代码:https://github.com/zyxElsa/InST
论文:https://arxiv.org/abs/2211.13203
文章目录
- Abstract
- Introduction
- Related Work
- Image style transfer
- Text-to-image synthesis
- Inversion of diffusion models
- Method
- Overview
- Experiments
- Comparison with Style Transfer Methods
- Comparison with Text-Guided Methods
- Ablation Study
- User Study
- Conclusion
- 代码实战
Abstract
一幅绘画中的艺术风格是表达的手段,其中包括绘画材料、颜色和笔触,还有高层次的属性,如语义元素、物体形状等。**先前的任意样例引导的艺术图像生成方法通常无法控制形状变化或传达元素。**预训练的文本到图像合成扩散概率模型已经取得了显著的质量,但通常需要大量的文本描述来准确描绘特定绘画的属性。我们相信艺术作品的独特之处正是因为它无法用普通语言充分解释。
我们的关键想法是直接从一幅绘画中学习艺术风格,然后在不提供复杂的文本描述的情况下指导合成。**具体而言,我们将风格视为一幅绘画的可学习文本描述。**我们提出了一种基于反向推导的风格转移方法(InST),可以高效准确地学习图像的关键信息,从而捕捉并转移绘画的艺术风格。我们在许多不同艺术家和风格的绘画上展示了我们方法的质量和效率。
使用我们的方法进行风格转移的结果。仅通过一幅输入绘画,我们的方法可以准确地将参考图像的风格属性,如语义、材料、物体形状、笔触和颜色,转移到自然图像上,并且只需要一个非常简单的学习文本描述“[C]”。

Introduction
如果一张照片能道出千言万语,每幅绘画都诉说一个故事。
一幅绘画蕴含着艺术家自己的创作灵感。绘画的艺术风格可以表现为个性化的质感和笔触,描绘的美丽瞬间或特定的语义元素。所有这些艺术因素很难用文字描述。因此,当我们希望利用一幅喜爱的绘画创作新的数字艺术作品,以模仿艺术家的原始创意时,任务就变成了样例引导的艺术图像生成。
