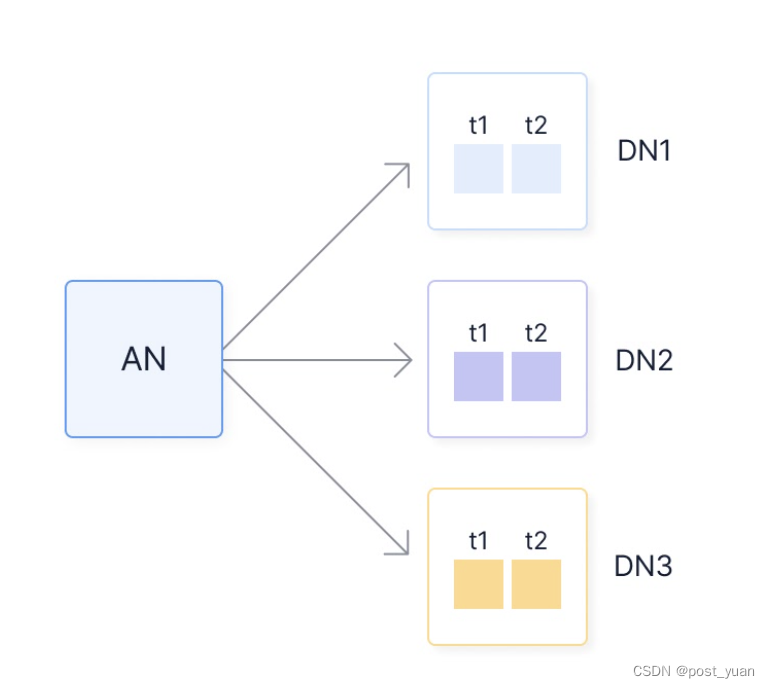
全文共5000余字,预计阅读时间约15~25分钟 | 满满干货(附代码案例),建议收藏!
本文目标:介绍Chat Completions模型的Function calling参数和使用方法,并完整的实现一个Chat模型的Function calling功能案例。
代码下载地址
一、背景
对于大模型(LLMs)来说,尽管能力很强且具备非常强大的涌现能力,但是也存在不小的局限性,比如它无法获取最新的信息、只能给出文字的建议但无法直接解决某些问题(如自动回复邮件、自动查询订阅机票等),这些问题的存在极大程度限制了大语言模型实际应用价值。
所以在2023年4月,AutoGPT针对这种情况提出了一个极具潜力的方案——赋予大语言模型调用外部工具API的能力,大幅拓展大语言模型的能力。例如如果能够让GPT模型调用谷歌搜索API(Google Custom Search JSON API),则模型就可以实时获取和用户问题相关的一系列搜索结果,并结合这些结果和原生的知识库来回答用户的问题,从而解决模型无法获取最新信息这一问题;再比如,如果能够让GPT模型调用谷歌邮箱API(Gmail API),则可以自动让GPT模型读取邮件,并自动进行回复等等。而根据AutoGPT项目规模来看,让GPT模型调用外部工具API其实并不复杂。
在这一大背景下,OpenAI在0613的更新中为目前最先进的Chat类模型增加了Function calling功能,该功能的本质是让大语言模型调用外部函数的能力,即Chat模型可以不再仅仅根据自身的数据库知识进行回答,而是可以额外挂载一个函数库,然后根据用户提问进行函数库检索,根据实际需求调用外部函数并获取函数运行结果,再基于函数运行结果进行回答。其基本过程如下:
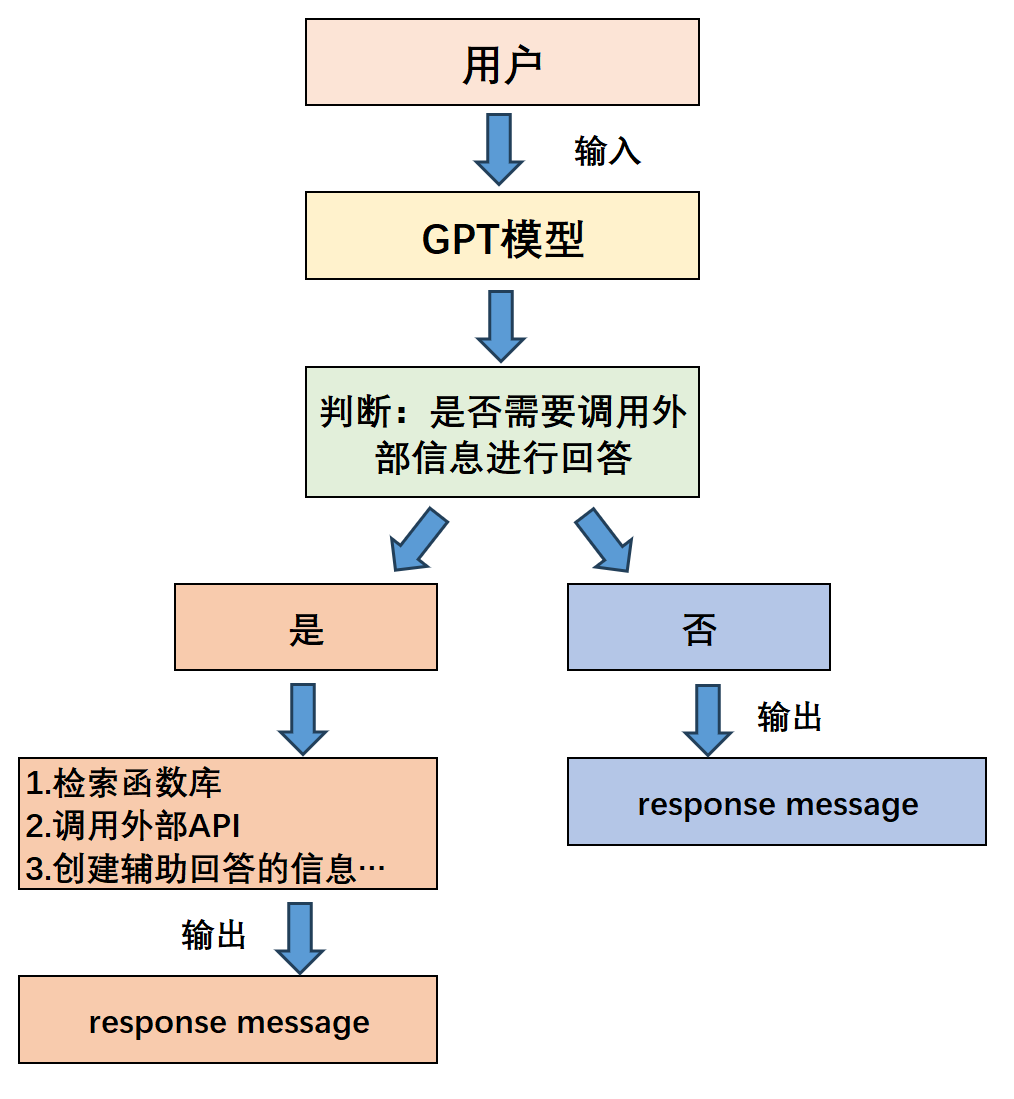
这个外部挂载的函数库,可以是简单的自定义函数,也可以是一个封装了外部工具API的功能型函数,例如一个可以调用谷歌搜索的函数、或者一个可以获取天气信息的函数。
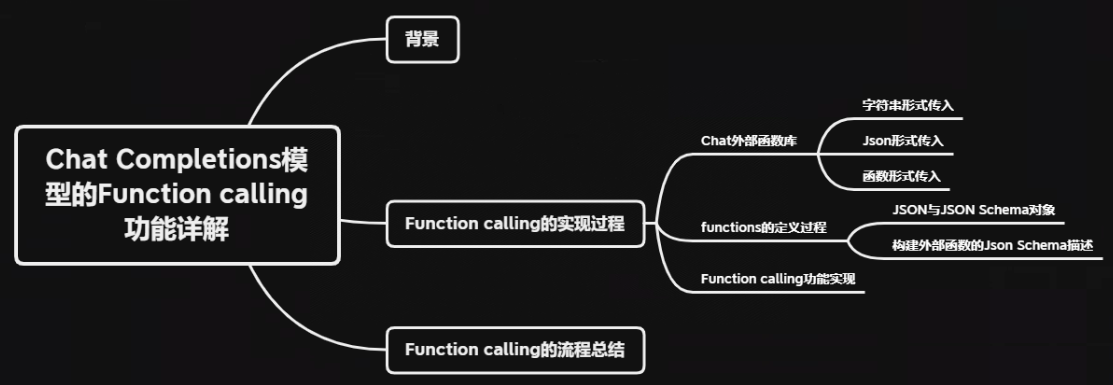
二、Function calling的实现过程
在OpenAI的精妙设计下,Function calling功能的实现过程并不复杂:在编写问答函数时,只需要在ChatCompletions.create函数中进行参数设置、并提前定义好外部函数库即可,然后在Chat模型执行Function calling时,模型会根据用户提问的语义自动检索并挑选合适的函数进行使用,整个过程并不需要人工手动干预指定使用某个函数,大预言模型能够充分发挥自身的语义理解优势,在函数库中自动挑选合适函数进行运行,并给出问题的答案。
2.1 Chat外部函数库
2.1.1 字符串形式传入
