-
根据国家电力行业发展报告统计,截止到 2018 年,全国电网 35 千伏及以上的输电线路回路长度达到 189 万千米,220 千伏及以上输电线路回路长度达73 万千米。截止到 2015年,根据国家电网公司的统计 330 千伏及以上输电线路故障跳闸总数中外力破坏作为主要原因的事故占到了 15.8%,而其中由线上异物引发的事故占到外力破坏的55.4%。特别是一些异物的人眼辨识度不高,在颜色、形状和大小上非常接近输电线上的金具,更容易使得工作人员漏检,进而引发电力事故,或者加长了异物处理的周期。电网公司的巡检工作主要依靠人工完成,需要大量人力物力,且实时性较差。 湖北工业大学,范亚雷
-
通过网络进行特定样本的训练,使得计算机程序具有对某一类或某几类特征的高敏感度,进而替代人眼实现图像中某些指定目标的识别与定位。通过新型的巡检设备替代传统的人工徒步巡检方式,通过图像分类和检测技术来筛选并且定位架空输电线异物,从而保障电力系统的安全可靠平稳运行。输电线的断股、输电杆塔事故、绝缘子破裂、绝缘子掉串以及输电线异物等方向都可以归类作为输电线路关键部件故障的研究内容。
-
提出的图像形态学方式识别和检测异物的方法,其核心思路都是根据附着异物的输电线的形态特征,例如:线路区域的灰度值、线路区域的形状、线路区域的宽度等,与正常输电线有所区别,采取合适的办法提取并判断这些高区分度特征是否符合设定值来判断异物的存在。但是显而易见,这类异物检测方式往往依赖于巡检图像背景与前景的分离结果,作者凭借对图像处理任务的认知理解和先验知识,通过图片的纹理、颜色和灰度值来设计分离算法,然后对提取出的输电线路区域进行特征计算,从而确定异物是否存在。其检测结果受前景提取算法参数设定和异物特征计算结果的影响很大,这就导致了算法在一定程度上缺少泛化能力和在复杂背景下检测异物的能力。
-
采用的深度学习模型各有不同,但共同特点是测试数据集中的图像都是默认存在异物的图像,这就相当于在进行目标检测之前先人为分类了图像。事实上,巡检所返回的大量图像中无异物的线路图像占了大多数,因此文献中的实验与真实应用的场景存在差距。
-
2019 年,全国“两会”提出“三型两网,世界一流”的国家电网建设目标,其内涵是以建设枢纽型、平台型、共享型为特征,以坚强智能电网和泛在电力物联网为手段,打造世界一流能源互联网企业。用移动互联、人工智能等现代通信和信息技术对传统电力行业赋能。截止至 2019 年,南方电网已使用无人机作业超 50 万公里,已全面实现“机巡为主、人巡为辅”的协同巡检模式。目前,使用无人机进行线路巡检的主要挑战集中在自动驾驶、飞行时间和通信带宽等方面。
-
卷积核中的值叫做权重,输入图像的每个位置是被同一个卷积核扫描的,即卷积的时候所用的权重是一样的。这样对于每一个卷积核来说,需要训练的权值参数与卷积核扫过的位置无关,需要调整的参数也就被限制在一个卷积核大小的数量级内。图像识别的一般流程如下:获取图像数据→数据预处理→提取特征→确定特征量并进行匹配→输出识别结果
-
计算机视觉中,像素之间的相关性与像素之间的距离同样相关,可以理解为在图像中的某一块区域中,相关性强的像素间距离往往较近,相关性比较弱的像素间距离则较远。局部连接,即卷积层的节点仅仅与其前一层的部分节点相连接。在假设数量级为 1 0 5 10^5 105 的示例图像上,若采用全连接则最终的参数量级为 1 0 11 10^{11} 1011。而局部连接大大减少了参数的数量级,在10 × 10的卷积核上仅为 1 0 8 10^8 108 数量级。相比减少了 3 个数量级,使网络的计算速度更快。
-
深度学习方法优势的体现需要大量的训练数据作为支撑,缺乏合适的数据大概率会导致网络的过拟合,严重的还会造成网络无法收敛。对个人构建的数据集来说,数据量一般是无法达到公开数据集千万级别数据量规模的,针对数据匮乏的问题,需要对已有数据进行处理,从而实现扩大数据量的目的。图片亮度可以通过增减图像通道R、G、B的值来调节大小,值越大亮度越高。
-
L = R + B + G 3 b r i = k L = k ∗ R + B + G 3 L=\frac{R+B+G}{3}\\ bri=kL=k*\frac{R+B+G}{3} L=3R+B+Gbri=kL=k∗3R+B+G
-
