目录
1.configs
2.具体实现
3.调用
3.1 注册
3.2 调用
配置部分在configs/_base_/models目录下,具体实现在mmdet/models/*_heads目录下。
这个heads可以是很多个目录下的。
1.configs

我们看下yolox的head吧。
https://github.com/open-mmlab/mmdetection/blob/master/configs/yolox/yolox_s_8x8_300e_coco.py#L17
bbox_head=dict(
type='YOLOXHead', num_classes=80, in_channels=128, feat_channels=128)2.具体实现
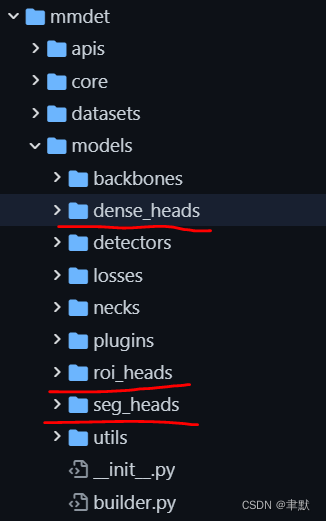
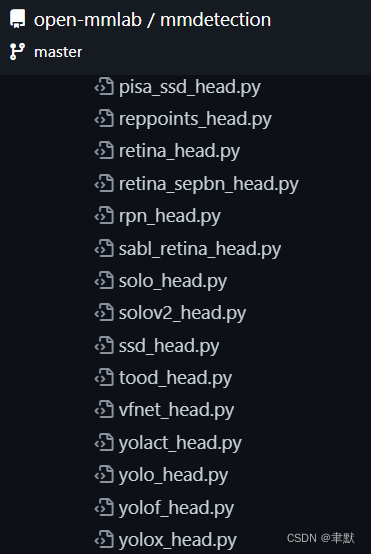
dense_heads中的yolox_head.py:
https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/dense_heads/yolox_head.py#L22
@HEADS.register_module()
class YOLOXHead(BaseDenseHead, BBoxTestMixin):
"""YOLOXHead head used in `YOLOX <https://arxiv.org/abs/2107.08430>`_.
Args:
num_classes (int): Number of categories excluding the background
category.
in_channels (int): Number of channels in the input feature map.
feat_channels (int): Number of hidden channels in stacking convs.
Default: 256
stacked_convs (int): Number of stacking convs of the head.
Default: 2.
strides (tuple): Downsample factor of each feature map.
use_depthwise (bool): Whether to depthwise separable convolution in
blocks. Default: False
dcn_on_last_conv (bool): If true, use dcn in the last layer of
towers. Default: False.
conv_bias (bool | str): If specified as `auto`, it will be decided by
the norm_cfg. Bias of conv will be set as True if `norm_cfg` is
None, otherwise False. Default: "auto".
conv_cfg (dict): Config dict for convolution layer. Default: None.
norm_cfg (dict): Config dict for normalization layer. Default: None.
act_cfg (dict): Config dict for activation layer. Default: None.
loss_cls (dict): Config of classification loss.
loss_bbox (dict): Config of localization loss.
loss_obj (dict): Config of objectness loss.
loss_l1 (dict): Config of L1 loss.
train_cfg (dict): Training config of anchor head.
test_cfg (dict): Testing config of anchor head.
init_cfg (dict or list[dict], optional): Initialization config dict.
"""
def __init__(self,
num_classes,
in_channels,
feat_channels=256,
stacked_convs=2,
strides=[8, 16, 32],
use_depthwise=False,
dcn_on_last_conv=False,
conv_bias='auto',
conv_cfg=None,
norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
act_cfg=dict(type='Swish'),
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=True,
reduction='sum',
loss_weight=1.0),
loss_bbox=dict(
type='IoULoss',
mode='square',
eps=1e-16,
reduction='sum',
loss_weight=5.0),
loss_obj=dict(
type='CrossEntropyLoss',
use_sigmoid=True,
reduction='sum',
loss_weight=1.0),
loss_l1=dict(type='L1Loss', reduction='sum', loss_weight=1.0),
train_cfg=None,
test_cfg=None,
init_cfg=dict(
type='Kaiming',
layer='Conv2d',
a=math.sqrt(5),
distribution='uniform',
mode='fan_in',
nonlinearity='leaky_relu')):
super().__init__(init_cfg=init_cfg)
self.num_classes = num_classes
self.cls_out_channels = num_classes
self.in_channels = in_channels
self.feat_channels = feat_channels
self.stacked_convs = stacked_convs
self.strides = strides
self.use_depthwise = use_depthwise
self.dcn_on_last_conv = dcn_on_last_conv
assert conv_bias == 'auto' or isinstance(conv_bias, bool)
self.conv_bias = conv_bias
self.use_sigmoid_cls = True
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.act_cfg = act_cfg
self.loss_cls = build_loss(loss_cls)
self.loss_bbox = build_loss(loss_bbox)
self.loss_obj = build_loss(loss_obj)
self.use_l1 = False # This flag will be modified by hooks.