即然要让Chat模型调用外部函数,首先需要准备的就是准备好这些“外部函数”。先自定义一个“特殊”的函数,用于测试Chat模型在合理提示下能否正常调用这个外部函数,比如针对这样一个数据:
- 数据准备
# 创建一个DataFrame
df = pd.DataFrame({'x1':[1, 2], 'x2':[3, 4]})
df
# 函数输出的结构都必须是字符串类型才能够被大模型正常的识别
df_str = df.to_string()
df_str
输出如下:
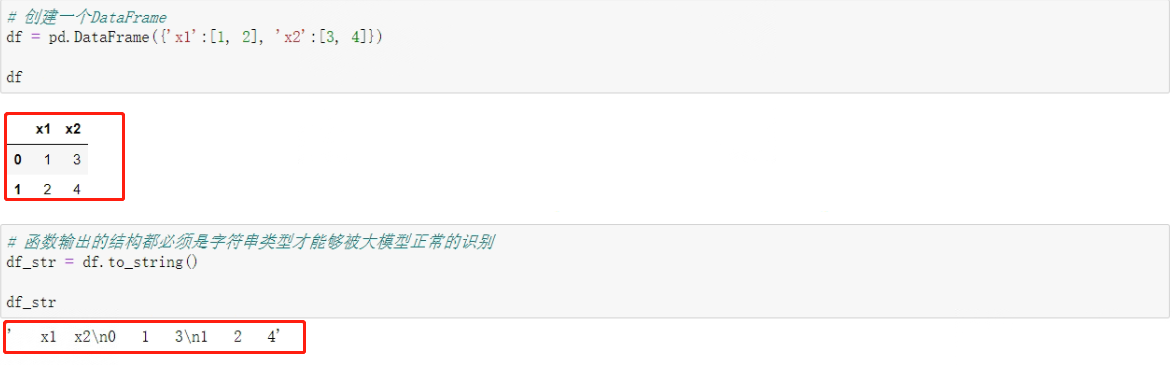
对于所有需要和大模型通信的函数来说,函数输出的结构都必须是字符串类型才能够被大模型正常的识别,所以需要.to_string()的方式,直接将Pandas对象类型转化为字符串,然后再让大模型进行识别,尽管可读性不强,但这个df_str对象实际上是一个包含了df全部信息的字符串对象。
- 验证
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "system", "content": "数据集df_str:'%s'" % df_str},
{"role": "user", "content": "请帮我解释下df_str数据集"}
]
)
response.choices[0].message['content']
输出如下:
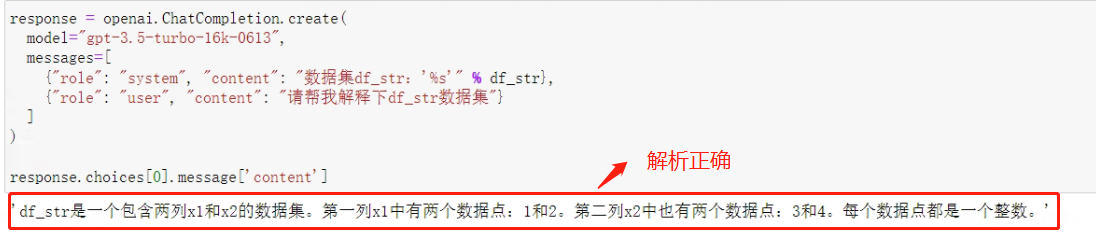
可以看出,模型能够很好的对字符串形式传入的数据集进行解读
2.1.2 Json形式传入
字符串类型对象的可读性并不强,而且很多时候,大模型也并不能非常准确的将字符串对象识别为DataFrame对象类型。一个更为通用的方法是借助JSON格式进行跨函数和跨编程环境的通信,这也是OpenAI官方更加推荐的通信方式。
JSON格式对象,其本质是一种轻量级的数据交换格式,它基于ECMAScript的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据,在python中的表现其实仍然是字符串类型,相当于是一种能够表示原始数据格式的字符串。
- 数据准备
对于df来说,可以通过pandas中的to_json()方法将其转化为json对象类型,代码如下:
df_json = df.to_json(orient='records')
df_json
输出数据格式如下:

- 验证
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "system", "content": "数据集df_json:'%s'" % df_json},
{"role": "user", "content": "请帮我解释下df_json数据集"}
]
)
response.choices[0].message['content']
看下模型解析情况:
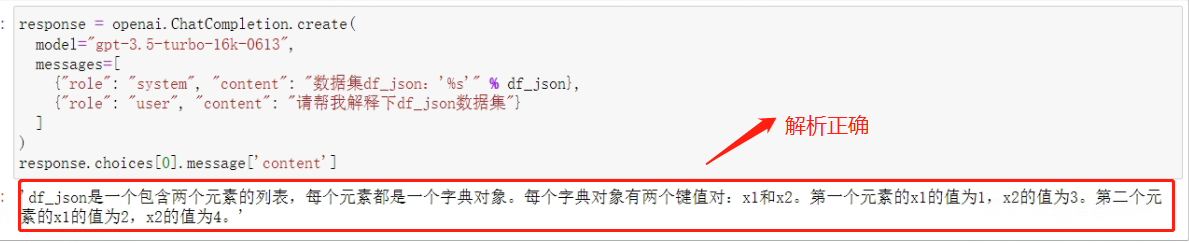
