随着ChatGPT的推出,通用人工智能的时代缓缓拉开序幕。我们第一次看到市场在追求人工智能开发者,而不是以往的开发者寻找市场。每一个企业都有大量的数据,私有的用户数据,自己积累的行业数据,产品数据,生产线数据,市场数据,等等一应俱全。这些数据都不在基础大语言模型的记忆里,如何有效的用起来是目前通用人工智能在企业端的重要课题。
我们可以将私有数据作为微调语料来让大语言模型记住新知识,这种方法虽然可以让大模型更贴近企业应用场景更高效使用私有数据,但往往难度较大,另外企业数据涵盖了文本,图像,视频,时序,知识库等模态,接入单纯的大语言模型学习效果较差。我们今天来聊聊另一种更常见的方案,通过矢量数据库提取相关数据,注入到用户prompt context(提示语境)里,给大语言模型提供充分的背景知识进行有效推理。【如图一所示】
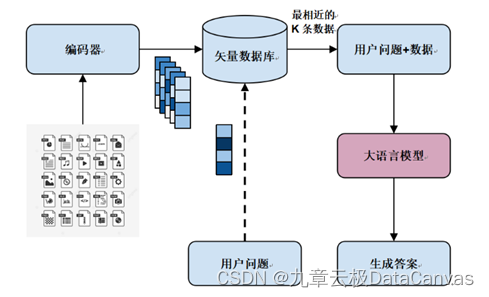
图一 基于数据提取的大语言模型应用架构
矢量数据库允许任何对象以矢量的形式表达成一组固定维度的数字,可以是一段技术文档,也可以是一幅产品配图。当用户的提示包含了相似语义的信息,我们就可以将提示编码成同样维度的矢量,通过矢量数据库查寻K-NearestNeighbor(近邻搜索)来获得相关的对象。Approximate NearestNeighbor(近似近邻搜索)作为矢量数据库的核心技术之一,在过去的十年里获得了长足进步。它可以通过损失一定的准确度在高维空间里快速搜索近邻矢量,比如NGT算法可以在接近一千维的矢量空间达到万次查询,而准确度不低于99%。如图二所示不同的算法展现了不同的妥协效果。
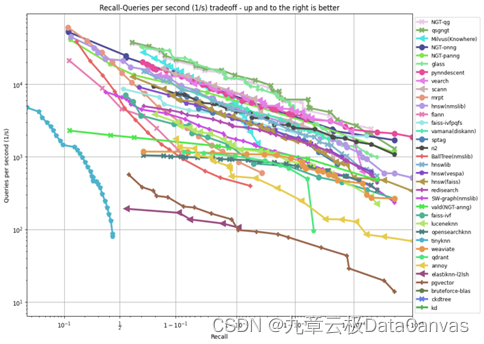
图二 查询QPS和返回准确度(召回)之间的妥协。数据集为fashion-mnist采用了784维矢量,
测试基于单个CPU的统一环境,测试时间为2023年四月。
这种语义搜索的方法起源于大语言模型时代之前,起初是为了降低企业搜索的工程复杂度,提升搜索结果的相关性,因为矢量本身和神经网络高度契合,也成为大语言模型应用的标准配置。甚至出现如Memorizing Transformer 和 KNN-LM这样的架构将近邻搜索算法和大语言模型结合来成功构造快速external memory(外部记忆)。
但是这样的架构依然存在一个重要的问题:从用户的提示生成矢量,通过近邻搜索找到有关数据,这两方面的矢量相似度高并不一定代表语义的相关性也高,因为两方的矢量可能并不在同一语义空间。如果企业数据的语义空间和大语言模型有比较大的区别,图一所示的架构就可能无法有效的关联重要数据而降低了可用性。这种语义空间差别在处理多模态数据时尤其明显,比如从文本到图像的对齐【如图三】,从文本到知识图谱的对齐【如图四】。同时,图像,视频,知识图谱,文档等等都蕴含大量的信息,压缩到单一矢量大大损失颗粒度,从而降低了近邻搜索的有效性。
如果将这些对象碎片化处理,再由大语言模型进行整合,除了复杂的碎片化工程,这种方法大大增加了提示语境的长度要求。尽管大量的研究工作已经从计算效率上解决了语境长度的瓶颈,比如Linear Transformer,Reformer,到最近的LongNet,理论上1B的Token已经是可行的,但实际的效果却显示当前的大语言模型并不能很好的利用长语境来获得相关信息【如图五】。归根结底将大量背景信息有效高效的投射到文本语义空间从而让后端的大语言模型可以更好发挥依然是目前应用开发的一大难点。