self.loss_l1 = build_loss(loss_l1)
self.prior_generator = MlvlPointGenerator(strides, offset=0)
self.test_cfg = test_cfg
self.train_cfg = train_cfg
self.sampling = False
if self.train_cfg:
self.assigner = build_assigner(self.train_cfg.assigner)
# sampling=False so use PseudoSampler
sampler_cfg = dict(type='PseudoSampler')
self.sampler = build_sampler(sampler_cfg, context=self)
self.fp16_enabled = False
self._init_layers()
def _init_layers(self):
self.multi_level_cls_convs = nn.ModuleList()
self.multi_level_reg_convs = nn.ModuleList()
self.multi_level_conv_cls = nn.ModuleList()
self.multi_level_conv_reg = nn.ModuleList()
self.multi_level_conv_obj = nn.ModuleList()
for _ in self.strides:
self.multi_level_cls_convs.append(self._build_stacked_convs())
self.multi_level_reg_convs.append(self._build_stacked_convs())
conv_cls, conv_reg, conv_obj = self._build_predictor()
self.multi_level_conv_cls.append(conv_cls)
self.multi_level_conv_reg.append(conv_reg)
self.multi_level_conv_obj.append(conv_obj)
def _build_stacked_convs(self):
"""Initialize conv layers of a single level head."""
conv = DepthwiseSeparableConvModule \
if self.use_depthwise else ConvModule
stacked_convs = []
for i in range(self.stacked_convs):
chn = self.in_channels if i == 0 else self.feat_channels
if self.dcn_on_last_conv and i == self.stacked_convs - 1:
conv_cfg = dict(type='DCNv2')
else:
conv_cfg = self.conv_cfg
stacked_convs.append(
conv(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg,
bias=self.conv_bias))
return nn.Sequential(*stacked_convs)
def _build_predictor(self):
"""Initialize predictor layers of a single level head."""
conv_cls = nn.Conv2d(self.feat_channels, self.cls_out_channels, 1)
conv_reg = nn.Conv2d(self.feat_channels, 4, 1)
conv_obj = nn.Conv2d(self.feat_channels, 1, 1)
return conv_cls, conv_reg, conv_obj
def init_weights(self):
super(YOLOXHead, self).init_weights()
# Use prior in model initialization to improve stability
bias_init = bias_init_with_prob(0.01)
for conv_cls, conv_obj in zip(self.multi_level_conv_cls,
self.multi_level_conv_obj):
conv_cls.bias.data.fill_(bias_init)
conv_obj.bias.data.fill_(bias_init)
def forward_single(self, x, cls_convs, reg_convs, conv_cls, conv_reg,
conv_obj):
"""Forward feature of a single scale level."""
cls_feat = cls_convs(x)
reg_feat = reg_convs(x)
cls_score = conv_cls(cls_feat)
bbox_pred = conv_reg(reg_feat)
objectness = conv_obj(reg_feat)
return cls_score, bbox_pred, objectness
def forward(self, feats):
"""Forward features from the upstream network.
Args:
feats (tuple[Tensor]): Features from the upstream network, each is
a 4D-tensor.
Returns:
tuple[Tensor]: A tuple of multi-level predication map, each is a
4D-tensor of shape (batch_size, 5+num_classes, height, width).
"""
return multi_apply(self.forward_single, feats,
self.multi_level_cls_convs,
self.multi_level_reg_convs,
self.multi_level_conv_cls,
self.multi_level_conv_reg,
self.multi_level_conv_obj)
@force_fp32(apply_to=('cls_scores', 'bbox_preds', 'objectnesses'))
def get_bboxes(self,
cls_scores,
bbox_preds,
objectnesses,
img_metas=None,
cfg=None,
rescale=False,
with_nms=True):
"""Transform network outputs of a batch into bbox results.
