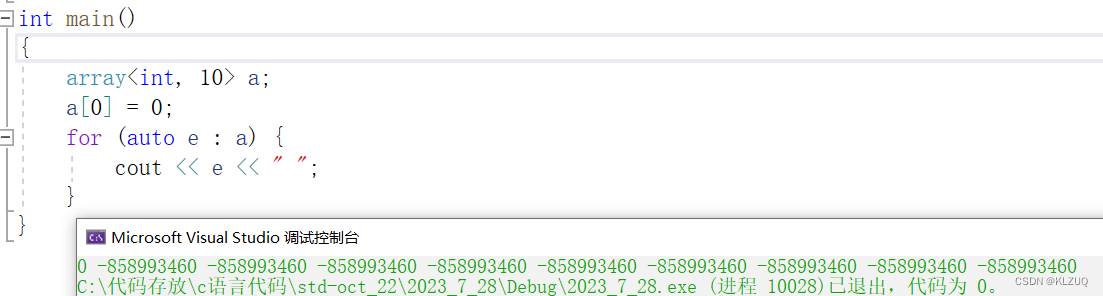
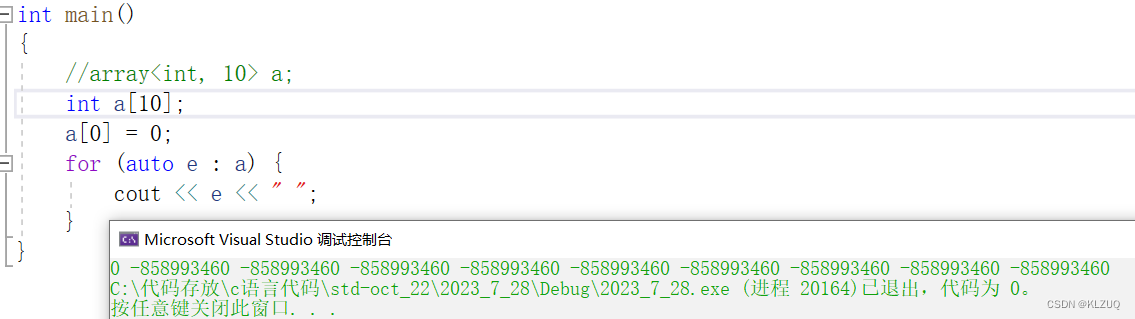
它和C语言的数组没啥区别 ,一样不能初始化,这东西还是C++11更新出来的(所以一直有人骂C++委员会,他们一直在摸鱼)
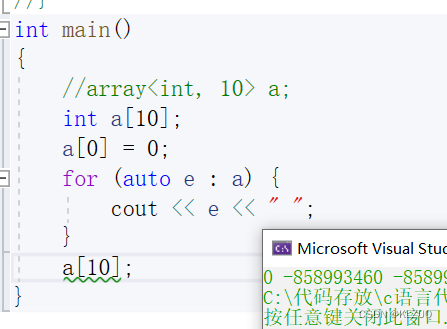
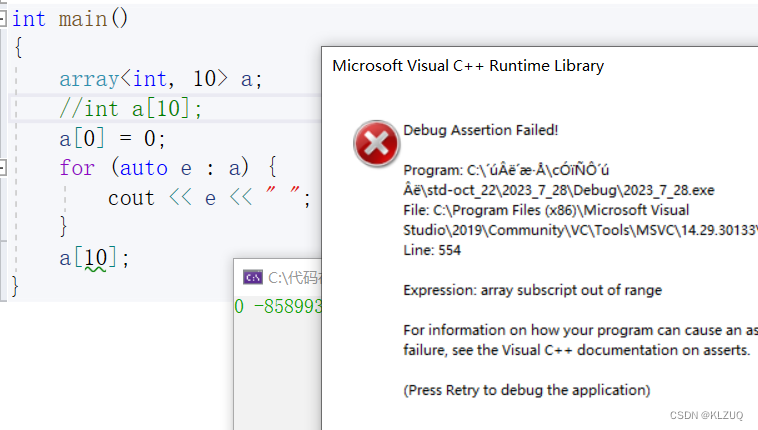
如果要说array的作用,大概只有检查越界了
array对于越界的检查非常严格,它是一个operator[ ] 的调用,越界读写都能检查
而普通数组不能检查越界读,少部分越界写可以检查
不过还是没什么用
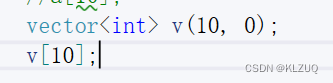
我们直接用vector更好,一样可以检查越界,而且还能初始化
模板特化
函数模板特化
通常情况下,使用模板可以实现一些与类型无关的代码,但对于一些特殊类型的可能会得到一些错误的结 果,需要特殊处理,比如:实现了一个专门用来进行小于比较的函数模板

