一、流程:ceph-deploy部署ceph-mon组建集群
1.ceph-deploy部署ceph-mon的工作流程及首次启动
1)通过命令创建ceph-mon,命令为:ceph-deploy create mon keyring
def mon(args):
if args.subcommand == 'create':
mon_create(args)
elif args.subcommand == 'add':
mon_add(args)
elif args.subcommand == 'destroy':
mon_destroy(args)
elif args.subcommand == 'create-initial':
mon_create_initial(args)
else:
LOG.error('subcommand %s not implemented', args.subcommand)2)在创建mon时,会根据传入的args参数生成配置文件ceph.conf。
def mon_create(distro, args, monitor_keyring):
hostname = distro.conn.remote_module.shortname()
logger = distro.conn.logger
logger.debug('remote hostname: %s' % hostname)
path = paths.mon.path(args.cluster, hostname)
uid = distro.conn.remote_module.path_getuid(constants.base_path)
gid = distro.conn.remote_module.path_getgid(constants.base_path)
done_path = paths.mon.done(args.cluster, hostname)
init_path = paths.mon.init(args.cluster, hostname, distro.init)
conf_data = conf.ceph.load_raw(args)
# write the configuration file
distro.conn.remote_module.write_conf( #写入配置/etc/ceph/ceph.conf
args.cluster,
conf_data,
args.overwrite_conf,
)
def write_conf(cluster, conf, overwrite): #写入配置/etc/ceph/ceph.conf
""" write cluster configuration to /etc/ceph/{cluster}.conf """
import os
path = '/etc/ceph/{cluster}.conf'.format(cluster=cluster)
tmp = '{path}.{pid}.tmp'.format(path=path, pid=os.getpid())
if os.path.exists(path):
with open(path) as f:
old = f.read()
if old != conf and not overwrite:
raise RuntimeError('config file %s exists with different content; use --overwrite-conf to overwrite' % path)
with open(tmp, 'w') as f:
f.write(conf)
f.flush()
os.fsync(f)
os.rename(tmp, path)3)检查ceph-mon组件工作目录(/var/lib/ceph/mon/mycluster-myhostname)是否存在,不存在就创建,除了创建该目录外,还需要在该路径下创建keyring秘钥。然后执行命令"ceph-mon --cluster args.cluster --mkfs -i hostname --keyring --setuser uid --setgroup gid"启动ceph-mon进程,此时也是第一次启动ceph-mon。然后它会创建done文件并启动cepn-mon服务。
# if the mon path does not exist, create it
distro.conn.remote_module.create_mon_path(path, uid, gid) #path为/var/lib/ceph/mon/mycluster-myhostname
if not distro.conn.remote_module.path_exists(done_path):
logger.debug('done path does not exist: %s' % done_path)
if not distro.conn.remote_module.path_exists(paths.mon.constants.tmp_path): #如果路径不存在还需要创建keyring
logger.info('creating tmp path: %s' % paths.mon.constants.tmp_path)
distro.conn.remote_module.makedir(paths.mon.constants.tmp_path)
keyring = paths.mon.keyring(args.cluster, hostname)
logger.info('creating keyring file: %s' % keyring)
distro.conn.remote_module.write_monitor_keyring( #创建keyring
keyring,
monitor_keyring,
uid, gid,
)
user_args = []
if uid != 0:
user_args = user_args + [ '--setuser', str(uid) ]
if gid != 0:
user_args = user_args + [ '--setgroup', str(gid) ]
remoto.process.run( #第一次运行时需要执行的命令
distro.conn,
[
'ceph-mon',
'--cluster', args.cluster,
'--mkfs',
'-i', hostname,
'--keyring', keyring,
] + user_args
)
# create the done file 创建done文件
distro.conn.remote_module.create_done_path(done_path, uid, gid)
# create init path
distro.conn.remote_module.create_init_path(init_path, uid, gid)
# start mon service 启动服务
start_mon_service(distro, args.cluster, hostname)
def create_mon_path(path, uid=-1, gid=-1):
"""create the mon path if it does not exist"""
if not os.path.exists(path):
os.makedirs(path)
os.chown(path, uid, gid);4)启动之后,需要将ceph-mon加入到mon_in_quorum里面,这是一个set的数据结构,这里面包含着集群的所有ceph-mon。该mon_in_quorum里面包含着leader,其他全都是peon(普通成员)。
def mon_create_initial(args):
# create them normally through mon_create
args.mon = mon_initial_members
mon_create(args)
# make the sets to be able to compare late
mon_in_quorum = set([])
for host in mon_initial_members:
mon_name = 'mon.%s' % host
LOG.info('processing monitor %s', mon_name)
sleeps = [20, 20, 15, 10, 10, 5]
tries = 5
rlogger = logging.getLogger(host)
distro = hosts.get(
host,
username=args.username,
callbacks=[packages.ceph_is_installed]
)
while tries:
status = mon_status_check(distro.conn, rlogger, host, args)
has_reached_quorum = status.get('state', '') in ['peon', 'leader']
if not has_reached_quorum:
LOG.warning('%s monitor is not yet in quorum, tries left: %s' % (mon_name, tries))
tries -= 1
sleep_seconds = sleeps.pop()
LOG.warning('waiting %s seconds before retrying', sleep_seconds)
time.sleep(sleep_seconds) # Magic number
else:
mon_in_quorum.add(host) //添加进mon_in_quorum
LOG.info('%s monitor has reached quorum!', mon_name)
break
distro.conn.exit()
2.ceph-mon数据存储方式
1)存储方式:mon它的数据可以通过两种方式来进行存储,一种是rocksDB存储、一种是leveldb存储,在ceph中具体使用哪一种存储方式取决于/var/lib/ceph/mon/$ceph-id目录下的kv_backend文件的内容,如果kv_backend中为rocksdb,则使用rocksdb存储,若为空或读取错误时,使用leveldb存储,它们都是一个key/value类型的数据库,区别在于rocksdb配置更灵活,支持的压缩算法比较多,除了snappy压缩外还支持zstd压缩,并且压缩比也更高。
int open(ostream &out) {
string kv_type;
int r = read_meta("kv_backend", &kv_type); //读取kv_backend文件,获取存储类型kv_type
if (r < 0 || kv_type.empty()) {
// assume old monitors that did not mark the type were leveldb.