Args:
cls_scores (list[Tensor]): Classification scores for all
scale levels, each is a 4D-tensor, has shape
(batch_size, num_priors * num_classes, H, W).
bbox_preds (list[Tensor]): Box energies / deltas for all
scale levels, each is a 4D-tensor, has shape
(batch_size, num_priors * 4, H, W).
objectnesses (list[Tensor], Optional): Score factor for
all scale level, each is a 4D-tensor, has shape
(batch_size, 1, H, W).
img_metas (list[dict], Optional): Image meta info. Default None.
cfg (mmcv.Config, Optional): Test / postprocessing configuration,
if None, test_cfg would be used. Default None.
rescale (bool): If True, return boxes in original image space.
Default False.
with_nms (bool): If True, do nms before return boxes.
Default True.
Returns:
list[list[Tensor, Tensor]]: Each item in result_list is 2-tuple.
The first item is an (n, 5) tensor, where the first 4 columns
are bounding box positions (tl_x, tl_y, br_x, br_y) and the
5-th column is a score between 0 and 1. The second item is a
(n,) tensor where each item is the predicted class label of
the corresponding box.
"""
assert len(cls_scores) == len(bbox_preds) == len(objectnesses)
cfg = self.test_cfg if cfg is None else cfg
scale_factors = np.array(
[img_meta['scale_factor'] for img_meta in img_metas])
num_imgs = len(img_metas)
featmap_sizes = [cls_score.shape[2:] for cls_score in cls_scores]
mlvl_priors = self.prior_generator.grid_priors(
featmap_sizes,
dtype=cls_scores[0].dtype,
device=cls_scores[0].device,
with_stride=True)
# flatten cls_scores, bbox_preds and objectness
flatten_cls_scores = [
cls_score.permute(0, 2, 3, 1).reshape(num_imgs, -1,
self.cls_out_channels)
for cls_score in cls_scores
]
flatten_bbox_preds = [
bbox_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1, 4)
for bbox_pred in bbox_preds
]
flatten_objectness = [
objectness.permute(0, 2, 3, 1).reshape(num_imgs, -1)
for objectness in objectnesses
]
flatten_cls_scores = torch.cat(flatten_cls_scores, dim=1).sigmoid()
flatten_bbox_preds = torch.cat(flatten_bbox_preds, dim=1)
flatten_objectness = torch.cat(flatten_objectness, dim=1).sigmoid()
flatten_priors = torch.cat(mlvl_priors)
flatten_bboxes = self._bbox_decode(flatten_priors, flatten_bbox_preds)
if rescale:
flatten_bboxes[..., :4] /= flatten_bboxes.new_tensor(
scale_factors).unsqueeze(1)
result_list = []
for img_id in range(len(img_metas)):
cls_scores = flatten_cls_scores[img_id]
score_factor = flatten_objectness[img_id]
bboxes = flatten_bboxes[img_id]
result_list.append(
self._bboxes_nms(cls_scores, bboxes, score_factor, cfg))
return result_list
def _bbox_decode(self, priors, bbox_preds):
xys = (bbox_preds[..., :2] * priors[:, 2:]) + priors[:, :2]
whs = bbox_preds[..., 2:].exp() * priors[:, 2:]
tl_x = (xys[..., 0] - whs[..., 0] / 2)
tl_y = (xys[..., 1] - whs[..., 1] / 2)
br_x = (xys[..., 0] + whs[..., 0] / 2)
br_y = (xys[..., 1] + whs[..., 1] / 2)
decoded_bboxes = torch.stack([tl_x, tl_y, br_x, br_y], -1)
return decoded_bboxes
def _bboxes_nms(self, cls_scores, bboxes, score_factor, cfg):
max_scores, labels = torch.max(cls_scores, 1)
valid_mask = score_factor * max_scores >= cfg.score_thr
bboxes = bboxes[valid_mask]
scores = max_scores[valid_mask] * score_factor[valid_mask]
labels = labels[valid_mask]
if labels.numel() == 0:
return bboxes, labels
else:
dets, keep = batched_nms(bboxes, scores, labels, cfg.nms)
return dets, labels[keep]
@force_fp32(apply_to=('cls_scores', 'bbox_preds', 'objectnesses'))
def loss(self,
cls_scores,
bbox_preds,
objectnesses,
gt_bboxes,
gt_labels,
img_metas,
gt_bboxes_ignore=None):
"""Compute loss of the head.
