什么是LRU
通过之前的学习我们知道计算机在处理任务的时候是先将数据从硬盘中提取出来加载进内存,然后再将内存中的数据加载进入cpu进行计算,但是这里存在一个问题cpu的计算速度非常快,而内存中加载数据的速度又很慢,所以为了提供整机的工作效率我们就得在内存和cpu计算机中添加一个东西叫做缓存,狭义的Cache指的是位于CPU和主存间的快速RAM(缓存),通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。 广义上的Cache指的是位于速度相差较大的两种硬件之间,用于协调两者数据传输速度差异的结构。除了CPU与主存之间有Cache,内存与硬盘之间也有Cache,乃至在硬盘与网络之间也有某种意义上的Cache── 称为Internet临时文件夹或网络内容缓存等。但是Cache的容量有限,因此当Cache的容量用完后,而又有新的内容需要添加进来时, 就需要挑选并舍弃原有的部分内容,从而腾出空间来放新内容。那么将哪部分数据删除这就由LRU来决定,设计一个LRU并不难,但是要想设计一个高效的LRU是很有难度的,这里的高效指的是任何操作的时间复杂度都是o(1), LRU Cache 的替换原则就是将最近最少使用的内容替换掉。其实,LRU译成最久未使用会更形象,因为该算法每次替换掉的就是一段时间内最久没有使用过的内容,那么接下来我们就通过一道题来带着大家模拟实现LRU,题目的内容如下:

题目给的代码如下:
class LRUCache {
public:
LRUCache(int capacity) {
}
int get(int key) {
}
void put(int key, int value) {
}
};
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache* obj = new LRUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/
模拟实现LRU
通过上面的介绍我们知道get函数就是到缓存里面查找数据,如果找到了就返回数据的内容如果没有找到就返回-1,然后put函数有两个功能一个是往容器里面插入数据,另外一个就是更新容器里面的数据,那么要想实现上述功能的话我们可以添加一个哈希表来实现,这样我们查找数据的时间复杂度是o(1),删除数据的时间复杂度也是o(1),更新数据的时间复杂度也是o(1),但是这么做存在一个问题这里的时间复杂度确实符合要求了,但是我们这里要实现的是LRU啊,在删除数据的时候你怎么知道谁的优先级高谁的优先级低呢?简单的说就是你怎么知道要删除的是哪些数据呢?所以单独的一个哈希表肯定是无法满足要求的,那么这时有人说那能不能添加一个优先级队列来辅助实现呢?答案也是不行的,优先级队列确实可以将数据的优先级进行排序,我们一下子就可以知道谁的优先级最高,谁的优先级最低,但是这里有个问题当我们更新数据的时候将优先级调制最高,那你如何将里面的数据优先级队列中的那个元素进行调整呢?即使能够调整那能不能保证时间复杂度是o(1)呢?所以这种方法肯定是不行的那么这个时候有小伙伴又会说能不能添加引用计数的形式来实现呢?答案是可以的但是这么做还是太麻烦了,我们有一个很简单的方法就是添加链表来进行辅助,那么这里的代码如下:
class LRUCache {
public:
LRUCache(int capacity) {
}
int get(int key) {
}
void put(int key, int value) {
}
private:
unordered_map<int, int> _hashmap;
list<pair<int,int>> _l1;
};
查找和新增可以通过哈希表来做到时间复杂度为O(1),在删除的时候可以根据链表中元素的位置来判断优先级的高低,如果对一个元素进行更新的话就将这个链表调整值头部,也就是说越位于链表头部的节点优先级越高,相反位于越位于链表尾部的节点优先级越低,在删除的时候优先删除链表尾部的数据,这么听好像很有道理但是更新的时间复杂度能够做到o(1)吗?好像不行对吧,因为链表不支持随机访问,所以我们得循环遍历从而找到要更新的节点,那么这一步时间复杂度就不是o(1)了更何况后面的步骤,所以我们这里得进行改进,哈希表可以帮助我们在o(1)的时间复杂度找到想要的数据,那要想更新的问题我们就得在哈希表找到数据的同时找到数据对应在链表上的位置,那么这里的做法就是在修改哈希表中记录的元素类型,由原来的int改为list类中的迭代器类型,那么这里的代码就如下:
unordered_map<int, list<pair<int,int>>::iterator> _hashmap;
list<pair<int,int>> _l1;
哈希表中的元素有一个元素记录着链表中相应元素的位置,这样我们就可以使用O(1)的时间找到哈希表中的元素还顺便找到了链表中的元素,构造函数里面提供了一个名为capacity的变量,表示这个容器能够存储数据的个数,那么为了方便我们后面删除数据,这里就再添加一个数据表示当然LRU的容量,并且再使用typedef来重命名依次减轻代码的长度,然后构造函数里面只用对容量变量进行初始化就行那么这里的代码就如下:
class LRUCache {
public:
typedef list<pair<int,int>>::iterator LiIter;
LRUCache(int capacity)
:_capacity(capacity)
{}
int get(int key) {
}
void put(int key, int value) {
}
private:
unordered_map<int,LiIter> _hashmap;
list<pair<int,int>> _l1;
size_t _capacity;
};
get函数非常好实现,首先使用find函数来查找当前的数据在还是不在,那么这里我们可以使用find函数来实现,如果find函数的返回值为哈希表的end的话就说明当前数据不存在,如果不为end的话我们就先通过操作->来得到内部的第二个数据,但是这里的数据依然为一个指向链表的迭代器,所以这里还要通过操作符->来获取第二个数据才是我们想要的,那么这里的代码就下:
int get(int key) {
auto ret=_hashmap.find(key);
if(ret!=_hashmap.end())
{
return ret->second->second;
}
else
{
return -1;
}
}
但是这里并没有结束,因为我们查找了这里的数据,所以这个数据的优先级应该要被改变,也就是说将元素所在的链表位置进行该表,那么这里有两种方法第一种就是先记录当前的元素,然后将元素进行删除并在链表的头部插入一个相同的数据,最后修改迭代器的指向,但是这种方法太麻烦了我们可以直接使用容器中的splice函数来实现节点的转移,这个函数的参数形式和功能介绍如下:


我们可以将自己链表中的节点转移到自己链表的头部位置,那么这里的代码就如下:
int get(int key) {
auto ret=_hashmap.find(key);
if(ret!=_hashmap.end())
{
LiIter it =ret->second;
_l1.splice(_l1.begin(),_l1,it);
return it->second;
}
else
{
return -1;
}
}
put函数分为两种情况:一个是新增一个是插入,我们首先来判断一下当前的数据在还是不在如果在的话就是新增,如果不在的话就是插入,那么这里可以通过find函数的返回值来进行判断:
void put(int key, int value) {
auto ret=_hashmap.find(key);
if(ret!=_hashmap.end())
{
//元素存在那么这里就是更新
}
else
{
//元素不存在这里是插入
}
}
如果当前是插入的话这里得进行判断,但是这里判断的时候不能使用list的size函数而是得使用哈希的size函数,因为list中的size是顺序遍历时间复杂度为o(N),而哈希中的size是直接返回内部的数据,所以当对象满了之后我们就得删除数据,首先创建变量记录链表的尾部数据,然后使用哈希的erase函数删除该数据,最后使用pop_back函数删除链表的尾部数据,那么这里的代码如下:
void put(int key, int value) {
auto ret=_hashmap.find(key);
if(ret!=_hashmap.end())
{
//元素存在那么这里就是更新
}
else
{
//元素不存在这里是插入
if(_capacity==_hashmap.size())
{