我们先写一个比较大小的代码

我们再传ab的地址过去,但是我们不想按地址比较,而是按数据大小比较该怎么办?
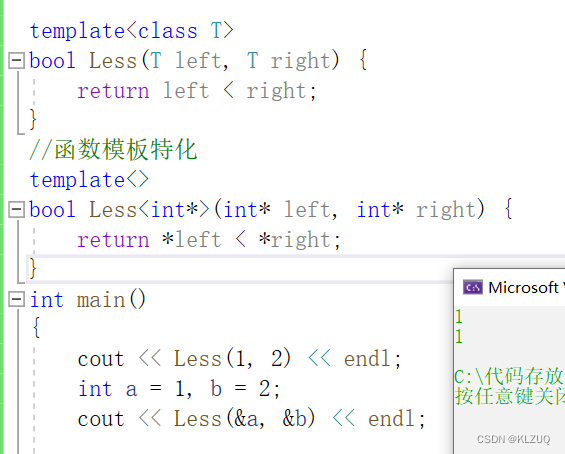
我们就可以使用函数模板的特化,如果是普通类型,我们就走类模板实例化,如果是int*类型就走特化

不过具体类型的话直接写成函数构成重载更好一点
但如果我们不仅仅想解决int*问题,我们是想解决所有指针问题呢?

我们可以这样解决
函数模板的特化我们一般使用重载就可以解决,这个我们了解即可
类模板特化
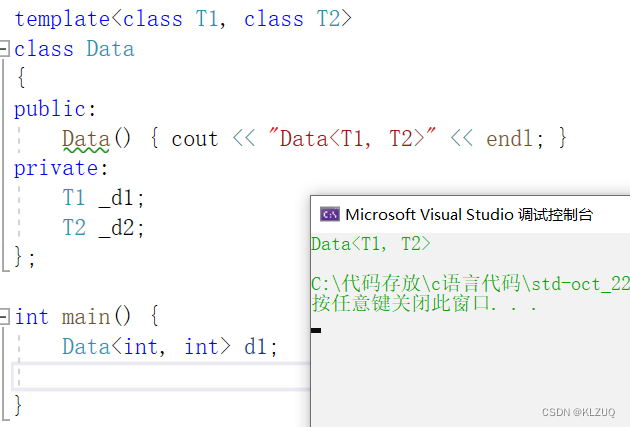
假设我们有一个data类,我们要对<int,double>类型进行特殊处理该怎么?
这时候我们就可以写一个特化
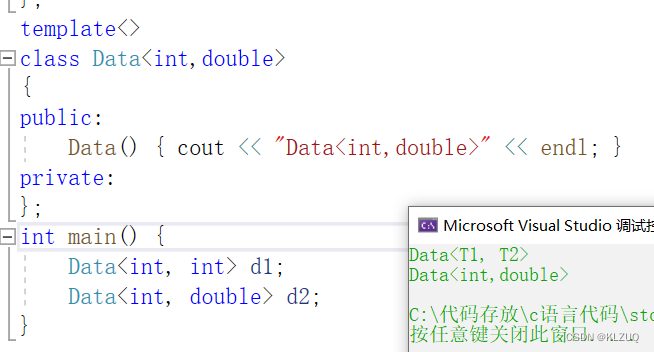
我们在这个特化的类里随意修改,不会影响原来的类
我们下面来看一个应用场景
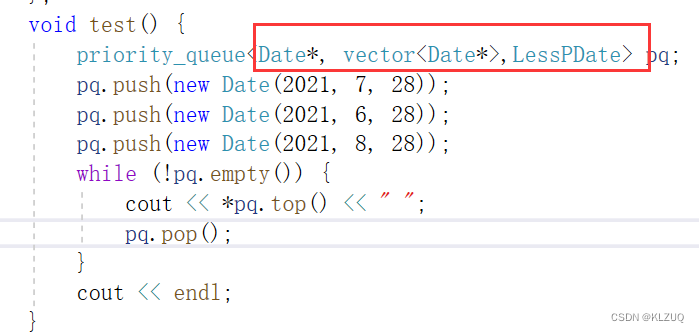
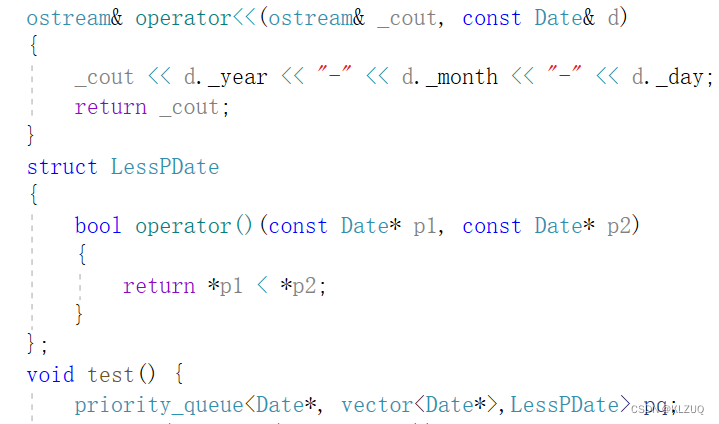
这是我们之前的优先级队列,正常的数据正常存进去就可以,但是我们要存一个Date*,它的后面就要写很多内容 ,比较大小我们希望使用我们自己的LessDate去比较
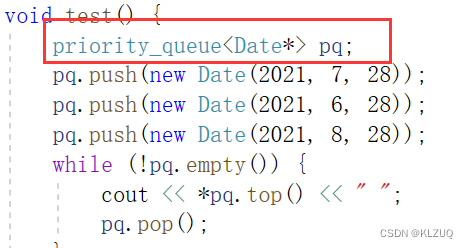
也就是我们写成这样就可以直接用LessDate去比较,而不用写后面的内容

