原理部分
1. 驱逐概念介绍
kubelet会定期监控node的内存,磁盘,文件系统等资源,当达到指定的阈值后,就会先尝试回收node级别的资源,比如当磁盘资源不足时会删除不同的image,如果仍然在阈值之上就会开始驱逐pod来回收资源。
2. 驱逐信号
kubelet定义了如下的驱逐信号,当驱逐信号达到了驱逐阈值执行驱逐流程
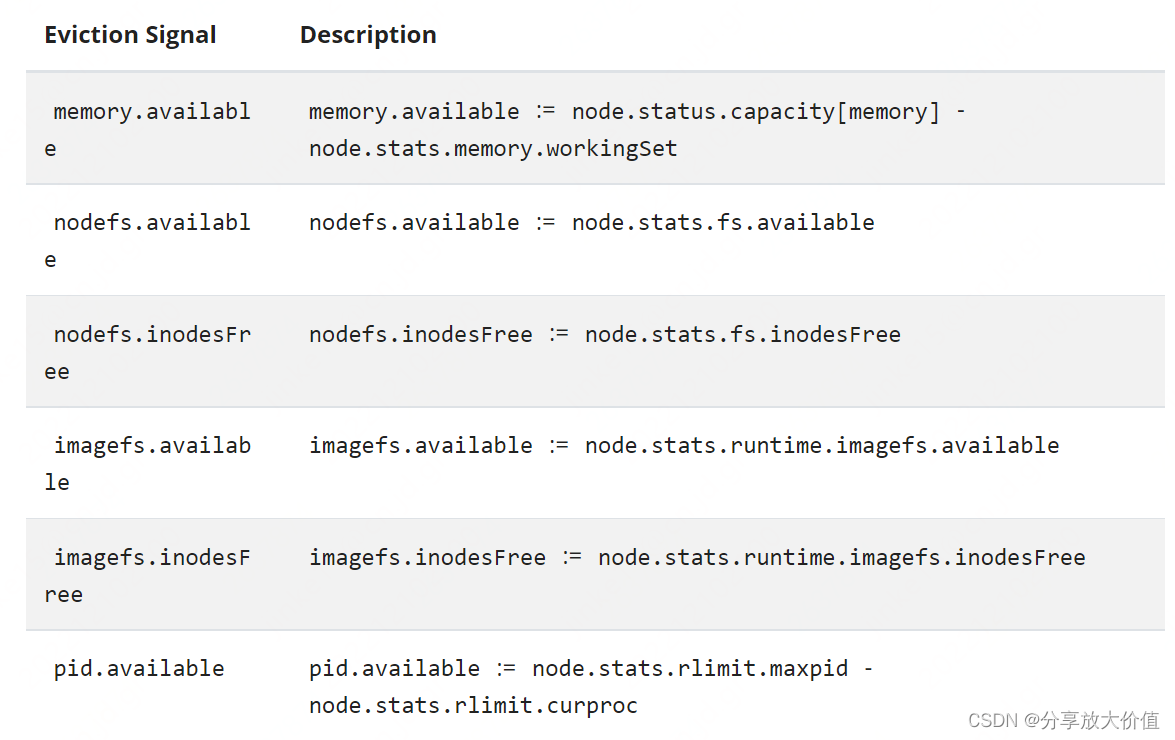
3. 驱逐阈值
驱逐阈值用来指定当驱逐信号达到某个阈值后执行驱逐流程,格式如下:[eviction-signal][operator][quantity],其中eviction-signa为上面定义的驱逐信号,operator为操作符,比如小于等,quantity为指定阈值数据,可以为数字,也可以为百分比。
比如一个node有10G内存,如果期望当可用内存小于1G触发驱逐,可以定义阈值如下:memory.available<10%或者memory.available<1Gi
a. 软驱逐阈值
软驱逐阈值会指定一个grace period时间,只有达到阈值的时间超过了grace period才会执行驱逐流程。
有如下三个相关参数:
–eviction-soft: 指定驱逐阈值集合,比如memory.available<1.5Gi
–eviction-soft-grace-period:指定驱逐grace period时间集合,比如memory.available=1m30s
–eviction-max-pod-grace-period: 指定pod优雅退出时间,要和上面的–eviction-soft-grace-period区分开,–eviction-soft-grace-period指的是
达到阈值持续多久后才执行驱逐流程,而–eviction-max-pod-grace-period指的是驱逐pod后,pod的退出时间
b. 硬驱逐阈值
硬驱逐阈值只要达到了阈值就会执行驱逐流程,有如下参数
–eviction-hard: 指定驱逐阈值集合
如果不指定–eviction-hard,则使用如下默认值
//pkg/kubelet/apis/config/v1beta1/default_linux.go
// DefaultEvictionHard includes default options for hard eviction.