其中,𝐿作为亮度变化系数,表示亮度的强弱。各通道按照一定规律统一增减即可改变图像的亮度。利用深度学习对摄像装置所采集的现场图像进行分析,执行目标检测任务,若发现威胁电网安全运行的隐患将及时通知工作人员。深度学习发挥其优势需要有效样本达到一定数量,包含隐患的真实样本较少,有些异物种类甚至没有合适的样本,往往不能满足深度学习算法的训练要求。扩充样本并不是简单的增加训练集的过程,训练集样本必须联系实际使用场景,才能够使训练所得模型的性能获得提升。盲目增加无关样本可能会使模型性能下降。
-
-
对于一个分类器来说,使用者更希望找到全部的分类目标,即TPR越高越好,但同时也不希望把分类目标以外的其他类别错分类,即FPR越低越好。综上可知,这两个指标存在着互相制约的关系。为了可以定量的分析一个分类器的好坏,引入曲线下面积(Area Under Curve, AUC)的概念,其被定义为ROC曲线下的面积。
-
接受者操作特性(Receiver Operating Characteristic, ROC)曲线就是将不同筛选阈值下的假阳性率和查全率交点绘制在同一个坐标系内所得到的曲线。ROC曲线的横坐标为假阳性率(False Positive Rate, FPR)。纵坐标为分类查全率,又称作真阳性率(True Positive Rate, TPR)。 AUC的值越大,当前的分类算法就越有可能对正样本进行排序,然后再对负样本进行排序,从而实现更好的分类。
-
T P R = T P c T P c + F N c F P R = F P c T P c + T N c A U C = ∫ 0 1 T P R d ( F P R ) TPR=\frac{TP_c}{TP_c+FN_c}\\ FPR=\frac{FP_c}{TP_c+TN_c}\\ AUC=\int_0^1TPRd(FPR) TPR=TPc+FNcTPcFPR=TPc+TNcFPcAUC=∫01TPRd(FPR)
-
其中,𝑇𝑃𝑐 表示分类样本中真阳性(True Positive),是分类器预测正确的正样本数。𝑇𝐹𝑐表示分类样本中真阴性(True Negative),是分类器预测正确的负样本数。𝐹𝑃𝑐表示分类样本中假阳性(False Positive),是分类器预测错误的负样本数。
-
-
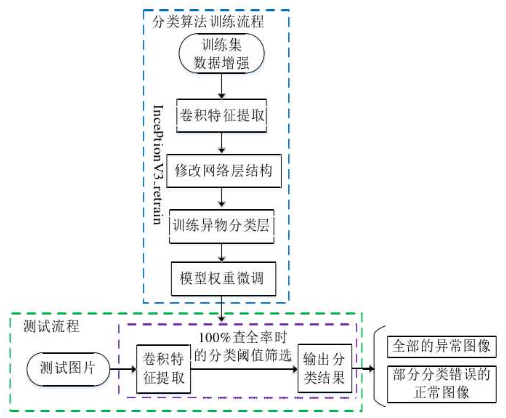
由于电力巡检任务的特殊性,输电线上异物的漏检危害比误检更大,因此本文侧重对分类器100%查全率指标的研究。本文选取InceptionV3-retrain模型作为输电线异物图像分类器的主要研究对象,其分类异物图像的总流程如下图所示。图中蓝色框的内容为算法的训练过程,本文通过训练集数据增强、修改网络结构和权重微调对模型进行训练。绿色框的内容为算法的测试流程。测试时,测试集中正常图像和异物图像共同作为分类器的输入,输出图像为全部的含有异物图像和部分分类错的正常图像。
-
在实际的巡检应用中,巡检图像承载着更为直观、丰富的巡检线路信息。红外影像和雷达成像等技术受环境影响较大,比如在停电情况下或者周围环境中存在其他电磁干扰与干扰热源时,其呈现的图像无法让工作人员直接判断现场情况,从而拖延事故处理速度。计算机视觉的核心之一是图像分类,特征描述及检测是其运用的普遍方式,对于一些简单的图像分类这类传统方法可能是有效的,但由于实际情况非常复杂,传统的分类方法不堪重负。卷积神经网络在经过大量数据训练后特征提取能力得到加强,目前主流的图像分类模型都是基于这种卷积结构。
-
输电线上异物检测作为智能电网和无人巡检系统中的重要组成部分,对于减少人力资源的浪费、提高巡线效率以及降低安全风险具有重要意义。基于深度学习的图像分类和目标检测技术在近年来取得了巨大的突破,但是该技术如何在输电线异物检测任务上进行运用仍是一个值得探索和研究的问题。
-
yolo数据集标注格式主要是 U版本[yolov5]项目需要用到。标签使用txt文本进行保存。yolo标注格式如下所示:
-
<object-class> <x> <y> <width> <height> # <object-class>:对象的标签索引 # x,y:目标的中心坐标,相对于图片的H和W做归一化。即x/W,y/H。 # width,height:目标(bbox)的宽和高,相对于图像的H和W做归一化。
-
-
VOC数据集由五个部分构成:JPEGImages,Annotations,ImageSets,SegmentationClass以及SegmentationObject.
