通常我们说redis是单线程指的是从接收客户端请求->解析请求->读写->响应客户端这整个过程是由一个线程来完成的。这并不意味着redis在任何场景、任何版本下都只有一个线程
为何用单线程处理数据读写?
内存数据储存已经很快了

redis相比于mysql等数据库是将数据储存到内存中的,那么即使相比于SSD也有1000倍的差距
因此io在当前并不能成为主要瓶颈
优化的数据结构让它更快

redis有效利用了底层数据结构来保证数据储存的高效,很多时候读写数据时间复杂度仅仅只有O(1)、O(N)或者O(log(N)),相当的快
单线程减少额外损耗
采用单线程架构
- 最小化减少因为线程创建销毁产生的cpu消耗
- 最小化减少线程切换产生的cpu消耗
- 减少多线程下锁产生的性能损耗
- 能够使用各种线程不安全的命令,如Lpush
为什么6.0之后引入多线程?
随着硬件能力提升,单线程已经无法匹配网络读写速度了
为此redis采用了多线程来更好地处理网络请求
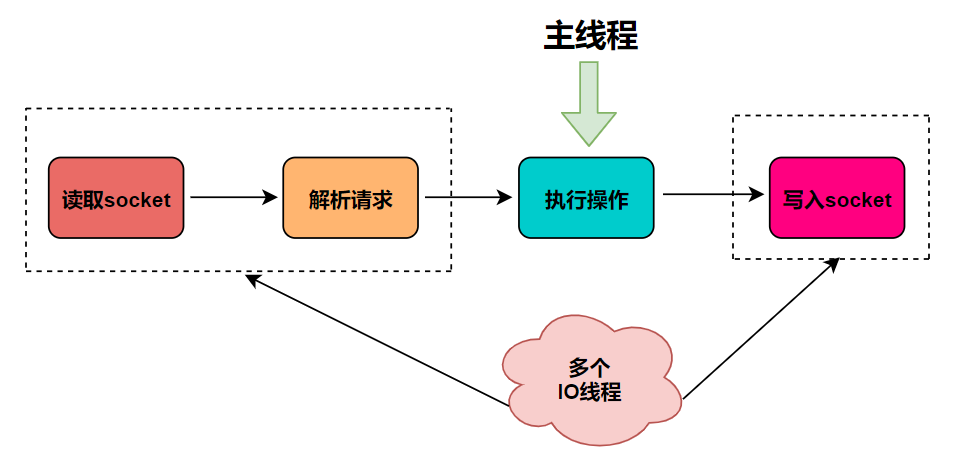
主要流程如下
- 主线程负责接收建立连接请求,获取socket放入等待队列中
- 主线程轮询等待队列socket,并分配给网络io线程
- io线程读取socket并解析
- 主线程执行redis命令
- io线程将执行结果写回socket
- 主线程清空等待队列,等待客户端后续的请求
6.0之前真的是单线程吗?
在6.0之前仍然存在以下后台线程
-
close_file: 用于关闭文件描述符对应文件(释放socket等)
- AOF、RDB产生的临时文件
- 副本数据同步过程中的临时文件
-
aof_fsync: aof刷盘
- 文件追加写之后刷
- 文件重写之后刷
-
lazy_free: 惰性释放空间
-
DEL命令
-
FLUSHALL/FLUSHDB命令
-
采用这些后台线程是想将关闭文件、AOF刷盘、释放内存这些耗时内存分担出去
这些耗时任务业务上常常会采用消息队列处理,redis也用了类似的架构。主线程将任务丢到任务队列中,然后后台线程不断轮询队列
在上面出现了刷盘这个神奇的词,在Linux上指的其实是fsync命令。
Fsync()将文件描述符fd引用的文件的所有修改的内核数据(即,修改的缓冲区缓存页)传输(“刷新”)到磁盘设备(或其他永久存储设备),以便即使系统崩溃或重新启动,也可以检索所有更改的信息。这包括通过磁盘缓存写入或刷新磁盘缓存(如果存在)。在调用过程中会阻塞,直到设备报告数据写入已经完成。
Ref
- https://redis.io/docs/getting-started/faq/
- https://levelup.gitconnected.com/4-reasons-why-single-threaded-redis-is-so-fast-414e0106f921
- https://segmentfault.com/a/1190000040376111
- https://juejin.cn/post/7102780434739626014
- http://antirez.com/news/93
- https://man7.org/linux/man-pages/man2/fsync.2.html