目录
- 前言
- 什么是语雀
- 富文本编辑器的发展历程
- 语雀结构简析
- 语雀核心
- 语雀渲染器
- 语雀前端技术
- 业务层
- 编辑器
- 语雀编辑器演化过程
- 语雀研发流程
- 关于语雀的讨论
- 为何文档编写不是一种标准化的中台能力
- 内容类产品典型类别
- 业务所需编辑器开发成本如何?
- 文本编辑器
- 代码编辑器
- 公式编辑器
- 表格编辑器
- 脑图编辑器
- 编辑器框架
- 语雀编辑器现状
- 内容生产型产品
- 内容聚合/消费型产品
- 参考
前言
本人有一段时间花了不少时间打磨自己的知识库系统,这个系统融知识采集、知识分类、知识搜索、知识导出成PDF/PPT,知识自动发布于一体。对web编辑器心有惴惴,结合网上资料,分享一下语雀的研发体验。
什么是语雀
语雀是阿里内部孵化出的知识库管理平台,目前已对外开放。用过的人都赞不绝口。虽然目前有腾讯文档、google文档、石墨文档等一大众优秀的在线文档平台,但语雀仍然算得上是一股清流。
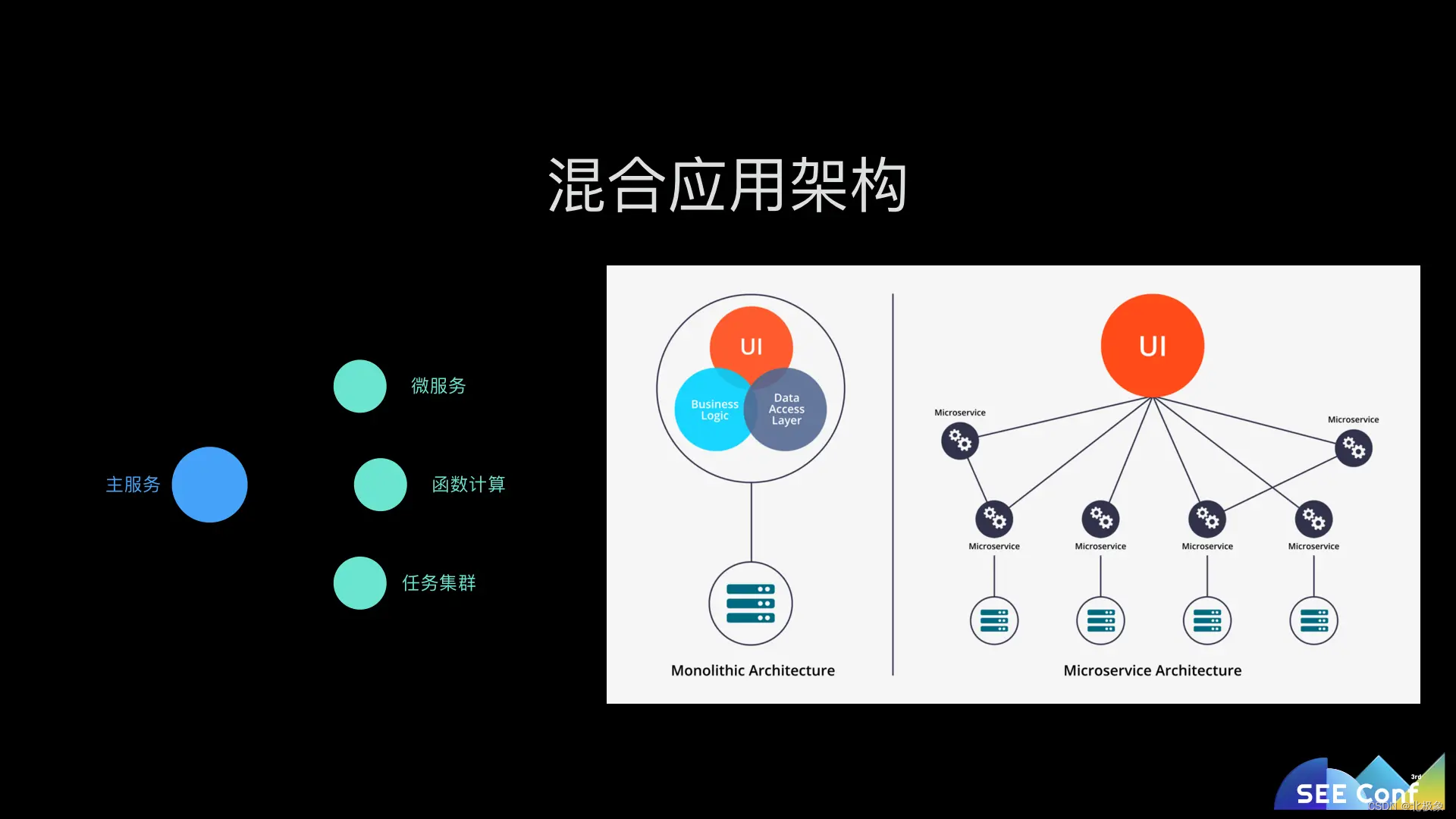
虽然语雀用户体量现在还不是很庞大,但是作为一个知识管理平台,它背后的复杂度也已经相当高了。本文将会从整体上介绍一下语雀的前后端都采用了哪些技术和框架来帮助研发的。由于语雀现在团队还比较精简,因此 Monolithic而不是Microservice的架构在当前阶段更适合语雀。而慢慢发展出来的一些独立于语雀核心逻辑的功能我们也会采用 Microservice 的形式发布,所以语雀是一个大的 Monolithic 服务加一些小的 microservice 服务组成的应用。
在阿里内部,JavaScript(Node.js)在服务端使用最多的场景依然主要还是集中在渲染层和 BFF 层,在复杂的 Web 服务端领域很少有实践和分享。
富文本编辑器的发展历程
编辑器目前可以分为以下三类:
- textArea 远古时代的编辑器实现,起始阶段,最简单的如多行文本
- contentEditable 浏览器提供了基础功能:
- draftjs (react)
- quilljs (vue)
- prosemirror(util)
- 脱离浏览器自带编辑能力,独立做光标和排版引擎:ffice 、wps、 google doc
其中第一类不支持图片及视频等其它内容,第三类可能是一项浩大的工程,目前活跃的开源代码框架大多属于第二类。
语雀结构简析
主体架构组成:
- Yuque Core:语雀核心服务,使用 Chair 编写的全栈应用,实现语雀的核心业务逻辑,包含前端和服务端代码。
- Yuque Render:Chair 编写的渲染 plantuml、latex、PDF、word 的服务,与语雀核心逻辑解耦。
- Yuque Job:处理语雀小站打包的任务,基于 Techless Function 的异步任务服务。
- Yuque Site:语雀小站服务,使用 Chair 编写,托管打包后的语雀小站站点。
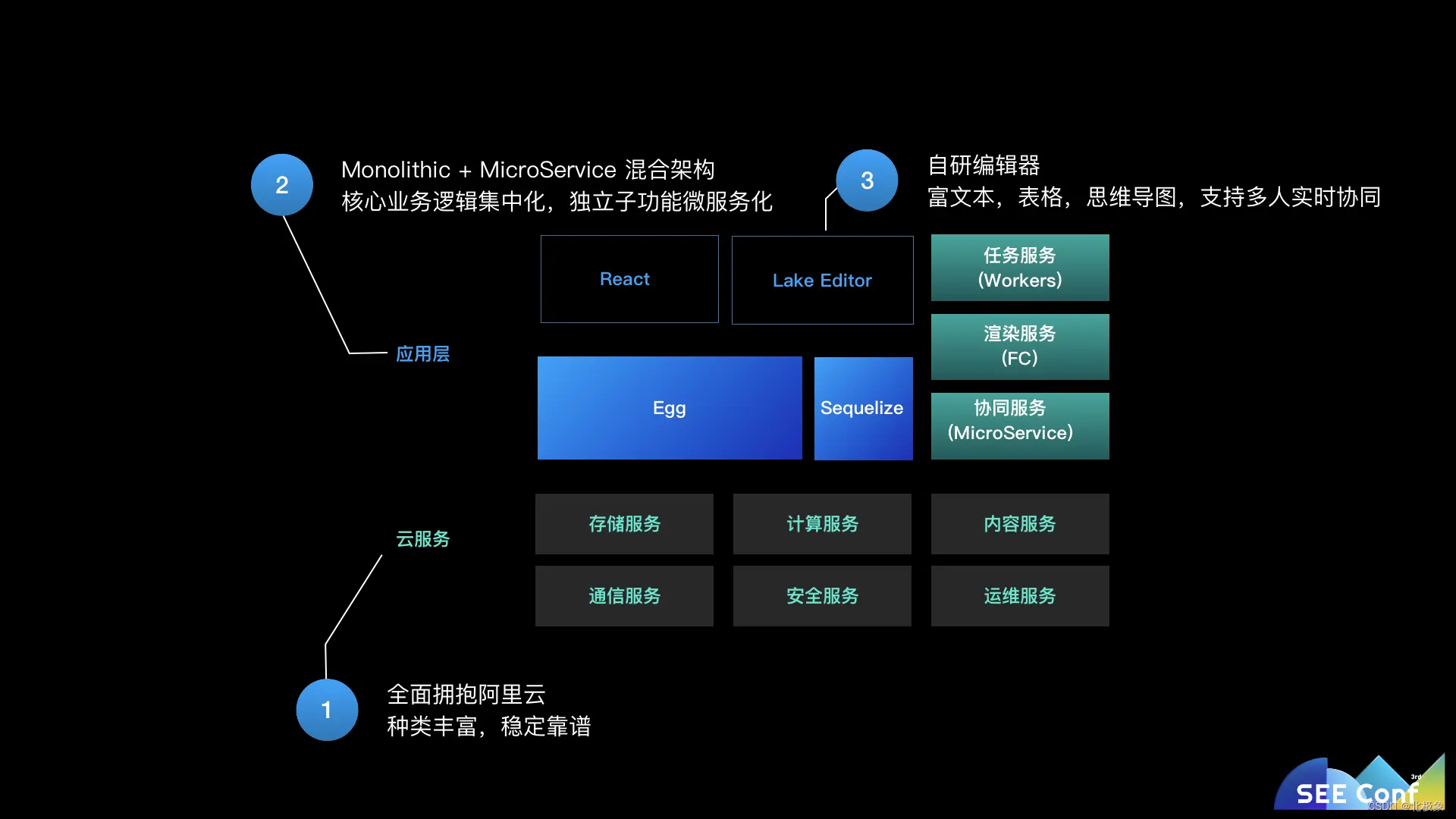
