文章目录
- MLP-Mixer: An all-MLP Architecture for Vision
- 摘要
- 本文方法
- 代码
- 实验结果
MLP-Mixer: An all-MLP Architecture for Vision
摘要
卷积神经网络(cnn)是计算机视觉的首选模型。
最近,基于注意力的网络,如VIT,也变得流行起来。在本文中,我们证明了虽然卷积和注意力对于良好的性能都是足够的,但它们都不是必需的。我们提出了MLP-Mixer,一种完全基于多层感知器(mlp)的架构。
MLP-Mixer包含两种类型的层:一种是独立应用于图像补丁的mlp(即“混合”每个位置的特征),另一种是跨补丁应用的mlp(即“混合”空间信息)。当在大型数据集上训练或使用现代正则化方案时,MLP-Mixer在图像分类基准上获得了具有竞争力的分数,其预训练和推理成本与最先进的模型相当。我们希望这些结果能激发进一步的研究,超越已经建立的cnn和transformer领域
代码地址
本文方法
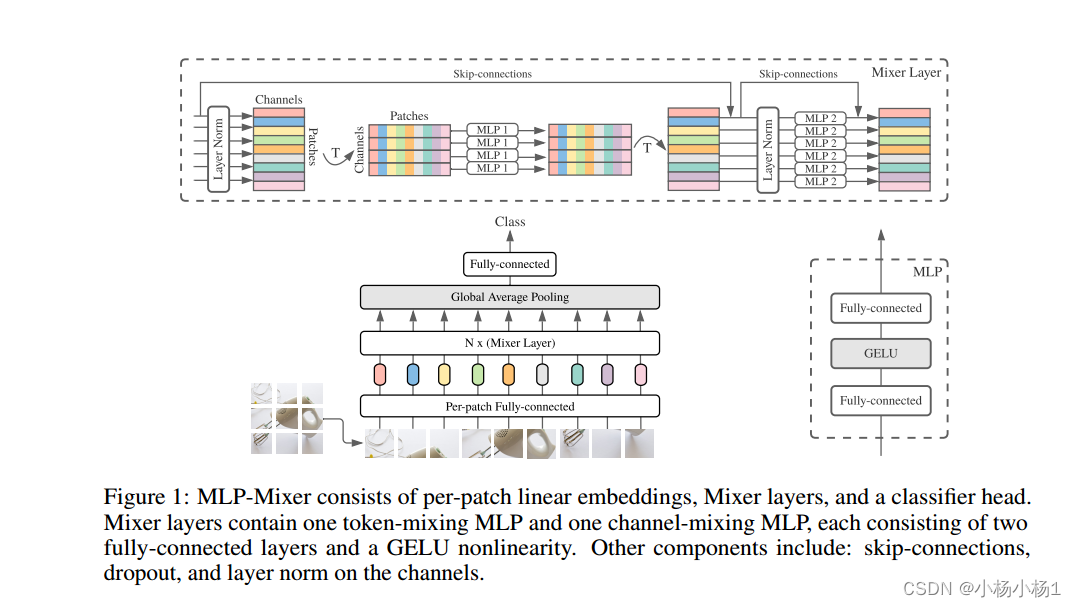
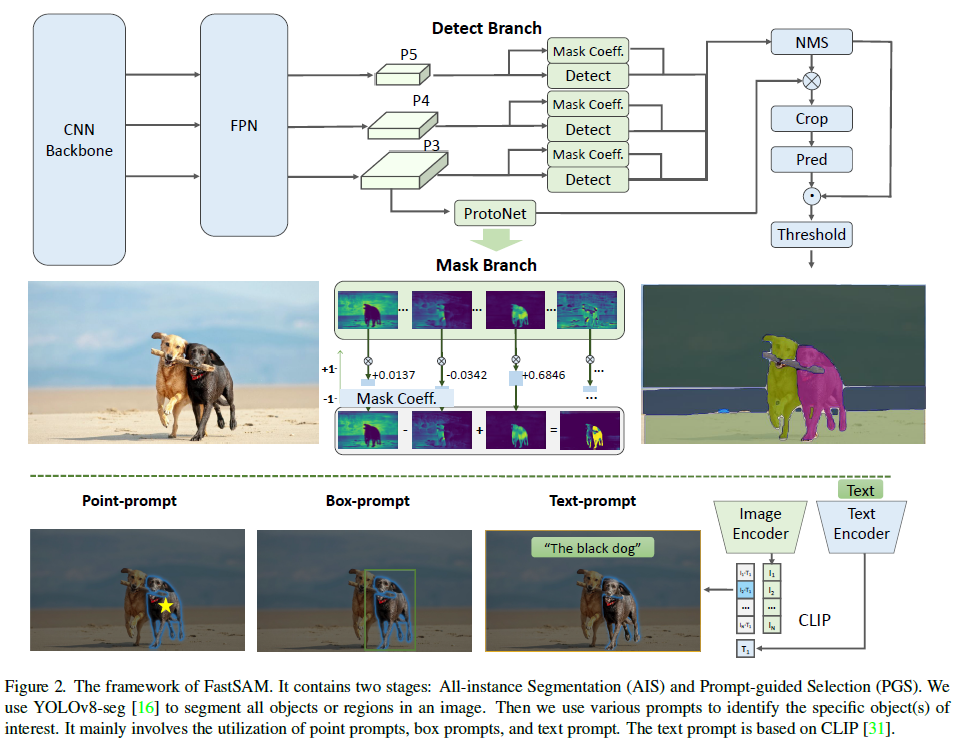
MLP-Mixer由每个patch线性嵌入、Mixer层和分类器头组成。
混合层包含一个令牌混合MLP和一个通道混合MLP,每个MLP由两个完全连接的层和一个GELU非线性组成。其他组件包括:通道上的跳过连接、退出和层规范。
