参考教程:
【PDF】Learning Transferable Visual Models From Natural Language Supervision
https://github.com/openai/CLIP
文章目录
- 概述
- 方法
- 自然语言监督
- 创建一个足够大的数据集
- 选择高效的预训练方法
- 代码解读
- 选择和缩放模型
- 训练
- 使用
- 代码解读
- model load related
- clip.available_models()
- clip.load()
- preporcess related
- CLIP model
- zero-shot prediction
- 获取类别编码
- 获取图像编码
- 计算相似度并分类
概述
CLIP (Contrastive Language-Image Pre-Training)是一个基于大规模图像-文本对训练的神经网络,有很多人说它是多模态的开山之作。
论文作者认为现在广泛使用的在给定类别上对图像进行预测的方法是存在一点缺陷的,这个缺陷就是有限的类别限制了模型对新类别的识别能力。比如说你现在训练的物体类别里有猫和狗,这时候凭空冒出来一只老鼠,那你肯定就无法正确预测。
于是作者们就提出了一个新的方法:直接从原始文本中学习,而不是标注好的类别。
为什么会这么做呢?是因为作者们发现,在nlp任务中,一个基于大规模互联网上的文本数据训练的模型的表现,是可以超过人工标注的高质量数据集上训练的模型的表现的。在是在计算机视觉领域,现在还是更多地选择使用人工标注的数据。
之前已经有一些用文本信息做监督获取图像表达的工作,但是效果可能没有那么好。作者认为影响这种效果的主要因素是数据的规模,所以他们直接用另一个很简单的方法,他们创建了一个数据量有4哥亿的数据集,数据集中的数据是图像和对应的文本,并用这个数据进行模型训练。
他们在三十多个视觉数据集上进行结果的验证,发现在很多任务上,CLIP都取得了相当不错的结果。
方法
自然语言监督
t the core of our approach is the idea of learning perception from supervision contained in natural language.
clip的核心是从包含监督的自然语言信息中学习。
从自然语言中学习和别的训练方式相比有多种优势。首先,相比人工标注的标签,它更容易获取。其次,基于自然语言的方法可以被动地从包含在网络上大量的文本的监督中学习。基于自然语言的学习方法不知学习表达,也将表达和语言连接在一起,从而实现灵活的零样本迁移。
创建一个足够大的数据集
A major motivation for natural language supervision is the large quantities of data of this form available publicly on the internet.
使用自然语言监督的一个动机是网络上有大量的数据可以获取。但是现在常用的一些数据集都没有利用到这个优势,他们在数量和质量上和作者们的预期都有些差异。作者认为正是因为这些数据集不算很达标,所以基于他们的成果才不算那么好。
为了解决这个问题,作者们构建了一个包括400million 图像-文本对的数据集。这些数据都是互联网上公开提供的。作者构建了500000个查询,每个查询包括2000的图像文本对。
选择高效的预训练方法
SOTA的计算机视觉相关模型都要求特别大的计算量,而这么大的计算量最终目的也只是对1000个类别进行预测。那用这些模型来学习自然语言中的open set of visual concetps,计算量该多吓人啊。