Args:
cls_scores (list[Tensor]): Box scores for each scale level,
each is a 4D-tensor, the channel number is
num_priors * num_classes.
bbox_preds (list[Tensor]): Box energies / deltas for each scale
level, each is a 4D-tensor, the channel number is
num_priors * 4.
objectnesses (list[Tensor], Optional): Score factor for
all scale level, each is a 4D-tensor, has shape
(batch_size, 1, H, W).
gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels (list[Tensor]): class indices corresponding to each box
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes_ignore (None | list[Tensor]): specify which bounding
boxes can be ignored when computing the loss.
"""
num_imgs = len(img_metas)
featmap_sizes = [cls_score.shape[2:] for cls_score in cls_scores]
mlvl_priors = self.prior_generator.grid_priors(
featmap_sizes,
dtype=cls_scores[0].dtype,
device=cls_scores[0].device,
with_stride=True)
flatten_cls_preds = [
cls_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1,
self.cls_out_channels)
for cls_pred in cls_scores
]
flatten_bbox_preds = [
bbox_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1, 4)
for bbox_pred in bbox_preds
]
flatten_objectness = [
objectness.permute(0, 2, 3, 1).reshape(num_imgs, -1)
for objectness in objectnesses
]
flatten_cls_preds = torch.cat(flatten_cls_preds, dim=1)
flatten_bbox_preds = torch.cat(flatten_bbox_preds, dim=1)
flatten_objectness = torch.cat(flatten_objectness, dim=1)
flatten_priors = torch.cat(mlvl_priors)
flatten_bboxes = self._bbox_decode(flatten_priors, flatten_bbox_preds)
(pos_masks, cls_targets, obj_targets, bbox_targets, l1_targets,
num_fg_imgs) = multi_apply(
self._get_target_single, flatten_cls_preds.detach(),
flatten_objectness.detach(),
flatten_priors.unsqueeze(0).repeat(num_imgs, 1, 1),
flatten_bboxes.detach(), gt_bboxes, gt_labels)
# The experimental results show that ‘reduce_mean’ can improve
# performance on the COCO dataset.
num_pos = torch.tensor(
sum(num_fg_imgs),
dtype=torch.float,
device=flatten_cls_preds.device)
num_total_samples = max(reduce_mean(num_pos), 1.0)
pos_masks = torch.cat(pos_masks, 0)
cls_targets = torch.cat(cls_targets, 0)
obj_targets = torch.cat(obj_targets, 0)
bbox_targets = torch.cat(bbox_targets, 0)
if self.use_l1:
l1_targets = torch.cat(l1_targets, 0)
loss_bbox = self.loss_bbox(
flatten_bboxes.view(-1, 4)[pos_masks],
bbox_targets) / num_total_samples
loss_obj = self.loss_obj(flatten_objectness.view(-1, 1),
obj_targets) / num_total_samples
loss_cls = self.loss_cls(
flatten_cls_preds.view(-1, self.num_classes)[pos_masks],
cls_targets) / num_total_samples
loss_dict = dict(
loss_cls=loss_cls, loss_bbox=loss_bbox, loss_obj=loss_obj)
if self.use_l1:
loss_l1 = self.loss_l1(
flatten_bbox_preds.view(-1, 4)[pos_masks],
l1_targets) / num_total_samples
loss_dict.update(loss_l1=loss_l1)
return loss_dict
@torch.no_grad()
def _get_target_single(self, cls_preds, objectness, priors, decoded_bboxes,
gt_bboxes, gt_labels):
"""Compute classification, regression, and objectness targets for
priors in a single image.
Args:
cls_preds (Tensor): Classification predictions of one image,
a 2D-Tensor with shape [num_priors, num_classes]
objectness (Tensor): Objectness predictions of one image,
a 1D-Tensor with shape [num_priors]
priors (Tensor): All priors of one image, a 2D-Tensor with shape
[num_priors, 4] in [cx, xy, stride_w, stride_y] format.
decoded_bboxes (Tensor): Decoded bboxes predictions of one image,
a 2D-Tensor with shape [num_priors, 4] in [tl_x, tl_y,
br_x, br_y] format.
gt_bboxes (Tensor): Ground truth bboxes of one image, a 2D-Tensor
with shape [num_gts, 4] in [tl_x, tl_y, br_x, br_y] format.
gt_labels (Tensor): Ground truth labels of one image, a Tensor
with shape [num_gts].
