引言
Redis是一款基于键值对的数据结构存储系统,它的特点是基于内存操作、单线程处理命令、IO多路复用模型处理网络请求、键值对存储与简单丰富的数据结构等等
这篇文章主要围绕Redis中的对象与数据结构来详细说明键值对存储与简单丰富的数据结构这两大特点
Redis中的数据以Key,Value键值对的形式存储在字典中,字典的实现是哈希表
键Key只能使用字符串对象来表示,值Value能够使用其他所有对象
对象与数据结构
Redis中存在丰富的对象,常用的对象(数据类型)有字符串对象string、列表对象list、散列对象hash、集合对象set、有序集合对象zset等
还有其他的数据类型如Bitmap、Hyperloglog、Geospatial、布隆过滤器等,但这篇文章只涉及常用的对象,其他数据类型再以后的文章中再展开说明
-
redis中的对象RedisObject由类型、编码、引用次数、lru、指向编码使用的数据结构对象构成
-
类型标识这个对象是什么类型对象
-
比如字符串、列表、哈希、集合、有序集合等
-
编码表示构成对应类型对象时使用哪种数据结构
-
引用次数表示这个对象被引用了多少次
-
redis内存回收使用引用计数法,回收引用次数为0的对象 redis只依赖字符串对象,而不存在循环依赖所以不存在循环引用,因此可以使用引用计数法
-
lru记录这个对象最近被调用的时间,当空间回收算法使用lru时会优先回收很久未用的对象(后续删除回收的文章会介绍)
数据结构
sds简单动态字符串
sds使用字节数组维护,len记录字符串长度(表示结尾的'\0'不算),free表示字节数组中空闲的长度
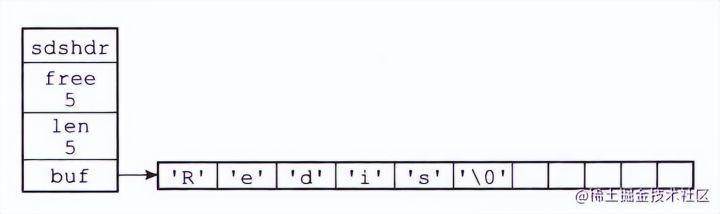
在添加元素前会判断数组长度是否足够,不够则会进行扩容;扩容有空间预分配策略,会留有一部分空闲空间
如果下次修改字符串未超出数组长度就能够直接修改,节省了扩容的开销
hashtable字典
字典使用哈希表实现,哈希表的原理本篇文章不会详细概述
哈希冲突使用链地址法解决,查找时先通过 hash%数组长度-1 来获取索引,得到索引后再遍历链表节点,如果是新增则直接使用头插法,插入链表头部

为了防止大字典扩容时发生阻塞,字典中哈希表的扩容是循序渐进的,在发生扩容时会有俩个哈希表

旧哈希表和新哈希表中都可能存储数据,再收到hget等请求时先在旧哈希表中查找,找到了就顺便把它迁移到新哈希表中;在旧哈希表中没找到就去新哈希表中找
在完成迁移时,新哈希表将旧哈希表替换
skiplist跳表
跳表维护多层级的有序链表,利用高层能够快速达到后续节点,实现简单,维护方便,增删改查时间复杂度平均log n

比如查找值为2.0的节点,查找顺序为图中虚线
先找到虚拟头节点,从当前维护的最高层(L5)开始寻找,往后找到o3对象值为3.0,说明已经找过头了,于是要去下一层进行寻找;来到L4先后遍历,o1对象值为1.0,比目标值2.0小,说明没有目标值在o1对象后面,于是来到o1对象L4层;继续在o1对象L4向后遍历,发现o3值为3.0大于目标值,于是降层来到o1对象L3层;L3层后面也是o3于是继续降层,来到L2层,L2层向后遍历为o2对象,值为2.0并比较o2对象相同说明找到了
从维护的最高层开始查询,查询为空或者查询值大于目标值则降层,当前在最后一层还需要降层说明找不到
当排序值相同时,按照对象大小排序,这里的对象都是字符串对象
增加节点时的层数是随机生成的,越高层几率越小;其他修改操作,也是通过查询再进行,同时还要维护一些如最高层级等其他属性
intset整数集合
intset 维护了一个有序,无重复的数组
在实现上使用数组、长度(记录元素数量)和编码(编码能够标识元素类型,如16、32、64位的整型)

当加入的元素为当前数组内不存在的高位整型时(比如数组中都是32位整型,此时加入一个64位整型)发生升级:先申请内存重分配,再将旧元素移动到对应位置上,然后加入新元素同时修改编码,当删除高位整型时不会发生降级
intset的升级有效的节约内存,当set对象都为整型且数据量较小时使用intset实现以此来节约内存
ziplist压缩列表
ziplist用连续空间的节点构成,节点由记录前驱节点偏移量(逆序遍历)、编码(字节数组或整型的编码)、内容(内容可以是字节数组或整型)组成