we found training efficiency was key to successfully scaling natural language supervision and we selected our final pre-training method based on this metric
作者认为训练的效率是一个很关键的因素,所以他们基于这个标准进行预训练方法的选择。
作者首先使用类似于VirTex的方法,对一个cnn和一个transformer进行联合训练,来预测图像的标签。然而他们也遇到了一些问题。

如上图所示,作者发现基于transformer的模型,尽管计算量大都是resnet50的两倍了,效率确只有简单的词袋模型的三分之一。这些方法都有一个主要的相似点,那就是它们都想要精准地预测出图片对应的文本中的单词。这个任务是很困难的,因为和图片对应的文本是多种多样的。
Recent work in contrastive representation learning for images has found that contrastive objectives can learn better representations than their equivalent predictive objective。
最近在对比学习中的研究结果发现,相比于预测目标,对比目标能够学习到更好的表达。基于这个发现,作者们设计了一个系统来解决一个更简单的任务,即预测哪个文本和图像匹配度更高,而不是精准地预测文本的文字。以词袋模型作为baseline,作者使用一个对比的目标来训练,并得到了四倍效率的提升。
给定一个大小为N的batch,batch中的样本是图像和文本对。训练好的clip模型可以预测哪个NxN的组合是更可能发生的。clip学习的是一个多模态的编码空间,通过联合训练一个图像encoder和一个text encoder来最大化图像和text编码的相似度,同时最小化其它 N 2 − N N^2-N N2−N个错误的配对的相似度。
由于训练数据非常多,所以在这个训练过程中,不太需要考虑过拟合。作者在训练的时候没有对图像encoder和textencoder进行初始化,也没有使用非线性的embedding projection,而只是使用了简单的线性映射。作者们还简化了transformation的部分,对于文本,只是采样单个句子;对于图像,只使用了random crop。
代码解读

作者给出了一个处理的该过程的伪代码。我们对代码进行进一步的分析。
首先作者已经训练好了两个分别针对图像和文本的编码器,名为image_encoder和text_endoder,这两个编码器的特征就是输入图像或者文本,得到它们对应的embedding。
使用到的输入就是图像I和文本T,得到的输出就是对应的embedding:I_f和T_f。
I_f = image_encoder(I)
T_f = text_encoder(T)
这两个embedding的维度是不一致的,为了便于两者相似度的计算,要先把它们映射到同一个维度上。所以在这里分别用了W_i和W_t与两个embedding相乘,这里可以理解成做了一个全连接,W_i和W_t就是全连接的权重。
I_e = l2_normalize(np.dot(I_f,W_i),axis=1)
T_e = l2_normalize(np.dot(T_f,W_t),aixs=1)
I_e和T_e在这里就是维度相同的图像和文本的embedding,下一步就是计算两者的相似度。这里计算使用的是余弦相似度,余弦相似度的范围是0到1,越大表示相似度越高。