kv_type = "leveldb";
r = write_meta("kv_backend", kv_type);
if (r < 0)
return r;
}
_open(kv_type);
r = db->open(out);
if (r < 0)
return r;
.....
}2)存储位置:mon的数据存储在一个可配置的路径mon_data下面,mon_data默认位置为/var/lib/ceph/mon/$ceph-id目录下,该目录存放了mon的keyring秘钥、kv存储引擎名称(rocksdb)、mon支持的版本(octopus)、以及RocksDB的存储文件store.db。
Option("mon_data", Option::TYPE_STR, Option::LEVEL_ADVANCED)
.set_flag(Option::FLAG_NO_MON_UPDATE)
.set_default("/var/lib/ceph/mon/$cluster-$id") //默认mon_data配置路径为/var/lib/ceph/mon/$cluster-$id
.add_service("mon")
.set_description("path to mon database")
MonitorDBStore *store = new MonitorDBStore(g_conf()->mon_data);
ceph3:/var/lib/ceph/mon/ceph-ceph3# ls
donekeyring kv_backend min_mon_release store.db systemd
ceph3:/var/lib/ceph/mon/ceph-ceph3# cat kv_backend
rocksdb
ceph3:/var/lib/ceph/mon/ceph-ceph3#
3)ceph-mon数据主要包括集群健康状态、配置、osd是否存活和Paxos等数据,而存储在Rocksdb中的也正是这些数据,存储方式主要是采用SSTable(Sorted String Table)的方式存储。通过encode_pending将数据编码后存入rocksdb。
MonitorDBStore::TransactionRef t = paxos->get_pending_transaction();
if (should_stash_full())
encode_full(t);
encode_pending(t);
have_pending = false;
if (format_version > 0) {
t->put(get_service_name(), "format_version", format_version);
}二、流程:ceph-mon加入集群后二次启动
1.启动流程
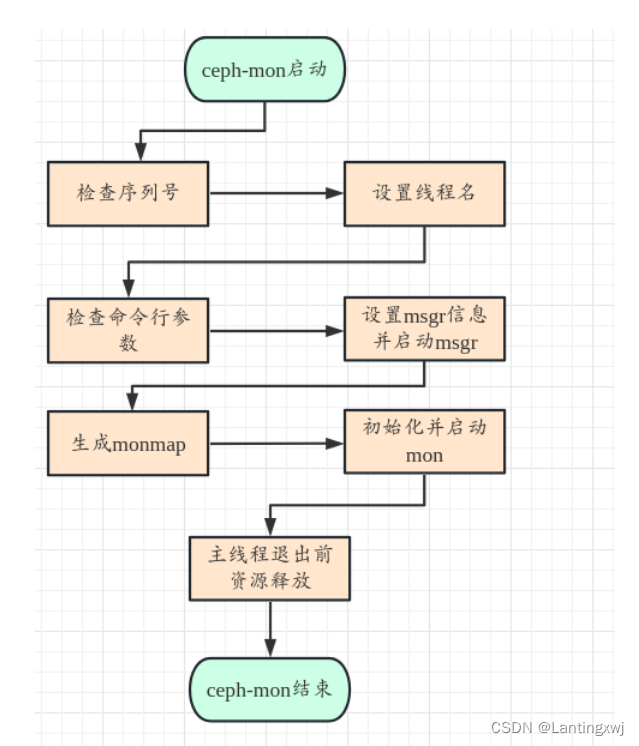
1.在ceph_mon.cc文件的main函数中,首先判断linxdfs序列号是否正确,然后设置线程名ceph-mon;接着读取启动时传入的命令行参数“/usr/bin/ceph-mon -f --cluster ceph --id ceph1 --setuser root --setgroup root”,并检验命令行参数。
int main(int argc, const char **argv)
{
//检查序列号
char* const linxdfspath = "/etc/linxsn/linxdfs_sn.conf";
.....
ceph_pthread_setname(pthread_self(), "ceph-mon");
......
