SparkSql能做些啥
Spark SQL的核心概念是DataFrame,它是一个分布式的数据集合,类似于关系数据库中的表。支持使用SQL语言直接对DataFrame进行查询,提供了丰富的内置函数和表达式,可以用于数据的转换、过滤和聚合等操作,支持多种数据源,包括Hive、Avro、Parquet、ORC、JSON和JDBC等。它可以读取和写入这些数据源,并且还支持将非结构化数据转换为结构化数据.
Spark SQL在Hive兼容层面仅依赖HiveQL解析和Hive元数据,也就是说,从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责。
DataFrame与RDD的区别
DataFrame的推出,让Spark具备GH了处理大规模结构化数据的能力,不仅比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能。Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询。

如上图,DataFrame和RDD的区别,RDD是分布式的 Java对象的集合,比如,RDD[Person]是以Person为类型参数,但是,Person类的内部结构对于RDD而言却是不可知的。DataFrame是一种以RDD为基础的分布式数据集,也就是分布式的Row对象的集合(每个Row对象代表一行记录),提供了详细的结构信息,也就是我们经常说的模式(schema),Spark SQL可以清楚地知道该数据集中包含哪些列、每列的名称和类型。
和RDD一样,DataFrame的各种变换操作也采用惰性机制,只是记录了各种转换的逻辑转换路线图(是一个DAG图),不会发生真正的计算,这个DAG图相当于一个逻辑查询计划,最终,会被翻译成物理查询计划,生成RDD DAG,按照之前介绍的RDD DAG的执行方式去完成最终的计算得到结果。
SparkSession是什么
SparkSession是在Spark 2.0中引入的,作为替代SparkContext的新入口点。SparkSession是一个用于与Spark进行交互的主要入口,它封装了SparkContext、SQLContext和HiveContext的功能,并提供了更简洁、更一致的API。
SparkSession功能
创建DataFrame和DataSet:SparkSession提供了创建DataFrame和DataSet的方法,这些方法可以从各种数据源(如文件、数据库、Hive表等)中读取数据,并将其转换为分布式数据集合。
执行SQL查询:SparkSession允许使用Spark SQL模块提供的SQL语法来查询数据。它提供了SQL方法来执行SQL查询,并将结果返回为DataFrame。
集成Hive:SparkSession内置了对Hive的支持,可以直接执行HiveQL查询和操作Hive表。
与其他数据源的交互:SparkSession提供了用于读取和写入数据的方法,可以与各种数据源进行交互,如Parquet、Avro、JSON、CSV等。
如何创建DataFrame
例子1-已知Rdd创建DataFrame
代码
package SparkSQL
//从一个已知rdd创建DataFrame
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
object DataFrame_create {
def main(args:Array[String]):Unit = {
//创建sparksession
val spark = SparkSession.builder.appName("dataframe_create").master("local")
.getOrCreate()
//创建RDD
val rdd = spark.sparkContext.parallelize(Seq(("zhugeliang",48),("guanyu",40),("xiangyu",19)))
//定义schama
val schema = StructType((Seq(
StructField("name",StringType,nullable = true),