logits = np.dot(I_e,T_e.T)*np.exp(t)
图像和文本的个数都是N,相似度计算得到的结果是一个NxN的矩阵,第i行第j列的值,表示 第i个图像和第j个文本的相似度。
我们希望得到的结果是,在i==j时,最大化相似度,在i!=j时,最小化相似度。
labels是我们的标签类别。
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
在这里是使用交叉熵进行计算的,在多分类中,会用softmax来进行概率的预测。
s
(
y
i
)
=
e
y
i
∑
j
e
y
j
s(y_i) = \frac{e^{yi}}{\sum_je^{yj}}
s(yi)=∑jeyjeyi
放到当前环境中,我们输出的logits是图像和文本对的相似度。以一个图像为例子,假设N=10,第一个图像的logits长度是10,分别表示第一个图像和第j个文本的相似度,那我们是希望第一个图像和第一个文本的相似度最高,所以它的label就是1。这样它们的相似度就会变成softmax的分子项,第一个图像和别的文本的相似度都会累加在分母项里。
训练过程中会最大化这个概率s(y_i),也就是最大化第一个图像和第一个文本的相似度,同时最小化第一个图像和别的文本的相似度。
选择和缩放模型
对于图像encoder的部分,作者们考虑了两个不同的模型架构。并进行了一些修改。
- resnet50。
- 使用ResNet-D 。
- 抗锯齿 rect-2 模糊池
- 使用attention pooling取代全局池化。
- ViT。
- 增加一个额外的layer normalization。
- 使用一个不太一样的初始化机制。
对于文本encoder的部分,作者们使用了transformer。使用一个63M参数量的12层的带有8个attention head的维度512的模型作为base。为了计算效率,最大的序列长度被设定为76。
先前的计算机视觉相关的工作通常会在宽度或者深度的单一维度中进行缩放,作者们选择的是在宽度,深度和分辨率三个维度都增加额外的计算量。而对于文本encoder,他们只进行模型宽度的缩放,而不考虑深度,从图像encoder的宽度保持一致。因为它们发现clip的性能对文本encoder不敏感。
训练
作者训练了一系列的模型。包括五个resnet:resnet50, resnet101, resnetx4, resnetx16, resnetx64和3个ViT: ViT-B/32, VIT-B/16和ViT-L/14。
- 训练轮数:32个epochs。
- adam optimizer with decoupled weight decay regularization。
- CosineAnnealing schedule余弦退火调整学习率。
- grid search,random search and manual tuning来初始化超参数。
- 使用很大的batch:32768
- 混合精度训练。和一些别的省内存的方法。
使用
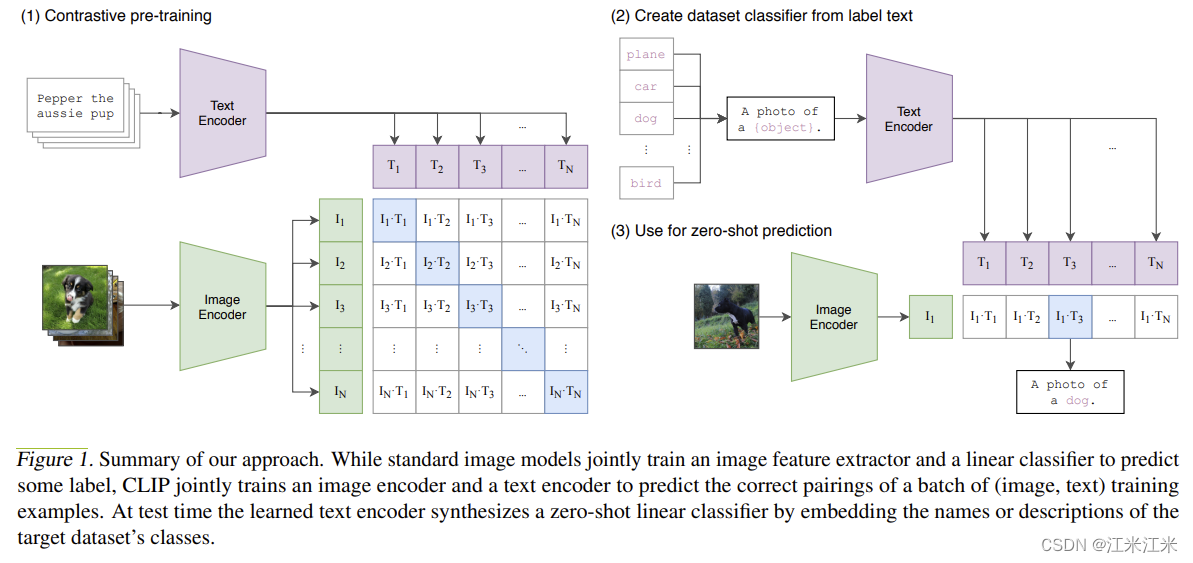
图中对CLIP方法进行了总结。在训练阶段,CLIP会训练一个图像encoder和一个文本encoder,并对一个batch中正确的图像文本对进行预测。在测试阶段,可以用训练好的text encoder生成一个零样本的线性分类器,也就是把目标数据集的类别进行编码。
CLIP is pre-trained to predict if an image and a text snippet are paired together in its dataset.