var DefaultEvictionHard = map[string]string{
"memory.available": "100Mi",
"nodefs.available": "10%",
"nodefs.inodesFree": "5%",
"imagefs.available": "15%",
}
驱逐的这些参数都可以在KubeletConfiguration文件中指定,只需要指定驱逐信号和对应的数值即可,操作符默认为小于,具体可参考官网
4. node健康状况
当达到软驱逐(不用等到grace period)或者硬驱逐阈值后,kubelet就会向api-server报告node的健康状况,反应出node的压力。
驱逐信号和node健康状况的关系如下表
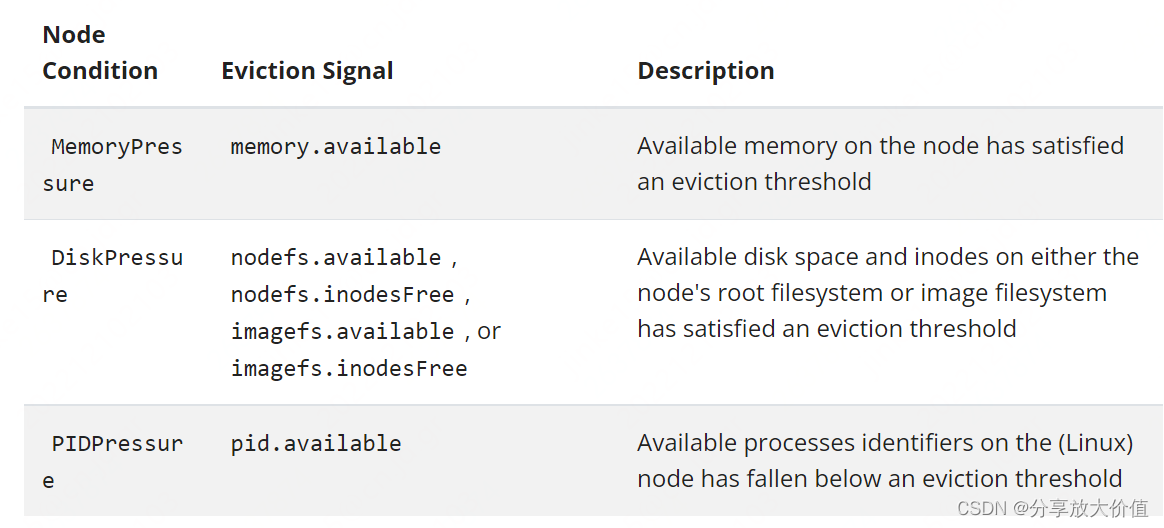
有些情况下,node健康状况可能会在软阈值上下波动,时而健康时而有压力,导致错误的驱逐决定。为了防止这种情况,可以使用参数–eviction-pressure-transition-period来控制node健康状况至少多久变化一次,默认值为5分钟
5. 驱逐pod选择
如果kubelet回收node级别的资源后仍然在阈值之上,则需要驱逐用户创建的pod。影响选择pod进行驱逐的因素如下:
a. 是否pod的资源使用超过了请求值
b. pod的优先级
c. pod的资源使用值和请求值的比例
根据上面三个因素,kubelet排序后进行驱逐pod的顺序如下:
a. 资源使用值超过了请求值的BestEffort和Burstable级别的pod。根据他们的pod优先级和超出请求值的多少进行驱逐
b. 资源使用值小于请求值的Guaranteed和Burstable级别的pod。根据他们的pod优先级进行驱逐
6. 最小回收资源
有些情况下,驱逐pod只能回收很少的一部分资源,可能导致kubelet频繁的执行达到阈值/进行驱逐的过程,为了防止这种情况,可以使用参数–eviction-minimum-reclaim为每种资源配置最小回收数值,当kubelet执行驱逐时,回收的资源会额外加上–eviction-minimum-reclaim指定的值。默认值为0
举例如下,当nodefs.available达到驱逐阈值后,kubelet开始驱逐回收资源直到可用资源达到1G,此时还会继续回收直到达到1.5G才会停止
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
evictionHard:
memory.available: "500Mi"
nodefs.available: "1Gi"
imagefs.available: "100Gi"
evictionMinimumReclaim:
memory.available: "0Mi"
nodefs.available: "500Mi"
imagefs.available: "2Gi"
7. KernelMemcgNotification
kubelet会启动协程周期检查是否达到驱逐阈值,如果有个很重要的pod内存使用增长很快的话,即使达到内存阈值了,kubelet也可能不能及时发现,最终oomkill掉此pod,如果kubelet能及时发现,就能驱逐其他低优先级的pod释放资源给这个高优先级的pod使用。
此时可以使用参数–kernel-memcg-notification使能memcg机制,kubelet会使用epoll监听,当达到阈值后,kubelet能很快得到通知,及时执行驱逐流程。
源码分析
1. 解析驱逐阈值配置
KubeletConfiguration文件中的驱逐阈值相关配置最终会保存到如下结构体中,Thresholds用来保存软驱逐阈值及其grace period,硬驱逐阈值。
// Config holds information about how eviction is configured.
type Config struct {
// PressureTransitionPeriod is duration the kubelet has to wait before transitioning out of a pressure condition.