-
JPEGImages:存放的是训练与测试的所有图片。
-
Annotations:里面存放的是每张图片打完标签所对应的XML文件。
-
ImageSets:ImageSets文件夹下本次讨论的只有Main文件夹,此文件夹中存放的主要又有四个文本文件test.txt、train.txt、trainval.txt、val.txt, 其中分别存放的是测试集图片的文件名、训练集图片的文件名、训练验证集图片的文件名、验证集图片的文件名。
-
SegmentationClass与SegmentationObject:存放的都是图片,且都是图像分割结果图,对目标检测任务来说没有用。class segmentation 标注出每一个像素的类别
-
object segmentation 标注出每一个像素属于哪一个物体。
-
-
voc数据集的标签主要以xml文件形式进行存放。xml文件的标注格式如下:
-
<annotation> <folder>17</folder> # 图片所处文件夹 <filename>77258.bmp</filename> # 图片名 <path>~/frcnn-image/61/ADAS/image/frcnn-image/17/77258.bmp</path> <source> #图片来源相关信息 <database>Unknown</database> </source> <size> #图片尺寸 <width>640</width> <height>480</height> <depth>3</depth> </size> <segmented>0</segmented> #是否有分割label <object> 包含的物体 <name>car</name> #物体类别 <pose>Unspecified</pose> #物体的姿态 <truncated>0</truncated> #物体是否被部分遮挡(>15%) <difficult>0</difficult> #是否为难以辨识的物体, 主要指要结体背景才能判断出类别的物体。虽有标注, 但一般忽略这类物体 <bndbox> #物体的bound box <xmin>2</xmin> #左 <ymin>156</ymin> #上 <xmax>111</xmax> #右 <ymax>259</ymax> #下 </bndbox> </object> </annotation>
-
-
自制VOC数据集,按照
VOC2007的数据集格式要求,分别创建文件夹VOCdevkit、VOC2007、Annotations、ImageSets、Main和JPEGImages,它们的层级结构如下所示-
└─VOCdevkit └─VOC2007 ├─Annotations ├─ImageSets │ └─Main └─JPEGImages -
其中,
Annotations用来存放xml标注文件,JPEGImages用来存放图片文件,而ImageSets/Main存放几个txt文本文件,文件的内容是训练集、验证集和测试集中图片的名称(去掉扩展名),这几个文本文件是需要人为生成的。使用开源工具 [labelImg]对图片进行标注,导出的数据集格式为PASCAL VOC,待数据标注完成后,可以看到文件夹是下面这个样子的,标注文件xml和图片文件混在了一起。将images文件夹中的图片文件拷贝到JPEGImages文件夹中,将images文件中的xml标注文件拷贝到Annotations文件夹中。 -
接下来新建一个脚本,把它放在
VOCdevkit/VOC2007文件夹下 -
import os import random # 训练集和验证集的比例分配 trainval_percent = 0.1 train_percent = 0.9 # 标注文件的路径 xmlfilepath = 'Annotations' # 生成的txt文件存放路径 txtsavepath = 'ImageSets\Main' total_xml = os.listdir(xmlfilepath) num = len(total_xml) list = range(num) tv = int(num * trainval_percent) tr = int(tv * train_percent) trainval = random.sample(list, tv) train = random.sample(trainval, tr) ftrainval = open('ImageSets/Main/trainval.txt', 'w') ftest = open('ImageSets/Main/test.txt', 'w') ftrain = open('ImageSets/Main/train.txt', 'w') fval = open('ImageSets/Main/val.txt', 'w') for i in list: name = total_xml[i][:-4] + '\n' if i in trainval: ftrainval.write(name) if i in train: ftest.write(name) else: fval.write(name) else: ftrain.write(name) ftrainval.close() ftrain.close() fval.close() ftest.close() -
