为什么使用Hive?
使用Hadoop MapReduce直接处理数据所面临的问题:人员学习成本太高需要掌握ava语言MapReduce实现,复杂查询逻辑开发难度太大!
1,使用Hive处理数据的好处操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)避免直接写MapReduce,减少开发人员的学习成本支持自定义函数,功能扩展很方便
2,背靠Hadoop,擅长存储分析海量数据集合。
什么是Hive
hive介绍
Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行Hive由Facebook实现并开源。
架构图

组件
用户接口
包括 CLI、JDBC/0DBC、WebGU。其中,CLI(command line interface)为shell命行;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。
元数据存储
通常是存储在关系数据库如 ysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
Driver驱动程序,包括语法解析器、计划编译器、优化器、执行器
完成HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS中,并在随后有执行引擎调用执行。
执行引擎
Hive本身并不直接处理数据文件。而是通过执行引警处理。当下Hive支持MapReduce、Tez、Spark3种执行引警
Data Mode1概念
数据模型:用来描述数据、组织数据和对数据进行操作,是对现实世界数据特征的描述Hive的数据模型类似于RDBMS库表结构,此外还有自己特有模型
Hive中的数据可以在粒度级别上分为三类
Table表
Partition 分区
Bucket 分桶
Databases 数据库
Hive作为一个数据仓库,在结构上积极向传统数据库看齐,也分数据库( Schema),每个数据库下面有各自的表组成。默认数据库default。
Hive的数据都是存储在HDFS上的,默认有一个根目录,在hive-site.xml中,由参数hive.metastore.warehouse.dir指定。默认值为/user/hive/warehouse。
因此,Hive中的数据库在HDFS上的存储路径为:
$fhive.metastore.warehouse.dir]/databasename.db
比如,名为itcast的数据库存储路径为:
/user/hive/warehouse/itcast.db
Tables 表
Hive表与关系数据库中的表相同。Hive中的表所对应的数据通常是存储在HDFS中,而表相关的元数据是存储在RDBMS中。
Hive中的表的数据在HDFS上的存储路径为:
$fhive.metastore.warehouse.dirl/databasename.db/tablename
Partitions 分区
1,Partition分区是hive的一种优化手段表。分区是指根据分区列(例如“日期day”)的值将表划分为不同分区。这样可以更快地对指定分区数据进行查询。
2,分区在存储层面上的表现是:table表目录下以子文件夹形式存在。
3,一个文件夹表示一个分区。子文件命名标准: 分区列分区值。
4,Hive还支持分区下继续创建分区,所谓的多重分区。关于分区表的使用和详细介绍,后面模块会单独展开。
Buckets 分桶
Bucket分桶表是hive的一种优化手段表。分桶是指根据表中字段( 例如“编号ID”)的值,经过hash计算规则将数据文件划分成指定的若干个小文件。
分桶规则:hashfunc(字段)% 个数,余数相同的分到同一个文件。
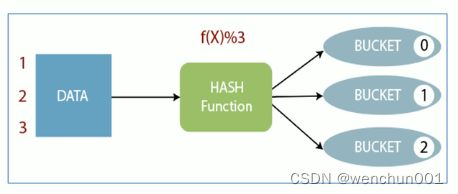
分桶的好处:
1,可以优化join查询和方便抽样查询
2,Bucket分桶表在HDFS中表现为同一个表目录下数据根据hash散列之后变成多个文件。关于桶表以及分桶操作,后面模块会单独展开详细讲解。
Hive和Hadoop关系
从功能来说,数据仓库软件,至少需要具备下述两种能力:
1,存储数据的能力、分析数据的能力。
2,Hive利用HDFS存储数据,利用MapReduce查询分析数据。