PressureTransitionPeriod time.Duration
// Maximum allowed grace period (in seconds) to use when terminating pods in response to a soft eviction threshold being met.
MaxPodGracePeriodSeconds int64
// Thresholds define the set of conditions monitored to trigger eviction.
Thresholds []evictionapi.Threshold
// KernelMemcgNotification if true will integrate with the kernel memcg notification to determine if memory thresholds are crossed.
KernelMemcgNotification bool
// PodCgroupRoot is the cgroup which contains all pods.
PodCgroupRoot string
}
// Threshold defines a metric for when eviction should occur.
type Threshold struct {
// Signal defines the entity that was measured.
Signal Signal
// Operator represents a relationship of a signal to a value.
Operator ThresholdOperator
// Value is the threshold the resource is evaluated against.
Value ThresholdValue
// GracePeriod represents the amount of time that a threshold must be met before eviction is triggered.
GracePeriod time.Duration
// MinReclaim represents the minimum amount of resource to reclaim if the threshold is met.
MinReclaim *ThresholdValue
}
调用ParseThresholdConfig解析用户配置
//pkg/kubelet/kubelet.go
func NewMainKubelet(...)
thresholds, err := eviction.ParseThresholdConfig(enforceNodeAllocatable, kubeCfg.EvictionHard, kubeCfg.EvictionSoft, kubeCfg.EvictionSoftGracePeriod, kubeCfg.EvictionMinimumReclaim)
evictionConfig := eviction.Config{
PressureTransitionPeriod: kubeCfg.EvictionPressureTransitionPeriod.Duration,
MaxPodGracePeriodSeconds: int64(kubeCfg.EvictionMaxPodGracePeriod),
Thresholds: thresholds,
KernelMemcgNotification: kernelMemcgNotification,
PodCgroupRoot: kubeDeps.ContainerManager.GetPodCgroupRoot(),
}
2. 创建evictionManager
调用eviction.NewManager创建evictionManager,klet.resourceAnalyzer用来获取node和pod的统计信息,evictionConfig为用户配置的驱逐阈值,killPodNow用来kill pod
//pkg/kubelet/kubelet.go
func NewMainKubelet(...)
// setup eviction manager
evictionManager, evictionAdmitHandler := eviction.NewManager(klet.resourceAnalyzer, evictionConfig, killPodNow(klet.podWorkers, kubeDeps.Recorder), klet.podManager.GetMirrorPodByPod, klet.imageManager, klet.containerGC, kubeDeps.Recorder, nodeRef, klet.clock)
klet.evictionManager = evictionManager
//将evictionManager添加到admitHandlers,创建pod时会调用evictionManager.Admit如果node有资源压力则拒绝pod运行在此node上
klet.admitHandlers.AddPodAdmitHandler(evictionAdmitHandler)
3. 启动evictionManager
调用evictionManager的start函数启动驱逐管理,kl.GetActivePods用来获取运行在本node上的active pod,kl.podResourcesAreReclaimed用来确认pod的资源是否完全释放,evictionMonitoringPeriod为没有驱逐pod时的sleep时间
// Period for performing eviction monitoring.
// ensure this is kept in sync with internal cadvisor housekeeping.
evictionMonitoringPeriod = time.Second * 10
func initializeRuntimeDependentModules(...)
// eviction manager must start after cadvisor because it needs to know if the container runtime has a dedicated imagefs
kl.evictionManager.Start(kl.StatsProvider, kl.GetActivePods, kl.podResourcesAreReclaimed, evictionMonitoringPeriod)
如果指定了–kernel-memcg-notification,则启动实时驱逐,同时也会创建协程启动轮训驱逐
//pkg/kubelet/eviction/eviction_manager.go
// Start starts the control loop to observe and response to low compute resources.