//解析命令行参数
std::string val;
for (std::vector<const char*>::iterator i = args.begin(); i != args.end(); ) {
if (ceph_argparse_double_dash(args, i)) {
break;
} else if (ceph_argparse_flag(args, i, "--mkfs", (char*)NULL)) { //若命令行参数中有mkfs参数,则会进行370的mkfs操作
mkfs = true;
} else if (ceph_argparse_flag(args, i, "--compact", (char*)NULL)) {
compact = true;
} else if (ceph_argparse_flag(args, i, "--force-sync", (char*)NULL)) {
force_sync = true;
} else if (ceph_argparse_flag(args, i, "--yes-i-really-mean-it", (char*)NULL)) {
yes_really = true;
} else if (ceph_argparse_witharg(args, i, &val, "--osdmap", (char*)NULL)) {
osdmapfn = val;
} else if (ceph_argparse_witharg(args, i, &val, "--inject_monmap", (char*)NULL)) {
inject_monmap = val;
} else if (ceph_argparse_witharg(args, i, &val, "--extract-monmap", (char*)NULL)) {
extract_monmap = val;
} else {
++i;
}
}2.然后进行mkfs流程,该流程里面会检查并创建/var/lib/ceph/mon/$ceph_id目录,该目录包括以下几个文件:done keyring kv_backend min_mon_release systemd和子目录 store.db 。
// -- mkfs --
if (mkfs) { //第一次启动时,mkfs一定会为true,并进入该if内部创建/var/lib/ceph/$ceph_id目录,同时会为该目录填充内容
int err = check_mon_data_exists(); //当mkfs为true时,第一次启动会检查mon_data存在,不存在会mkdir创建
if (err == -ENOENT) {
if (::mkdir(g_conf()->mon_data.c_str(), 0755)) {
derr << "mkdir(" << g_conf()->mon_data << ") : "
<< cpp_strerror(errno) << dendl;
exit(1);
}
} else if (err < 0) {
derr << "error opening '" << g_conf()->mon_data << "': "
<< cpp_strerror(-err) << dendl;
exit(-err);
}3.构建monmap,将mon_data中的数据(store.db)decode解码到bufflist中,再写入到文件,以此来构建monmap。
......
MonMap monmap; //构建monmap
{
// note that even if we don't find a viable monmap, we should go ahead
// and try to build it up in the next if-else block.
bufferlist mapbl;
int err = obtain_monmap(*store, mapbl); //从store.db中获取monmap信息并构建monmap
if (err >= 0) {
try {
monmap.decode(mapbl);
} catch (const buffer::error& e) {
derr << "can't decode monmap: " << e.what() << dendl;
}
} else {
derr << "unable to obtain a monmap: " << cpp_strerror(err) << dendl;
}
dout(10) << __func__ << " monmap:\n";
JSONFormatter jf(true);
jf.dump_object("monmap", monmap);
jf.flush(*_dout);
*_dout << dendl;
if (!extract_monmap.empty()) {
int r = mapbl.write_file(extract_monmap.c_str());4.创建Messager对象msgr,从monmap中获取rank并绑定到msgr上面,设置msgr信息、绑定地址等
//创建msgr
Messenger *msgr = Messenger::create(g_ceph_context, public_msgr_type,
entity_name_t::MON(rank), "mon",
0, // zero nonce
Messenger::HAS_MANY_CONNECTIONS);
msgr->set_cluster_protocol(CEPH_MON_PROTOCOL);
msgr->set_default_send_priority(CEPH_MSG_PRIO_HIGH);
msgr->set_default_policy(Messenger::Policy::stateless_server(0));
msgr->set_policy(entity_name_t::TYPE_MON,
Messenger::Policy::lossless_peer_reuse(
CEPH_FEATURE_SERVER_LUMINOUS));
msgr->set_policy(entity_name_t::TYPE_OSD,
Messenger::Policy::stateless_server(
CEPH_FEATURE_SERVER_LUMINOUS));
msgr->set_policy(entity_name_t::TYPE_CLIENT,
Messenger::Policy::stateless_server(0));
msgr->set_policy(entity_name_t::TYPE_MDS,
Messenger::Policy::stateless_server(0));
// bind
err = msgr->bindv(bind_addrs);
if (public_addrs != bind_addrs) {
msgr->set_addrs(public_addrs);
}5.创建Monitor对象mon,设置传入的cmd信息,调用preinit进行预初始化(预初始化里面主要包括对paxos、msgr对应的服务端,客户端初始化)。
//创建mon对象
mon = new Monitor(g_ceph_context, g_conf()->name.get_id(), store,
msgr, mgr_msgr, &monmap); //创建mon对象
mon->orig_argc = argc;
mon->orig_argv = argv;
err = mon->preinit(); //预初始化
int Monitor::preinit()
{
paxos->init_logger();
init_paxos();
messenger->set_auth_client(this);
messenger->set_auth_server(this);
mgr_messenger->set_auth_client(this);
....