我们就可以对less进行特化,从而解决问题

再看看我们的普通版 ,特化的本质就是编译器的匹配原则,符合条件就走一个特殊化处理
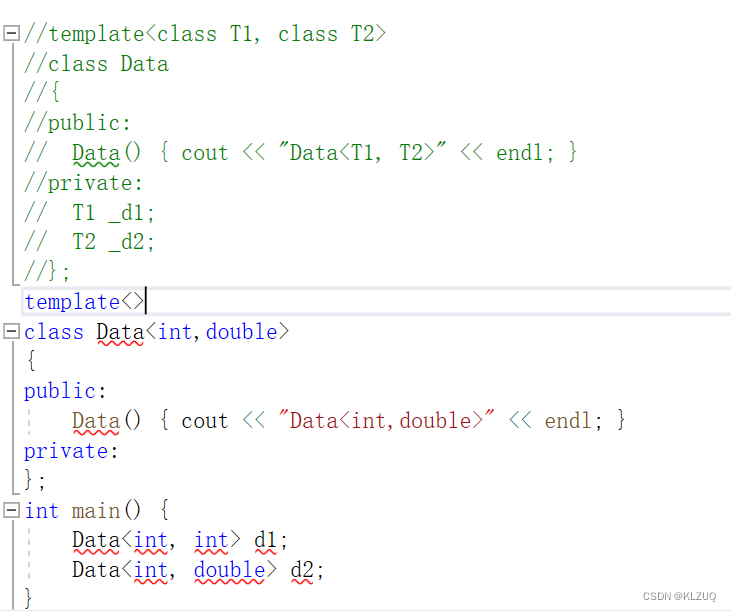
特化必须要有原模版,这里我们写的叫做全特化,我们还可以半特化(偏特化)
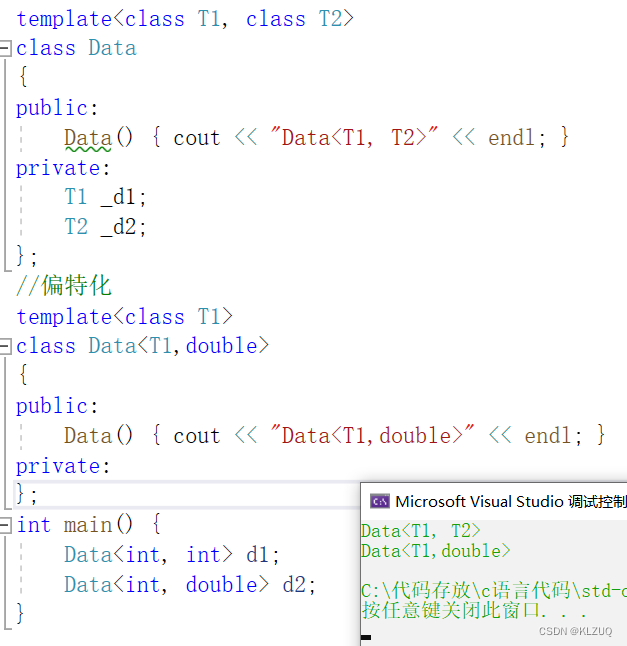
第一个参数可以随便选,第二个如果是double,会走下面的,否则还是走原来的