func (m *managerImpl) Start(diskInfoProvider DiskInfoProvider, podFunc ActivePodsFunc, podCleanedUpFunc PodCleanedUpFunc, monitoringInterval time.Duration) {
thresholdHandler := func(message string) {
klog.InfoS(message)
m.synchronize(diskInfoProvider, podFunc)
}
//实时驱逐。如果指定了--kernel-memcg-notification,则使能memcg机制,如果达到指定的阈值,就能很快调用synchronize
if m.config.KernelMemcgNotification {
for _, threshold := range m.config.Thresholds {
if threshold.Signal == evictionapi.SignalMemoryAvailable || threshold.Signal == evictionapi.SignalAllocatableMemoryAvailable {
notifier, err := NewMemoryThresholdNotifier(threshold, m.config.PodCgroupRoot, &CgroupNotifierFactory{}, thresholdHandler)
if err != nil {
klog.InfoS("Eviction manager: failed to create memory threshold notifier", "err", err)
} else {
go notifier.Start()
m.thresholdNotifiers = append(m.thresholdNotifiers, notifier)
}
}
}
}
//轮训驱逐
// start the eviction manager monitoring
go func() {
for {
//如果synchronize返回值不为空,说明有pod被驱逐了,则调用waitForPodsCleanup等待pod的资源被释放
if evictedPods := m.synchronize(diskInfoProvider, podFunc); evictedPods != nil {
klog.InfoS("Eviction manager: pods evicted, waiting for pod to be cleaned up", "pods", format.Pods(evictedPods))
m.waitForPodsCleanup(podCleanedUpFunc, evictedPods)
} else {//否则没有pod被驱逐时,需要sleep 10s
time.Sleep(monitoringInterval)
}
}
}()
}
waitForPodsCleanup堵塞等待pod资源被回收,直到成功或者超时
func (m *managerImpl) waitForPodsCleanup(podCleanedUpFunc PodCleanedUpFunc, pods []*v1.Pod) {
//最多等待30s
timeout := m.clock.NewTimer(podCleanupTimeout)
defer timeout.Stop()
//每秒执行一次
ticker := m.clock.NewTicker(podCleanupPollFreq)
defer ticker.Stop()
for {
select {
case <-timeout.C():
klog.InfoS("Eviction manager: timed out waiting for pods to be cleaned up", "pods", format.Pods(pods))
return
case <-ticker.C():
for i, pod := range pods {
//podCleanedUpFunc为pkg/kubelet/kubelet_pods.go:podResourcesAreReclaimed,用来判断pod的资源是否已经被回收,
//如果仍然被回收则返回false,跳出循环等待下次
if !podCleanedUpFunc(pod) {
break
}
if i == len(pods)-1 {
klog.InfoS("Eviction manager: pods successfully cleaned up", "pods", format.Pods(pods))
return
}
}
}
}
}
synchronize为evictionManager的核心函数,实时驱逐和轮训驱逐都会调用它
// synchronize is the main control loop that enforces eviction thresholds.
// Returns the pod that was killed, or nil if no pod was killed.
func (m *managerImpl) synchronize(diskInfoProvider DiskInfoProvider, podFunc ActivePodsFunc) []*v1.Pod {
// if we have nothing to do, just return
thresholds := m.config.Thresholds
//如果配置的驱逐阈值集合为空,则返回。因为有默认值的存在,肯定不会为空
if len(thresholds) == 0 && !utilfeature.DefaultFeatureGate.Enabled(features.LocalStorageCapacityIsolation) {
return nil
}
klog.V(3).InfoS("Eviction manager: synchronize housekeeping")
// build the ranking functions (if not yet known)
// TODO: have a function in cadvisor that lets us know if global housekeeping has completed
if m.dedicatedImageFs == nil {
hasImageFs, ok := diskInfoProvider.HasDedicatedImageFs()
if ok != nil {
return nil
}
m.dedicatedImageFs = &hasImageFs
//建立驱逐信号到排序函数的映射,比如对于SignalMemoryAvailable,使用rankMemoryPressure进行排序
m.signalToRankFunc = buildSignalToRankFunc(hasImageFs)
//建立驱逐信号到node级别资源回收函数的映射
m.signalToNodeReclaimFuncs = buildSignalToNodeReclaimFuncs(m.imageGC, m.containerGC, hasImageFs)
}
//podFunc()为kl.GetActivePods用来获取运行在本node上的active pod
activePods := podFunc()
updateStats := true
//调用summaryProviderImpl.Get获取node和pod统计信息
summary, err := m.summaryProvider.Get(updateStats)
if err != nil {
klog.ErrorS(err, "Eviction manager: failed to get summary stats")
return nil
}
//notifier相关的,暂时忽略
if m.clock.Since(m.thresholdsLastUpdated) > notifierRefreshInterval {
m.thresholdsLastUpdated = m.clock.Now()
for _, notifier := range m.thresholdNotifiers {
if err := notifier.UpdateThreshold(summary); err != nil {
klog.InfoS("Eviction manager: failed to update notifier", "notifier", notifier.Description(), "err", err)
}
}
}
//将获取的node和pod统计信息summary转换到observations,此为驱逐信号到signalObservation的map,signalObservation保存了驱逐信号
//的总容量,可用值和获取统计时的时间
// make observations and get a function to derive pod usage stats relative to those observations.