模型能够正常识别JSON对象类型。并且,相比.to_string()翻译而成的字符串对象,JSON对象本身的可读性更强。
2.1.3 函数形式传入
前面提到过,在Chat模型执行Function calling时,模型会根据用户提问的语义自动检索并挑选合适的函数进行使用,但是,作为支持Function calling功能的外部函数,OpenAI明确规定支持Function calling功能的外部函数给大模型返回的结果类型必须是json字符串类型,OpenAI官网说明
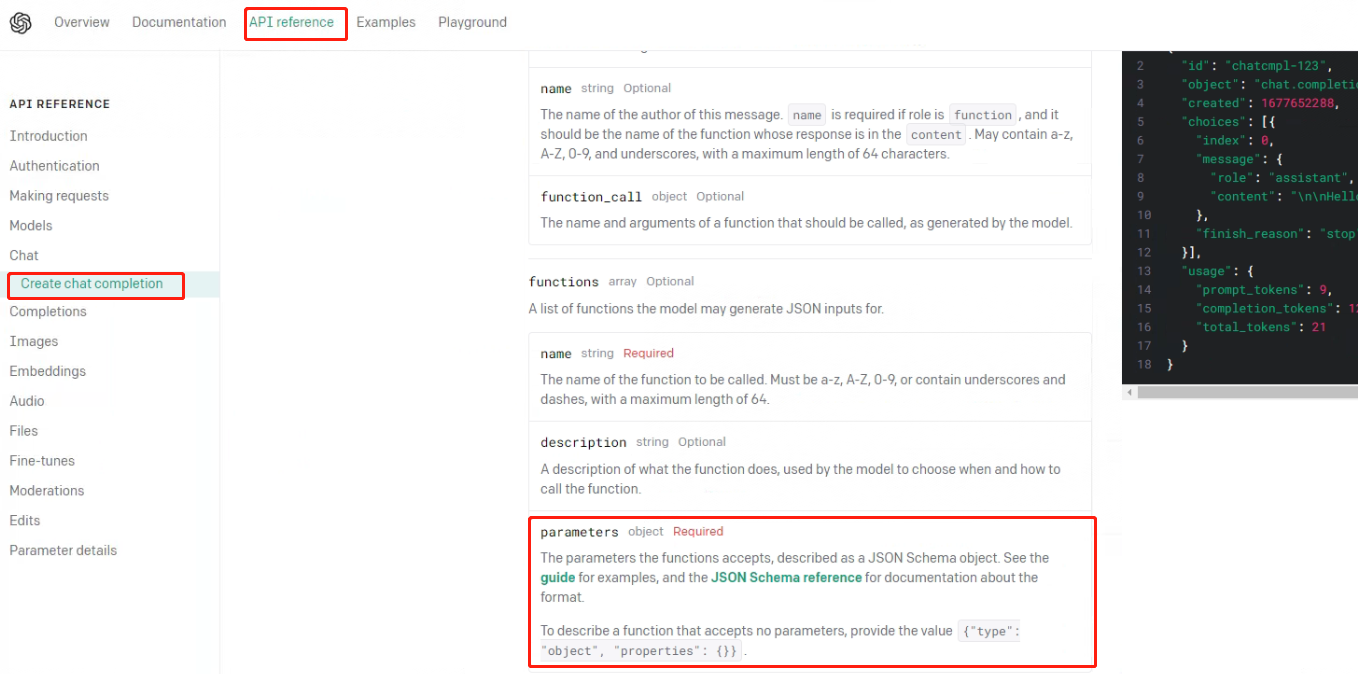
- 编写外部函数
按照要求,创建一个测试函数,功能是将数据集对象按行求和再减1,计算过程如下:
def calculate_algorithm(data):
"""
该函数定义了一种特殊的数据集计算过程
:param data: 必要参数,表示带入计算的数据表,用字符串进行表示
:return:函数计算后的结果,返回结果为表示为JSON格式的Dataframe类型对象
"""
data = io.StringIO(data)
df_new = pd.read_csv(data, sep='\s+', index_col=0)
res = np.sum(df_new, axis=1) - 1
return json.dumps(res.to_string())
- 函数功能测试
该函数的输出结果需要先将Dataframe对象转化为字符串对象,然后再将字符串对象转化为json字符串类型对象,测试下输出:

- 定义函数库
在Chat模型实际执行Function calling功能时,是从一个函数库中筛选合适的函数进行调用,因此需要准备一个函数库。最简单的情况下,函数库允许只包含一个函数,代码如下:
available_functions = {
"calculate_algorithm": calculate_algorithm,
}
函数库对象必须是一个字典,一个键值对代表一个函数,其中Key是代表函数名称的字符串,而value表示对应的函数。
以上是三种传入大模型的形式,显而易见通过函数形式才是利于进一步的开发的,但是对于外部函数(functions)来说,OpenAI定义了一种特殊的编写规则。
2.2 functions的定义过程
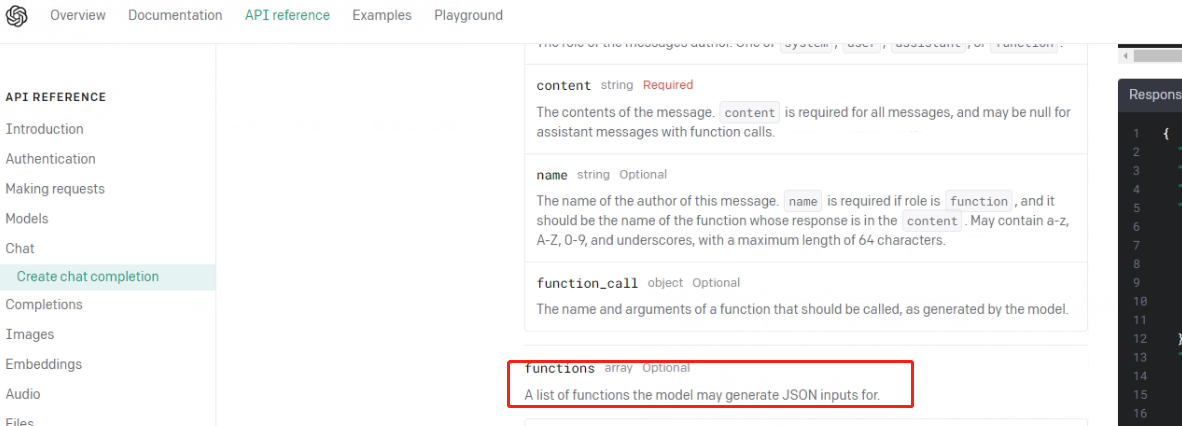
准备好外部函数及函数库之后,接下来非常重要的一步就是需要将外部函数的信息以某种形式传输给Chat模型。此时就需要使用到ChatCompletion.create函数的functions参数,类似于messages参数是用于向模型传输消息,functions参数专门用于向模型传递当前可以调用的外部函数信息。根据OpenAI的官网说明来看:

从参数的具体形式来看,functions参数和messages参数也是非常类似的——都是包含多个字典的list。对于messages来说,每个字典都是一条信息,而对于functions参数来说,每个字典都是一个函数。在大语言模型(LLMs)实际进行问答时,会根据functions参数提供的信息对各函数进行检索。
functions参数对于Chat模型的Function calling功能的实现至关重要。
2.2.1 JSON与JSON Schema对象
"parameters"参数是一个按照JSON Schema格式编写的字典。总的来说,这个字典中包含了函数参数这个对象的全部信息,同时其本身的编写格式也可以用于验证后续传入这个函数的参数是否满足格式要求。
JSON Schema对象,从形式上来说,以下字典其实就是一个JSON Schema对象:
{"type": "object",
"properties": {"data": {"type": "string",
"description": "执行计算算法的数据集"}
},
"required": ["data"]
}
这个字典其实是由多个字典组成,其中type、properties、required等都是字典中的关键字,从语法结构上来说,(和JSON对象类似)满足JSON Schema语法要求的字典对象,都可以看成是JSON Schema对象。而对于JSON Schema对象来说,字典中的关键字都是有独特含义的,要理解这些关键含义,就必须理解JSON Schema对象的作用。
**从功能上来说,JSON Schema对象的根本作用是用于用于描述某一类JSON对象的格式要求。**比如JSON是这样的:
# 创建一个DataFrame
df = pd.DataFrame({'x1':[1, 2], 'x2':[3, 4]})
json_str = df.to_json(orient='records')
json_str
其数据形式是这样的:

不同于JSON对象用于保存实际的对象信息,JSON Schema对象则专门用于描述某JSON对象的数据格式要求,例如在这个例子中,json_str是一个包含多个对象的数组,每个对象都有"x1"和"x2"两个属性,且它们的值都是数字,此时就可以用如下JSON Schema对象来描述json_str对象的数据格式要求:
json_Schema_str = {
"type": "array",
"items": {
"type": "object",
"properties": {
"x1": {
"type": "number"
},
"x2": {
"type": "number"
}
},
"required": ["x1", "x2"]
}
}
json_Schema_str
在这个JSON Schema中:
- “type”: 本身指代 JSON 对象数据的类型,如"string"、“number”、“object”、“array”、“boolean” 或 “null”,这里的JSON对象是个"array",表示这个Schema描述的是一个数组。