我们把两种特化都写上
偏特化除了可以特化部分参数,还可以对某些类型进行限制

比如这里,无论是什么类型,只要是两个指针就会进行匹配
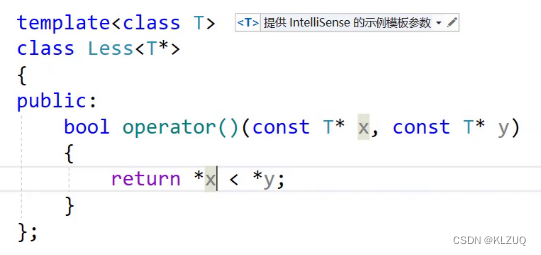
再看我们的Less,我们就可以改成这样的,只要是指针 ,就解引用去比较
库里面也有使用特化的场景,也有自己独特的价值
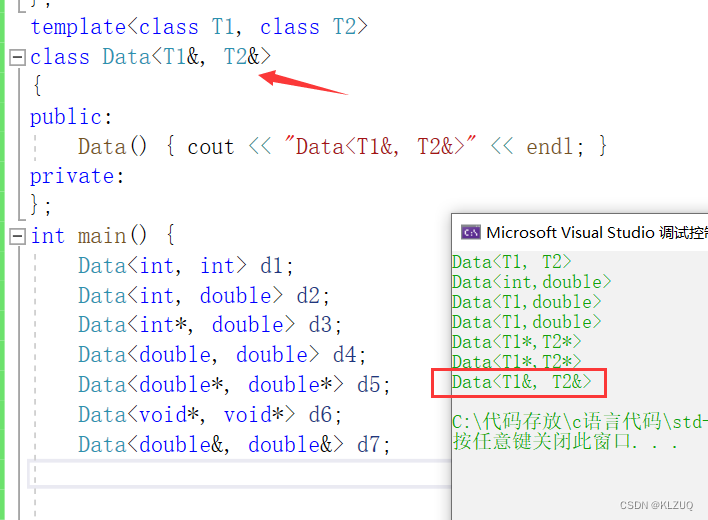
还可以在传引用时特化 ,指针和引用混在一起的也可以
模板分离编译
什么是分离编译?
一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。
我们之前模拟实现的string,vector,list等等声明和定义是在一起的,而我们之前在C语言时写代码经常会声明和定义在两个文件里
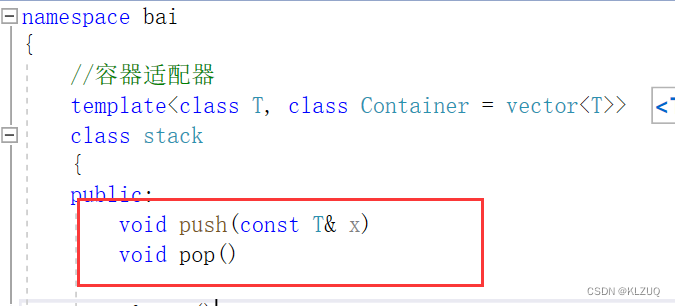
我们以push和pop为例