}6.启动msgr,然后调用init对mon进行初始化同时启动mon。
msgr->start();
mgr_msgr->start();
mon->init(); //初始化mon7.当触发SIGINT、SIGTERM信号时就会释放所有mon、msgr等资源。
register_async_signal_handler_oneshot(SIGINT, handle_mon_signal);
register_async_signal_handler_oneshot(SIGTERM, handle_mon_signal);
if (g_conf()->inject_early_sigterm)
kill(getpid(), SIGTERM);
msgr->wait();
mgr_msgr->wait();
store->close();
shutdown_async_signal_handler();
delete mon;
delete store;
delete msgr;
.....
3.加入集群
ceph-mon需要与其他监视器节点进行通信以构建监视器集群。它会尝试连接到其他已知的监视器节点,并通过消息交换建立集群中的监视器之间的通信。
3.1)建立通信连接(绑定地址、端口等)

ceph-mon模块通信依赖于AsyncMessager的异步通信,在ceph-mon.cc里面创建mon和Messenger对象(由于继承关系实质上是创建的AsyncMessenger对象),并且在初始化mon和AsyncMessager时,服务端会绑定本机ip和端口(通过配置获取),然后再调用_init_local_connection函数建立连接。
//创建Messenger对象
Messenger *Messenger::create(CephContext *cct, const string &type,
entity_name_t name, string lname,
uint64_t nonce, uint64_t cflags)
{
int r = -1;
if (type == "random") {
r = 0;
//r = ceph::util::generate_random_number(0, 1);
}
if (r == 0 || type.find("async") != std::string::npos)
return new AsyncMessenger(cct, name, type, std::move(lname), nonce); //异步对象
lderr(cct) << "unrecognized ms_type '" << type << "'" << dendl;
return nullptr;
}
// bind
err = msgr->bindv(bind_addrs);
if (err < 0) {
derr << "unable to bind monitor to " << bind_addrs << dendl;
prefork.exit(1);
}
//绑定socket具体实现
int AsyncMessenger::bindv(const entity_addrvec_t &bind_addrs)
{
lock.lock();
if (!pending_bind && started) {
ldout(cct,10) << __func__ << " already started" << dendl;
lock.unlock();
return -1;
}
ldout(cct,10) << __func__ << " " << bind_addrs << dendl;
if (!stack->is_ready()) {
ldout(cct, 10) << __func__ << " Network Stack is not ready for bind yet - postponed" << dendl;
pending_bind_addrs = bind_addrs;
pending_bind = true;
lock.unlock();
return 0;
}
lock.unlock();
// bind to a socket
set<int> avoid_ports;
entity_addrvec_t bound_addrs;
unsigned i = 0;
for (auto &&p : processors) {
int r = p->bind(bind_addrs, avoid_ports, &bound_addrs);
if (r) {
// Note: this is related to local tcp listen table problem.
// Posix(default kernel implementation) backend shares listen table
// in the kernel, so all threads can use the same listen table naturally
// and only one thread need to bind. But other backends(like dpdk) uses local
// listen table, we need to bind/listen tcp port for each worker. So if the
// first worker failed to bind, it could be think the normal error then handle
// it, like port is used case. But if the first worker successfully to bind
// but the second worker failed, it's not expected and we need to assert
// here
ceph_assert(i == 0);
return r;
}
++i;
}
_finish_bind(bind_addrs, bound_addrs);
return 0;
}
//启动AsyncMessenger
int AsyncMessenger::start()
{
std::scoped_lock l{lock};
ldout(cct,1) << __func__ << " start" << dendl;
// register at least one entity, first!
ceph_assert(my_name.type() >= 0);
ceph_assert(!started);
started = true;
stopped = false;
if (!did_bind) {
entity_addrvec_t newaddrs = *my_addrs;
for (auto& a : newaddrs.v) {
a.nonce = nonce;
}
set_myaddrs(newaddrs);
_init_local_connection(); //建立连接
}
return 0;
}3.2)加入集群
ceph-mon在与其他ceph-mon建立起链接过后会进入STATE_PROBING状态,然后发送OP_PROBE消息给各个节点,等待其他节点同步完成后开始插入到集群中。
void Monitor::bootstrap()
{
.....