observations, statsFunc := makeSignalObservations(summary)
debugLogObservations("observations", observations)
//比较observations中的资源信息和配置的驱逐阈值thresholds,将达到阈值的thresholds返回,
//比如配置的驱逐阈值为memory.available: "500Mi"和nodefs.available: "1Gi",而observations中内存可用为400Mi,
//可用nodefs为2Gi,则返回memory.available相关信息
// determine the set of thresholds met independent of grace period
thresholds = thresholdsMet(thresholds, observations, false)
debugLogThresholdsWithObservation("thresholds - ignoring grace period", thresholds, observations)
//thresholdsMet记录的是上次达到驱逐阈值的信号
// determine the set of thresholds previously met that have not yet satisfied the associated min-reclaim
if len(m.thresholdsMet) > 0 {
//经过上次的驱逐流程后,可能已经成功回收资源,对上次达到驱逐阈值的信号再次进行判断是否降低到阈值之下,
//如果没降低到阈值之下,需要将本次的thresholds和上次的m.thresholdsMet进行合并。
//还有一种情况,对于软驱逐来说,第一次达到阈值后可能还没超过grace periods,则保存到m.thresholdsMet,下次走到这里时进行合并,
//执行后续流程,如果仍然没超过grace periods则继续,直到超过grace periods指定的时间
thresholdsNotYetResolved := thresholdsMet(m.thresholdsMet, observations, true)
thresholds = mergeThresholds(thresholds, thresholdsNotYetResolved)
}
debugLogThresholdsWithObservation("thresholds - reclaim not satisfied", thresholds, observations)
//记录驱逐信号第一次达到阈值的时间,目的是为了计算是否超过grace periods指定的时间
//thresholds是本次发现达到阈值的驱逐信号,m.thresholdsFirstObservedAt保存的驱逐信号是第一次
//达到阈值的时间
// track when a threshold was first observed
now := m.clock.Now()
thresholdsFirstObservedAt := thresholdsFirstObservedAt(thresholds, m.thresholdsFirstObservedAt, now)
//根据达到阈值的驱逐信号返回对应的node健康状况,比如达到内存可用阈值了,则返回NodeMemoryPressure
// the set of node conditions that are triggered by currently observed thresholds
nodeConditions := nodeConditions(thresholds)
if len(nodeConditions) > 0 {
klog.V(3).InfoS("Eviction manager: node conditions - observed", "nodeCondition", nodeConditions)
}
//记录不同node健康状况上次出问题的时间,目的是为了计算是否超过了PressureTransitionPeriod指定的时间,防止node健康状况出现波动
// track when a node condition was last observed
nodeConditionsLastObservedAt := nodeConditionsLastObservedAt(nodeConditions, m.nodeConditionsLastObservedAt, now)
//只要记录的node健康状况出问题的时间在PressureTransitionPeriod指定的时间内,则返回true,即认为node健康状况还是有问题,
//比如PressureTransitionPeriod为5分钟,在第一分钟时可用内存信号达到了内存阈值,设置node健康状况为NodeMemoryPressure,
//第二分钟即使可用内存信号降到了内存阈值之下,也不会将NodeMemoryPressure删除,而是等到过了5分钟之后,如果可用内存信号仍然
//在内存阈值之下,才会删除NodeMemoryPressure,即需要保持NodeMemoryPressure状态持续至少5分钟,不过这段时间内内存如何变化。
// node conditions report true if it has been observed within the transition period window
nodeConditions = nodeConditionsObservedSince(nodeConditionsLastObservedAt, m.config.PressureTransitionPeriod, now)
if len(nodeConditions) > 0 {
klog.V(3).InfoS("Eviction manager: node conditions - transition period not met", "nodeCondition", nodeConditions)
}
//返回超过grace periods的驱逐信号,主要是针对软驱逐来说,硬驱逐每次都会返回
// determine the set of thresholds we need to drive eviction behavior (i.e. all grace periods are met)
thresholds = thresholdsMetGracePeriod(thresholdsFirstObservedAt, now)
debugLogThresholdsWithObservation("thresholds - grace periods satisfied", thresholds, observations)
//保存重要的变量
// update internal state
m.Lock()
m.nodeConditions = nodeConditions
m.thresholdsFirstObservedAt = thresholdsFirstObservedAt
m.nodeConditionsLastObservedAt = nodeConditionsLastObservedAt
m.thresholdsMet = thresholds
// determine the set of thresholds whose stats have been updated since the last sync
thresholds = thresholdsUpdatedStats(thresholds, observations, m.lastObservations)
debugLogThresholdsWithObservation("thresholds - updated stats", thresholds, observations)
m.lastObservations = observations
m.Unlock()
// evict pods if there is a resource usage violation from local volume temporary storage
// If eviction happens in localStorageEviction function, skip the rest of eviction action
if utilfeature.DefaultFeatureGate.Enabled(features.LocalStorageCapacityIsolation) {
if evictedPods := m.localStorageEviction(activePods, statsFunc); len(evictedPods) > 0 {
return evictedPods
}
}
//如果为0,说明没有驱逐信号达到阈值,即没有资源压力,返回即可
if len(thresholds) == 0 {
klog.V(3).InfoS("Eviction manager: no resources are starved")
return nil
}
//将驱逐信号进行排序,将内存驱逐信号排在前面
// rank the thresholds by eviction priority
sort.Sort(byEvictionPriority(thresholds))
//获取第一个驱逐信号,上面刚排序过,最新驱逐的是内存信号
thresholdToReclaim, resourceToReclaim, foundAny := getReclaimableThreshold(thresholds)
if !foundAny {
return nil
}
klog.InfoS("Eviction manager: attempting to reclaim", "resourceName", resourceToReclaim)
// record an event about the resources we are now attempting to reclaim via eviction
m.recorder.Eventf(m.nodeRef, v1.EventTypeWarning, "EvictionThresholdMet", "Attempting to reclaim %s", resourceToReclaim)
//首先查看是否有node层级的资源可回收,回收后,再次m.summaryProvider.Get获取node和pod统计信息,和m.config.Thresholds进行比较,
//如果没有达到阈值的驱逐信号,则返回true,说明node层级的资源回收后,已经没有资源压力。
//内存驱逐信号不属于node层级资源
// check if there are node-level resources we can reclaim to reduce pressure before evicting end-user pods.