近年来,从给定的示例生成艺术图像引起了许多兴趣。其中一个典型的任务是风格转移[1, 16, 30, 48, 52],通过将自然图像和绘画图像的内容相结合,从任意输入的自然图像和绘画图像对中创建新的艺术图像。然而,特定的艺术因素,如物体形状和语义元素,很难进行转移(见图2(b)和图2(e))。文本引导的风格化[13, 15, 26, 34]通过给定自然图像和文本提示生成艺术图像,但通常用于目标风格的文本提示只能是材料的粗略描述(例如“油画”,“水彩画”,“素描”),艺术运动(例如“印象派”,“立体主义”),艺术家(例如“文森特·梵高”,“克劳德·莫奈”)或著名艺术品(例如“星夜”,“呐喊”)。扩散基方法[8, 22, 24, 32, 47]基于文本提示生成高质量且多样化的艺术图像,无论是否有图像示例。除了输入图像外,如果我们想要复现一些生动的内容和风格,生成过程需要详细的辅助文本输入,这可能仍然难以在结果中复现特定绘画的关键创意。
在本文中,我们提出了一种新颖的示例引导的艺术图像生成框架InST,它与风格转移和文本到图像合成有关,旨在解决上述所有问题。只需一幅输入绘画图像,我们的方法可以学习并将其风格转移到自然图像上,并且只需要一个非常简单的文本提示(见图1和图2(f))。生成的图像展现了原始绘画的非常相似的艺术特性,包括材料、笔触、颜色、物体形状和语义元素,而不会失去多样性。此外,我们还可以通过给出文本描述来控制生成图像的内容(见图2©)。
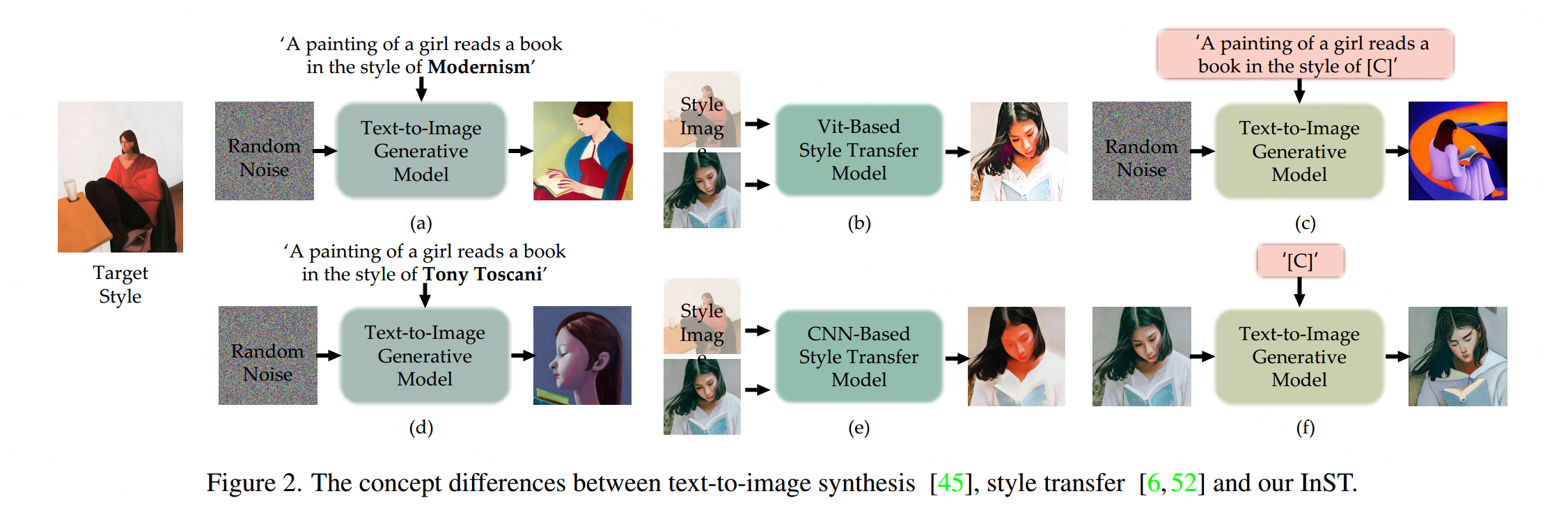
为了实现这个优点,我们需要获取图像风格的表示,这指的是在图像的高层次文本描述中出现的一系列属性。我们将文本描述定义为“新词”,这些词在正常语言中并不存在,并通过反推方法获得它们的embeddings 。我们受益于最近扩散模型[38,45]和inversion [2,14]的成功。我们在工作中将扩散模型作为主干骨架进行反推,并在图像到图像和文本到图像合成中作为生成器。具体而言,我们提出了一种基于注意机制的高效准确的文本反推方法,它可以快速地从图像中学习关键特征,并采用随机反推来保持内容图像的语义。我们使用CLIP [35]图像嵌入来获取高质量的初始点,并通过多层交叉注意力来学习图像中的关键信息。以艺术图像作为参考,基于注意机制的反推模块将其CLIP图像嵌入作为输入,然后给出其文本嵌入。基于文本嵌入的扩散模型可以生成具有参考图像学习风格的新图像。
为了证明InST的有效性,我们进行了全面的实验,将我们的方法应用于众多不同艺术家和风格的图像上。所有实验都显示出我们的InST产生了优秀的结果,生成了艺术图像,其风格属性得到了很好的模仿,并且其内容与输入的自然图像或文本描述保持一致。与最先进的方法相比,我们展示了显著提高的视觉质量和艺术一致性。这些结果证明了我们方法的通用性、精度和适应性。
Related Work
