时序数据,作为一种时间上有序的数据形式,无疑是我们日常生活中最常见的数据类型之一。它记录了事件、现象或者过程随时间的变化,是对于许多实际场景的忠实反映。而在众多时序数据的应用领域中,跑步训练记录莫过于是一项令人着迷的话题。
跑步,作为一项简单又充满挑战的运动,吸引着众多跑者不断挑战自我,突破极限。从晨跑的第一缕阳光,到夜跑的璀璨星空,每一次脚步都是一段关于自己的时刻记录。随着跑步的发展,越来越多的跑者开始利用技术手段记录自己的训练数据,而这些数据正是构成了一份宝贵的时序数据集。
在这个时序数据集中,我们不仅能够了解每次跑步的时间、距离、配速等基本信息,还可以追踪每段训练的进步与成长。我们可以看到每天清晨的体能状态,记录自己在慢跑、短跑、长跑中的表现,了解不同训练方式对身体的影响。这些数据的背后,蕴含着跑者不断努力和坚持的足迹,也见证着训练计划的调整和优化。
而在这场时序数据的探索与分析中,Pandas 无疑是我们最得力的工具之一。Pandas 是 Python 中一个强大的数据处理库,它提供了灵活高效的数据结构和数据操作方法,让我们能够轻松地对时序数据进行各种操作、聚合、分析和可视化。
在本系列文章中,我们将带您一起探索 Pandas 在时序数据分析中的应用。我们将从如何加载和处理跑步训练记录开始,逐步深入探讨数据的清洗、转换、聚合和可视化。我们将学习如何从大量的时序数据中提取有价值的信息,识别趋势和周期性,评估训练效果,甚至利用机器学习方法预测未来的表现。
无论您是一位跑步爱好者,还是对时序数据分析感兴趣的数据科学家,本系列文章都将为您揭示时序数据分析的魅力。让我们一起踏上这段充满数据洞察力的跑步之旅,用数据为您的跑步训练增色添彩。让 Pandas 引领我们探索时序数据的无限可能!
1. Pandas
Pandas 是 Python 语言的一个强大的开源数据分析和数据处理扩展程序库,建立在 NumPy 之上,提供了更高级、更灵活的数据结构和数据处理工具。它是 Python 数据科学生态系统中最重要的库之一,广泛应用于数据清洗、转换、处理和分析等领域。Pandas 名字衍生自术语 “panel data”(面板数据)和 “Python data analysis”(Python 数据分析)。下面对 Pandas 的主要特点和功能进行系统的介绍:
-
数据结构: Pandas 提供了两种主要的数据结构:Series 和 DataFrame。
- Series:类似于一维数组,每个元素都有对应的索引,可以是任意数据类型。
- DataFrame:类似于二维表格,是由多个 Series 组成的数据结构,每列可以有不同的数据类型,同时具有行和列的索引。
-
数据导入与导出: Pandas 支持从各种数据源(如 CSV、Excel、数据库、JSON、HTML 等)中导入数据,并能将数据导出为不同的文件格式。
-
数据清洗和转换: Pandas 提供了丰富的数据清洗和转换功能,包括缺失值处理、重复值处理、数据类型转换、字符串操作、日期处理等。
-
数据选择和过滤: Pandas 允许根据条件对数据进行选择和过滤,支持布尔索引、位置索引、标签索引等多种方式。
-
数据聚合和分组: Pandas 提供了灵活的数据聚合和分组操作,可以进行统计计算、分组汇总、透视表等复杂数据分析。
-
数据合并和拼接: Pandas 可以方便地将多个数据集进行合并和拼接,支持多种连接方式(如内连接、外连接、左连接、右连接)。
-
时间序列处理: Pandas 对时间序列数据有很好的支持,可以进行时间索引、时间频率转换、滚动窗口计算等。
-
数据可视化: Pandas 结合 Matplotlib 和 Seaborn 等库,提供了简单易用的数据可视化功能,帮助用户快速生成各种图表。
-
高级应用: 学习一些高级的 Pandas 应用技巧,如使用 apply 函数、使用自定义函数进行数据处理等。
-
性能优化: 了解如何优化 Pandas 的性能,包括避免使用循环,使用向量化操作,使用合适的数据类型等,提高数据处理效率。
Pandas 的优势在于它提供了高效灵活的数据结构和操作方法,使得数据处理变得简单快捷。无论是进行简单的数据转换,还是进行复杂的数据分析,Pandas 都能为数据科学家和分析师提供强大的支持。同时,Pandas 社区非常活跃,不断有新的功能和改进被加入进来,保持着它的领先地位。
2. Jupyter
Jupyter 是一个非常流行的交互式计算和数据科学环境,它支持多种编程语言,但最常用的是 Python。Jupyter 的名字由三个编程语言的缩写组成:Julia、Python 和 R,它们都是在 Jupyter 中的支持语言。主要特点包括:
-
交互性: Jupyter 提供了一个交互式的计算环境,用户可以一边编写代码,一边查看运行结果。代码可以逐行执行,方便调试和快速尝试不同的方法。
-
Notebook: Jupyter Notebook 是 Jupyter 的主要界面。它是一个 Web 应用程序,允许用户创建和共享包含代码、文本、图像和交互式图表的文档。Notebook 支持 Markdown 和 LaTeX 语法,可以创建富文本的笔记和报告。
-
多语言支持: Jupyter 支持多种编程语言,包括 Python、R、Julia、Scala、Haskell 等。用户可以根据需要选择合适的内核来运行代码。
-
数据可视化: Jupyter 集成了许多数据可视化工具,例如 Matplotlib、Plotly、Seaborn 等,可以轻松地在 Notebook 中展示图表和图像。
-
数据处理和分析: Jupyter 非常适合进行数据处理和分析工作,可以使用 Pandas、NumPy 等数据科学库进行数据处理,支持交互式数据分析和数据可视化。
-
教育和研究: Jupyter 在教育和研究领域得到广泛应用。教师和学生可以在 Notebook 中编写代码、做实验、记录笔记,研究人员可以用它来展示和共享研究成果。
-
扩展性: Jupyter 可以通过插件和扩展来增强功能,例如支持其他编程语言、增加新的图表库等。
-
云端支持: 许多云计算平台支持 Jupyter,用户可以在云端运行 Jupyter Notebook,不需要在本地安装任何软件。
总的来说,Jupyter 是一个非常强大、灵活和便捷的数据科学工具,它为数据科学家、程序员和研究人员提供了一个交互式的环境,方便他们进行数据分析、数据可视化和实验性编程。
3. 开发环境安装
在 Windows 10 环境下的安装和配置步骤:
3.1. 安装 Python:
访问 Python 官网(https://www.python.org/downloads/windows/)下载适用于 Windows 的 Python 安装程序。
打开安装程序,勾选 “Add Python x.x to PATH” 选项,点击 “Install Now” 完成安装。请注意,x.x 是你下载的 Python 版本号。
详细安装过程可以参考《Pandas高级数据分析快速入门之一——Python开发环境篇》内容。
3.2. 安装 Jupyter 和 Pandas:
打开命令提示符(CMD)或 PowerShell,输入以下命令分别安装 Jupyter 和 Pandas:
pip install jupyter
pip install pandas
注意:由于网络原因,境外可能速度较慢,推荐使用国内的镜像,例如清华镜像(https://pypi.tuna.tsinghua.edu.cn/simple),命令变为:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
3.3. 使用与配置 Jupyter Notebook
3.3.1. 配置Jupyter Notebook
首先,为Jupyter建立工作目录,例如使用”D:\01workspace\Jupyter_notework“为工作目录(自行手工创建)。
接着,运行产生系统配置文件命令,配置工作目录为系统可以识别(默认在python的命令目录下)。
python目录\Scripts>jupyter-notebook --generate-config
Writing default config to: C:\Users\Administrator\.jupyter\jupyter_notebook_config.py