在应用层,语雀的服务端依然还是以一个基于 Egg 框架的大型的 Node.js web 应用为主。但是随着功能越来越多,也开始将一些相对比较独立的服务从主服务中拆出去,可以把这些服务分成几类:
- 微服务类:例如多人实时协同服务,由于它相对独立,且长连接服务不适合频繁发布,所以我们将其拆成了一个独立的微服务,保持其稳定性;
- 任务服务类:像语雀提供的大量本地文件预览服务,会产生一些任务比较消耗资源、依赖复杂。我们将其从主服务中剥离,可以避免不可控的依赖和资源消耗对主服务造成影响;
- 函数计算类:类似 plantuml 预览、mermaid 预览等任务,对响应时间的敏感度不高,且依赖可以打包到阿里云函数计算中,我们会将其放到函数计算中运行,既省钱又安全;
数据模型层即是数据层的 Model,以 Doc 模型举例,它的 meta 信息数据被存储在了 MySQL 中,而文档正文数据被加密后存储在 OSS 中。对于语雀核心的业务逻辑来说,完全不感知底层的存储在哪里。更进一步来说,只要语雀是使用 SQL 和数据库进行交互,底层数据可以无缝迁移到 OceanBase 等其他支持完整 SQL 语法的数据库中,即使有少量修改也可以在 Model 层封装掉。
随着编辑器越来越复杂,在 slate 的基础上进行开发遇到的问题越来越多。最终语雀还是走上了自研编辑器的道路,基于浏览器的 contenteditable 实现了富文本编辑器,通过 canvas 实现了表格编辑器,通过 SVG 实现了思维导图编辑器。
语雀核心
语雀核心应用的服务端是一个典型的 Chair 全栈应用,通过 Chair 和一些 Egg 官方提供的插件完成研发。除了 Chair 之外,还有一些比较重要的插件可以帮助我们开发一个全栈应用。
- egg-sequelize: 提供 ORM 的支持,通过 Migration 管理研发时的数据结构变更,通过 factory-girl 模块完成测试数据生成,可以阅读此篇文档来进一步了解使用 sequelize ORM 的实践经验。
- egg-cancan: 提供了一个类似 ruby cancancan 的权限校验,可以简洁的实现针对用户 + 实体 + 操作的权限校验。
- egg-validate: 提供声明式的参数校验和数据预处理。
- egg-ons: 对接阿里云的 MQ 队列服务。
语雀渲染器
这个服务用来提供 plantuml、公式的渲染(代码 => 图片),文档和知识库的导出(word 和 PDF),由于函数计算暂时还无法实现这么复杂的需求,暂时也基于 Chair 研发,部署成一个独立服务。
- node-plantuml: 通过调用 java 进程,将 plantuml 代码生成为图片,常驻 java 进程实现,平均生成时间在几百毫秒。
- MathJax: 通过在 Node.js 运行环境中模拟浏览器 API,生成 SVG 图片,平均生成时间在几十毫秒。
- puppeteer: 渲染文档 HTML 生成 PDF。服务稳定但是暂时不支持生成 PDF 的 TOC。
- officegen: 生成 word 文档。语雀的实现是解析语雀的文档格式使用 officegen 生成 word 文档。