// probe monitors
dout(10) << "probing other monitors" << dendl;
for (unsigned i = 0; i < monmap->size(); i++) {
if ((int)i != rank)
send_mon_message(
new MMonProbe(monmap->fsid, MMonProbe::OP_PROBE, name, has_ever_joined, //发送probe消息给其他节点
ceph_release()),
i);
......
dout(10) << "bootstrap" << dendl;
wait_for_paxos_write(); //等待其他节点同步完成
......
if (monmap->contains(name))
quorum.insert(name); //插入集群中
....
}4.mon选举
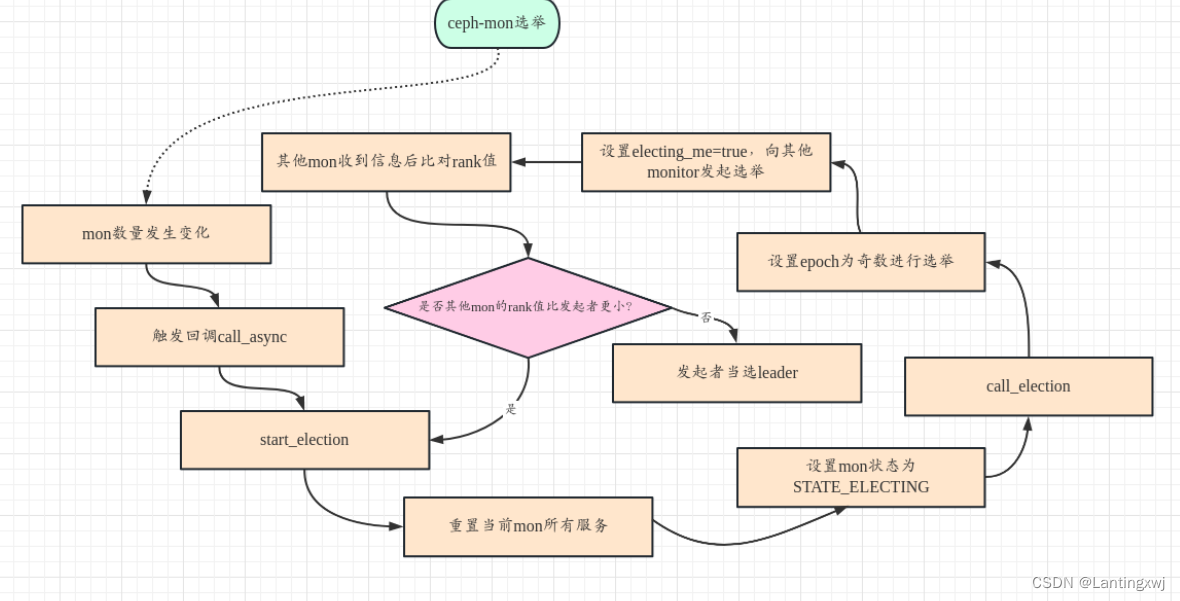
当mon增加或减少时,ceph-mon进程会触发回调函数call_async里start_election开始进行选举,在该函数里主要做了以下几件事:
1)如果Paxos正在STATE_WRITING或者STATE_WRITING_PREVIOUS状态,则等待paxos更新完成。
2)调用_reset()重置monitor中的服务,包括probe timeout事件、health检查事件、scrub事件等,并且restart paxos以及所有的paxos service服务。
3)设置自己进入STATE_ELECTING状态,并增加l_mon_num_elections和l_mon_election_call这些统计数据。
4)调用elector的call_election()进行选举。
void Monitor::start_election()
{
dout(10) << "start_election" << dendl;
wait_for_paxos_write(); //等待paxos的更新完成
_reset();
state = STATE_ELECTING; //设置自身状态
logger->inc(l_mon_num_elections);
logger->inc(l_mon_election_call);
clog->info() << "mon." << name << " calling monitor election";
elector.call_election();
}
// called by bootstrap(), or on leader|peon -> electing
void Monitor::_reset()
{
dout(10) << __func__ << dendl;
// disable authentication
{
std::lock_guard l(auth_lock);
authmon()->_set_mon_num_rank(0, 0);
}
cancel_probe_timeout();
timecheck_finish();
health_events_cleanup(); //重置健康服务
health_check_log_times.clear();
scrub_event_cancel();
leader_since = utime_t();
quorum_since = {};
if (!quorum.empty()) {
exited_quorum = ceph_clock_now();
}
quorum.clear();
outside_quorum.clear(); //重置选举服务
quorum_feature_map.clear();
scrub_reset();
paxos->restart();
for (auto& svc : paxos_service) {
svc->restart();
}
}5)Elector::call_election (),在这里主要做了以下几件事:
5.1)从Mon store中读出mon的election_epoch存储在epoch中,更新epoch的值使其变为奇数,表明进入了选举cycle。epoch为偶数,表明已经形成了稳定的quorum。epoch为偶数时表示为稳定状态,奇数为还在选举中。
5.2)把自己加入到acked_me map中,并设置electing_me为true,希望大家选自己当leader。
5.3)向monmap中的成员发送MMonElection::OP_PROPOSE消息。
void ElectionLogic::start()
{
if (!participating) {
ldout(cct, 0) << "not starting new election -- not participating" << dendl;
return;
}
ldout(cct, 5) << "start -- can i be leader?" << dendl;
acked_me.clear();
init();
// start by trying to elect me
if (epoch % 2 == 0) {
bump_epoch(epoch+1); // odd == election cycle·更新epoch值为奇数
} else {
elector->validate_store();
}
electing_me = true;
acked_me.insert(elector->get_my_rank()); //加入acked_me
leader_acked = -1;
elector->propose_to_peers(epoch); //发送OP_PROPOSE消息
elector->_start();
}6)其它的Monitor收到消息后,经过dispatch逻辑,即Monitor:: ms_dispatch() --> Monitor::_ms_dispatch() --> Monitor::dispatch_op()--> Elector::dispatch(),之后进入消息处理流程。dispatch()中调用Elector::handle_propose(),首先确保收到消息的epoch版本是处于选举的版本(奇数)并且满足对feature的要求,接着判断将自己的选举epoch设置为和消息中包含的epoch的值,最后调用ElectionLogic::receive_propose比对rank值,如果其他的Monitor它们自己的rank值更小,则自己不去确认此次选举,而是重新发起一轮选举,如果它们自己的rank值更大,则进入Elector::defer()流程,发送MMonElection::OP_ACK消息,确认该轮选举为最小的那个Monitor,这样经过rank值小的Monitor多次选举后,最终选出了rank值最小的那个Monitor,选它为leader。