在计算机视觉中,零样本学习通常是指在图像分类中泛化到不可见类别的研究。作者在这里使用的zero-shot的概念是更加广义的,是对不可见数据集的泛化。
对于每个数据集,作者把数据集中所有类别的名字作为文本的集合,并使用clip预测最大概率的图像和文本对。更具体地来说,作者首先计算图像的特征编码,和一组代表类别的文本的特征编码,然后计算编码之间的相似度。得到的相似度会使用一个温度系数进行缩放,并使用softmax得到一个概率分布。
代码解读
我们先来看一下github上clip这个repo提供了什么功能。
https://github.com/openai/CLIP
clip这个repo本身提供了几个很好用的api,包括已经训练好的模型的加载,同时模型的种类也比较广泛。
model load related
我们首先来看一下和模型加载相关的几个方法。
https://github.com/openai/CLIP/blob/main/clip/clip.py
clip.available_models()
def available_models() -> List[str]:
"""Returns the names of available CLIP models"""
return list(_MODELS.keys())
直接调用这个方法,返回的结果是_MODELS这个字典的key。这个字典是key是模型的名字,value是训练好的模型文件。名称和文件位置都是预设好的。
_MODELS = {
"RN50": "https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt",
"RN101": "https://openaipublic.azureedge.net/clip/models/8fa8567bab74a42d41c5915025a8e4538c3bdbe8804a470a72f30b0d94fab599/RN101.pt",
"RN50x4": "https://openaipublic.azureedge.net/clip/models/7e526bd135e493cef0776de27d5f42653e6b4c8bf9e0f653bb11773263205fdd/RN50x4.pt",
"RN50x16": "https://openaipublic.azureedge.net/clip/models/52378b407f34354e150460fe41077663dd5b39c54cd0bfd2b27167a4a06ec9aa/RN50x16.pt",
"RN50x64": "https://openaipublic.azureedge.net/clip/models/be1cfb55d75a9666199fb2206c106743da0f6468c9d327f3e0d0a543a9919d9c/RN50x64.pt",
"ViT-B/32": "https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt",
"ViT-B/16": "https://openaipublic.azureedge.net/clip/models/5806e77cd80f8b59890b7e101eabd078d9fb84e6937f9e85e4ecb61988df416f/ViT-B-16.pt",
"ViT-L/14": "https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.pt",
"ViT-L/14@336px": "https://openaipublic.azureedge.net/clip/models/3035c92b350959924f9f00213499208652fc7ea050643e8b385c2dac08641f02/ViT-L-14-336px.pt",
}
clip.load()
def load(name: str, device: Union[str, torch.device] = "cuda" if torch.cuda.is_available() else "cpu", jit: bool = False, download_root: str = None):
load函数可以加载与训练好的模型,它的输入包含以下几个参数。
- name: 这个name必须是在_MODELS这个字典中存在的。
- device:你要使用的device。
- jit:你要load的模型文件是不是jit。
- download_root: 下载的模型文件保存的路径。
在加载模型时,首先会根据你输入的模型名称,下载它对应的模型文件。下载成功后会返回该文件在你本地保存的地址。
如果文件是torchscript类型,则使用torch.jit直接加载。
如果不是的话,需要使用torch.load()方法,加载文件后再使用build_model方法进行model的重建。
返回的结果是model和对应的transform方法。
preporcess related
然后我们来看一下和数据预处理有关的方法。已知clip的输入包括图像和文本两种,所以它的预处理也有两种。
-
图像预处理。
clip.load()方法会返回两个结果,第一个结果就是你的模型,第二个结果是你的图像的预处理。在论文中也提到过,clip的预处理方法非常简单。更具体的来说就是如下。进行了resize,crop,然后normalize。def _transform(n_px): return Compose([ Resize(n_px, interpolation=BICUBIC), CenterCrop(n_px), _convert_image_to_rgb, ToTensor(), Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)), ]) -
文本的预处理使用的是clip.tokenize()方法。
def tokenize(texts: Union[str, List[str]], context_length: int = 77, truncate: bool = False) -> Union[torch.IntTensor, torch.LongTensor]:tokenize可以将你输入文本转成对应指定长度的tensor,在这里设定的长度是77。转成tensor是用来作为模型输入的。我们可以看一下 这个方法的输入参数:
1. texts:你的输入文本。
2. context_length: 文本长度,默认是77。
3. truncate:如果文本长度大于设定长度,是否要进行截断。
文本预处理使用的是一个simple tokenizer,代码:https://github.com/openai/CLIP/blob/main/clip/simple_tokenizer.py
- 简单的编码修复和空格去除(连续多个空格只保留一个)。
- 将句子compile成多个单词。
- bpe编码
在clip的colab中给出了一个处理结果的例子。
CLIP model
先回忆一下clip中都包括哪几个部分。
- 一个image encoder
- 一个text encoder
- embedding projection
在实现中,图像embedding的projection包含在了encoder内,encoder直接输出的维度就是embed dim。文本的仍然通过一个线性变换来实现。
class CLIP(nn.Module):
def __init__(self,
embed_dim: int,
# vision
image_resolution: int,
vision_layers: Union[Tuple[int, int, int, int], int],
vision_width: int,
vision_patch_size: int,
# text
context_length: int,
vocab_size: int,
transformer_width: int,
transformer_heads: int,
transformer_layers: int
):
我们先来看一下CLIP这个类的输入参数都有哪些。
- embed_dim:图像和文本编码的维度。两个编码的维度要一直,便于计算。
- 图像部分:
- image_resolution: 输入大小,一般是224.