将需要训练、验证、测试的图片绝对路径写到对应的
txt文件中 -
import xml.etree.ElementTree as ET import pickle import os from os import listdir, getcwd from os.path import join # 原始脚本中包含了VOC2012,这里,把它删除 # sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')] sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')] # classes也需要根据自己的实际情况修改 # classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"] classes = ["class_one"] def convert(size, box): dw = 1./size[0] dh = 1./size[1] x = (box[0] + box[1])/2.0 y = (box[2] + box[3])/2.0 w = box[1] - box[0] h = box[3] - box[2] x = x*dw w = w*dw y = y*dh h = h*dh return (x,y,w,h) def convert_annotation(year, image_id): in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id)) out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w') tree=ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): difficult = obj.find('difficult').text cls = obj.find('name').text if cls not in classes or int(difficult) == 1: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w,h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') wd = getcwd() for year, image_set in sets: if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)): os.makedirs('VOCdevkit/VOC%s/labels/'%(year)) image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split() list_file = open('%s_%s.txt'%(year, image_set), 'w') for image_id in image_ids: list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id)) convert_annotation(year, image_id) list_file.close()
-
-
执行上述脚本后,在
VOCdevkit同级目录就会生成2007_train.txt、2007_val.txt、2007_test.txt。 -
准备转换脚本
voc2yolo.py,部分注释写在代码里.(将所有图片存放在images文件夹,xml标注文件放在Annotations文件夹,然后创建一个文件夹labels) -
import xml.etree.ElementTree as ET import pickle import os from os import listdir, getcwd from os.path import join # 根据自己情况修改 classes = ["class_one"] def convert(size, box): dw = 1. / size[0] dh = 1. / size[1] x = (box[0] + box[1]) / 2.0 y = (box[2] + box[3]) / 2.0 w = box[1] - box[0] h = box[3] - box[2] x = x * dw w = w * dw y = y * dh h = h * dh return (x, y, w, h) def convert_annotation(image_id): if not os.path.exists('Annotations/%s.xml' % (image_id)): return in_file = open('annotations/%s.xml' % (image_id)) out_file = open('labels/%s.txt' % (image_id), 'w') tree = ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): cls = obj.find('name').text if cls not in classes: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w, h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') for image in os.listdir('images'): # 这里需要根据图片情况进行对应修改。比如图片名称是123.456.jpg,这里就会出错了。一般来讲,如果图片格式固定,如全都是jpg,那就image_id=image[:-4]处理就好了。总之,情况比较多,自己看着办,哈哈! image_id = image.split('.')[0] convert_annotation(image_id) -
执行上述脚本后,
labels文件夹就会生成txt格式的标注文件了,yolov5训练时使用的数据集结构是这样的 -
├─test │ ├─images │ └─labels ├─train │ ├─images │ └─labels └─valid ├─images └─labels -
因此,还需要将图片文件和对应的
txt标签文件再进行一次划分,首先创建外层的train、valid、test文件夹,然后在每个文件夹底下都分别创建images和labels文件夹.接下来,可以使用下面的脚本,将图片和标签文件按照比例进行划分 -
import os import shutil import random # 训练集、验证集和测试集的比例分配 test_percent = 0.1 valid_percent = 0.2 train_percent = 0.7 # 标注文件的路径 image_path = 'images' label_path = 'labels' images_files_list = os.listdir(image_path) labels_files_list = os.listdir(label_path) print('images files: {}'.format(images_files_list)) print('labels files: {}'.format(labels_files_list)) total_num = len(images_files_list) print('total_num: {}'.format(total_num)) test_num = int(total_num * test_percent) valid_num = int(total_num * valid_percent) train_num = int(total_num * train_percent) # 对应文件的索引 test_image_index = random.sample(range(total_num), test_num) valid_image_index = random.sample(range(total_num), valid_num) train_image_index = random.sample(range(total_num), train_num) for i in range(total_num): print('src image: {}, i={}'.format(images_files_list[i], i)) if i in test_image_index: # 将图片和标签文件拷贝到对应文件夹下 shutil.copyfile('images/{}'.format(images_files_list[i]), 'test/images/{}'.format(images_files_list[i])) shutil.copyfile('labels/{}'.format(labels_files_list[i]), 'test/labels/{}'.format(labels_files_list[i])) elif i in valid_image_index: shutil.copyfile('images/{}'.format(images_files_list[i]), 