bool ms_dispatch(Message *m) override {
std::lock_guard l{lock};
_ms_dispatch(m); //
return true;
}
void Monitor::_ms_dispatch(Message *m)
{
......
if ((is_synchronizing() ||
(!s->authenticated && !exited_quorum.is_zero())) &&
!src_is_mon &&
m->get_type() != CEPH_MSG_PING) {
waitlist_or_zap_client(op);
} else {
dispatch_op(op); //
}
return;
}
void Monitor::dispatch_op(MonOpRequestRef op)
{
......
// elector messages
case MSG_MON_ELECTION:
op->set_type_election();
//check privileges here for simplicity
if (!op->get_session()->is_capable("mon", MON_CAP_X)) {
dout(0) << "MMonElection received from entity without enough caps!"
<< op->get_session()->caps << dendl;
return;;
}
if (!is_probing() && !is_synchronizing()) {
elector.dispatch(op); //
}
......
}
void Elector::dispatch(MonOpRequestRef op)
{
op->mark_event("elector:dispatch");
ceph_assert(op->is_type_election());
switch (op->get_req()->get_type()) {
case MSG_MON_ELECTION:
......
switch (em->op) {
case MMonElection::OP_PROPOSE: //处理OP_PROPOSE消息
handle_propose(op);
return;
......
}
void Elector::handle_propose(MonOpRequestRef op)
{
op->mark_event("elector:handle_propose");
auto m = op->get_req<MMonElection>();
dout(5) << "handle_propose from " << m->get_source() << dendl;
int from = m->get_source().num();
ceph_assert(m->epoch % 2 == 1); // election 确保选举epoch为奇数
uint64_t required_features = mon->get_required_features();
mon_feature_t required_mon_features = mon->get_required_mon_features();
dout(10) << __func__ << " required features " << required_features
<< " " << required_mon_features
<< ", peer features " << m->get_connection()->get_features()
<< " " << m->mon_features
<< dendl;
if ((required_features ^ m->get_connection()->get_features()) &
required_features) {
dout(5) << " ignoring propose from mon" << from
<< " without required features" << dendl;
nak_old_peer(op);
return;
} else if (mon->monmap->min_mon_release > m->mon_release) {
dout(5) << " ignoring propose from mon" << from
<< " release " << (int)m->mon_release
<< " < min_mon_release " << (int)mon->monmap->min_mon_release
<< dendl;
nak_old_peer(op);
return;
} else if (!m->mon_features.contains_all(required_mon_features)) {
// all the features in 'required_mon_features' not in 'm->mon_features'
mon_feature_t missing = required_mon_features.diff(m->mon_features);
dout(5) << " ignoring propose from mon." << from
<< " without required mon_features " << missing
<< dendl;
nak_old_peer(op);
}
logic.receive_propose(from, m->epoch); //比对rank值,决定选举权
}
void ElectionLogic::receive_propose(int from, epoch_t mepoch)
{
......
if (elector->get_my_rank() < from) {
// i would win over them.
if (leader_acked >= 0) { // we already acked someone
ceph_assert(leader_acked < from); // and they still win, of course
ldout(cct, 5) << "no, we already acked " << leader_acked << dendl;
} else {
// wait, i should win!