我们将声明和定义分离
 然后出现了链接错误
然后出现了链接错误
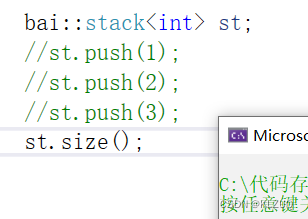
可是我们调用size缺没有问题
链接错误是通过了编译,在符合表里找不到地址,这是什么原因呢?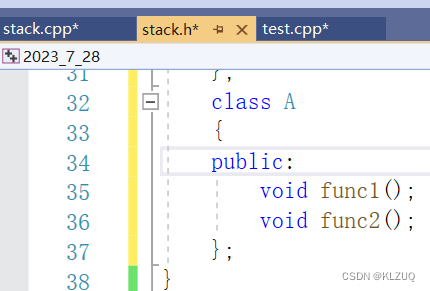
我们在.h文件里加一个A类
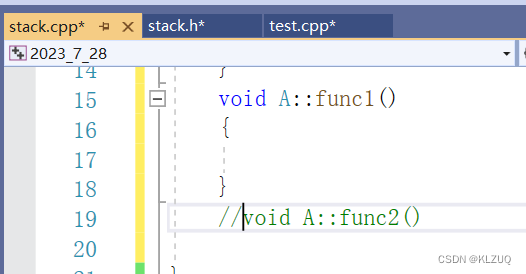
然后在.c里写出func1
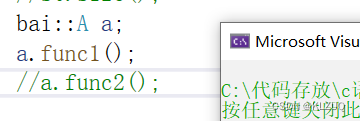

我们调用func1是没问题的,但是func2就有问题了
原因就是在call的时候可以找到func1,找不到func2
我们之前说过,在链接之前是单交互的
![]()
我们有这三个文件 ,会先预处理,预处理会进行头文件替换,预处理之后就没有头文件了,会生成.i文件,然后经过编译生成.s文件

这里的.h文件会被拷贝过来
有函数的定义才有函数的地址,所以size的地址在编译的时候,生成汇编时,在.s文件就确定了
而在.h里,除了size,像func1,func2,push,pop他们都是声明,没有定义,所以在编译阶段都没有地址
然后到了汇编,会生成.o文件,在经过链接,会将stack.o和test.o合并在一起,此时我们就发现,在编译完成时,push,pop,fun1和fun2的地址都是没有确认的,但是编译过了,这是因为是他们都有声明,声明是一种承诺,编译检查的声明函数名参数返回值等等都可以对上,所以就会等着链接的时候,拿着修饰后的函数去其他文件的符号表查找
这里就有问题了,func1查到了,所以链接过了,但是func2链接查不到,因为func2我们没有定义,这些我们都可以理解,然后就是push,push链接查不到,可是push我们是定义的,这是什么情况?
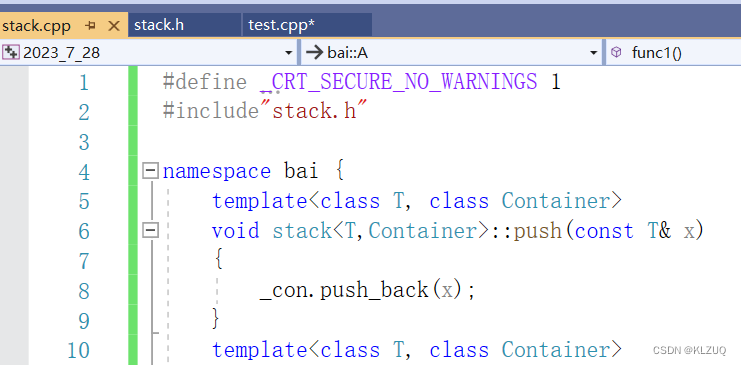
我们再看这几个文件,有声明有定义,但是单有一个定义,是不能生成地址的,因为这里连T是什么都不知道