'valid/images/{}'.format(images_files_list[i])) shutil.copyfile('labels/{}'.format(labels_files_list[i]), 'valid/labels/{}'.format(labels_files_list[i])) else: shutil.copyfile('images/{}'.format(images_files_list[i]), 'train/images/{}'.format(images_files_list[i])) shutil.copyfile('labels/{}'.format(labels_files_list[i]), 'train/labels/{}'.format(labels_files_list[i])) -
执行代码后,可以看到类似文件层级结构
-
─test │ ├─images │ │ aaa.jpg │ │ bbb.jpg │ │ │ └─labels │ aaa.txt │ bbb.txt │ ├─train │ ├─images │ │ xxx.jpg │ │ │ └─labels │ xxx.txt │ └─valid ├─images │ 111.jpg │ └─labels 111.txt -
如果拿到了
txt的标注,但是需要使用VOC,也需要进行转换。看下面这个脚本,注释写在代码中 -
import os import xml.etree.ElementTree as ET from PIL import Image import numpy as np # 图片文件夹,后面的/不能省 img_path = 'images/' # txt文件夹,后面的/不能省 labels_path = 'labels/' # xml存放的文件夹,后面的/不能省 annotations_path = 'Annotations/' labels = os.listdir(labels_path) # 类别 classes = ["class_one"] # 图片的高度、宽度、深度 sh = sw = sd = 0 def write_xml(imgname, sw, sh, sd, filepath, labeldicts): ''' imgname: 没有扩展名的图片名称 ''' # 创建Annotation根节点 root = ET.Element('Annotation') # 创建filename子节点,无扩展名 ET.SubElement(root, 'filename').text = str(imgname) # 创建size子节点 sizes = ET.SubElement(root,'size') ET.SubElement(sizes, 'width').text = str(sw) ET.SubElement(sizes, 'height').text = str(sh) ET.SubElement(sizes, 'depth').text = str(sd) for labeldict in labeldicts: objects = ET.SubElement(root, 'object') ET.SubElement(objects, 'name').text = labeldict['name'] ET.SubElement(objects, 'pose').text = 'Unspecified' ET.SubElement(objects, 'truncated').text = '0' ET.SubElement(objects, 'difficult').text = '0' bndbox = ET.SubElement(objects,'bndbox') ET.SubElement(bndbox, 'xmin').text = str(int(labeldict['xmin'])) ET.SubElement(bndbox, 'ymin').text = str(int(labeldict['ymin'])) ET.SubElement(bndbox, 'xmax').text = str(int(labeldict['xmax'])) ET.SubElement(bndbox, 'ymax').text = str(int(labeldict['ymax'])) tree = ET.ElementTree(root) tree.write(filepath, encoding='utf-8') for label in labels: with open(labels_path + label, 'r') as f: img_id = os.path.splitext(label)[0] contents = f.readlines() labeldicts = [] for content in contents: # 这里要看图片格式了,这里是jpg,注意修改 img = np.array(Image.open(img_path + label.strip('.txt') + '.jpg')) # 图片的高度和宽度 sh, sw, sd = img.shape[0], img.shape[1], img.shape[2] content = content.strip('\n').split() x = float(content[1])*sw y = float(content[2])*sh w = float(content[3])*sw h = float(content[4])*sh # 坐标的转换,x_center y_center width height -> xmin ymin xmax ymax new_dict = {'name': classes[int(content[0])], 'difficult': '0', 'xmin': x+1-w/2, 'ymin': y+1-h/2, 'xmax': x+1+w/2, 'ymax': y+1+h/2 } labeldicts.append(new_dict) write_xml(img_id, sw, sh, sd, annotations_path + label.strip('.txt') + '.xml', labeldicts)
【电网异物检测硕士论文摘抄记录】电力巡检图像中基于深度学习的异物检测方法研究
news2026/2/11 10:34:57
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/802109.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
Linux内存文件系统tmpfs的使用方法
1、tmpfs理论
默认的Linux发行版中的内核配置都会开启tmpfs,映射到了/dev/下的shm目录。可以通过df 命令查看结果. /dev/shm/是linux下一个非常有用的目录,因为这个目录不在硬盘上,而是在内存里。因此在linux下,就不需要大费周折…
python的web学习(一)-初识django
文章目录 软件创建项目默认项目文件说明App的概念(应用)apps.py编写URL和视图函数对应关系【urls.py】编写视图函数【views.py】启动服务 软件
python下载 django下载
创建项目
django-admin startproject 文件名默认项目文件说明
项目名 manage.py(项目管理,启…

打造完美直播体验:美颜技术与美型SDK的融合
随着直播行业的蓬勃发展,主播们对于直播体验的要求也日益提高。其中,美颜技术和美型SDK的融合为主播们带来了前所未有的完美直播体验。本文将深入探讨美颜技术和美型SDK的原理与应用,以及这两者如何协同工作,为直播行业带来更具吸…
记录egg官方初始化项目失败解决方案
快速初始化
我们推荐直接使用脚手架,只需几条简单指令,即可快速生成项目(npm >6.1.0):
$ mkdir egg-example && cd egg-example
$ npm init egg --typesimple
$ npm i
但是在某些情况下,会安装失败&…
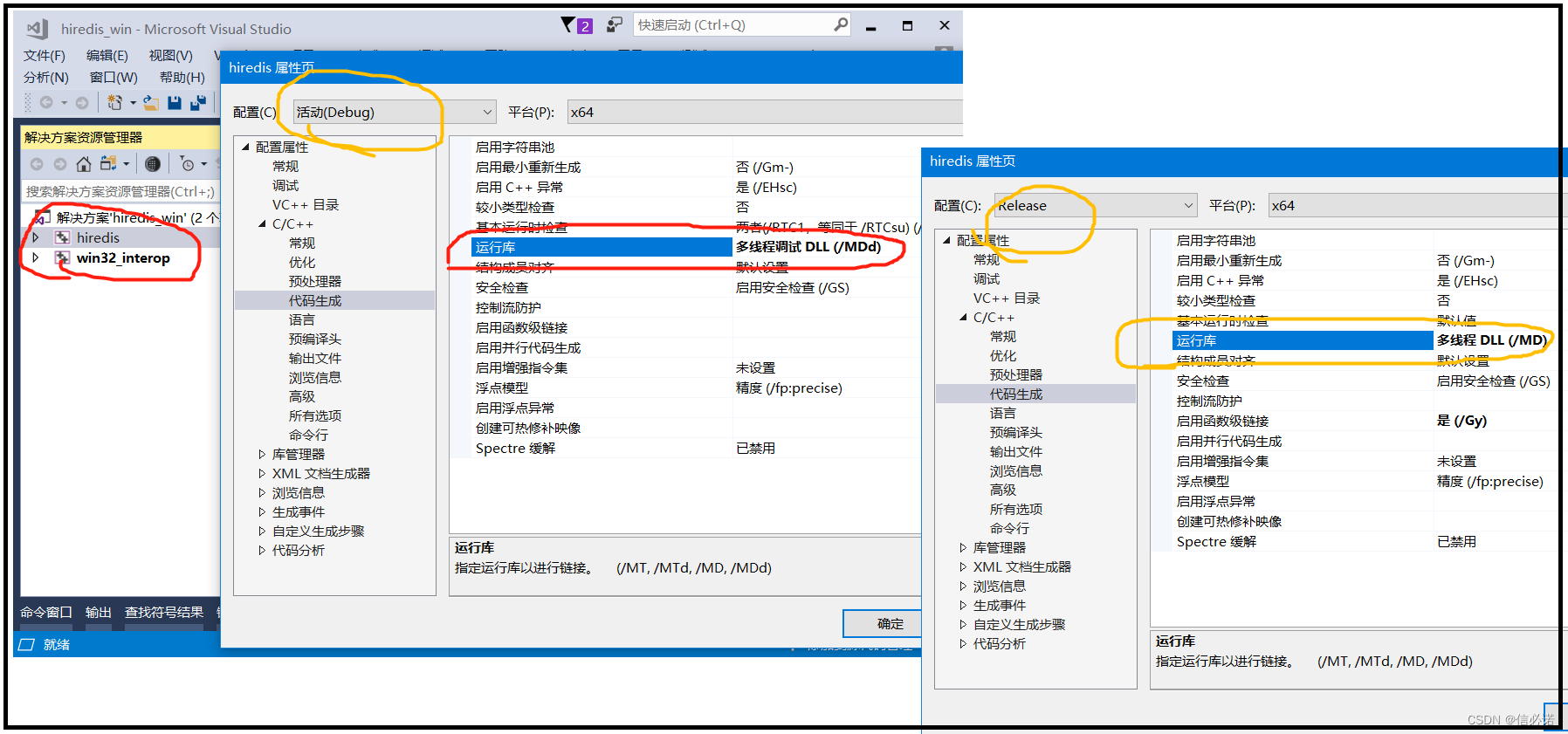
Qt —— Vs2017编译hiredis源码并测试调用(附调用hiredis库源码)
下载hiredis源码 编译hiredis源码 1、解压下载的hiredis源码包,如图使用Vs2017打开hiredis_win.sln 2、如下两图,Vs2017打开.sln后点击升级。 分别对两个工程的debug、release进行配置。Debug配置为多线程调试DLL(MDd)、Release配置为多线程DLL(/MD),这样做是为了配合被调用…

Android开发:通过Tesseract第三方库实现OCR
一、引言 什么是OCR?OCR(Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。简单地说&#…
YAML+PyYAML笔记 6 | PyYAML源码之yaml.scan(),yaml.parse(),yaml.compose()
6 | PyYAML源码之yaml.scan,yaml.parse, yaml.compose 0 yaml文档1 yaml.scan()2 yaml.parse()3 yaml.compose() 0 yaml文档
以下示例来源于网络,便于后续学习用, 文档为config_yaml.yaml。
{name: John Doe,age: 28,hobbies: [hiking, cooking, fishi…

生信分析案例 Python简明教程 | 视频15