- sharp: 实现 svg -> png 的转换(由于 word 中无法插入 svg 图片)。
语雀前端技术
语雀应用的前端初略可以分为两个部分:业务层和编辑器,两者虽然紧密结合,但是又在一定程度上互相独立。
业务层
语雀的业务层使用 React + Ant Design + dva 进行研发,bigfish 进行构建。
编辑器
编辑器是语雀最核心的功能,同时,富文本编辑器技术也是前端最复杂的领域之一,在这个领域中的编辑器基本可以分为 L0 到 L2 三个级别,从 L0 到 L2,自由度越来越高,研发难度也越来越大:
L0:全面依赖浏览器特性,直接使用浏览器自带的输入框(designMode、contenteditable、webkit-user-modify),直接使用浏览器自带的 execCommand 执行操作之后做一些简单的 DOM 修复。
L1:直接使用浏览器自带的输入框,大部分执行操作通过 Seletion、Range、Element、TextNode 等 DOM API 自主实现。
L2:终极方案,自主实现输入框,包括光标、输入文本、删除文本等基础编辑功能。
更多的业界方案对比可以阅读《富文本技术方案调研》。
语雀编辑器演化过程
经过了三个大版本的迭代:
1.0:基于 codemirror 包装的 Markdown 编辑器。
2.0:以 slate 为底层二次开发,基于 Contenteditable 的 React 技术栈的富文本编辑器。(L1)
3.0:基于 Contenteditable 自研的原生 JavaScript 技术栈的富文本编辑器 LakeEditor。(L1)
1.0 到 2.0 的升级是从 Markdown 时代到富文本编辑器时代的跨越,2.0 到 3.0 的升级我们摆脱了 React 技术栈的束缚,性能和可定制性上得到了大幅提升。
语雀研发流程
在语雀,产品工程师们的产品研发流程是这样的:
在产品设计阶段,产品工程师就会参与进去进行讨论,最终会产出一份 final design 的产品设计稿。由于前期产品工程师参与充分讨论,一般此处定下的产品设计稿到后期的研发过程中不会遇到技术上的问题;
随后会在语雀上进行文档化的系统分析设计。会在语雀上发起异步的评审。一些大的技术方案会有其他的领域专家加入进来一起进行评审,确保将所有的技术难点都梳理清楚;
系统设计清晰后,进入研发阶段;
对所有的代码,都需要有自动化测试覆盖。对所有新增代码和修改的业务逻辑都需要有完全覆盖的单元测试,对关键链路的功能同时也要提供端到端测试。编写完自动化测试是进入代码评审前的必备流程。
阶段性的功能研发完成、测试编写完善后会发起异步的代码评审。会邀请相关业务的负责人和对应的一些领域专家来进行代码评审。从业务逻辑的正确性,安全性,可维护性等多个角度来进行代码评审。
最终在发布上线时,必须遵循三板斧原则:可灰度、可应急、可监控。避免功能变更可能带来的 bug 影响到大量用户。
语雀做的第一件事情就是确定核心系统和外部系统的边界。通过六边形架构(也叫做端口适配器架构),我们把语雀核心系统和外界系统和用户之间的交互固定下来。通过“端口”的形式,来确定输入和输出。外部系统通过“适配器”来将系统对接到语雀暴露的端口之上,只需要按照“端口”定义来实现,外部系统可以自由替换。
