概览
本科毕设做过电影推荐系统,但当时的推荐算法只有一个,现在已经忘记大部分了,当时也没有记录,因此写这个博客重新来记录一下。此外,技术栈由于快秋招原因来不及做过多的部分,因此只实现简单的功能,在此不做搜索引擎部分。
技术栈:Vue+Element-ui、SpringBoot、Spark、Redis、Mongodb、Flume、Kafka、Azkaban
1 云服务器选择
- 由于电脑比较老,开太多应用实在太卡(之前做毕设的体会),因此选用了云服务器。
- 之前使用过云服务器,但由于大数据需要的内存比较大些,实在没钱。发现轻量服务器貌似便宜一点,因此使用腾讯的轻量服务器4cpu+16GB来开发。
2 大数据环境搭建
- 时间原因+服务器配置原因,在此我只用买了一台来进行开发,这是出于开发的简单,旦可能这样做一台机器上压力比较大。
- 由于配置实在太费时间(之前每次配置都心累),因此直接使用docker拉取镜像
- 操作系统:centos7.6
2.1 docker安装
- 参考博客docker安装
2.2 使用docker-compose快速部署spark环境
- 安装docker-compose见docker-compose安装。
- 我使用curl方式安装,若遇见
curl: (35) Encountered end of file,则原因可能是云服务器没有开放443端口(解决方案:443端口开放)
- 快速部署Spark环境
(1)新建test文件夹并进入,依次执行下列命令
wget https://raw.githubusercontent.com/zq2599/blog_demos/master/sparkdockercomposefiles/docker-compose.yml
wget https://raw.githubusercontent.com/zq2599/blog_demos/master/sparkdockercomposefiles/hadoop.env
# 在test文件下执行该命令,该命令需要等待一会
docker-compose up -d
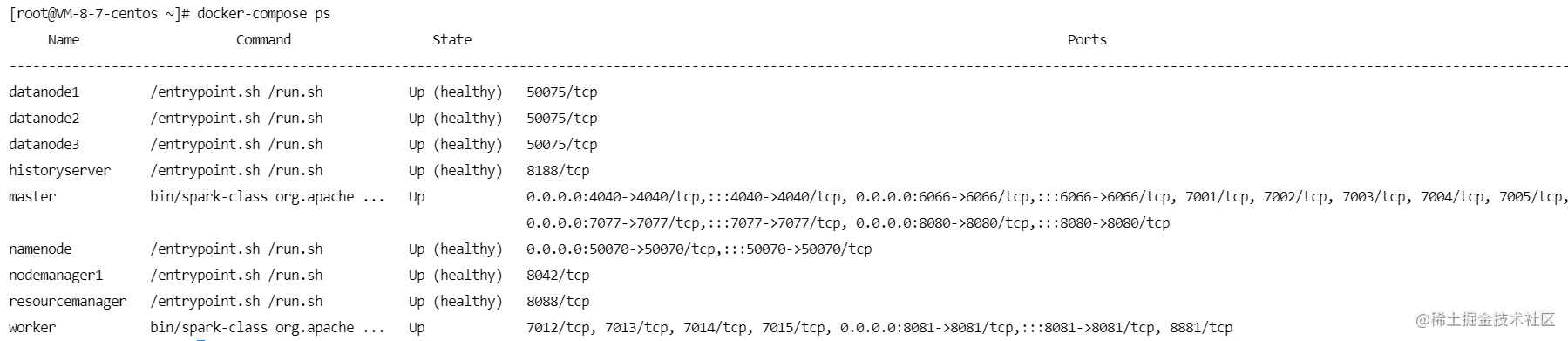
(2)使用docker-compose ps查看当前的镜像
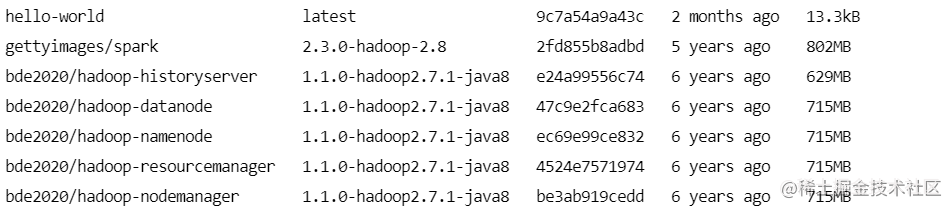
(3)使用docker-compose ps查看当前运行的情况
- 这里我出现两个exit,查询日志(
docker-compose logs)检查错误原因
# 发现错误
could only be replicated to 0 nodes instead of minReplication (=1). There are 1 datanode(s) running and no node(s) are excluded in this operation.