if m.reclaimNodeLevelResources(thresholdToReclaim.Signal, resourceToReclaim) {
klog.InfoS("Eviction manager: able to reduce resource pressure without evicting pods.", "resourceName", resourceToReclaim)
return nil
}
klog.InfoS("Eviction manager: must evict pod(s) to reclaim", "resourceName", resourceToReclaim)
//根据驱逐信号获取排序函数,比如内存驱逐信号对应的排序函数为rankMemoryPressure
// rank the pods for eviction
rank, ok := m.signalToRankFunc[thresholdToReclaim.Signal]
if !ok {
klog.ErrorS(nil, "Eviction manager: no ranking function for signal", "threshold", thresholdToReclaim.Signal)
return nil
}
//没有active的pod,返回
// the only candidates viable for eviction are those pods that had anything running.
if len(activePods) == 0 {
klog.ErrorS(nil, "Eviction manager: eviction thresholds have been met, but no pods are active to evict")
return nil
}
//对activePods进行排序
// rank the running pods for eviction for the specified resource
rank(activePods, statsFunc)
klog.InfoS("Eviction manager: pods ranked for eviction", "pods", format.Pods(activePods))
//record age of metrics for met thresholds that we are using for evictions.
for _, t := range thresholds {
timeObserved := observations[t.Signal].time
if !timeObserved.IsZero() {
metrics.EvictionStatsAge.WithLabelValues(string(t.Signal)).Observe(metrics.SinceInSeconds(timeObserved.Time))
}
}
//遍历activePods开始驱逐,每次最多驱逐一个pod。为什么还要循环呢?因为有些pod属于Critical pod,这些pod不能驱逐
// we kill at most a single pod during each eviction interval
for i := range activePods {
pod := activePods[i]
gracePeriodOverride := int64(0)
//软驱逐设置gracePeriodOverride为MaxPodGracePeriodSeconds,
//硬驱逐置gracePeriodOverride为0
if !isHardEvictionThreshold(thresholdToReclaim) {
gracePeriodOverride = m.config.MaxPodGracePeriodSeconds
}
message, annotations := evictionMessage(resourceToReclaim, pod, statsFunc)
//执行驱逐,如果evictPod返回nil说明pod为Critical pod,返回非nil说明对pod进行驱逐了,但不会管驱逐是否成功
if m.evictPod(pod, gracePeriodOverride, message, annotations) {
metrics.Evictions.WithLabelValues(string(thresholdToReclaim.Signal)).Inc()
return []*v1.Pod{pod}
}
}
klog.InfoS("Eviction manager: unable to evict any pods from the node")
return nil
}
evictPod对pod执行驱逐,如果pod为Critical pod则直接返回nil
func (m *managerImpl) evictPod(pod *v1.Pod, gracePeriodOverride int64, evictMsg string, annotations map[string]string) bool {
// If the pod is marked as critical and static, and support for critical pod annotations is enabled,
// do not evict such pods. Static pods are not re-admitted after evictions.
// https://github.com/kubernetes/kubernetes/issues/40573 has more details.
if kubelettypes.IsCriticalPod(pod) {
klog.ErrorS(nil, "Eviction manager: cannot evict a critical pod", "pod", klog.KObj(pod))
return false
}
// record that we are evicting the pod
m.recorder.AnnotatedEventf(pod, annotations, v1.EventTypeWarning, Reason, evictMsg)
// this is a blocking call and should only return when the pod and its containers are killed.