因为ziplist的内容不是固定的,比如记录前驱节点偏移量是可变长的,这会影响节点的长度,又因为ziplist是空间连续的,这会导致后续的节点空间都要变动,被称为连锁更新(发生的概率小)
为了节省空间,用于数量量小场景下列表、哈希、有序集合的实现
quicklist快速列表
快速列表可以当作双向链表,只不过节点使用ziplist,常用来实现数据量大场景下的列表对象
对象
说明:
下文中数据量代表着占用字节情况和数据元素数量
本篇文章不介绍各个对象的命令使用规则,需要学习命令的同学可以去官网查看
字符串对象
字符串对象string由sds简单动态字符串来实现
-
sds有不同的编码:int、embstr、row
-
int 用来存储整型字符串,计算时可能发生整型与字符串的转换
-
embstr 用来存储短的字符串,只分配一次内存,分配内存时同时分配redisobject和sds
-
row 用来存储长字符串,分配内存时需要分配两次:redisobject、sds
字符串对象是Redis中最常用的对象,也是唯一会被其他对象依赖使用的对象
字符串对象常见的使用场景:整存整取的缓存、计数器、分布式锁
列表对象
列表对象list是一个队列,可以操作队头队尾,由ziplist或quicklist来实现
数据量小时使用ziplist,数据量大时使用quicklist( linkedlist+ziplist )
列表的使用场景是FIFO队列保证元素访问顺序
哈希对象
哈希对象hash是维护KV键值对的无序数据结构,由ziplist或hashtable来实现
数据量少使用ziplist、数据量大使用hashtable
哈希的使用场景是缓存的部分存取(比如一个大礼包下有A商品B商品等)
集合对象
集合对象set的特点是无序、无重,由intset或hashtable来实现
数据量少且数据为整型使用intset、数据量大或数据不为整型使用hashtable且值永远为null
集合的使用场景是唯一性元素或交集并集(共同关注、可能认识)等(无序、无重复)
有序集合对象
有序集合对象zset是有序、无重的数据结构,由ziplist或skiplist + hashtable实现
数据量少时使用ziplist、数据量大时使用skiplist + hashtable(为了满足根据对象查询分指常量级功能,共享对象,不造成内存开销)
有序集合的使用场景是排行榜、关注程度榜单等(有序、无重复)
总结
本篇文章围绕Redis以键值对存储、丰富多元的数据结构为特点详细介绍了Redis中的对象与数据结构
对象由类型、编码、数据结构指针等构成
为了节省空间,每种类型的对象都有多种编码类型的数据结构能够实现
-
字符串对象常用来做缓存、分布式锁、计数器等,被其他对象依赖使用
-
由sds实现主要有int、embstr、row三种编码来处理不同类型的字符串,embstr处理短字符串优化内存分配
-
sds是动态字符串,利用空间预分配策略在修改不超过数组长度情况下可以不需要进行扩容,节省开销
-
列表对象常用来维护队列元素有序性
-
当数据量小时使用压缩列表ziplist实现,数据量大时使用快速列表quicklist实现
-
压缩列表使用连续空间,节点中存储可以时字符串也可以是整型
-
快速列表则可以当作链表,节点为压缩列表
-
哈希对象常用来维护部分存取的缓存
-
当数据量小时使用压缩列表zpilist实现,数据量大时使用哈希表hashtable实现
-
哈希表为了防止阻塞,在扩容时使用新旧两个哈希表存储元素,在处理命令的同时完成迁移
-
集合对象有无序、无重的特点,常用来做唯一、交集(共同好友)、并集(可能认识)
-
当数据量小且元素都为整型时使用整型集合intset实现,当数据量大使用哈希表实现
-
整型集合有不同的编码形式,充分节省了空间;使用哈希表时Value为空
-
有序集合对象有有序、无重的特点,常用来做排行榜
-
当数据量小时使用压缩列表实现;当数据量大时使用跳表skiplist+哈希表实现,哈希表保存K对象V比较值
-
跳表是多层级有序的链表,平均时间复杂度在log n,简单易维护



![[附源码]JAVA毕业设计医院管理系统(系统+LW)](https://img-blog.csdnimg.cn/13f401b6c6784d89aeb272baf962f2e0.png)
![[oeasy]python0028_直接运行_修改py文件执行权限_设置py文件打开方式](https://img-blog.csdnimg.cn/img_convert/0b387a7e4585d2722586c8b1e0376447.png)