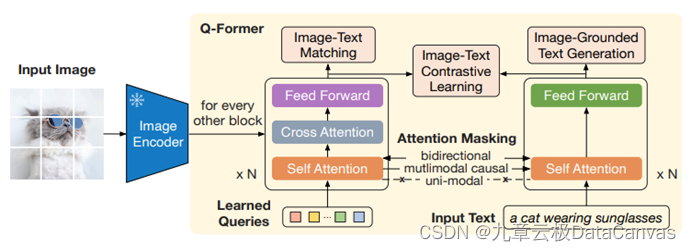
图三 图像文本通过交叉注意力机制对齐。借用BLIP2架构图
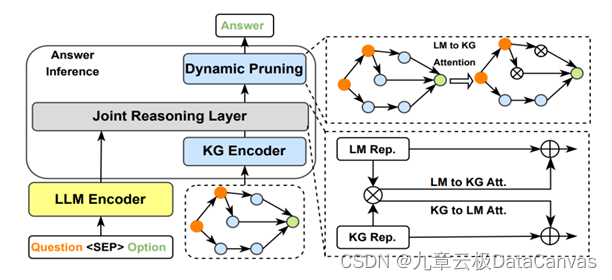
图四 知识图谱和文本通过交叉注意力机制对齐。借用动态知识图谱融合模型
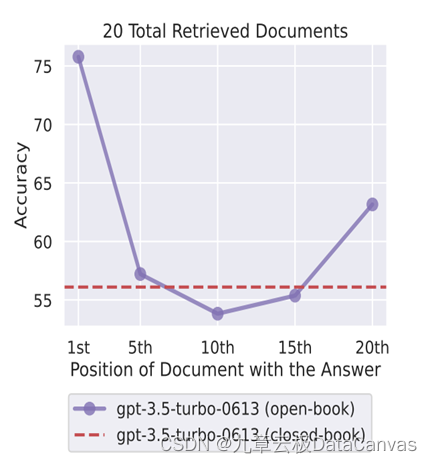
图五 相关的文档在提示语境中的位置会极大影响大语言模型的能力。来自于最近的研究
语义空间的投射可以看作是一个alignment(对齐)任务。在粗颗粒度上,单一矢量的空间对齐可以通过学习投射矩阵来实现【如图六所示】。这个投射空间小,可以用较少的标注数据训练,从而大大提升搜索结果的相关性,也已经成为业界广泛使用的技术。而细粒度的对齐工作依然是目前技术突破的焦点,从Perceiver IO,CLIP到BLIP2,我们也渐渐看到交叉注意力机制的通用对齐能力【如图三,四】,特别是大规模的无监督学习半监督学习大大提升了对齐的泛化能力。把这些对齐算法和矢量数据库结合起来提供快速高效的细粒度对齐将会极大提升大语言模型应用的用户体验,也是我们值得期待的方向。
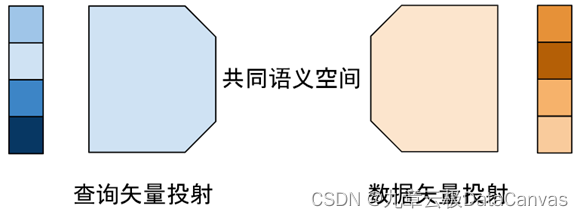
图六 粗粒度对齐
总体而言,通过矢量数据库将企业内部数据和大语言模型结合起来拥有广泛的应用场景,但技术挑战也仍然很大,我们今天讨论的这些技术点仅仅是诸多挑战中的一两个环节,还有很多没有触碰,后面有机会和大家继续探讨。
参考资料:
1.https://github.com/erikbern/ann-benchmarks
2.https://arxiv.org/pdf/1911.00172.pdf
3.https://arxiv.org/pdf/2203.08913.pdf
4.https://arxiv.org/pdf/2006.16236.pdf
5.https://arxiv.org/pdf/2001.04451.pdf
6.https://arxiv.org/pdf/2307.02486.pdf
7.https://arxiv.org/pdf/2301.12597.pdf
8.https://arxiv.org/pdf/2306.08302.pdf
9.https://arxiv.org/pdf/2307.03172.pdf
10.https://finetunerplus.jina.ai/
11.https://github.com/krasserm/perceiver-io
12.https://arxiv.org/pdf/2103.00020.pdf
13.https://arxiv.org/pdf/2301.12597.pdf
作者简介:
缪 旭 九章云极DataCanvas公司首席AI科学家
二十余年人工智能研究和管理经验,深耕人工智能的技术实现和应用,发表多篇学术文章,并拥有多项授权发明,专注将可推理可解释的人工智能、大模型、大规模实时机器学习、知识图谱等前沿AI技术加速应用于各行各业。


![[OnWork.Tools]系列 03-软件设置](https://img-blog.csdnimg.cn/img_convert/08b1963b35cff3172a28944e2da912a1.png)