- “items”:当 JSON 数据的类型为 “array” 时,定义其元素的结构。在这个例子中,每个元素都是一个对象(object),在JSON中,一个对象(object)指的是由零个或多个键值对组成的无序集合。
- 在"items"对象中,“type”: "object"表示每个元素都是一个对象,"properties"关键字描述了对象的属性,“x1"和"x2"都是对象的属性,它们的类型都是"number”。
- “required”:用于定义哪些属性是必需的。关键字指定了每个对象都必须有"x1"和"x2"这两个属性。
这个JSON Schema可以用来验证类似json_str这样的JSON对象。如果一个JSON对象满足这个Schema,那么它就是一个包含多个对象的数组,每个对象都有"x1"和"x2"两个数字属性。
也就是说,JSON Schema本身并不包含某对象的具体内容信息,只包含某类对象的格式信息
2.2.2 构建外部函数的Json Schema描述
基于对Json Schema的理解,可以创建如下字典完成对calculate_function(计算函数)的完整描述,代码如下:
calculate_function = {"name": "calculate_algorithm",
"description": "用于执行计算算法的函数,定义了一种特殊的数据集计算过程",
"parameters": {"type": "object",
"properties": {"data": {"type": "string",
"description": "执行计算算法的数据集"},
},
"required": ["data"],
},
}

calculatefunction[‘parameters’]非常明确的定义了某类JSON对象类型。而为何需要编写chen_ming_function[‘parameters’],是因为在Chat模型在进行对话时,传入和传出数据信息都是以类似JSON数据格式进行传输的,如下:
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=[
{"role": "user", "content": "请帮我创建一个两行两列的数据集,两列的列名称分别是x1和x2,第一行数据为1、3,第二行为2、4"}
]
)
response.choices[0].message['content']
看下输出结果:
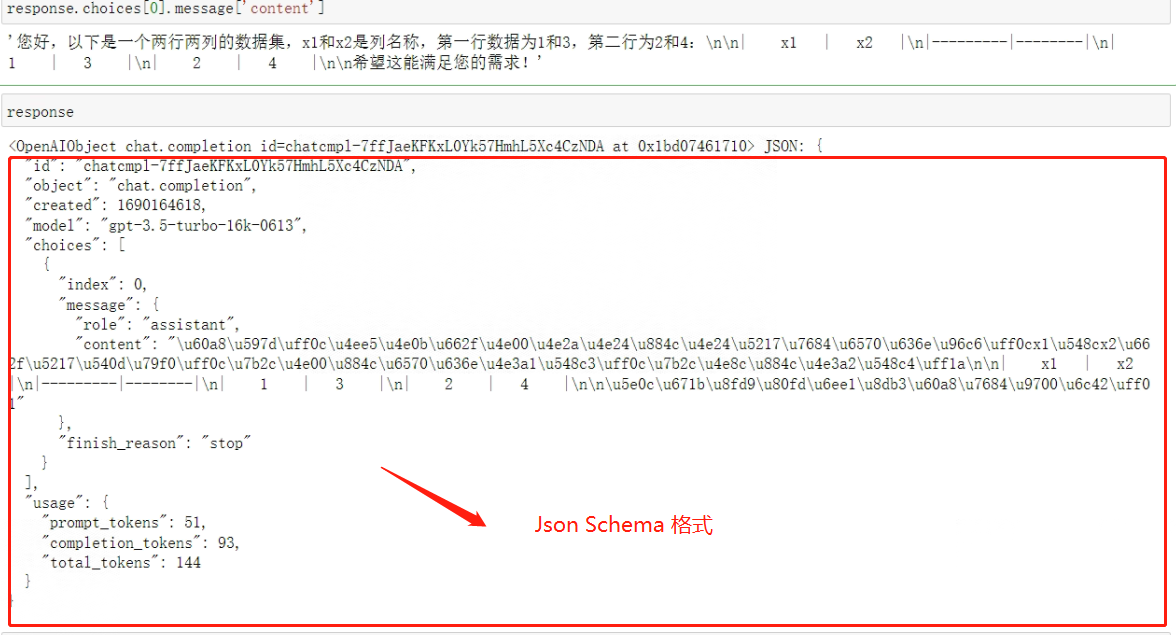
functions的官方参数说明是:A list of functions the model may generate JSON inputs for,也侧面说明模型是通过JSON格式进行数据传输。
2.3 Function calling功能实现