最终以一次文档发布举例,用户通过调用 HTTP 接口与语雀进行交互,数据会通过 Model 层写入到存储中,包括 MySQL 和 OSS,更新文档缓存。同时出发异步消息给其他系统,触发钉钉的 WebHook,并将数据同步到搜索引擎中。这些和外界系统的交互通过适配器封装之后各司其职,参数转换、权限校验、日志记录,不仅确保核心逻辑的精简,也让系统调用链路跟踪更加简单。
语雀这几年一步步发展过来,背后的技术一直在演进,但是始终遵循了几条原则:
- 技术栈选型要匹配产品发展阶段。产品在不同的阶段对技术提出的要求是不一样的,越前期,对迭代效率的要求越高,商业化规模化之后,对稳定性、性能的要求就会变高。不需要一上来就用最先进的技术方案,而是需要和产品阶段一起考虑和权衡。
- 技术栈选型要结合团队成员的技术背景。语雀选择 JavaScript 全栈的原因是孵化语雀的团队,大部分都是 JavaScript 背景的程序员,同时 Node.js 在蚂蚁也算是一等公民,配套的设施相对完善。
- 最重要的一点是,不论选择什么技术栈,安全、稳定、可维护(扩展)都是要考虑清楚的。用什么语言、用什么服务会变化,但是这些基础的安全意识、稳定性意识,如何编写可维护的代码,都是决定项目能否长期发展下去的重要因素。
关于语雀的讨论
随着语雀被越来越多的团队所使用, 语雀的两大核心能力:文本编辑 & 浏览、结构化知识组织和管理逐步被大家所接受。于是,很多有内容编辑需求的业务很自然地就会想到:
语雀编辑器非常好用,可以独立出来作为一个通用编辑器,集成到我们的产品中。
语雀应该承担起集团内文档基础能力的角色,有文档的地方就有应该有语雀的全力支持,为其它业务提供文档编辑、版本管理等能力
这两个声音背后的诉求是:希望语雀扮演大中台的角色,将能力标准化输出以支撑业务。其实语雀并不是一个中台服务,我们是阿里“大中台、小前台”模式下的一个面向最终用户的前台产品,我们希望为每个想表达所思所想的人提供一款顺手的工具,让知识得以记录和分享 。接下来将从内容类业务的维度来分析。
为何文档编写不是一种标准化的中台能力
业务中有文档相关诉求该如何处理,为何「文档编写」不是中台能力
要回答这个问题,首先得从「文档编写」的应用领域「内容类产品」的典型类别入手进行分析。
内容类产品典型类别
张小龙有一条重要的产品设计原则「设计就是分类」,美团的王慧文在 为什么美团总是看起来四处受敌 中针对互联网产品进行的分类很好地诠释了这个观点。不难发现,不同类别的产品会导致不同的打法、使用不同的技术。内容类业务的范围非常广,背后是一个行业,我们先从 生产-> 消费 的角度尝试对着这个行业的产品进行下归类:
-
内容生产型产品:编写内容是产品根本,所有的其它功能都是围绕产出的内容进行的,内容编创作和阅读体验是产品的核心能力,部分产品会基于内容打造生态或者社区,媒体网站、Google Docs、Wiki、Medium、知乎、公众号算是典型产品。
-