//满了就要删除
pair<int,int> tmp=_l1.back();
_l1.pop_back();
_hashmap.erase(tmp.second);
}
}
}
将数据删除之后就往链表的头部插入数据,然后再往哈希表里面插入数据并将该元素的第二个元素初始化为容器开头的位置,那么这里的代码就如下:
void put(int key, int value) {
auto ret=_hashmap.find(key);
if(ret!=_hashmap.end())
{
//元素存在那么这里就是更新
}
else
{
//元素不存在这里是插入
if(_capacity==_hashmap.size())
{
//满了就要删除
pair<int,int> tmp=_l1.back();
_l1.pop_back();
_hashmap.erase(tmp.second);
}
_l1.push_front(make_pair(key,value));
_hashmap[key]=_l1.begin();
}
}
如果当前的对象没有满的话我们就要更新value的值和链表中当前元素所在的位置,那么这里的思路和前面的一致,只不过得修改一下存储的value即可,那么这里的代码如下:
void put(int key, int value) {
auto ret=_hashmap.find(key);
if(ret!=_hashmap.end())
{
//元素存在那么这里就是更新
LiIter it =ret->second;
it->second=value;
_l1.splice(_l1.begin(),_l1,it);
}
else
{
//元素不存在这里是插入
if(_capacity==_hashmap.size())
{
//满了就要删除
pair<int,int> tmp=_l1.back();
_l1.pop_back();
_hashmap.erase(tmp.second);
}
_l1.push_front(make_pair(key,value));
_hashmap[key]=_l1.begin();
}
}
写到这里我们的代码就完成了,那么完整的代码如下:
class LRUCache {
public:
typedef list<pair<int,int>>::iterator LiIter;
LRUCache(int capacity)
:_capacity(capacity)
{}
int get(int key) {
auto ret=_hashmap.find(key);
if(ret!=_hashmap.end())
{
LiIter it =ret->second;
_l1.splice(_l1.begin(),_l1,it);
return it->second;
}
else
{
return -1;
}
}
void put(int key, int value) {
auto ret=_hashmap.find(key);
if(ret!=_hashmap.end())
{
//元素存在那么这里就是更新
LiIter it =ret->second;
it->second=value;
_l1.splice(_l1.begin(),_l1,it);
}
else
{
//元素不存在这里是插入
if(_capacity==_hashmap.size())
{
//满了就要删除
pair<int,int> tmp=_l1.back();
_l1.pop_back();
_hashmap.erase(tmp.first);
}
_l1.push_front(make_pair(key,value));
_hashmap[key]=_l1.begin();
}
}
private:
unordered_map<int,LiIter> _hashmap;
list<pair<int,int>> _l1;
size_t _capacity;
};
题目测试的结果如下:
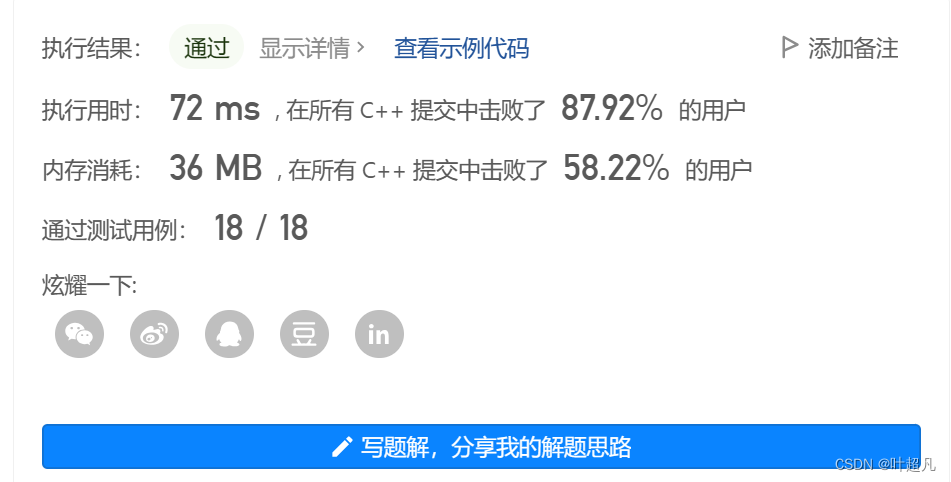
那么这就说明我们的代码没有问题,本篇文章到此结束。









![c++学习(哈希)[21]](https://img-blog.csdnimg.cn/bbc6b0da083b46a4a2b85bce726fd2ef.png)