目录
- 使用IDEA创建Spark项目
- 设置sbt依赖
- 创建Spark 项目结构
- 新建Scala代码
使用IDEA创建Spark项目
打开IDEA后选址新建项目
选址sbt选项
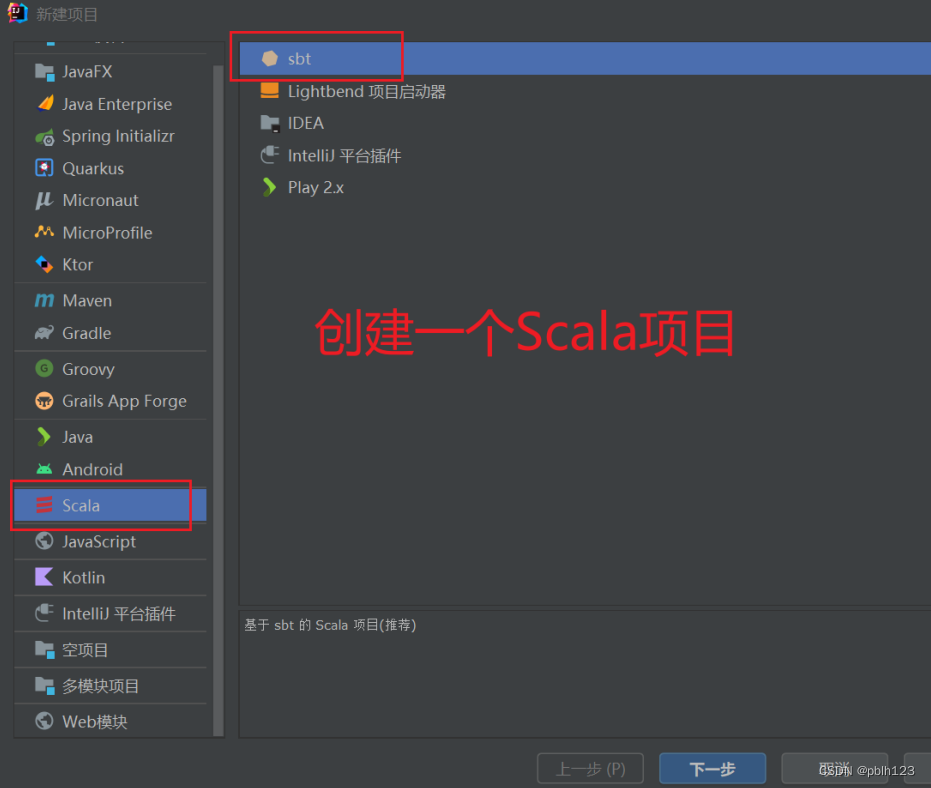
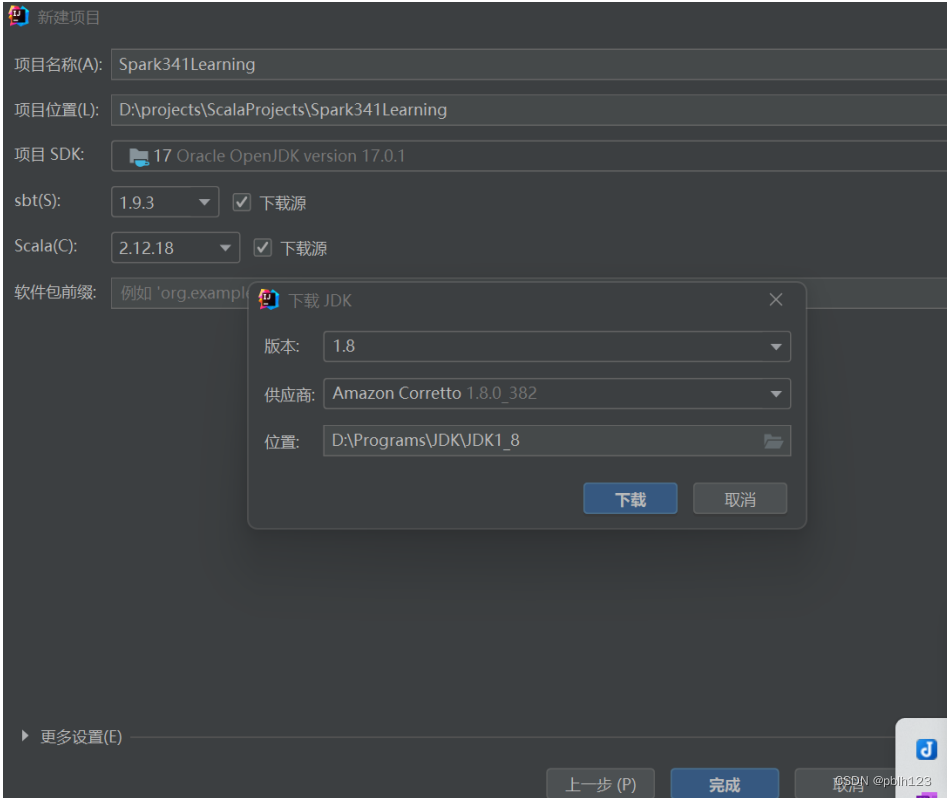