内容聚合类产品:连接和分发是产品的根本,将不同渠道的内容聚合在一起,进行加工和二次处理,形成一个内容平台,提供给浏览者。今日头条、搜索引擎是典型代表。
就前者而言,每个产品的用户、使用场景、交互方式、内容形态都有差异。
并不存在通用编辑器
「文档编写」看似简单,无非是文本、格式、图片、表格的处理,似乎很容易做成一个标准化的中台能力。然而,「文档编写」背后是一种内容生成能力,在抽象度上和「编程」、「机器制造」是一样的。不存在一个能开发出任何程序的万能程序员,也不存在一款能生产任何机器的万能生产线,所以也不存在一种能编写任何文档的通用编辑器,前台产品的的文档需求并不是某个文档中台所能解决的。
内容的格式决定了如何编写和呈现,不同的内容有不同的编写方式,电子表格、Office 文档、LaTeX 文档、Markdown 、博客文档、Wiki、知乎问答、脑图等等都是不同的内容形态,不难发现每种类别的文档通常就会有一个专属编辑器,同一类别的文档由于内容应用场景的差异也会导致需要不同的编辑器。所以,并不存在一款能涵盖所有场景的万能编辑器,「文档编写」并非一个可标准化输出的中台能力,能复用的就只是开发编辑器所属的技术。
或许你会说:既然这么多业务都需要用到编辑器,阿里内部应该造一个编辑器开发框架来支撑内部业务。其实造这个轮子的必要性不大,原因在于:
也会已有有很多优秀成果,每个都经过数十年的打磨,远非短期能做出精品
自研成本非常高,编辑器背后往往有复杂的交互细节、兼容性处理、性能处理,需要足够的时间、经验和场景验证才能保证质量和稳定性
国内也有基于浏览器原生接口研制编辑器的 CASE:百度 - UEditor 、淘宝 - Kissy Editor ,UEditor 曾经被广泛使用,但因种种原因这两款均未坚持下去,现已停止维护。这个领域从最底层开始构建的成本远远大于自研一个 UI 库、开发框架,因而除非这是产品战略级核心竞争力、而且现有的编辑器框架不能满足需求、团队原因持续投入研发资源,否则不建议从最底层开始构建。
业务所需编辑器开发成本如何?
很多 PD、研发会认为实现成本非常高,不是普通工程师所能搞定的,其实并非如此。业界有很多内容生产型产品:简书、头条、36氪、天涯、知乎、豆瓣、幕布、一起写、石墨等,编辑器是他们绕不开的技术。反向思考下就会发现真相:如果实现编辑器是非常难的一件事,就不会有这么多做内容的产品,内容生态也不至于蓬勃发展,所以实现业务所需的编辑器并不难。
造成这个误解的原因可能是:
阿里的产品以电商、企业级服务为主,内容类产品较少,业务场景导致了这方面研发经验较少
近几年前端领域的关注点多在 H5、React/VUE、工程化等维度,导致这项专项技术的介绍和实践经验分享比较少,让这个原本比较普遍的技术变得神秘起来。
其实编辑器技术虽然有一定的技术门槛,但在业界已发展多年,已经是成熟技术了,也产生了很多优秀的编辑器,它们通常都支持可定制、可扩展,代表性的有:
文本编辑器
-
CKEditor4 The battle-tested WYSIWYG HTML editor, when you need even more features and legacy compatibility.
-