在Chat模型对话执行Function calling功能,需要将函数库相关信息输入给Chat模型,需要额外设置两个参数,其一是functions参数,用于申明外部函数库当前情况,其二则是需要设置function_call参数,该参数用于控制是否执行Function calling功能,该参数有三种不同的取值,默认取值为none,表示不需要调用外部函数,不执行Function calling功能,此时functions参数不需要进行额外设置。而如果设置了functions参数,则function_call参数会默认修改为’auto’(当然也可以手动填写该参数),表示模型将根据用户实际对话情况,有选择性的自动挑选合适函数进行执行,而若想让模型在本次对话中特定执行functions中的某个函数,则可以通过输入如下形式的字典:{“name”:\ “my_function”}进行申明,此时模型不再会自动挑选模型,而是会在functions中挑选"my_function"进行执行。
Chat模型的Function calling实现流程整体来看为如下形式:
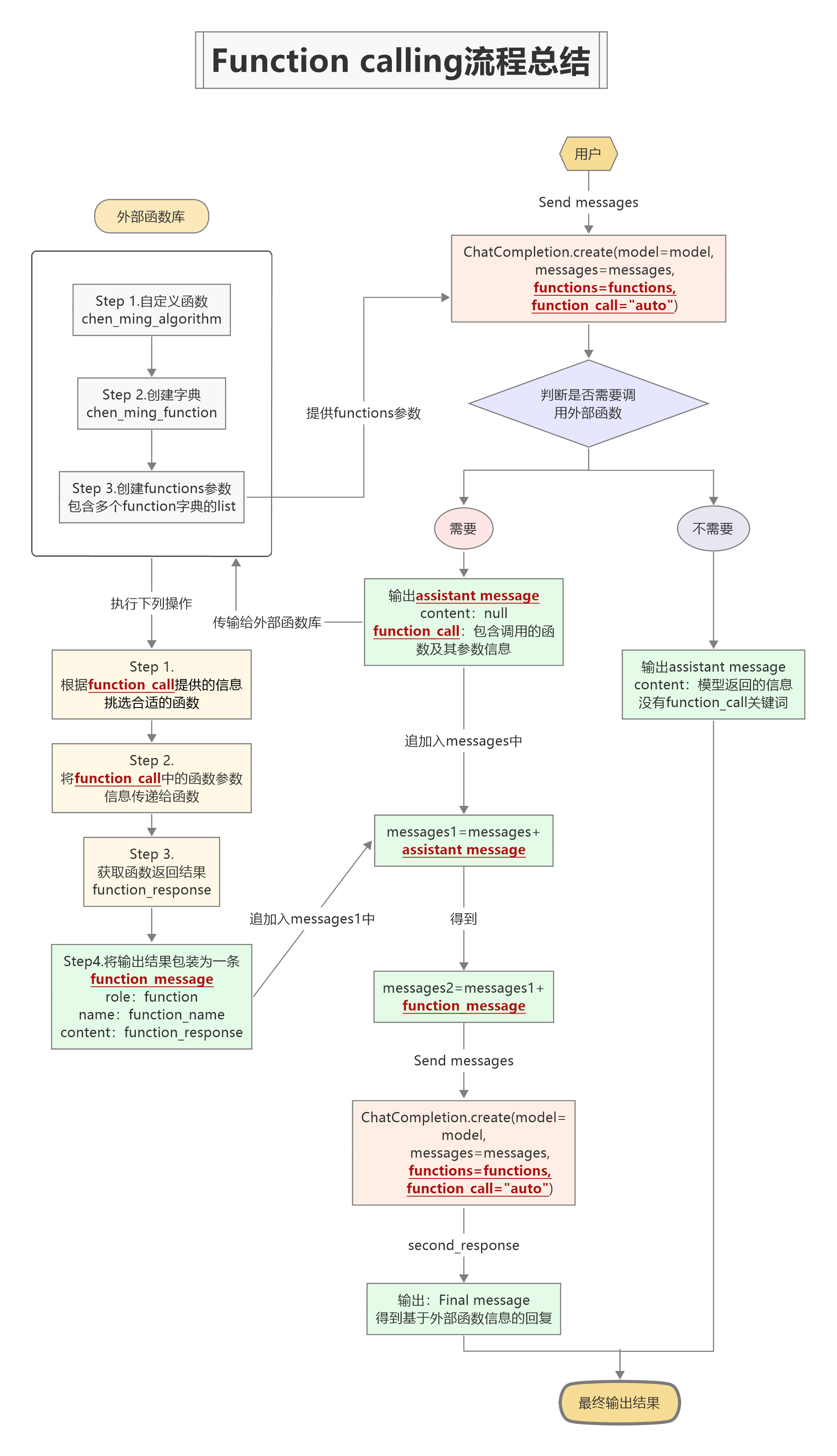
下面尝试使用上述流程完成一个调用测试。
- Step 1: 创建函数列表
类似于输入模型的messages参数是包含多个message的列表,输入模型的functions也是包含多个函数描述的列表,只不过此时只有一个函数,因此functions列表中只有一个字典,代码如下:
calculate_function = {"name": "calculate_algorithm",
"description": "用于执行计算算法的函数,定义了一种特殊的数据集计算过程",
"parameters": {"type": "object",
"properties": {"data": {"type": "string",
"description": "执行计算算法的数据集"},
},
"required": ["data"],
},
}
functions = [calculate_function]
functions
- Step 2:构建数据集
# 创建一个DataFrame
df = pd.DataFrame({'x1':[1, 2], 'x2':[3, 4]})
df_str = df.to_string()
df_str
看下数据形式:

- Step 3:构建messages
messages=[
{"role": "system", "content": "数据集data:%s,数据集以字符串形式呈现" % df_str},
{"role": "user", "content": "请在数据集data上执行计算算法"}
]
- Step 4:传入模型,自动筛选参数
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=messages,
functions=functions,