- vision_layer: 模型的层数,也就是深度。
- vision_width: 模型的宽度。
- vision_patch_size: 如果使用vit模型,则需要patch_size。
- 文本部分:
- context_length: 文本长度。
- vocab_size: 词库大小。
- transformer_width: 模型宽度。
- transformer_heads: 注意力头的个数。
- transformer_layers: 模型的层数。
图像encoder有两种实现,一种是修改过的resnet,一种是vit模型。如果是用的resnet模型,最后一层就是attention pooling,输出的维度是embed_eim; 如果是用的vit模型,模型最后会有一个输出维度为embed_dim的projection。
文本encoder使用的transformer。输入的文本需要先编码成embedding,并添加一个位置编码后,再送入transformer,输出结果需要经过一个额外的text projection。
self.token_embedding = nn.Embedding(vocab_size, transformer_width)
self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))
self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))
这个模型forward(self, image, text)的部分比较简单。
def forward(self, image, text):
image_features = self.encode_image(image)
text_features = self.encode_text(text)
# normalized features
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# cosine similarity as logits
logit_scale = self.logit_scale.exp()
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
# shape = [global_batch_size, global_batch_size]
return logits_per_image, logits_per_text
这部分和在论文里的伪代码差不多。首先用image encoder和text encoder分别获得输入的图像和文本的编码,并且normalize。
然后计算得到图像编码和文本编码的相似度。返回的结果也是相似度。
zero-shot prediction
我们之前也说过使用CLIP进行分类任务预测的过程。
获取类别编码
首先要对目标数据集的类别作为文本,使用clip得到对应的编码。
text_descriptions = [f"This is a photo of a {label}" for label in cifar100.classes]
在这里可以看到,文本准备的过程就是将类别填入到句子“This is a photo of a ——”中,实验证明使用这样的句子比使用单独一个单词的准确率要高一点。
然后进行文本的预处理。
text_tokens = clip.tokenize(text_descriptions).cuda()
将输入送到clip的文本encoder中获取结果。
with torch.no_grad():
text_features = model.encode_text(text_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
得到的文本编码备用,一会儿会用于我们的图像分类。
获取图像编码
对于我们想要预测类别的图像,我们也需要先对它进行预处理。
假如我们有多个图像作为输入:
for filename in [filename for filename in os.listdir(skimage.data_dir) if filename.endswith(".png") or filename.endswith(".jpg")]:
name = os.path.splitext(filename)[0]
image = Image.open(os.path.join(skimage.data_dir, filename)).convert("RGB")
images.append(preprocess(image))
image_input = torch.tensor(np.stack(images)).cuda()
处理好的输入,直接送入clip的模型中,获得图像encoder的编码结果。
with torch.no_grad():
image_features = model.encode_image(image_input).float()
image_features /= image_features.norm(dim=-1, keepdim=True)
计算相似度并分类
现在我们已经得到了目标类别的text_features和想要预测的图像的image_features。我们只要进行相似度的计算,并使用softmax转为概率分布,就可以获得类别。
similarity = text_features.cpu().numpy() @ image_features.cpu().numpy().T
text_prob = (100.0 * similarity).softmax(dim=-1)