配置JDK
debug
解决方案
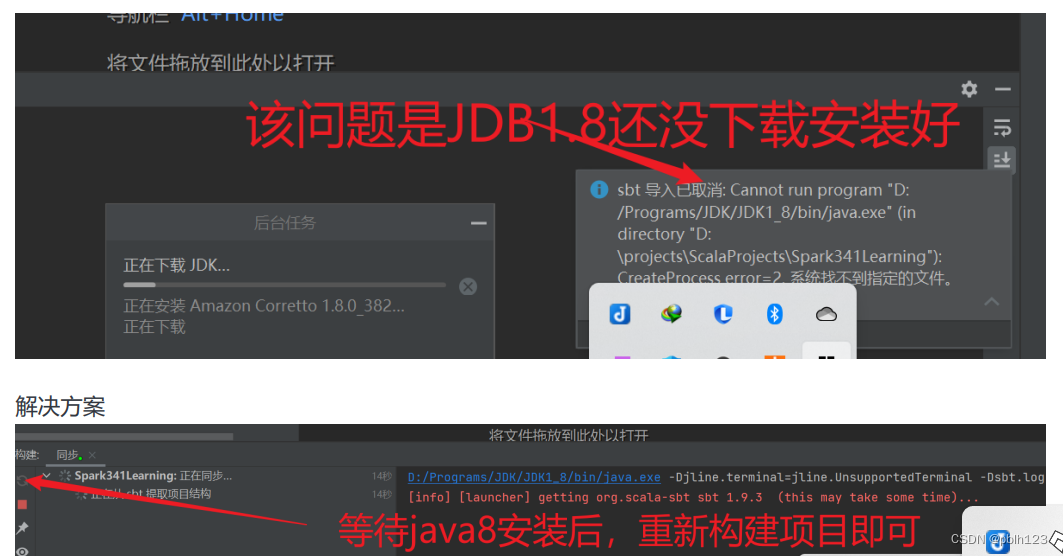
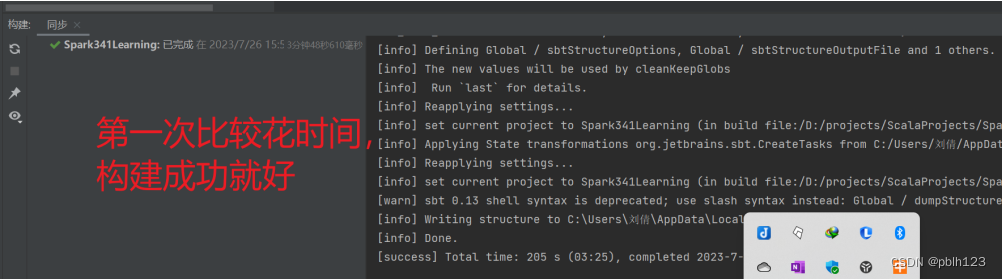
相关的依赖下载出问题多的话,可以关闭idea,重启再等等即可。
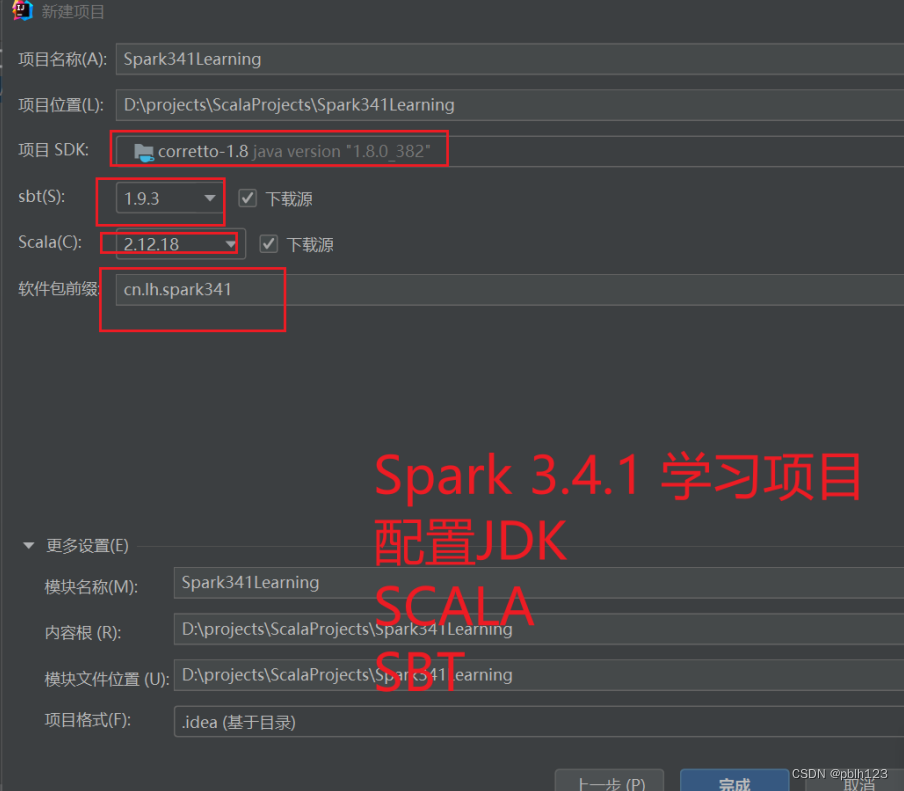
设置sbt依赖
- 将sbt源设置为国内源
- 基于sbt添加依赖
- spark-sql
- spark-core
ThisBuild / version := "0.1.0-SNAPSHOT"
ThisBuild / scalaVersion := "2.12.18"
lazy val root = (project in file("."))