klog.V(3).InfoS("Evicting pod", "pod", klog.KObj(pod), "podUID", pod.UID, "message", evictMsg)
//killPodFunc为pkg/kubelet/pod_workers.go:killPodNow
err := m.killPodFunc(pod, true, &gracePeriodOverride, func(status *v1.PodStatus) {
status.Phase = v1.PodFailed
status.Reason = Reason
status.Message = evictMsg
})
if err != nil {
klog.ErrorS(err, "Eviction manager: pod failed to evict", "pod", klog.KObj(pod))
} else {
klog.InfoS("Eviction manager: pod is evicted successfully", "pod", klog.KObj(pod))
}
return true
}
Critical pod的判断方法
// IsCriticalPod returns true if pod's priority is greater than or equal to SystemCriticalPriority.
func IsCriticalPod(pod *v1.Pod) bool {
//pod的注释kubernetes.io/config.source不为api,即不是从apiserver获取的pod都为静态pod
if IsStaticPod(pod) {
return true
}
//pod的注释kubernetes.io/config.mirror不为空的pod为镜像pod
if IsMirrorPod(pod) {
return true
}
//pod的优先级不为空,且优先级大于 2*1000000000
if pod.Spec.Priority != nil && IsCriticalPodBasedOnPriority(*pod.Spec.Priority) {
return true
}
return false
}
killPodNow调用pod_workers的UpdatePod kill pod,此函数为堵塞调用,或者返回成功,或者等timeout超时
//pkg/kubelet/pod_workers.go
// killPodNow returns a KillPodFunc that can be used to kill a pod.
// It is intended to be injected into other modules that need to kill a pod.
func killPodNow(podWorkers PodWorkers, recorder record.EventRecorder) eviction.KillPodFunc {
return func(pod *v1.Pod, isEvicted bool, gracePeriodOverride *int64, statusFn func(*v1.PodStatus)) error {
// determine the grace period to use when killing the pod
gracePeriod := int64(0)
if gracePeriodOverride != nil {
gracePeriod = *gracePeriodOverride
} else if pod.Spec.TerminationGracePeriodSeconds != nil {
gracePeriod = *pod.Spec.TerminationGracePeriodSeconds
}
// we timeout and return an error if we don't get a callback within a reasonable time.
// the default timeout is relative to the grace period (we settle on 10s to wait for kubelet->runtime traffic to complete in sigkill)
timeout := int64(gracePeriod + (gracePeriod / 2))
minTimeout := int64(10)
if timeout < minTimeout {
timeout = minTimeout
}
timeoutDuration := time.Duration(timeout) * time.Second
// open a channel we block against until we get a result
ch := make(chan struct{}, 1)
podWorkers.UpdatePod(UpdatePodOptions{
Pod: pod,
UpdateType: kubetypes.SyncPodKill, //更新类型为kill
KillPodOptions: &KillPodOptions{
CompletedCh: ch,
Evict: isEvicted,
PodStatusFunc: statusFn,
PodTerminationGracePeriodSecondsOverride: gracePeriodOverride,
},
})
// wait for either a response, or a timeout
select {
//堵塞channel等待,kill成功后会close此channel,这里返回nil
case <-ch:
return nil
case <-time.After(timeoutDuration): //超时了返回err
recorder.Eventf(pod, v1.EventTypeWarning, events.ExceededGracePeriod, "Container runtime did not kill the pod within specified grace period.")
return fmt.Errorf("timeout waiting to kill pod")
}
}
}
UpdatePod的调用链如下
UpdatePod-> managePodLoop -> syncTerminatingPod -> killPod -> containerRuntime.KillPod
4. nodeConditions的作用
有如下两个作用
a. 如果node健康状况出问题就会上报到kube-apiserver,代码如下
func (kl *Kubelet) defaultNodeStatusFuncs() []func(*v1.Node) error
setters = append(setters,
//上传MemoryPressure
nodestatus.MemoryPressureCondition(kl.clock.Now, kl.evictionManager.IsUnderMemoryPressure, kl.recordNodeStatusEvent),
//上传DiskPressure
nodestatus.DiskPressureCondition(kl.clock.Now, kl.evictionManager.IsUnderDiskPressure, kl.recordNodeStatusEvent),
//上传PIDPressure
nodestatus.PIDPressureCondition(kl.clock.Now, kl.evictionManager.IsUnderPIDPressure, kl.recordNodeStatusEvent),
)
如果m.nodeConditions包含NodeMemoryPressure说明有当前可用内存超过了内存驱逐信号的阈值
// IsUnderMemoryPressure returns true if the node is under memory pressure.
func (m *managerImpl) IsUnderMemoryPressure() bool {
m.RLock()
defer m.RUnlock()
return hasNodeCondition(m.nodeConditions, v1.NodeMemoryPressure)
}
会有两个表现,一个是node污点增加了node.kubernetes.io/memory-pressure:NoSchedule,另一个是node的Conditions也能看到MemoryPressure,可使用kubectl describe node master查看
root@master:~# kubectl describe node master
...