Image style transfer
图像风格转移作为示例引导的艺术图像生成的典型机制已经被广泛研究。传统的风格转移方法使用低级手工设计的特征来匹配内容图像和风格图像之间的块[46, 50]。近年来,预训练的深度卷积神经网络被用于提取特征的统计分布,可以有效捕捉风格模式[17, 18, 25]。
任意风格转移方法使用统一的模型通过构建前向传递的架构来处理任意输入[7, 23, 27–29, 33, 44, 48, 51]。
Liu等人[30]通过自适应注意力归一化模块(AdaAttN)从浅层和深层特征中学习空间注意力得分。An等人[1]通过可逆神经流和无偏的特征转移模块(ArtFlow)减轻了内容泄漏问题。Chen等人[3]采用内外方案来学习特征统计量(均值和标准差)作为风格先验(IEST)。Zhang等人[52]通过对比学习直接从图像特征中学习风格表示,实现了增强任意风格转移(CAST)。除了CNN,视觉变换器也被用于风格转移任务。Wu等人[48]通过transformer驱动的风格合成模块(StyleFormer)进行内容引导的全局风格合成。Deng等人[6]提出了一种基于transformer的方法(StyTr2),通过考虑输入图像的长程依赖关系来避免风格转移中的内容偏差。图像风格转移方法主要关注学习和转移颜色和笔触,但在其他艺术创作因素(如物体形状和装饰元素)方面存在困难。
Text-to-image synthesis
文本引导的合成方法也可以用于生成艺术图像[10, 36, 37, 40, 49]。CLIPDraw [12]通过使用CLIP编码器[35]来最大化文本描述和生成绘画之间的相似性,从而合成艺术图像。VQGANCLIP [5]使用CLIP引导的VQGAN [11]来从文本提示中生成各种风格的艺术图像。Rombach等人[38]在潜在空间中训练扩散模型[21, 42]以降低复杂性,并从文本生成高质量的艺术图像。这些模型仅使用文本引导来生成图像,没有对细粒度内容或风格进行控制。
**有些方法添加图像提示来增加对生成图像内容的可控性。**CLIPstyler [26]通过使用CLIP损失和PatchCLIP损失将输入图像转换为带有文本描述的目标风格。StyleGANNADA [15]使用CLIP自适应地训练生成器,可以通过目标风格的文本描述将照片转换为艺术领域。Huang等人[22]提出了一种基于扩散的艺术图像生成方法,通过利用多模态提示作为引导来控制分类器自由的扩散模型。Hertz等人[19]通过使用包含风格描述的文本提示和注入源注意力图来将图像转换为艺术风格。