.settings(
name := "Spark341Learning",
idePackagePrefix := Some("cn.lh.spark341"),
resolvers += "HUAWEI" at "https://mirrors.huaweicloud.com/repository/maven",
updateOptions := updateOptions.value.withCachedResolution(true),
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.4.1",
libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.4.1"
)
创建Spark 项目结构
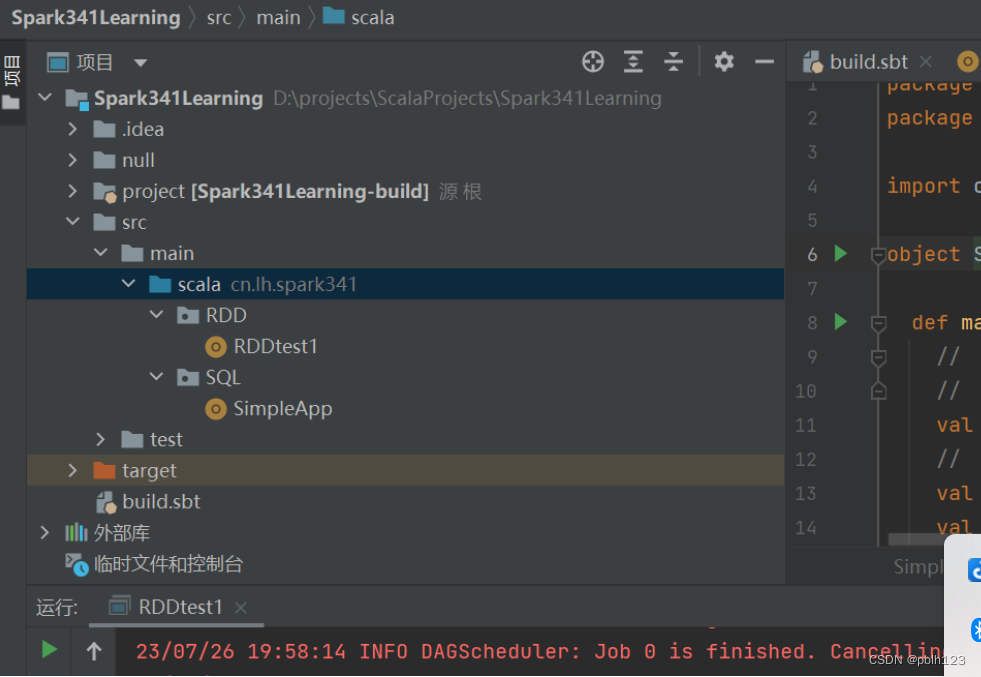
新建Scala代码
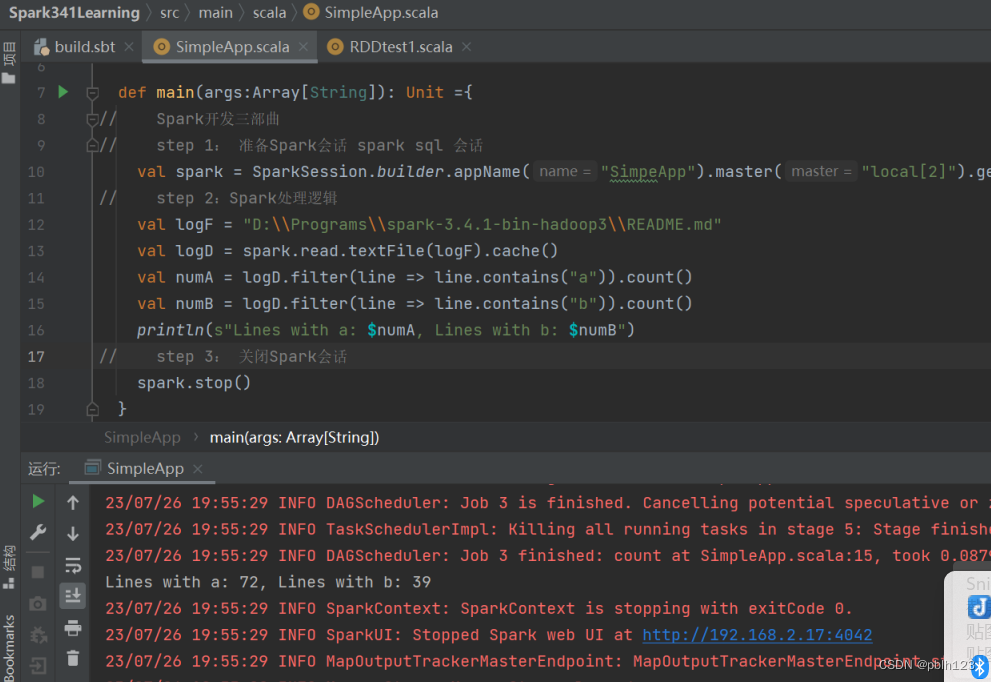
Spark sql simleapp代码如下:
package cn.lh.spark341
package SQL
import org.apache.spark.sql.SparkSession
object SimpleApp {
def main(args: Array[String]): Unit = {
// Spark开发三部曲
// step 1: 准备Spark会话 spark sql 会话
val spark = SparkSession.builder.appName("SimpeApp").master("local[2]").getOrCreate()
// step 2:Spark处理逻辑
val logF = "D:\\Programs\\spark-3.4.1-bin-hadoop3\\README.md"