总的来说就是,基于通道的和基于patch的MLP,然后增加跳跃连接
代码
class MlpBlock(nn.Module):
mlp_dim: int
@nn.compact
def __call__(self, x):
y = nn.Dense(self.mlp_dim)(x)
y = nn.gelu(y)
return nn.Dense(x.shape[-1])(y)
class MixerBlock(nn.Module):
"""Mixer block layer."""
tokens_mlp_dim: int
channels_mlp_dim: int
@nn.compact
def __call__(self, x):
y = nn.LayerNorm()(x)
y = jnp.swapaxes(y, 1, 2)
y = MlpBlock(self.tokens_mlp_dim, name='token_mixing')(y)
y = jnp.swapaxes(y, 1, 2)
x = x + y
y = nn.LayerNorm()(x)
return x + MlpBlock(self.channels_mlp_dim, name='channel_mixing')(y)
代码非常简单,就是一个轴交换然后相加得到的最后结果
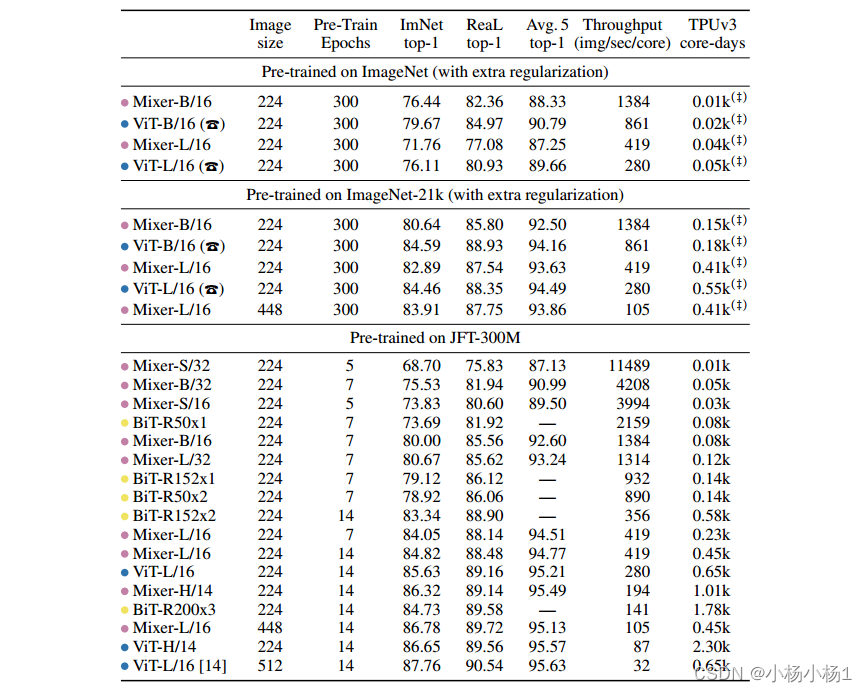
实验结果