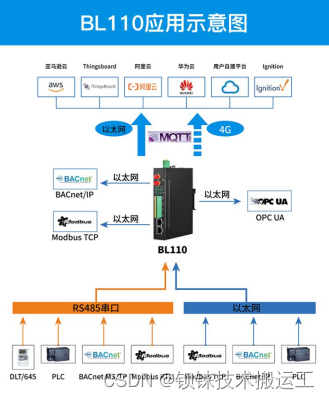
以下内容来自 尚硅谷,写这一系列的文章,主要是为了方便后续自己的查看,不用带着个PDF找来找去的,太麻烦!
第 16 章 时序数据库是怎么存储用户名和密码的
1、InfluxDB内部自带了一个用Go语言写的BlotDB,BlotDB是一个键值数据库,它的功能比较有限,基本上就是专注于存值、读值。同时,因为功能有限,它也可以做的很小很轻量。
2、InfluxDB就是把用户名、密码、token什么的信息存在这样的键值数据库里的。默认情况下,BlotDB的数据会存储在一个单独的文件中,这个文件会在~/.influxdbv2/ 路径下,名称为influxd.bolt。这个文件的路径可以在influxd通过bolt-path配置项来进行修改。
第 17 章 从InfluxDB OSS迁移数据
17.1 将InfluxDB中的数据导出
1、导出InfluxDB数据必须使用influxd命令(注意,不是influx命令)。在InfluxDB2.x中,数据导出是以存储桶为单位的。下面是示例命令:
influxd inspect export-lp \
--bucket-id 12ab34cd56ef \
--engine-path ~/.influxdbv2/engine \
--output-path path/to/export.lp \
--start 2022-01-01T00:00:00Z \
--end 2022compress-01-31T23:59:59Z \
--compress
2、参数讲解:
- influxd inspect,influxd是可以操作 InfluxDB服务进程的命令行工具,inspect是influxd命令的子命令
- export-lp,是export xxx to line protocol的缩写,表示将数据导出为行协议。它是inspect的子命令。
- bucket-id,inspect的必须参数。存储桶的id
- engine-path,inspect的必须参数,不过有默认值
~/.influxdbv2/engine。所以如果你的数据目录是~/.influxdbv2/engine那么不指定这个参数也行。 - output-path,inspect的必须参数,指定输出文件的位置。
- start,非必须,导出数据的开始时间
- end,非必须,导出数据的结束时间。
- compress,建议启用,如果启用了,那么influxd会使用gzip的方式压缩输出的数据。
17.2 示例:将InfluxDB中的数据导出
1、这次,我们尝试导出test_init的数据导出,截至目前,这个bucket里面的数据应该是当前最多的。
2、首先,你可以使用influx-cli也可以使用Web UI 来查看我们想要导出的bucket对应的ID。这里,选择使用 Web UI,可以看到 test_init 存储桶的 ID 为0a2e821ccd12854a。

3、于是,我们运行下面的命令,尝试把数据导出。
./influxd inspect export-lp --bucket-id a2e821ccd12854a --out-path 0./oh.lp
4、这条命令会把test_init存储桶里的数据以InfluxDB行协议的格式导出到当前目录下的oh.lp文件中。正常情况下,程序会输出一系列读写信息。

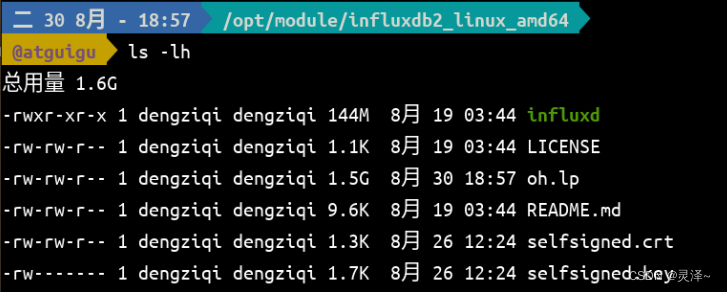
5、使用下面的命令查看当前路径下的文件及其大小。ls -lh,ls的h参数,可以将文件的字节数打印为更容易阅读的MB、GB单位。可以看到,我们导出的数据文件oh.lp有1.5G大小。
6、现在,我们使用tail命令来查看一下文件的内容。 命令输出的是文件的最后 15 行内容,可以看到里面全是InfluxDB行协议的数据。
tail -15 ./oh.lp
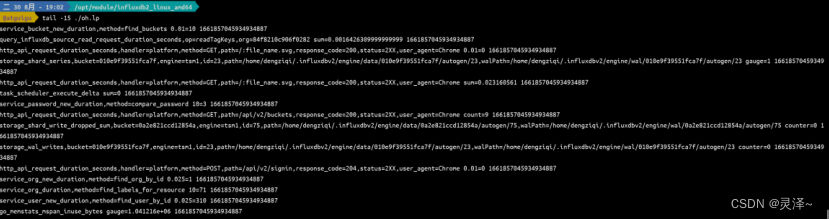
7、不过,我们要注意到InfluxDB行协议的一个特点,其实对于整个文件来说,多条数据的measurement其实是重复的,tagset的重复率也不低,filed的变化也不会很大。这种高度重复的数据其实是非常适合压缩算法的。
17.3 示例:导出数据时压缩
1、现在,我们重新运行数据导出的命令,这次在命令的最后加上–compress参数。不必担心目录下已经存在oh.lp文件,程序会直接将其覆盖的。
./influxd inspect export-lp --bucket-id a2e821ccd12854a --out-path 0./oh.lp - -compress
2、使用ls命令再次查看文件大小。可以看到文件从之前的 1 .5G变成了现在的 9 1M,压缩率非常高。
ls -lh