开源生信 Python教程 生信专用简明 Python 文字和视频教程 源码在:https://github.com/Tong-Chen/Bioinfo_course_python 目录 背景介绍 编程开篇为什么学习Python如何安装Python如何运行Python命令和脚本使用什么编辑器写Python脚本Python程序事例Python基本语法 数…

怎样修改LED显示屏的显示内容
每个LED显示屏通常都附带配套的控制卡和相应的管理软件。安装完LED显示屏后,只需连接控制卡和电源,并通过运行管理软件,便能轻松地更换LED显示屏的显示内容。 更改LED显示屏内容非常便捷,我们可以使用电脑、手机或者U盘等设备进行…

html实现蜂窝菜单
效果图 CSS样式
keyframes _fade-in_mkmxd_1 {0% {filter: blur(20px);opacity: 0}to {filter: none;opacity: 1}
}
keyframes _drop-in_mkmxd_1 {0% {transform: var(--transform) translateY(-100px) translateZ(400px)}to {transform: var(--transform)}
}
._examples_mkmx…

layui各种事件无效(例如表格重载或 分页插件按钮失效)的解决方法
下图是我一个系统的操作日志,在分页插件右下角嵌入了一个导出所有数据的按钮 ,代码没有任何问题,点击导出按钮却失效 排查之后,发现表格标签table定义了ID又定义了lay-filter,因我使用的layui从2.7.6升级到2.8.11&…
JMeter接口测试:BeanShell实现接口的加密和解密
前些天用JMeter写了一个接口的自动化脚本,请求参数加密和响应数据解密都覆盖到了,中间涉及了BeanShell脚本编写和导入jar包的一些方法,想着挺有代表性的,分享给大家,希望对大家的接口自动化测试有所启发。 这是一个注册…

简化Java单元测试数据
用EasyModeling简化Java单元测试
EasyModeling 是我在2021年圣诞假期期间开发的一个 Java 注解处理器,采用 Apache-2.0 开源协议。它可以帮助 Java 单元测试的编写者快速构造用于测试的数据模型实例,简化 Java 项目在单元测试中准备测试数据的工作&…

半路杀出个“程咬金”,谁在吹响智能化供应链重构号角
汽车智能化的竞争,不再是平行模式(车企与车企、Tier1与Tier1),也不再是一边倒的车企自研模式,更不是纯粹的B2C模式。 随着昨天大众集团对外官宣与小鹏、上汽的深度合作启动,围绕电动化、智能化的竞争无疑进…

PHP注册、登陆、6套主页-带Thinkphp目录解析-【白嫖项目】
强撸项目系列总目录在000集
PHP要怎么学–【思维导图知识范围】 文章目录 本系列校训本项目使用技术 上效果图主页注册,登陆 phpStudy 设置导数据库项目目录如图:代码部分:控制器前台的首页 其它配套页面展示直接给第二套方案的页面吧第三套…

Talk | 南洋理工大学博士后研究员李祥泰:基于Transformer的视觉分割模型总结、回顾与展望
本期为TechBeat人工智能社区第517期线上Talk! 北京时间7月27日(周四)20:00,南洋理工大学博士后研究员—李祥泰的Talk已经准时在TechBeat人工智能社区开播了! 他与大家分享的主题是: “基于Transformer的视觉分割模型总结、回顾与展望”&am…

无涯教程-jQuery - animate()方法函数
animate()方法执行一组CSS属性的自定义动画。
animate( params, [duration, easing, callback] ) - 语法
selector.animate( params, [duration, easing, callback] );
这是此方法使用的所有参数的说明
params - 动画将朝其移动的CSS属性图。duration - 这是可选…
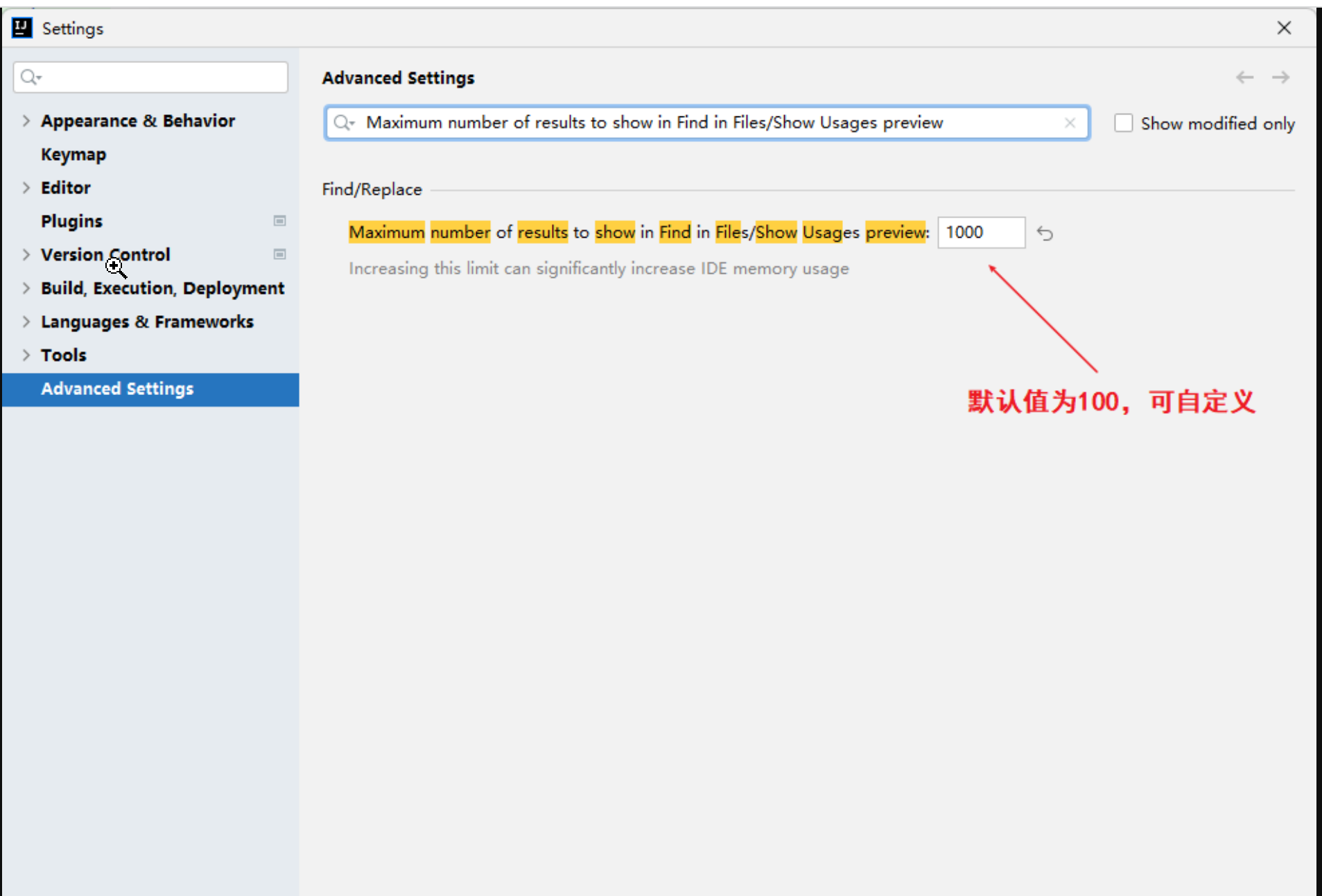
idea常用技巧/idea常见问题
idea常见问题
idea全局搜索默认只显示100条解决方案 如上图,每次搜索时只显示100条,没法展示全。因版本的不同,配置也有些差异,以下也是经过各种搜索整理出了两个方案来解决这个问题。
方案一: 快捷键Ctrl shift a…
windows环境启动redis-server.exe出现闪退问题解决方案(亲测有效)
现象
windows环境下,启动redis-server.exe,出现闪退现象
解决方案
在你的redis解压目录下,新建一个start.bat文件 在start.bat文件里面写上这一句话:
redis-server.exe redis.windows.conf然后保存,后面启动redis…

网络安全/信息安全—学习笔记
一、网络安全是什么
网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。
无论网络、Web、移动、桌面、云等哪个领域,都有攻与防两面…