TinyMCE The world’s most popular JavaScript library for rich text editing.
-
Quill Your powerful, rich text editor.
代码编辑器
-
ACE Editor Ace is an embeddable code editor written in JavaScript. It matches the features and performance of native editors such as Sublime, Vim and TextMate.
-
CodeMirror It is specialized for editing code, and comes with over 100 language modes and various addons that implement more advanced editing functionality.
公式编辑器
- MathQuill MathQuill is a web formula editor designed to make typing math easy and beautiful.
- MathJax MathJax is an open-source JavaScript display engine for LaTeX, MathML, and AsciiMath notation that works in all modern browsers.
表格编辑器
- Handsontable JavaScript Spreadsheet, Most popular component for Enterprises
- SpreadJS 基于HTML5的JavaScript电子表格和网格功能控件,适用于.NET、Java和移动端等各平台在线编辑类Excel功能的表格程序开发
脑图编辑器
- kityminder-editor 强大、简洁、体验优秀的脑图编辑工具,适合用于编辑树/图/网等结构的数据。
编辑器框架
经过多年的技术积累,再加上浏览器对可视化编辑支持的持续优化,也产生了不少专门用于开发自定义编辑器的优秀框架,典型代表:
-
Draft.js Draft.js is a framework for building rich text editors in React, powered by an immutable model and abstracting over cross-browser differences.
-
Slate.js A completely customizable framework for building rich text editors.
-
CKEdiror5 A set of components enabling you to create any kind of text editing solution.
-
ProseMirror A toolkit for building rich-text editors on the web.