StructField("age",IntegerType,nullable = true))
))
//将RDD转化为Row对象
val rowRDD = rdd.map(row => Row(row._1,row._2))
//创建dataFrame
val df = spark.createDataFrame(rowRDD,schema)
//展示
df.show()
}
}
运行结果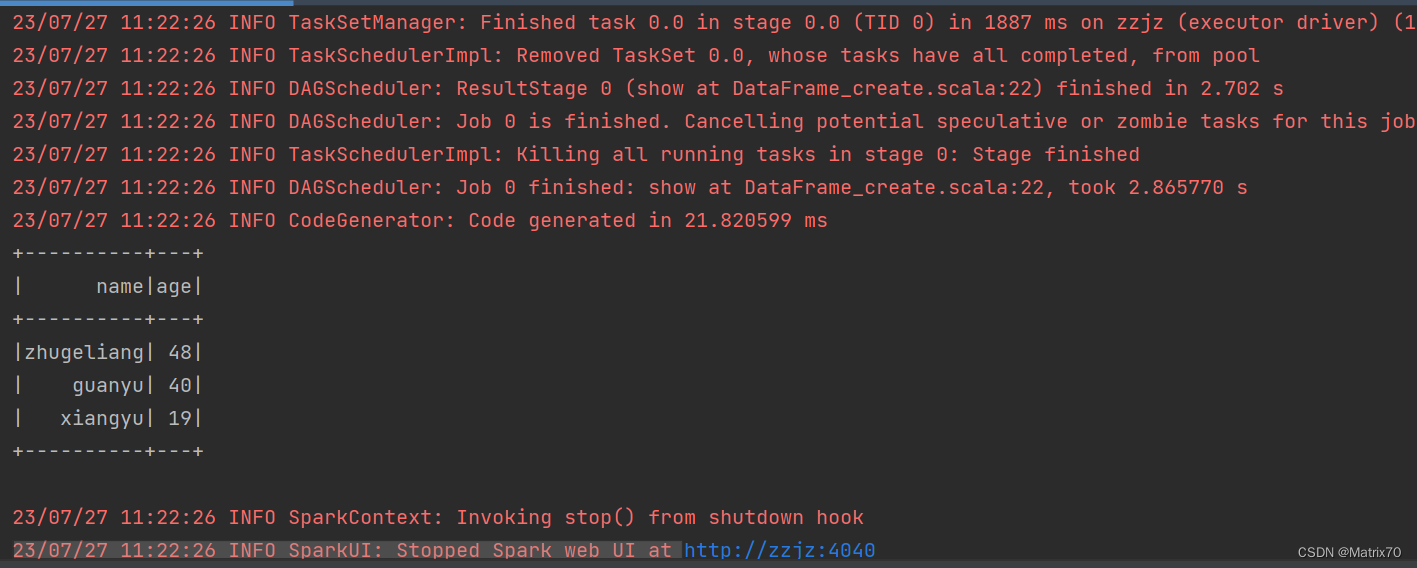
例子2-读取外部数据集创建DataFrame
代码
package Sparksql
// 读取json文件创建
import org.apache.spark.sql.SparkSession
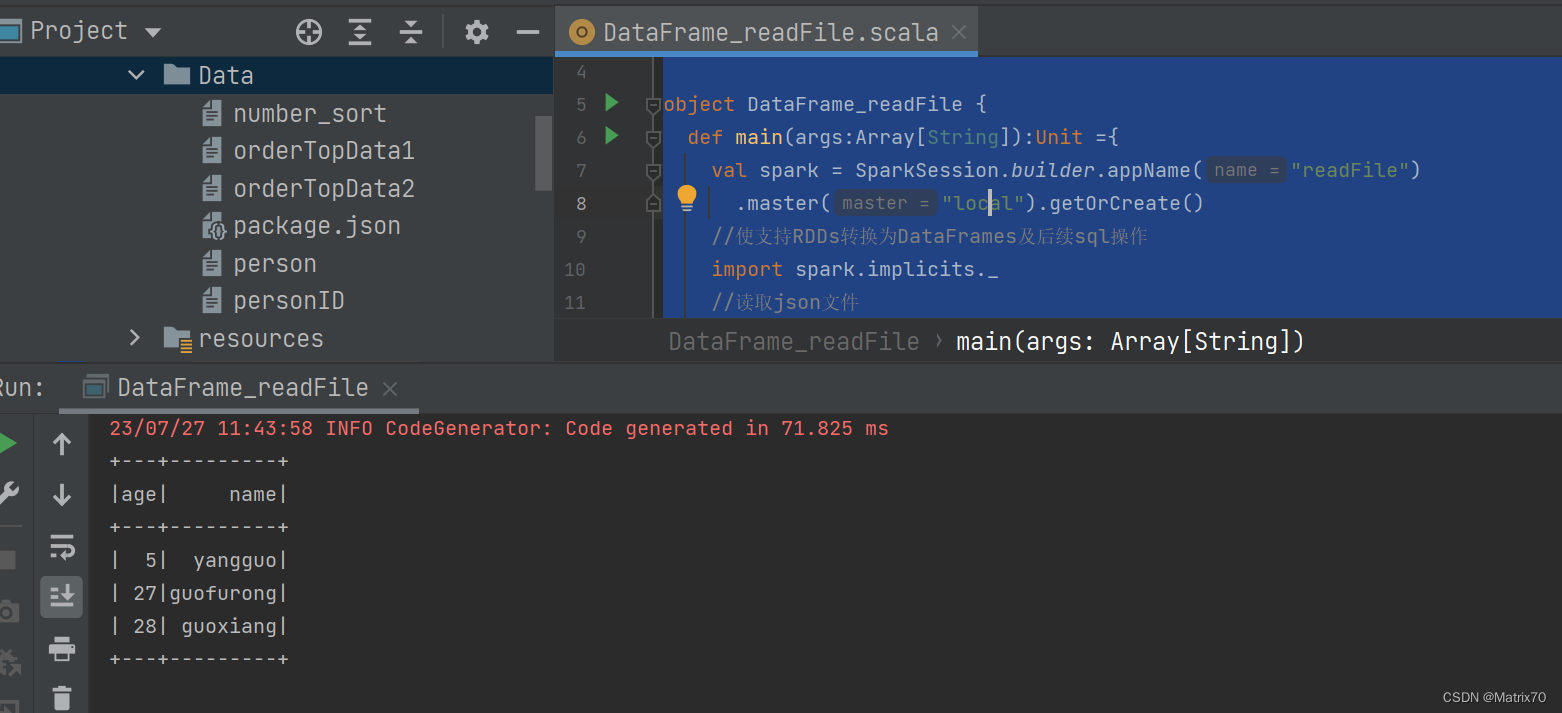
object DataFrame_readFile {
def main(args:Array[String]):Unit ={
val spark = SparkSession.builder.appName("readFile")
.master("local").getOrCreate()
//使支持RDDs转换为DataFrames及后续sql操作
import spark.implicits._
//读取json文件
val df = spark.read.json("D:\\workspace\\spark\\src\\main\\Data\\package.json")
//展示结果
df.show()
}
}
运行结果
例子3-编码创建DataFrame
代码
package Sparksql
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.Row
object DF_create_list {
def main(args:Array[String]):Unit ={
这里设置为local表示在本地运行
val spark = SparkSession.builder.appName("DF_list").master("local").getOrCreate()
//创建数据列表
val data = Seq(("libai",43,"changan"),("jushi",48,"newYork"),("xinge",28,"jinan"))
//定义schema
val schema = StructType(Seq(
StructField("name",StringType,nullable = true),
StructField("age",IntegerType,nullable = true),
StructField("city",StringType,nullable = true)
))
//将数据转换为row对象
val row = spark.sparkContext.parallelize(data).map{
case
(name,age,city) => Row(name,age,city)}
val df = spark.createDataFrame(row,schema)
df.show()
}
}
运行结果

注:DataFrame的模式(Schema)
代码定义了一个Spark SQL中DataFrame的模式(Schema),用于描述DataFrame中各列的名称和数据类型。
StructType(Seq(...))表示创建一个结构类型(StructType)对象,用于存储DataFrame的模式信息。
Seq(...)是一个包含多个元素的序列,每个元素都代表DataFrame的一个列。我们定义了三个列,分别是name、age和city。每个列都由StructField对象来表示,StructField的构造函数接受三个参数:列名、数据类型和是否可为空。
StructField("name", StringType, nullable = true):表示一个名为name的列,数据类型为StringType,可以为空。