val logD = spark.read.textFile(logF).cache()
val numA = logD.filter(line => line.contains("a")).count()
val numB = logD.filter(line => line.contains("b")).count()
println(s"Lines with a: $numA, Lines with b: $numB")
// step 3: 关闭Spark会话
spark.stop()
}
}
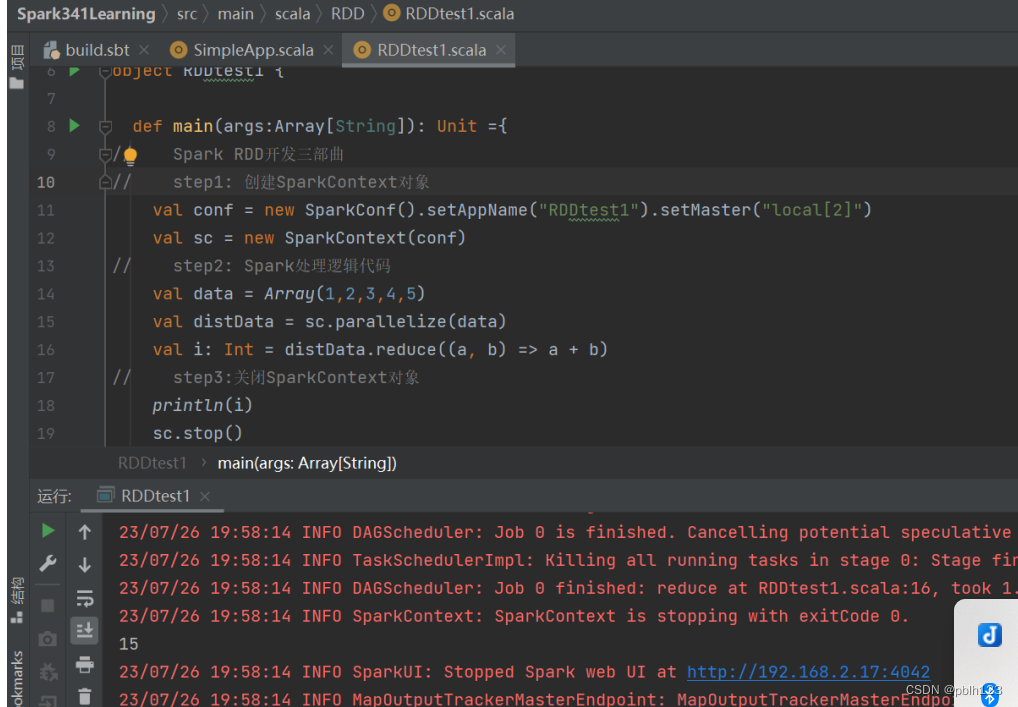
Spark RDD代码如下:
package cn.lh.spark341
package RDD
import org.apache.spark.{SparkConf, SparkContext}
object RDDtest1 {
def main(args:Array[String]): Unit ={
// Spark RDD开发三部曲
// step1: 创建SparkContext对象
val conf = new SparkConf().setAppName("RDDtest1").setMaster("local[2]")
val sc = new SparkContext(conf)
// step2: Spark处理逻辑代码
val data = Array(1,2,3,4,5)
val distData = sc.parallelize(data)
val i: Int = distData.reduce((a, b) => a + b)
// step3:关闭SparkContext对象
println(i)
sc.stop()
}
}
到此,基于Scala2.12.18开发Spark 3.4.1 项目完成。