注:Administrator,或你所使用的其他操作系统用户下。
用文本编辑器,打开“jupyter_notebook_config.py”文件,查找“notebook_dir”参数:c.NotebookApp.notebook_dir = ‘D:\01workspace\Jupyter_notework’
3.3.2. 启动 Jupyter Notebook
在命令提示符或 PowerShell 中,输入以下命令启动 Jupyter Notebook:
jupyter notebook
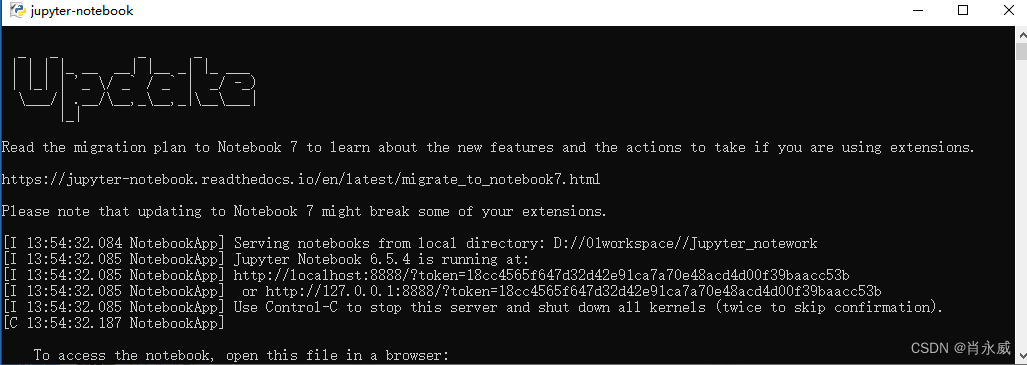
会自动打开一个浏览器窗口,显示 Jupyter Notebook 的界面。
注:Jupyter工具jupyter-notebook.exe在“python路径/Scripts”文件夹下,为了方便使用,可以在桌面创建快捷方式
3.3.3. 使用 Jupyter Notebook:
在 Jupyter Notebook 界面中,可以看到文件浏览器和 Notebook 列表。点击右上角的 “New”,选择 “Python 3” 创建一个新的 Python Notebook。在新的 Notebook 中,你可以编写代码、运行代码,并使用 Pandas 进行数据分析。

注意事项:
确保你的系统已经正确安装了 Python 和 pip,可以在命令行中输入 python --version 和 pip --version 来检查版本。
如果在安装 Jupyter 和 Pandas 时遇到权限问题,可以尝试使用管理员权限运行命令提示符或 PowerShell。
通过以上步骤,你可以在 Windows 10 环境下成功安装并配置 Jupyter 和 Pandas,开始使用它们进行数据分析和处理。
参考:
肖永威. Pandas高级数据分析快速入门之一——Python开发环境篇. CSDN博客. 2021.09








![[OnWork.Tools]系列 01-简介](https://img-blog.csdnimg.cn/img_convert/d89e6e99a5d77e46b3ac94b7542054cf.png)