function_call="auto",
)
response
看下输出结果:
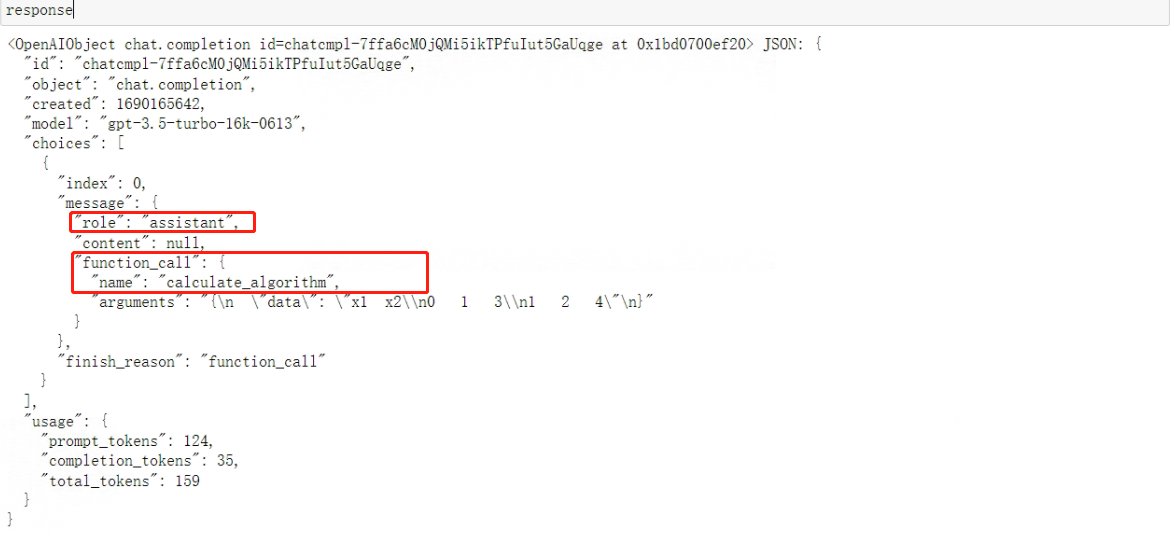
返回的message中content为空,而增了一个"function_call"字典,该字典包含两个键值对,Key为"name"的键值对表示完成该对话需要调用的函数名称,也就是calculate_algorithm,而Key为"arguments"的键值对则表示需要传入该函数的参数。包含function_call关键词,表示这条assistant消息需要调用外部函数。而function_call关键词也是messages参数可以包含的备选关键词之一。
- Step 5:保存核心信息
# 完成对话需要调用的函数名称
function_name = response["choices"][0]["message"]["function_call"]["name"]
available_functions = {
"calculate_algorithm": calculate_algorithm,
}
# 具体的函数对象
fuction_to_call = available_functions[function_name]
# 执行该函数所需要的参数
function_args = json.loads(response["choices"][0]["message"]["function_call"]["arguments"])
保存情况如下:
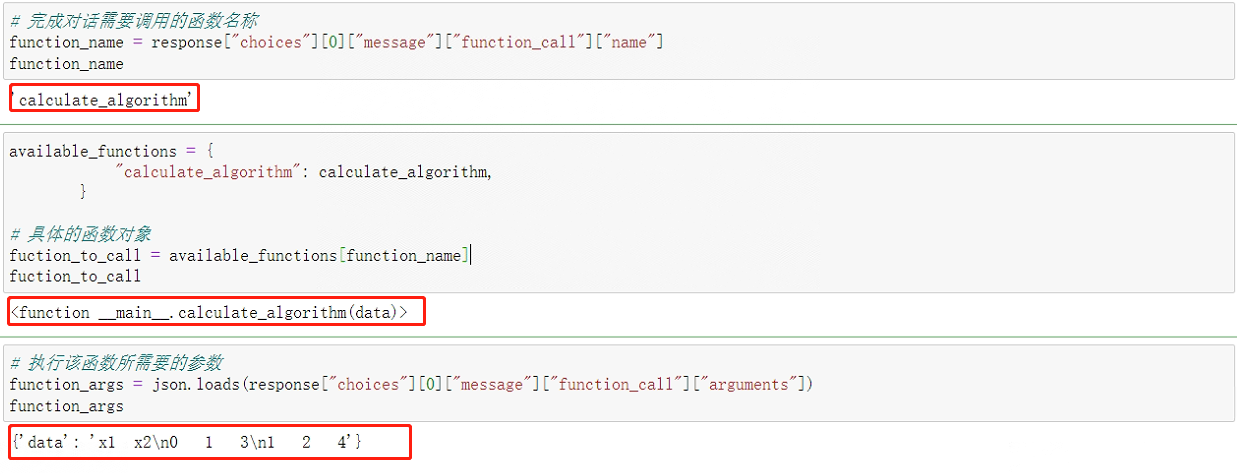
这样做的原因是:外部函数的计算过程仍然是在本地执行,即Chat模型并不会将代码读取到服务器上再进行在线计算,因此接下来需要根据模型返回的函数和函数参数,在本地完成函数计算,然后再将计算过程和结果保存为message并追加到messages后面,并第二次调用Chat模型分析函数的计算结果,并最终根据函数计算结果输出用户问题的答案。
- Step 6:追加参数
借助**方法,直接将function_args对象传入fuction_to_call中,即可一次性传输全部参数,代码如下:
function_response = fuction_to_call(**function_args)
function_response
看下计算结果:

能够发现,模型已经顺利完成计算。
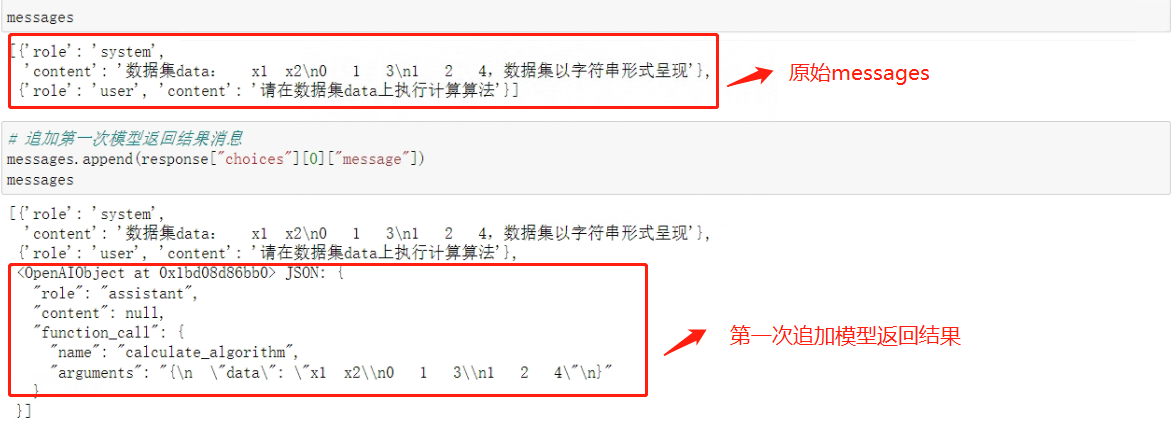
接下来在messages对象中追加两条消息,第一条消息是第一次模型返回的结果(即调用模型的assistant message),第二条消息则是外部函数计算结果,该条消息的role为function,且name为函数名称。
与user、system、assistant message不同,function message必须要输入关键词name,且function message的内容源于外部函数执行的计算结果,并且需要手动进行输入,代码如下:
# 追加第一次模型返回结果消息
messages.append(response["choices"][0]["message"])
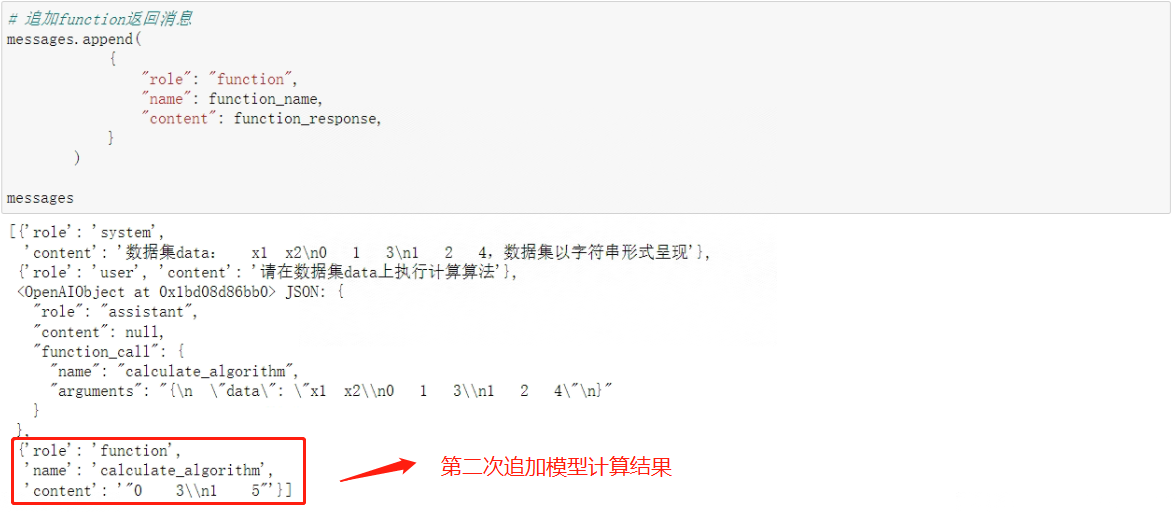
# 追加function返回消息
messages.append(
{
"role": "function",
"name": function_name,
"content": function_response,
}
)
messages
看下messages最终数据情况:
- Step 7: 再次调用Chat模型
此时不再需要向模型重复提问,只需要简单的将已经准备好的messages传入Chat模型即可,代码如下:
second_response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-16k-0613",
messages=messages,)
second_response["choices"][0]["message"]["content"]
看下计算结果:

模型最终做出了准确回答。
- Step 8 :格式化结果
将答案中的字符串再次转化为Dataframe,结果如下:
df_str = '\n\n x1 x2\n0 3\n1 5'
# 使用StringIO将字符串转换为文件对象
data = io.StringIO(df_str)
# 使用read_csv()函数读取数据,并设置第一列为索引
df_new = pd.read_csv(data, sep='\s+', index_col=0)
df_new
得到最终结果:
最终,经过两次Chat模型的调用以及一次本地函数的计算,Chat模型很好的完成了最初问题的回答。至此,也完整的实现了一次Chat模型的Function calling功能。就整个流程而言,Chat模型的Function calling功能实现逻辑还是非常清晰的。
三、 总结
本文给出了Chat Completions模型中Function calling功能的背景,然后详细讲解了Function calling的实现过程。这包括如何构建Chat外部函数库,包括字符串形式、Json形式和函数形式的传入,还解释了如何定义functions,包括JSON与JSON Schema对象和构建外部函数的Json Schema描述。最后,对Function calling的功能实现进行了详细介绍,并对整个流程进行了总结,提供了全面且深入的理解和应用Function calling功能的指导。
最后,感谢您阅读这篇文章!如果您觉得有所收获,别忘了点赞、收藏并关注我,这是我持续创作的动力。您有任何问题或建议,都可以在评论区留言,我会尽力回答并接受您的反馈。如果您希望了解某个特定主题,也欢迎告诉我,我会乐于创作与之相关的文章。谢谢您的支持,期待与您共同成长!