这些方法仍然难以生成具有复杂或特殊艺术特征的图像,这些特征无法用普通文本来描述。StyleCLIPDraw [41]通过联合优化文本描述和风格图像来实现艺术图像的生成。Liu等人[31]通过对比训练策略从CLIP模型中提取风格描述,使网络能够在内容图像和文本风格描述之间进行风格转移。这些方法利用CLIP的对齐图像和文本嵌入来实现风格转移,通过缩小生成图像与风格图像之间的距离,而我们直接从艺术图像中获取图像表示。
Inversion of diffusion models
扩散模型的Inversion 是找到与生成图像相对应的噪声图和条件向量。这是改进示例引导的艺术图像生成质量的潜在方法。然而,简单地向图像添加噪声然后去噪可能会导致图像内容发生显著变化。Choi等人[4]通过使用目标图像的噪声低通滤波器数据作为去噪过程的基础来执行反推。Dhariwal等人[9]通过对DDIM [43]采样过程进行闭合形式的反推,得到产生给定真实图像的潜在噪声图。Ramesh [36]基于扩散模型和反推CLIP开发了一种文本条件的图像生成器。上述方法在保持忠实度的同时,很难生成给定示例的新实例。Gal等人[14]提出了一种文本反推方法,以在固定的文本到图像模型的嵌入空间中找到描述特定对象或艺术风格的视觉概念的新伪词。他们使用基于优化的方法直接优化概念的嵌入。Ruiz等人[39]将主题嵌入到文本到图像扩散模型的输出域中,使得它可以在新视角中合成,并具有唯一的标识符。他们的反推方法基于扩散模型的微调,需要高计算资源。这两种方法通过文本反推从图片中学习概念,但它们需要一个小的(3-5张)图像集来描述概念。他们的目标概念总是一个对象。我们的方法可以从单个图像中学习相应的文本嵌入,并将其作为条件来指导艺术图像的生成,无需微调生成模型。
Method
Overview
在这项工作中,我们使用反推作为我们的InST框架和SDM的生成骨干。需要注意的是,我们的框架不限于特定的生成模型。如图3所示,我们的方法涉及像素空间、潜在空间和文本空间。在训练过程中,图像x和图像y是相同的。图像x的图像嵌入是通过CLIP图像编码器获得的,然后发送到基于注意力的反推模块。通过多层交叉注意力,学习图像嵌入的关键信息。反推模块给出文本嵌入v,将其转换为标准格式的标题条件SDMs。在输入文本信息的条件下,生成模型通过序列去噪过程从随机噪声zT获得一系列潜在代码zt,最后给出对应于艺术图像的潜在代码z。反推模块通过前向过程和反向过程(见第3.2节)的“潜在噪声”计算简单损失的LDMs进行优化。在推理过程中,x是内容图像,y是参考图像。参考图像y的文本嵌入v引导生成模型生成一个新的艺术图像。