if (!electing_me) {
elector->trigger_new_election();
}
}
} else { //自身rank值更大
// they would win over me
if (leader_acked < 0 || // haven't acked anyone yet, or
leader_acked > from || // they would win over who you did ack, or
leader_acked == from) { // this is the guy we're already deferring to
defer(from); //确认选举
} else {
// ignore them!
ldout(cct, 5) << "no, we already acked " << leader_acked << dendl;
}
}......}5.同步数据
选举完成后,ceph-mon需要同步leader节点数据,触发MSG_MON_SYNC事件类型,经过调用栈dispatch_op->handle_sync->handle_sync_chunk→sync_finish调用apply_transaction进行数据同步。
void Monitor::sync_finish(version_t last_committed)
{
......
if (sync_full) {
// finalize the paxos commits
auto tx(std::make_shared<MonitorDBStore::Transaction>());
paxos->read_and_prepare_transactions(tx, sync_start_version,
last_committed);
tx->put(paxos->get_name(), "last_committed", last_committed);
dout(30) << __func__ << " final tx dump:\n";
JSONFormatter f(true);
tx->dump(&f);
f.flush(*_dout);
*_dout << dendl;
store->apply_transaction(tx);
}
......
}6.健康检查
当其他节点传入的消息op类型为CEPH_MSG_PING时,mon会执行handle_ping流程去处理,处理过程是先通过op获取到请求的消息,然后构造reply消息进行回复,reply消息的内容是通过mon内置的healthMonitor获取到的状态信息。
void Monitor::dispatch_op(MonOpRequestRef op)
{
.......
case CEPH_MSG_PING:
handle_ping(op);
return;
......
}
void Monitor::handle_ping(MonOpRequestRef op)
{
auto m = op->get_req<MPing>();
dout(10) << __func__ << " " << *m << dendl;
MPing *reply = new MPing;
bufferlist payload;
boost::scoped_ptr<Formatter> f(new JSONFormatter(true));
f->open_object_section("pong");
healthmon()->get_health_status(false, f.get(), nullptr);
get_mon_status(f.get());
f->close_section();
stringstream ss;
f->flush(ss);
encode(ss.str(), payload);
reply->set_payload(payload); //设置发送内容,即健康信息
dout(10) << __func__ << " reply payload len " << reply->get_payload().length() << dendl;
m->get_connection()->send_message(reply); //发送回复
}三、ceph-mon集群正常工作时的工作流程
ceph-mon集群正常运行情况下,mon数量和状态并没有发生变化,因此不会触发重新选举leader的行为,所以此时的ceph-mon更多的是监控和维护集群的状态,它会执行一些监控流程,比如监控集群状态情况、记录日志等。
1.记录日志
ceph-mon通过dout宏来将日志输出到指定文件中,日志路径可通过配置写入log_file变量中,当需要打印日志时,可通过如下方式写入日志到文件中(需要将ceph.conf中对应模块日志级别debug mgr、debug mon等调至20 dout(20)才能生效):
void LogMonitor::update_from_paxos(bool *need_bootstrap)
{
.......
if (g_conf()->mon_cluster_log_to_file) { //获取配置中的log_file变量,该变量存放日志位置
string log_file = channels.get_log_file(channel);
dout(20) << __func__ << " logging for channel '" << channel
<< "' to file '" << log_file << "'" << dendl;
......
}2.监控集群状态
2.1)ceph-mon定期进行对集群其他节点进行状态收集,状态收集的周期默认为30s,可通过mon_data_avail_warn进行配置更改周期长度,状态收集的过程实质是更新monmap、osdmap和pgmap这些表来监控集群的状态。
Option("mon_data_avail_warn", Option::TYPE_INT, Option::LEVEL_ADVANCED)
.set_default(30) //配置默认30s
.add_service("mon")
.set_description("issue MON_DISK_LOW health warning when mon available space below this percentage"),2.2)每个节点的ceph-mon都会收集自身的节点状态,然后互相通信来同步各自节点的状态。
2.2.1)ceph-mon 在处理同步的流程中,根据ceph-mon发出的同步请求MMonSync::OP_CHUNK给leader进行处理,调用Monitor::handle_sync_chunk(MonOpRequestRef op)将数据发送给集群leader节点。
void Monitor::handle_sync(MonOpRequestRef op)
{
auto m = op->get_req<MMonSync>();
dout(10) << __func__ << " " << *m << dendl;
switch (m->op) {
// provider ---------
case MMonSync::OP_CHUNK: //同步
case MMonSync::OP_LAST_CHUNK:
handle_sync_chunk(op);
break;
......
}
void Monitor::handle_sync_chunk(MonOpRequestRef op)
{
......
if (m->op == MMonSync::OP_CHUNK) {
sync_reset_timeout();
sync_get_next_chunk();
} else if (m->op == MMonSync::OP_LAST_CHUNK) {
sync_finish(m->last_committed);
}
......