Taints: node.kubernetes.io/memory-pressure:NoSchedule
Unschedulable: false
Lease:
HolderIdentity: master
AcquireTime: <unset>
RenewTime: Sat, 10 Dec 2022 10:23:38 +0000
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
MemoryPressure True Sat, 10 Dec 2022 10:22:06 +0000 Sat, 10 Dec 2022 10:22:06 +0000 KubeletHasInsufficientMemory kubelet has insufficient memory available
node有了node.kubernetes.io/memory-pressure:NoSchedule污点后,还可能会影响新pod的调度,在Filter扩展点TaintToleration插件会检查污点
// Filter invoked at the filter extension point.
func (pl *TaintToleration) Filter(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
if nodeInfo == nil || nodeInfo.Node() == nil {
return framework.AsStatus(fmt.Errorf("invalid nodeInfo"))
}
filterPredicate := func(t *v1.Taint) bool {
// PodToleratesNodeTaints is only interested in NoSchedule and NoExecute taints.
return t.Effect == v1.TaintEffectNoSchedule || t.Effect == v1.TaintEffectNoExecute
}
taint, isUntolerated := v1helper.FindMatchingUntoleratedTaint(nodeInfo.Node().Spec.Taints, pod.Spec.Tolerations, filterPredicate)
if !isUntolerated {
return nil
}
errReason := fmt.Sprintf("node(s) had taint {%s: %s}, that the pod didn't tolerate",
taint.Key, taint.Value)
return framework.NewStatus(framework.UnschedulableAndUnresolvable, errReason)
}
如果新创建的pod没有声明容忍memory-pressure污点,会有如下报错,导致pod调度失败
I1210 12:43:04.147715 92808 scheduler.go:351] "Unable to schedule pod; no fit; waiting" pod="default/nginx-demo3-574cdd99c7-lwk9x" err="0/2 nodes are available: 1 node(s) had untolerated taint {node.kubernetes.io/memory-pressure: }, 1 node(s) had untolerated taint {node.kubernetes.io/unreachable: }. preemption: 0/2 nodes are available: 2 Preemption is not helpful for scheduling."
b. 即使新建pod能调度成功,在目标node上也需要经过canAdmitPod检查后才能允许此pod运行在此node上,调用链如下
HandlePodAdditions -> canAdmitPod -> podAdmitHandler.Admit
evictionManager的Admit会检查node健康状态m.nodeConditions,如果为空说明没有资源压力,可直接返回true,如果是CriticalPod也返回true,如果只有内存压力,会根据pod的qos级别进行区分,如果不是besteffort的pod也返回true,是besteffort的pod如果可以容忍内存压力也可以,但如果不是内存压力就返回false,即pod不能运行在此node上
// Admit rejects a pod if its not safe to admit for node stability.
func (m *managerImpl) Admit(attrs *lifecycle.PodAdmitAttributes) lifecycle.PodAdmitResult {
m.RLock()
defer m.RUnlock()
//node健康状态集合为空,说明没有资源压力,可直接返回true
if len(m.nodeConditions) == 0 {
return lifecycle.PodAdmitResult{Admit: true}
}
//CriticalPod也返回true
// Admit Critical pods even under resource pressure since they are required for system stability.
// https://github.com/kubernetes/kubernetes/issues/40573 has more details.
if kubelettypes.IsCriticalPod(attrs.Pod) {
return lifecycle.PodAdmitResult{Admit: true}
}
//有且只有内存压力
// Conditions other than memory pressure reject all pods
nodeOnlyHasMemoryPressureCondition := hasNodeCondition(m.nodeConditions, v1.NodeMemoryPressure) && len(m.nodeConditions) == 1
if nodeOnlyHasMemoryPressureCondition {
//获取pod的qos级别
notBestEffort := v1.PodQOSBestEffort != v1qos.GetPodQOS(attrs.Pod)
//非BestEffort的pod返回true
if notBestEffort {
return lifecycle.PodAdmitResult{Admit: true}
}
//如果能容忍内存压力也返回true
// When node has memory pressure, check BestEffort Pod's toleration:
// admit it if tolerates memory pressure taint, fail for other tolerations, e.g. DiskPressure.
if v1helper.TolerationsTolerateTaint(attrs.Pod.Spec.Tolerations, &v1.Taint{
Key: v1.TaintNodeMemoryPressure,
Effect: v1.TaintEffectNoSchedule,
}) {
return lifecycle.PodAdmitResult{Admit: true}
}
}
//其他情况均返回false
// reject pods when under memory pressure (if pod is best effort), or if under disk pressure.
klog.InfoS("Failed to admit pod to node", "pod", klog.KObj(attrs.Pod), "nodeCondition", m.nodeConditions)
return lifecycle.PodAdmitResult{
Admit: false,
Reason: Reason,
Message: fmt.Sprintf(nodeConditionMessageFmt, m.nodeConditions),
}
}
参考
https://kubernetes.io/docs/concepts/scheduling-eviction/node-pressure-eviction/#eviction-thresholds
https://github.com/kubernetes/design-proposals-archive/blob/main/node/kubelet-eviction.md