jsonpath语法
$ 表示根节点,也是所有jsonpath表达式的开始
. 表示获取子节点
.. 表示获取所有符合条件的内容
* 代表所有的元素节点
[] 表示迭代器的标示(可以用于处理下标等情况)
[,] 表示多个结果的选择
?() 表示过滤操作
@ 表示当前节点
一、使用代码示例
引入jsonpath库,调用jsonpath方法,入参1是响应结果,入参2是jsonpath表达式。
import jsonpath
data = {
"store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
},
"expensive": 10
}
color = jsonpath.jsonpath(data, '$..bicycle.color')
print(color)
二、解析结果-案例1
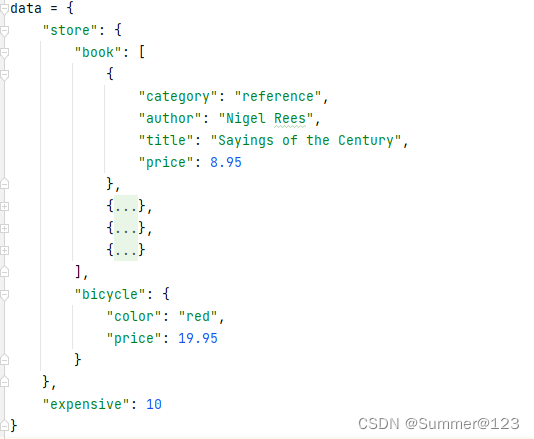
2.1 数据内容
看一下结构如下图:
根节点下只有2个子节点store和expensive。
store有2个子节点book和bicycle
book是一个列表,有4个字典元素,每个字典有4个元素节点
bicycle是一个字典,有2个元素节点color和price
data = {
"store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
},
"expensive": 10
}
2.2 提取bicycle的color
以下三种表达式都可以提取到color。如果可以提取到结果,结果将是一个list,要想取值可通过下标访问。如果没有提取到结果,结果将是False。代码中可以封装一下jsonpath,用isinstance方法对返回结果进行判断。
# 逐级
color = jsonpath.jsonpath(data, '$.store.bicycle.color')
print(color[0])
# 先定位到bicycle节点,再定位到color子节点
color1 = jsonpath.jsonpath(data, '$..bicycle.color')
print(color1[0])
# 由于结构中只有一个color节点,所以可以直接找color节点
color2 = jsonpath.jsonpath(data, '$..color')
print(color2[0])
result:
red
red
red
2.3 提取所有的book
同样两种表达式提取结果相同,更推荐第2种
book1 = jsonpath.jsonpath(data,'$.store.book')
print(book1)
book2 = jsonpath.jsonpath(data,'$..book')
print(book2)
result:
[[{'category': 'reference', 'author': 'Nigel Rees', 'title': 'Sayings of the Century', 'price': 8.95}, {'category': 'fiction', 'author': 'Evelyn Waugh', 'title': 'Sword of Honour', 'price': 12.99}, {'category': 'fiction', 'author': 'Herman Melville', 'title': 'Moby Dick', 'isbn': '0-553-21311-3', 'price': 8.99}, {'category': 'fiction', 'author': 'J. R. R. Tolkien', 'title': 'The Lord of the Rings', 'isbn': '0-395-19395-8', 'price': 22.99}]]
[[{'category': 'reference', 'author': 'Nigel Rees', 'title': 'Sayings of the Century', 'price': 8.95}, {'category': 'fiction', 'author': 'Evelyn Waugh', 'title': 'Sword of Honour', 'price': 12.99}, {'category': 'fiction', 'author': 'Herman Melville', 'title': 'Moby Dick', 'isbn': '0-553-21311-3', 'price': 8.99}, {'category': 'fiction', 'author': 'J. R. R. Tolkien', 'title': 'The Lord of the Rings', 'isbn': '0-395-19395-8', 'price': 22.99}]]
2.4 获取store下所有的price节点的值
同样两种表达式提取结果相同。提取到的值,有book节点中所有的price,也有bicycle的price节点。
# 获取store下所有的price节点的值
price1 = jsonpath.jsonpath(data, '$.store..price')
print(price1)
price2 = jsonpath.jsonpath(data, '$..price')
print(price2)
result:
[8.95, 12.99, 8.99, 22.99, 19.95]
[8.95, 12.99, 8.99, 22.99, 19.95]
2.5 切片:获取book下的price节点
# 获取book下的所有price节点
price3 = jsonpath.jsonpath(data, '$..book..price')
print(price3)
# 连接操作符,在xpath中 结果合并其他结果的集合。JSONPATH允许name或者数据索引。类似于xpath
# 提取前3本书的price(索引0,索引1,索引2)
price4 = jsonpath.jsonpath(data, '$.store.book[0,1,2].price')
print(price4)
# 提取前3本书的price(索引0-索引2,前闭后开,下同)
price5 = jsonpath.jsonpath(data, '$.store.book[:3].price')
print(price5)
# 提取第2、3本书的price(索引1到索引2两本)
price6 = jsonpath.jsonpath(data, '$.store.book[1:3].price')
print(price6)
# 倒数第1的索引是-1,取倒数第一
price7 = jsonpath.jsonpath(data, '$.store.book[-1:].price')
print(price7)
# 取倒数第3和倒数第2两本的price
price8 = jsonpath.jsonpath(data, '$.store.book[-3:-1].price')
print(price8)
result:
[8.95, 12.99, 8.99, 22.99]