StructField("age", IntegerType, nullable = true):表示一个名为age的列,数据类型为IntegerType,可以为空。
StructField("city", StringType, nullable = true):表示一个名为city的列,数据类型为StringType,可以为空。
即定义了一个包含三个列的模式,可以用于创建DataFrame。使用模式创建DataFrame时,可确保DataFrame的列具有正确的名称和数据类型。
常用DataFrame操作
我使用了例子3的DataFrame,在原基础上进行操作。
这里总结了日常使用中使用的DataFrame操作,主要有选择出多列进行打印,条件过滤,分组聚合,单列排序,多列排序,对列名进行重命名。
//打印df
df.show
+-----+---+-------+
| name|age| city|
+-----+---+-------+
|libai| 43|changan|
|jushi| 48|newYork|
|xinge| 28| jinan|
+-----+---+-------+
//打印模式信息
df.printSchema()
root
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
|-- city: string (nullable = true)
//选择多列
df.select(df("name"),df("age")+1).show()
+-----+---------+
| name|(age + 1)|
+-----+---------+
|libai| 44|
|jushi| 49|
|xinge| 29|
+-----+---------+
//条件过滤
df.filter(df("age") > 30).show()
+-----+---+-------+
| name|age| city|
+-----+---+-------+
|libai| 43|changan|
|jushi| 48|newYork|
+-----+---+-------+
//分组聚合
df.groupBy("age").count().show()
+---+-----+
|age|count|
+---+-----+
| 28| 1|
| 48| 1|
| 43| 1|
+---+-----+
//排序
df.sort(df("age").desc).show()
+-----+---+-------+
| name|age| city|
+-----+---+-------+
|jushi| 48|newYork|
|libai| 43|changan|
|xinge| 28| jinan|
+-----+---+-------+
//多列排序
df.sort(df("age").asc,df("city").asc).show()
+-----+---+-------+
| name|age| city|
+-----+---+-------+
|xinge| 28| jinan|
|libai| 43|changan|
|jushi| 48|newYork|
+-----+---+-------+
//对某列进行重名名
df.select(df("city").as("area"),df("age")).show()
+-------+---+
| area|age|
+-------+---+
|changan| 43|
|newYork| 48|
| jinan| 28|
+-------+---+DataSet
概念
Spark SQL and DataFrames - Spark 2.2.3 Documentation,看官网
DataSet、DataFrame、RDD之间的关系

参考文章:
Spark2.1.0入门:DataFrame的创建_厦大数据库实验室博客,林子雨教授
Spark RDD(Resilient Distributed Datasets)论文 - 【布客】Spark 中文翻译
Spark SQL and DataFrames - Spark 2.2.3 Documentation Spark官网