}2.2.2)选举完成后,ceph-mon需要同步leader节点数据,触发MSG_MON_SYNC事件类型,经过调用栈dispatch_op->handle_sync->handle_sync_chunk→sync_finish调用apply_transaction进行数据同步。
void Monitor::sync_finish(version_t last_committed)
{
......
if (sync_full) {
// finalize the paxos commits
auto tx(std::make_shared<MonitorDBStore::Transaction>());
paxos->read_and_prepare_transactions(tx, sync_start_version,
last_committed);
tx->put(paxos->get_name(), "last_committed", last_committed);
dout(30) << __func__ << " final tx dump:\n";
JSONFormatter f(true);
tx->dump(&f);
f.flush(*_dout);
*_dout << dendl;
store->apply_transaction(tx);
}
......
}其他:ceph-mon通信方式分析
1)vip迁移到另外节点,ceph-mon恢复需要同步哪些数据
当vip发生迁移时,需要同步迁移ceph-mon的节点的/var/lib/ceph/mon/$cluster-$ceph-id/目录内的所有数据,因为该目录存储了ceph-mon的所有数据。可参考:https://www.bookstack.cn/read/ceph-handbook/Advance_usage-mon_backup.mdhttps://www.bookstack.cn/read/ceph-handbook/Advance_usage-mon_backup.md
2)数据通信
建立通信连接后,AsyncMessenger对象中的NetworkStack成员会默认创建三个worker(可配置),每个worker线程被创建时都会被命名为msgr-worker-0/1/2以此类推,这些线程是真正被用来进行通信的,具体通信方式是:每个线程中包含一个EventCenter去获取发生的事件,通过EventCenter内置的EpollDriver对象来获取并处理这些事件,该对象使用epoll网络模型,当某个socket有事件到来时,会被该epoll对象监测到并根据不同的事件类型进行处理,EventCenter中支持的事件类型有file事件和timer事件,主要包含事件的创建、删除以及处理超时事件。
NetworkStack::NetworkStack(CephContext *c, const string &t): type(t), started(false), cct(c)
{
const uint64_t InitEventNumber = 5000;
num_workers = cct->_conf->ms_async_op_threads; // cct->_conf->ms_async_op_threads默认配置为3
for (unsigned i = 0; i < num_workers; ++i) {
Worker *w = create_worker(cct, type, i);
w->center.init(InitEventNumber, i, type);
workers.push_back(w);
}
cct->register_fork_watcher(this);
}
//线程命名为msgr-worker-%u
std::function<void ()> NetworkStack::add_thread(unsigned worker_id)
{
Worker *w = workers[worker_id]; //worker线程
return [this, w]() {
char tp_name[16];
sprintf(tp_name, "msgr-worker-%u", w->id);
ceph_pthread_setname(pthread_self(), tp_name);
const unsigned EventMaxWaitUs = 30000000;
w->center.set_owner(); //创建CenterDriver
ldout(cct, 10) << __func__ << " starting" << dendl;
w->initialize();
w->init_done();
while (!w->done) {
ldout(cct, 30) << __func__ << " calling event process" << dendl;
//创建worker如下
Worker* NetworkStack::create_worker(CephContext *c, const string &type, unsigned i)
{
if (type == "posix")
return new PosixWorker(c, i);
...
}
//EventCenter
class Worker : public Thread {
...
EventCenter center;
...
}
//初始化EventCenter
int EventCenter::init(int nevent, unsigned center_id, const std::string &type)
{
// can't init multi times
ceph_assert(this->nevent == 0);
this->type = type;
this->center_id = center_id;
if (type == "dpdk") {
#ifdef HAVE_DPDK
driver = new DPDKDriver(cct);
#endif
} else {
#ifdef HAVE_EPOLL
driver = new EpollDriver(cct); //使用epoll模型
#else
#ifdef HAVE_KQUEUE
driver = new KqueueDriver(cct);
#else
driver = new SelectDriver(cct);
#endif
#endif
}
......
int fds[2];
if (pipe_cloexec(fds, 0) < 0) { //创建管道
int e = errno;
lderr(cct) << __func__ << " can't create notify pipe: " << cpp_strerror(e) << dendl;
return -e;
}
notify_receive_fd = fds[0];
notify_send_fd = fds[1];
r = net.set_nonblock(notify_receive_fd); //设置非阻塞socket
if (r < 0) {
return r;
}
r = net.set_nonblock(notify_send_fd);
if (r < 0) {
return r;
}
return r;
}
} // Used by internal thread
int create_file_event(int fd, int mask, EventCallbackRef ctxt); //创建file事件
uint64_t create_time_event(uint64_t milliseconds, EventCallbackRef ctxt); //创建timer事件
void delete_file_event(int fd, int mask);
void delete_time_event(uint64_t id);
int process_events(unsigned timeout_microseconds, ceph::timespan *working_dur = nullptr); //处理超时事件



![[STL]详解vector模拟实现](https://img-blog.csdnimg.cn/img_convert/2489d1738e6f13dc4fd2e6f8c2ea6f91.png)