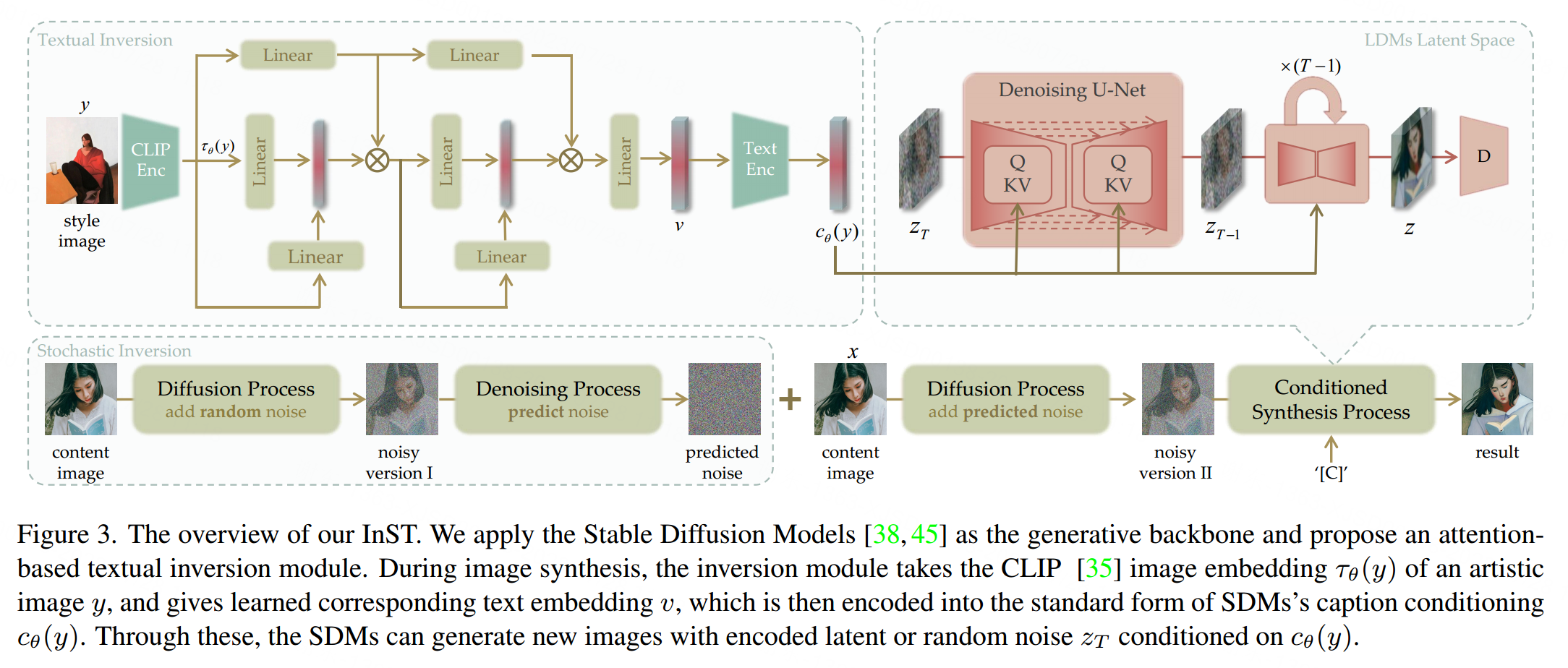
我们的目标是获得预训练的文本到图像模型对于特定绘画的中间表示。SDMs在文本到图像生成中使用CLIP文本嵌入作为条件。CLIP文本编码包含标记化和参数化两个过程。输入文本首先被转换成标记,每个单词或子单词对应一个预定义字典中的索引。然后,每个标记与一个可以通过索引定位的独特嵌入向量相关联。我们将绘画的概念设置为占位符"[C]“,并将其标记化的对应文本嵌入设置为可学习的向量vˆ。”[C]“位于正常语言领域,而vˆ位于文本空间。通过假设一个在真实语言中不存在的”[C]“,我们为某个无法用正常语言表达的艺术图像创造了一个"新词”。为了获得vˆ,我们需要设计约束作为监督,依赖于单个图像。学习vˆ的一种直观方法是通过直接优化[14],即最小化单个图像的LDM损失:

由于CLIP的图像嵌入和文本嵌入在对齐的潜在空间中,它为我们的优化过程提供了强大的指导。我们提出了一种基于多层交叉注意力的学习方法。首先,将输入的艺术图像送入CLIP图像编码器,并获得图像嵌入。通过对这些图像嵌入执行多层注意力,可以快速获取图像的关键信息。CLIP图像编码器τθ将y投影到图像嵌入τθ(y)。多层交叉注意力从v0 = τθ(y)开始。然后,每一层实施
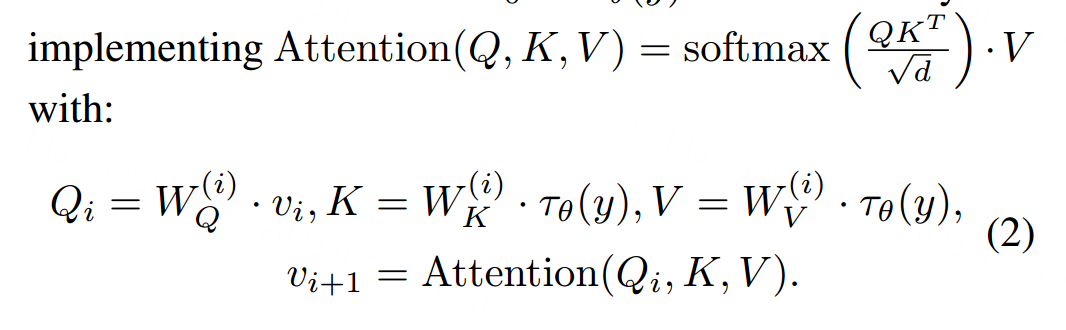
在训练过程中,模型仅通过相应的文本嵌入进行条件化。为了避免过拟合,我们在每个交叉注意力层中应用了丢弃(dropout)策略,丢弃率设置为0.05。

我们观察到,除了文本描述外,由随机种子控制的随机噪声对于图像的表示也很重要。正如在[19]中所示,随机种子的改变导致视觉差异明显变化。我们将基于预训练的文本到图像扩散模型的图像表示定义为两个部分:整体表示和细节表示。整体表示指的是文本条件,而细节表示由随机噪声控制。我们将从图像到噪声图的过程定义为反演问题,并提出随机反演以保持内容图像的语义。我们首先向内容图像添加随机噪声,然后使用扩散模型中的去噪U-Net来预测图像中的噪声。预测的噪声在生成过程中被用作初始输入噪声,以保留内容。具体而言,对于每个图像z,随机反演模块将图像潜在代码z = E(y)作为输入。将z的噪声版本zt设置为可计算的参数,然后通过以下方式获得εt:
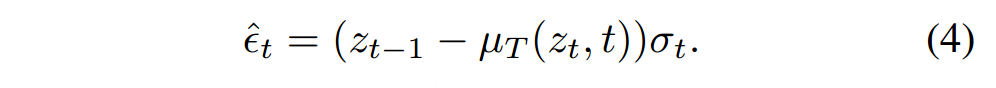
We illustrate the stochastic inversion in Figure 3.