实现一个编辑器虽然比实现一个普通 Web 页面复杂点,但基于已有成果,其难度绝对不至于难到一般工程师都搞不定。现有的这些编辑器及其开发框架使得打造一个业务专属的编辑器的成本已经非常低了,内容类产品通常会采用这几种方式来实现自己的编辑器:
-
低成本-基于现有的进行配置和扩展:Wordpress、淘宝论坛就采用了 TinyMCE
-
中等成本-基于框架进行开基于这些编辑器开发框架:语雀、阿里邮箱、阿里笔记采用了这种
-
高成本-全自主研发编辑器:Google Docs 是典型代表,也是业界最好的 Web 编辑器
语雀编辑器现状
语雀的可视化编辑器是基于 Slate.js 实现的,Markdown 编辑器是在 CodeMirror 上扩展和配置出来的。目前勉强能满足写点简单文档,但在兼容性、性能、功能丰富度上离 TinyMCE、CKEditor 还有非常大的差距。内容创作是语雀的生命线,我们正在探索一种全新的内容生产方式,这导致目前并没有定义出一种标准格式,再加上未来会引入动态内容的特性(比如:TODO、内容片段引用),使得语雀的编辑器和业务耦合非常紧密,基本上不可能独立出来。
内容生产型产品
内容生产是核心能力,平台的价值在于打通内容从“生产 -> 消费“整个链接,内容生成是其地点,没有内容平台的后续流程和其它功能就玩不转。
开放平台、阿里笔记、法务中台是典型代表,这类产品核心数据就是内容,是产品的命脉,在本质上和语雀一样,属于内容生产在不同领域的垂直产品,在业界甚至都有专门的服务来支持,比如:法天使 、EoLinker - API管理平台 。短期看语雀的编辑器可能会解燃眉之急,但长远来看由于最终产生的内容带有不同业务属性,导致内容编写方式、组织方式、呈现方式、流转方式、权限控制等都会有很大差异,不是语雀所能支持的。
拿「交通工作制造」来类比,语雀就是一个造自行车的,而这些垂直类产品想造的是汽车、火车、飞机,不是一个造自行车的所能搞定的。如果非要一起合作,会阻碍各自的发展,因为:短期可能会快速出个东西,但长远发展下去双方的业务对接成本远大于单独实现编辑器成本。针对这种场景,我们更推荐的做法是:
业务在一开始设计时就考虑打造专属的编辑器解决方案
如果只想要一款拿来即用的可视化编辑器,可以考虑:TinyMCE、CKEditor,推荐 TinyMCE,因为的确是使用最广泛的,淘宝论坛 、阿里邮箱 开源协议对商业产品比较友好
如果有非常多的定制化编辑需求,可以考虑基于前边介绍的编辑器开发框架来实现,我们推荐 Slate.js ,语雀的编辑器就是基于它实现的
语雀不会提供源码和业务上的支持,但可以分享和交流编辑器研发的经验,协助解决实现过程中的一些疑难问题
或许你会说 Word 不就是一个通用编辑器吗?CKEditor、Google Docs、TinyMCE 也能提供云服务来支持第三方业务来使用其能力,为何语雀不提供这种能力?这几类编辑器的背后都有一套固定的文档格式和编辑方式,内容也是静态的,所以可以做到这点。而语雀的内容是动态的,目前并没有固定的格式,所以提供不了这样的服务。
内容聚合/消费型产品
内容并不是核心能力,并不太关心内容是怎么生产出来的,内容编写在产品中的比重很小,产品核心在于挖掘现有内容的价值,将之关联到自身产品中解决内容消费诉求。
Aone、阿里云知识库、NOMO 算是典型代表,这类系统的核心能力不是文档生产,只不过在某些环节需要用到文档,我们推荐的做法是:
如果仅是需要把某些仓库的内容集成到语雀,可以通过 iframe 嵌入语雀阅读页的方式,如果要追求体验,可以考虑通过 API 获取仓库的内容集成在自己的系统中
如果需要把语雀的产生的内容纳入自身系统作为内容容,可通过 API 获取数据进行利用,阿里云知识库、阿里内外搜索就采用了这种方式
如果系统希望把语雀文档关联到自身的用户操作流程中,形成一个相对完整的链路,可采用关联模式,Aone 中的文档就是这样实现的。
参考
- 语雀编辑器的自研之路
- 富文本编辑器调研
- 语雀,即将开源!
![[附源码]Python计算机毕业设计SSM基于的网上拍卖系统(程序+LW)](https://img-blog.csdnimg.cn/0ee59d788c454c79a3a2927a90e68a97.png)