我们知道最后这里会被各种修饰,变为pushi什么什么的 ,拿着pushi去前面到处找,是确实找不到的,.o文件里找不到的,没有生成地址,因为没有实例化,func1为什么可以呢?因为func1不是模板,它可以生成地址,涉及模板的,只有实例化才能生成地址
举个例子,假设我们买房,然后我们的钱在银行存的是死期,于是我们用信用卡套了几万块钱,当我们把钱转给开发商时,被银行拦截下来,告诉我们借贷的钱不能用来入市,这里就存在一个信息差,银行知道,而我们不知道,所以我们的代码也是一样的
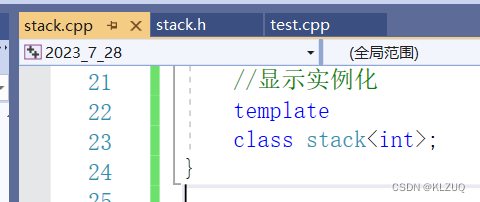
这里的一个解决办法就是显示实例化 ,但是这种方式是不好的
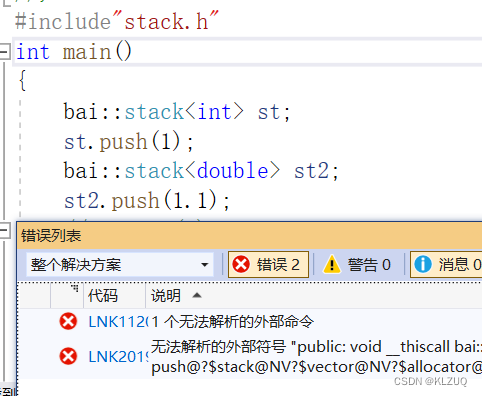
这种方法治标不治本
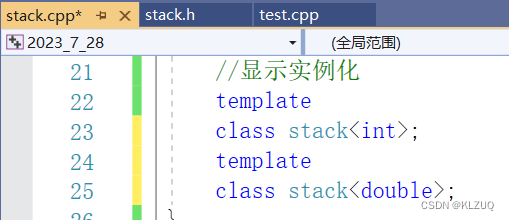
除非我们再加一个,但是这样太麻烦了,用一个就要加一个
这里还有更好的办法,大家先想想为什么我们调用size没事
是因为size不需要去链接的时候找,其他类型是因为只有声明,而size的声明和定义在一起,所以最后在test.cpp里它知道自己要实例化成什么,而且他有定义,就会实例化,可以找到
所以想要声明和定义分离的话,在一个文件声明和定义分离就行了,stl里也是这么做的

这是stl的list,对于小函数,这种几行就能写完的,它的定义就在类里面,成了内联
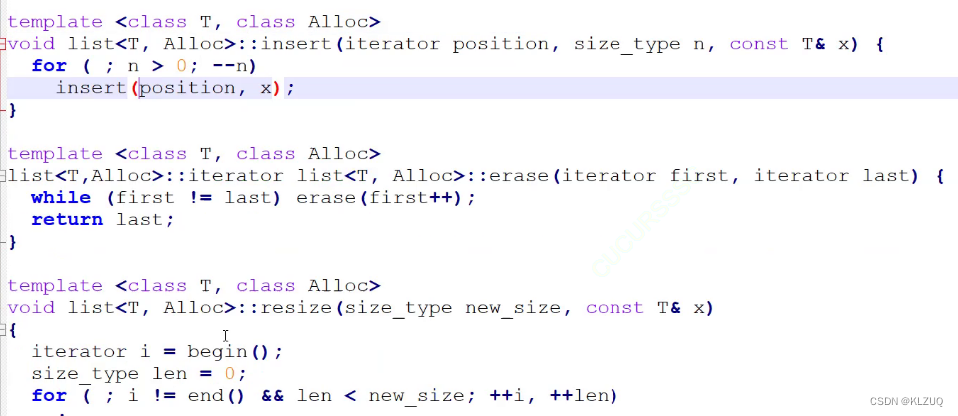
而大一点的在类外面,不过他们还是在同一个文件里 ,而不是分离成两个文件
有些人会将声明和定义的文件改为xxx.hpp,就是.h和.cpp合在一起的意思
比如boost就是这样做的,当然定义为.h也可以,这只是名字的暗示,根据喜好选择即可
模板总结
【优点】1. 模板复用了代码,节省资源,更快的迭代开发, C++ 的标准模板库 (STL) 因此而产生2. 增强了代码的灵活性【缺陷】1. 模板会导致代码膨胀问题,也会导致编译时间变长2. 出现模板编译错误时,错误信息非常凌乱,不易定位错误
以上即为本期全部内容,希望大家可以有所收获
如果错误,还请指正