Experiments
在本节中,我们提供可视化比较和应用示例,以展示我们方法的有效性。
实现细节:我们保留了SDMs的原始超参数选择。训练过程在一张NVIDIA GeForce RTX3090上,批大小为1,每张图像大约需要20分钟。基本学习率设置为0.001。合成过程的时间与SDM相同,取决于步数。
图5. 与文本反演[14]的定性比较。我们的方法在效率和准确性方面表现优越。可以观察到,我们基于注意力机制的反演可以更快地收敛到对应于艺术图像的文本特征空间区域。

Comparison with Style Transfer Methods
我们将我们的方法与最先进的图像风格转移方法进行比较,包括ArtFlow [1],AdaAttN [30],StyleFormer [48],IEST [3],StyTr2 [6]和CAST [52],以展示我们方法的有效性。从结果中,我们可以看到我们的方法在将参考图像的语义和艺术技巧转移到内容图像方面相比传统风格转移方法有明显的优势。例如,我们的方法可以更好地转移重要对象的形状,如面部形态和眼睛(第1、3、4和5行),山(第7行)和太阳(第8行)。我们的方法可以捕捉一些参考图像的特殊语义,并在结果中再现出视觉效果,例如背景上的星星(第1行),花环头饰(第3行)和跑车(第6行,内容图像中的汽车变成了跑车)。这些效果对于传统的风格转移方法来说是非常难以实现的。


Comparison with Text-Guided Methods
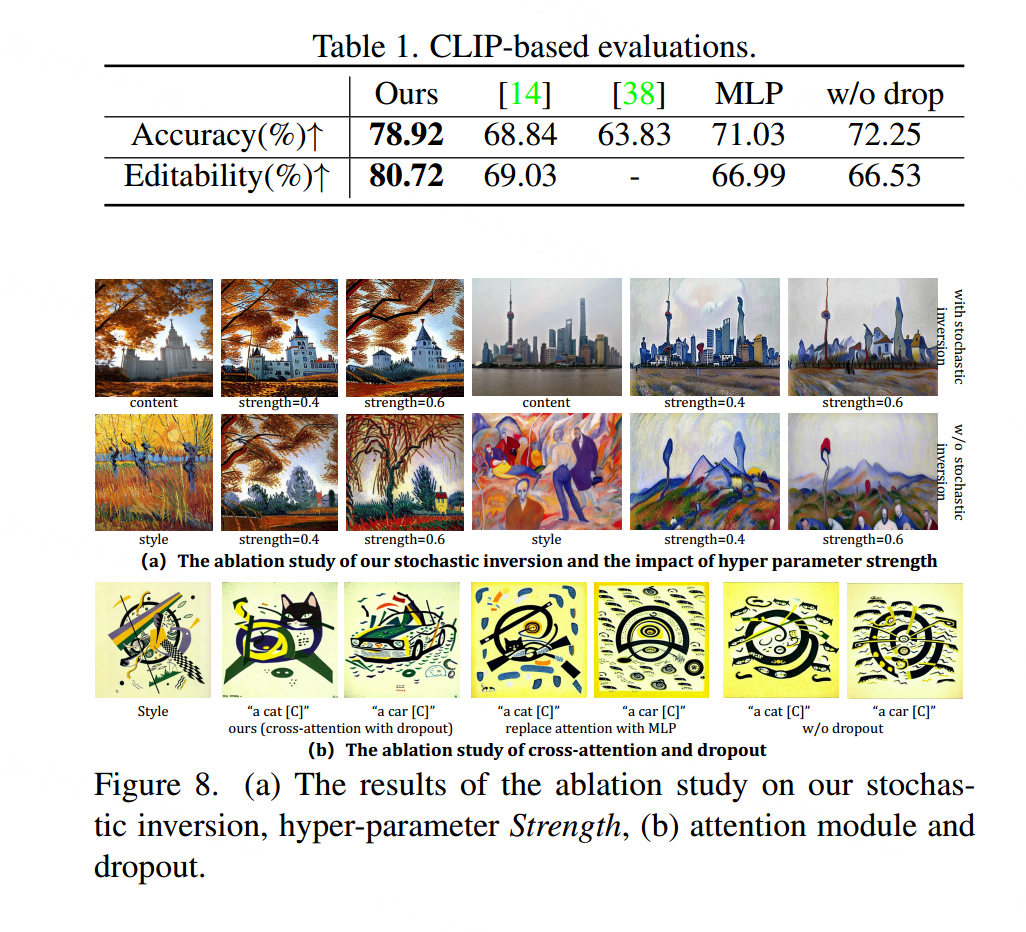
我们将我们的方法与文本反演[14]和SDM [38]在人类标题的指导下进行了比较。与[14]类似,我们通过比较样式图像和生成图像之间的CLIP嵌入相似性以及指导文本和生成图像之间的相似性来衡量准确性和可编辑性。
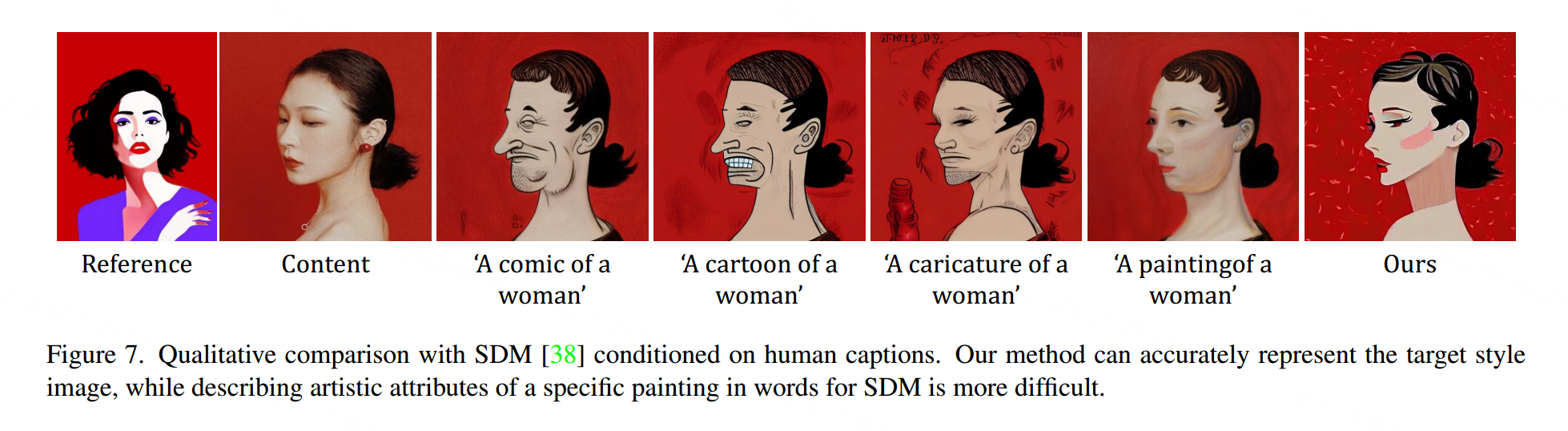
我们与最先进的文本到图像生成模型SDM [38]进行了比较。SDM可以根据文本描述生成高质量的图像。然而,仅通过文本来描述特定绘画的风格是很困难的,因此无法获得令人满意的结果。如图6和图7所示,我们的方法更好地捕捉了参考图像的独特艺术属性。如表1所示,我们的方法在准确性方面优于[38]。