[8.95, 12.99, 8.99]
[8.95, 12.99, 8.99]
[12.99, 8.99]
[22.99]
[12.99, 8.99]
2.6 过滤操作
# 获取price大于10的所有book
book_1 = jsonpath.jsonpath(data,'$..book[?(@.price>10)]')
print(book_1)
result:
提取到2本书。
[{'category': 'fiction', 'author': 'Evelyn Waugh', 'title': 'Sword of Honour', 'price': 12.99}, {'category': 'fiction', 'author': 'J. R. R. Tolkien', 'title': 'The Lord of the Rings', 'isbn': '0-395-19395-8', 'price': 22.99}]
2.7 表达式错误
# 这是一条错误的JsonPath
book_2 = jsonpath.jsonpath(data,'$..Evelyn Waugh[?(@.price>10)]')
print(book_2)
result:
提取不到结果,返回的就是False
False
三、解析结果-案例2
3.1 数据内容
根节点下只有1个子节点Connections,且是一个列表,有3个元素,每个元素是一个字典。每个元素有RoleRelationships、Name、Gender、Age四个节点。
RoleRelationships是一个列表,仅有1各元素,每个元素有3个节点:CreatedTime、Type、Role

resp = {
"Connections": [
{
"RoleRelationships": [
{
"CreateTime": "2021-09-08T08:50:56.452Z",
"Type": "家人",
"Role": "妈妈"
}
],
"Name": "闵慧",
"Gender": "Female",
"Age": 28
},
{
"RoleRelationships": [
{
"CreateTime": "2021-09-08T08:50:56.452Z",
"Type": "家人",
"Role": "爸爸"
}
],
"Name": "辛旗",
"Gender": "Male",
"Age": 30
},
{
"RoleRelationships": [
{
"CreateTime": "2021-09-08T08:50:56.452Z",
"Type": "亲戚",
"Role": "妈妈"
}
],
"Name": "曹牧",
"Gender": "Female",
"Age": 30
}
]
}
3.2 提取数据
# 角色是妈妈的
result1 = jsonpath.jsonpath(resp, "$.Connections[?(@.RoleRelationships[0].Role=='妈妈')]")
print(f"1-角色是妈妈:{result1}")
result2 = jsonpath.jsonpath(resp, "$.Connections[?(@.RoleRelationships[0])].[?(@.Role=='妈妈')]")
print(f"2-角色是妈妈:{result2}")
result3 = jsonpath.jsonpath(resp, "$.Connections[?(@.RoleRelationships[0])]..Name")
print(f"3-所有人的名字:{result3}")
result4 = jsonpath.jsonpath(resp, '$.Connections')
print(f"4-所有关系:{result4}")
# 所有家人
result5 = jsonpath.jsonpath(resp, "$.Connections[?(@.RoleRelationships[0].Type=='家人')]")
print(f"5-type是家人:{result5}")
result6 = jsonpath.jsonpath(resp, "$.Connections[?(@.RoleRelationships[0])].[?(@.Type=='家人')]")
print(f"6-type是家人:{result6}")
# 年龄大于28的
result7 = jsonpath.jsonpath(resp, "$.Connections.[?(@.Age>28)]..Name")
print(f"7-年龄大于28:{result7}")
result8 = jsonpath.jsonpath(resp, "$.Connections[?(@.RoleRelationships[0].Role=='爸爸')].Name")
print(f"8-爸爸的名字:{result8}")
result:
1-角色是妈妈:False
2-角色是妈妈:[{'CreateTime': '2021-09-08T08:50:56.452Z', 'Type': '家人', 'Role': '妈妈'}, {'CreateTime': '2021-09-08T08:50:56.452Z', 'Type': '亲戚', 'Role': '妈妈'}]
3-所有人的名字:['闵慧', '辛旗', '曹牧']
4-所有关系:[[{'RoleRelationships': [{'CreateTime': '2021-09-08T08:50:56.452Z', 'Type': '家人', 'Role': '妈妈'}], 'Name': '闵慧', 'Gender': 'Female', 'Age': 28}, {'RoleRelationships': [{'CreateTime': '2021-09-08T08:50:56.452Z', 'Type': '家人', 'Role': '爸爸'}], 'Name': '辛旗', 'Gender': 'Male', 'Age': 30}, {'RoleRelationships': [{'CreateTime': '2021-09-08T08:50:56.452Z', 'Type': '亲戚', 'Role': '妈妈'}], 'Name': '曹牧', 'Gender': 'Female', 'Age': 30}]]
5-type是家人:False
6-type是家人:[{'CreateTime': '2021-09-08T08:50:56.452Z', 'Type': '家人', 'Role': '妈妈'}, {'CreateTime': '2021-09-08T08:50:56.452Z', 'Type': '家人', 'Role': '爸爸'}]
7-年龄大于28:['辛旗', '曹牧']
8-爸爸的名字:False
问题:
1、结果为False的,小编使用JSONPath Online Evaluator - jsonpath.com都是可以提取出结果的,但是用python脚本提取不出结果,并且jsonpath的入参也没有问题。有解决办法欢迎评论。