"""
num_priors = priors.size(0)
num_gts = gt_labels.size(0)
gt_bboxes = gt_bboxes.to(decoded_bboxes.dtype)
# No target
if num_gts == 0:
cls_target = cls_preds.new_zeros((0, self.num_classes))
bbox_target = cls_preds.new_zeros((0, 4))
l1_target = cls_preds.new_zeros((0, 4))
obj_target = cls_preds.new_zeros((num_priors, 1))
foreground_mask = cls_preds.new_zeros(num_priors).bool()
return (foreground_mask, cls_target, obj_target, bbox_target,
l1_target, 0)
# YOLOX uses center priors with 0.5 offset to assign targets,
# but use center priors without offset to regress bboxes.
offset_priors = torch.cat(
[priors[:, :2] + priors[:, 2:] * 0.5, priors[:, 2:]], dim=-1)
assign_result = self.assigner.assign(
cls_preds.sigmoid() * objectness.unsqueeze(1).sigmoid(),
offset_priors, decoded_bboxes, gt_bboxes, gt_labels)
sampling_result = self.sampler.sample(assign_result, priors, gt_bboxes)
pos_inds = sampling_result.pos_inds
num_pos_per_img = pos_inds.size(0)
pos_ious = assign_result.max_overlaps[pos_inds]
# IOU aware classification score
cls_target = F.one_hot(sampling_result.pos_gt_labels,
self.num_classes) * pos_ious.unsqueeze(-1)
obj_target = torch.zeros_like(objectness).unsqueeze(-1)
obj_target[pos_inds] = 1
bbox_target = sampling_result.pos_gt_bboxes
l1_target = cls_preds.new_zeros((num_pos_per_img, 4))
if self.use_l1:
l1_target = self._get_l1_target(l1_target, bbox_target,
priors[pos_inds])
foreground_mask = torch.zeros_like(objectness).to(torch.bool)
foreground_mask[pos_inds] = 1
return (foreground_mask, cls_target, obj_target, bbox_target,
l1_target, num_pos_per_img)
def _get_l1_target(self, l1_target, gt_bboxes, priors, eps=1e-8):
"""Convert gt bboxes to center offset and log width height."""
gt_cxcywh = bbox_xyxy_to_cxcywh(gt_bboxes)
l1_target[:, :2] = (gt_cxcywh[:, :2] - priors[:, :2]) / priors[:, 2:]
l1_target[:, 2:] = torch.log(gt_cxcywh[:, 2:] / priors[:, 2:] + eps)
return l1_target
3.调用
3.1 注册
注册创建类名字典。
@HEADS.register_module()
3.2 调用
YOLOX的基类中调用了这个head:
mmdetection/single_stage.py at 31c84958f54287a8be2b99cbf87a6dcf12e57753 · open-mmlab/mmdetection · GitHub
self.bbox_head = build_head(bbox_head)YOLOXHead其中还继承了这个类BaseDenseHead,运行时调用这个函数:
https://github.com/open-mmlab/mmdetection/blob/master/mmdet/models/dense_heads/base_dense_head.py
def forward_train(self,
x,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=None,
proposal_cfg=None,
**kwargs):
"""
Args:
x (list[Tensor]): Features from FPN.
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes (Tensor): Ground truth bboxes of the image,
shape (num_gts, 4).
gt_labels (Tensor): Ground truth labels of each box,
shape (num_gts,).
gt_bboxes_ignore (Tensor): Ground truth bboxes to be
ignored, shape (num_ignored_gts, 4).
proposal_cfg (mmcv.Config): Test / postprocessing configuration,
if None, test_cfg would be used
Returns:
tuple:
losses: (dict[str, Tensor]): A dictionary of loss components.
proposal_list (list[Tensor]): Proposals of each image.
"""
outs = self(x)
if gt_labels is None:
loss_inputs = outs + (gt_bboxes, img_metas)
else:
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
if proposal_cfg is None:
return losses
else:
proposal_list = self.get_bboxes(
*outs, img_metas=img_metas, cfg=proposal_cfg)
return losses, proposal_list运行是在这里:
https://github.com/open-mmlab/mmdetection/blob/31c84958f54287a8be2b99cbf87a6dcf12e57753/mmdet/models/detectors/single_stage.py#L83
losses = self.bbox_head.forward_train(x, img_metas, gt_bboxes,
gt_labels, gt_bboxes_ignore)