图6. 与文本反演[14]和SDM[38]在文本到图像生成方面的定性比较。每个图像的内容取决于下方的标题。“[C]”表示我们对左列显示的相应绘画图像的学习描述。“*”表示由文本反演[14]优化得到的伪词。InST在可编辑性方面表现更好。我们的方法能够与附加文本进行交互,生成具有相应风格的艺术图像。然而,当[14]基于单个图像进行训练时,它受到附加文本的严重影响,无法保持风格。

Ablation Study
随机反演 如图8(a)所示,在没有随机反演的情况下,内容图像中的建筑物被转换为树木或山脉,而全模型可以保持内容信息并减少风格图像的语义影响。
超参数强度 对于图像合成,最相关的超参数是变化的强度,其影响如图8(a)所示。强度越大,风格图像对生成结果的影响越强,反之,生成图像更接近于内容图像。
注意模块 我们展示了多层注意力的消融研究,如图8(b)所示。通过多次与CLIP嵌入进行交互,多层注意力有助于使学习的概念与CLIP特征空间保持一致,从而提高可编辑性,如表1所示。
丢弃(Dropout) 在注意模块的线性层中添加了丢弃操作,以防止过拟合。如图8(b)和表1所示,通过丢弃潜在嵌入的参数,准确性和可编辑性都得到了改善。
User Study
我们将我们的方法与几种最先进的图像风格迁移方法(即ArtFlow [1]、AdaAttN [30]、StyleFormer [48]、IEST [3]、StyTr2 [6]和CAST [52])以及文本到图像生成方法(即文本反演 [14])进行了比较。所有基线方法均使用公开可用的实现,并采用默认配置进行训练。
对于每个参与者,随机选择了26组内容-参考图像对,并随机显示了我们的生成结果与其他方法之一的结果。参与者被建议以艺术一致性来评估生成图像与参考图像之间的表现,并被邀请在每个内容-参考图像对中选择更好的结果。最后,我们收集了来自87名参与者的2,262个投票。表2显示了每种方法获得的投票百分比,表明我们的方法在视觉特征迁移方面获得了最佳结果。
此外,我们对60名参与者进行了一项关于内容图像引导强度和艺术视觉效果偏好的调查。在存在内容图像的情况下,用户倾向于认为“为了描绘艺术风格,应该适当地装饰内容的细节”。然后,我们邀请参与者对其期望的视觉效果因素进行排名。在排序问题中,选项的平均综合得分根据所有参与者的排序自动计算。得分越高,综合排名越高。计分规则为:
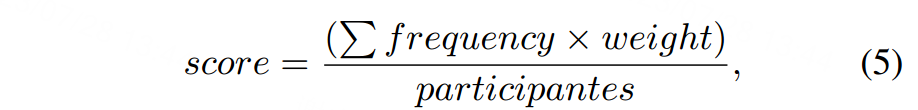
得分表示选项的平均综合评分,参与者表示完成此问题的人数,频率表示选项被用户选择的频率,权重表示选项的权重,由排名确定。排名结果(按得分从高到低排名):(1)在语义对应的主题上具有相似的艺术效果(得分为5.4);(2)使用相同的绘画材料(得分为3.65);(3)具有类似的笔触(得分为3.2);(4)具有典型的形状(得分为2.65);(5)具有相同的装饰元素(得分为2.1);(6)共享相同的颜色(得分为1.4)。
尽管我们的方法在一定程度上可以转换典型的颜色,但当内容图像和参考图像的颜色存在显著差异时,我们的方法可能无法在语义上进行一对一的颜色转换。例如,在图4的第一行中,内容图像的绿色头发没有转换成棕色。如图9所示,我们使用了一个额外的色调转换模块[23]来对齐内容图像和参考图像的颜色。然而,我们观察到不同的用户对于是否保留内容图像的颜色有不同的偏好。我们认为照片的颜色至关重要,所以在某些情况下我们选择尊重原始内容图像的色调。

Conclusion
我们引入了一种新颖的示例引导艺术图像生成框架,称为InST。该框架通过学习单幅绘画图像的高级文本描述,并指导文本到图像生成模型创建具有特定艺术外观的图像。我们提出了一种基于注意力的文本逆转方法,将绘画反演为相应的文本嵌入,该方法受益于CLIP对齐的文本和图像特征空间。广泛的实验证明,与最先进的方法相比,我们的方法在图像到图像和文本到图像生成结果方面取得了优越的成果。我们的方法旨在为即将到来的独特艺术图像合成任务铺平道路。
代码实战
训练
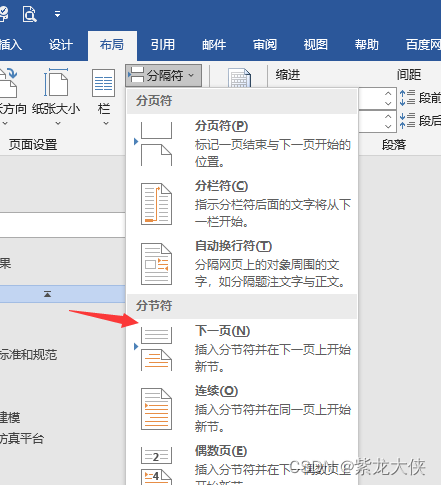
注意这里--gpus 0, 这里的逗号不能去掉!
python main.py --base configs/stable-diffusion/v1-finetune.yaml -t --actual_resume ./models/sd/sd-v1-4.ckpt -n log1_shuimo --gpus 0, --data_root /ssd/xiedong/workplace/InST-main/style