Apache Hive作为一款大数据时代的数据仓库软件,当然也具备上述两种能力。只不过Hive并不是自己实现了上述两种能力,而是借助Hadoop。
3,Hive的最大的魅力在于用户专注于编写HQL,Hive帮您转换成为MapReduce程序完成对数据的分析。
Hive不不是没啥用,不过是套壳Hadoop罢了,其实不然。
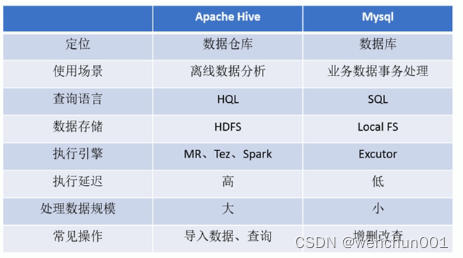
Hive和MySQL对比
1,Hive虽然具有RDBMS数据库的外表,包括数据模型、SQL语法都十分相似,但应用场景却完全不同。
2,Hlive只适合用来做海量数据的离线分析。Hive的定位是数据仓库,面向分析的OLAP系统。
3,Hive不是大型数据库,也不是要取代MySQL承担业务数据处理。
Hive元数据
元数据(Metadata),又称中介数据、中继数据,为描述数据的数据( data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
Hive Metadata
1,Hive Metadata即Hive的元数据
2,包含用Hive创建的database、 table、表的位置、类型、属性,字段顺序类型等元信息。
3,元数据存储在关系型数据库中。如hive内置的Derby、或者第三方如MySQL等。
Hive Metastore
1,Metastore即元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据。
2,有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore服务即可。某种程度上也保证了hive元数据的安全
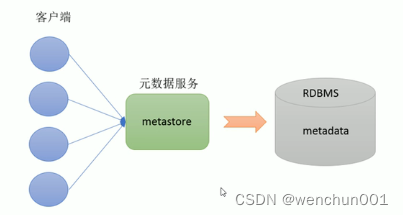
Metastore配置方式
概述
metastore服务配置有3种模式:内嵌模式本地模式、远程模式区分
3种配置方式的关键是弄清楚两个问题:
1,Metastore服务是否需要单独配置、单独启动?
2,Metadata是存储在内置的derby中,还是第三方RDBMS,比如MySQL
本文中使用企业推荐模式--远程模式部署
内嵌模式
1,内嵌模式(Embedded Metastore)是metastore,默认部署模式。
此种模式下,元数据存储在内置的Derby数据库,并且Derby数据库和metastore服务都嵌入在主HiveServer进程中当启动HiveServer进程时,Derby和metastore都会启动。不需要额外起Metastore服务。但是一次只能支持一个活动用户,适用于测试体验,不适用于生产环境。
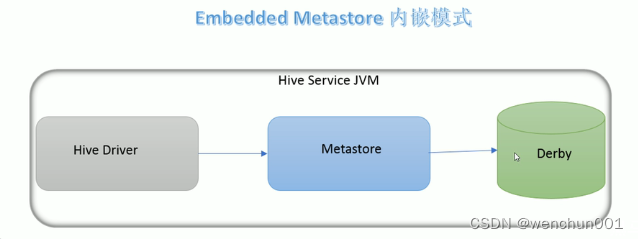
本地模式
本地模式(Local Metastore)下,Metastore服务与主HiveServer进程在同一进程中运行,但是存储元数据的数据库在单独的进程中运行,并且可以在单独的主机上。metastore服务将通过JDBC与metastore数据库进行通信本地模式采用外部数据库来存储元数据,推荐使用MySQL。
hive根据hive.metastore.uris 参数值来判断,如果为空,则为本地模式
缺点:每启动一次hive服务,都内置启动了一个metastore。

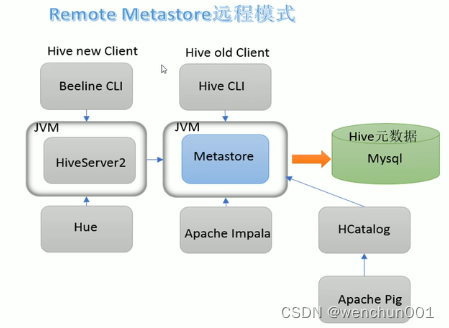
远程模式
1,远程模式(Remote Metastore)下,Metastore服务在其自己的单独JVM上运行,而不在HiveServer的JVM中运行。如果其他进程希望与Metastore服务器通信,则可以使用Thrift Network API进行通信。
2,远程模式下,需要配置hive.metastore.uris 参数来指定metastore服务运行的机器ip和端口,并且需要单独手动启动metastore服务。元数据也采用外部数据库来存储元数据,推荐使用MySQL。







![[深度学习实战]基于PyTorch的深度学习实战(下)[Mnist手写数字图像识别]](https://img-blog.csdnimg.cn/89ce5bf717c64f6cba851a83ff29453c.png)