- 可能是因为端口原因,设置云服务器全部端口开放(有风险但先暂时这样做),重新启动
docker-compose up -d,成功
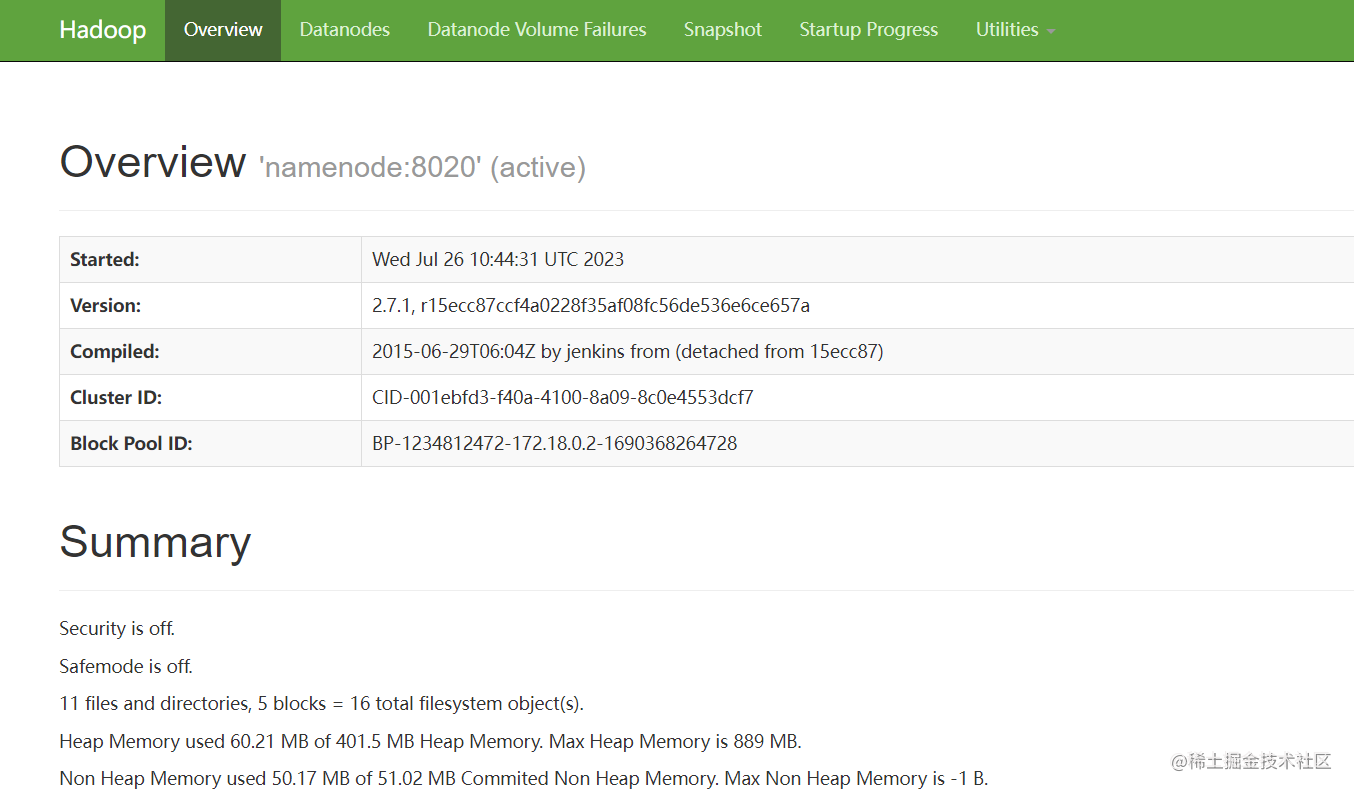
(4)查看HDFS(xxxx:50070)
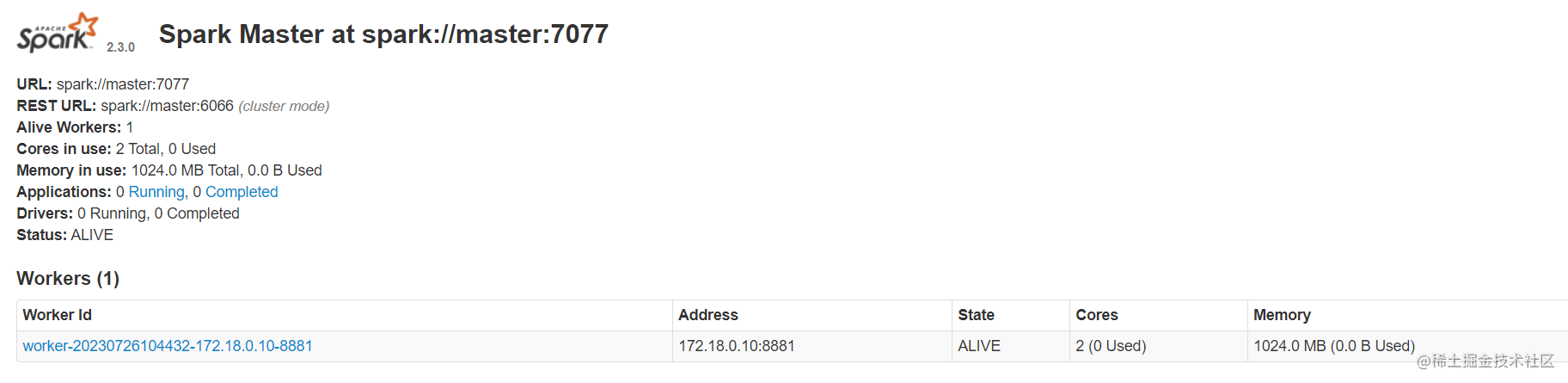
(5)查看Spark界面(xxxx:8080)
总结
- 为了快速回顾之前的项目,因此是怎么简单怎么来,但如果有时间的话,建议用三台机器,也可以考虑CDH搭建。
- 下一节将介绍数据准备、离线推荐功能开发