以下内容来自 尚硅谷,写这一系列的文章,主要是为了方便后续自己的查看,不用带着个PDF找来找去的,太麻烦!
第 13 章 定时任务
13.1 什么是定时任务
1、InfluxDB任务是一个定时执行的FLUX脚本,它先查询数据,然后以某种方式进行修改或聚合,然后将数据写回InfluxDB或执行其他操作。
13.2 示例:将数据转成json发给别的应用
13.2.1 创建任务的途径
1、有很多方式可以帮你创建任务,比如DataExplorer、Notebook、HTTP API和 influx-cli。不过,此处我们为了还愿定时任务的本来面貌,我们会使用influx-cli去创建定时任务。
13.2.2 本任务的需求
1、我们的定时任务要实现下面的需求。
- 每 30s调度一次
- 查询最近 30 s的第一条数据
- 将数据转为json
- 将json通过HTTP发送SimpleHttpPostServer。
2、SimpleHttpPostServer是自己用go语言写的一个最简单的HTTP POST服务,它的功能就是接收一个POST请求,然后把请求体重的内容转为字符串打印出来。访问github地址https://github.com/realdengziqi/simpleHttpPostServer ,下载源码自行编译,或者在发行记录中下载我已编译好的linux-x64可执行程序。
13.2.3 启动simpleHttpPostServer
1、下载simpleHttpPostServer后,cd到其所在目录,执行simpleHttpPostServer程序。效果如下图所示,终端会被阻塞。

13.2.4 测试simpleHttpPostServer是否正常工作
1、我们可以使用curl来验证simpleHttpPostServer是否正常工作。使用下面的命令,向simpleHttpPostServer发送一个POST请求。
curl -POST <http://localhost:8080/> -d '{"hello":"world"}'
2、之后,查看simpleHttpPostServer所占的终端,如果终端出现了一条新的数据,那么说明simpleHttpPostServer工作正常。

13.2.5 在DataExplorer中编写FLUX脚本
1、我们首先在DataExplorer中把查询到转为json的这段逻辑写好。我们要查询的是test_init存储桶下的 go_goroutines测量。这个测量反应的是我们当前InfluxDB程序中的goroutines(轻量级线程)数量。
2、打开DataExplrer,编写如下代码
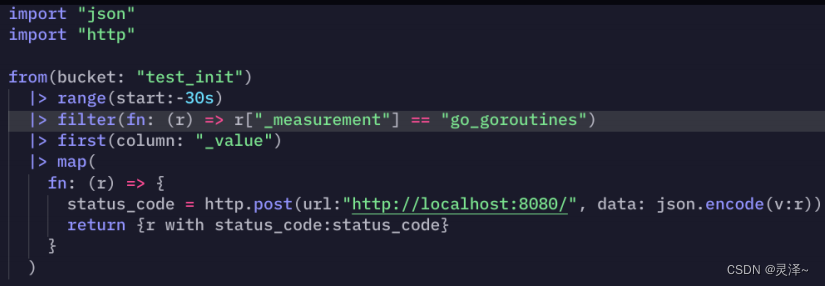
3、代码解释:
- from -> range -> filter,指定了数据源并取出了我们想要的序列,其中range的start参数我们写死-30s。
- first函数,Flux查询InfluxDB返回的数据默认是按照时间从先到后排序的,first函数配合前面的查询相当于只取了最近 30 s的第一条数据。
- map函数,我们在map函数里完成数据的发送。这里需要注意,因为map函数要求必须返回record,而且输出的record不能和输入的record一模一样。所以,结尾return的时候,我们使用了with语法,给map输出的record增加了一个字段。也就是我们发出http
请求响应的状态码。在map中的匿名函数,我们使用了http.post向http://localhost:8080/发送了一条json格式的数据。
13.2.6 运行代码并观察效果
1、现在,我们点击SUBMIT按钮,执行这个FLUX查询脚本,观察DataExplorer返回的数据和simpleHttpPostServer的输出。
13.2.6.1 观察DataExplorer
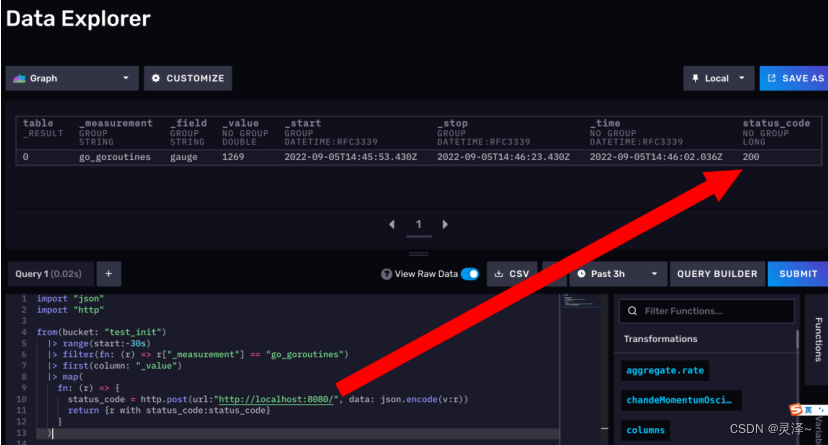
1、点击SUBMIT后,点一下view Raw Data按钮,我们关注table格式的数据。可以看到,现在数据中多了status_code一列,而且它的值是 200 。而且,因为first()函数的作用,这次查询,我们只产生了一行数据。
13.2.6.2 观察 SimpleHttpPostServer
1、可以看到,我们的httpServer顺利收到了JSON。

2、截至目前,说明我们的 FLUX 脚本可以实现需求,现在的问题就是如何将这份脚本设为定时任务。
13.2.7 配置定时调度
1、现在,在我们的查询逻辑前面插入一行。
option task = { name: "example_task", every: 30s, offset:0m }
2、表示,我们做了一个设定,指定了一个名为example_task的任务。这个任务每隔 30 秒执行一次。offset 这里暂时设为 0m,后面我们会专门讲这里的offset有什么意义。
13.2.8 使用influx-cli创建任务
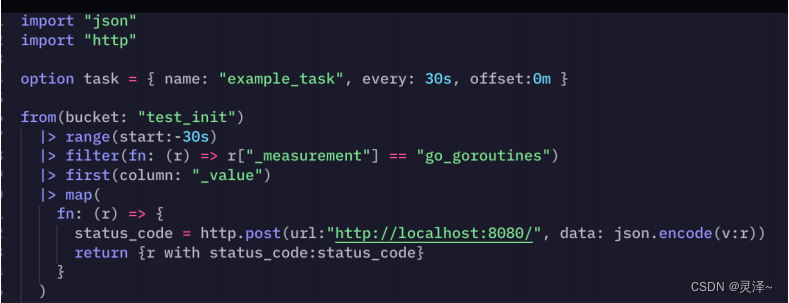
1、虽然我们在 DataExplorer 里写了一个 option,但是具体到option会不会生效,必须要看FLUX脚本再跟 InfluxDB 的那个HTTP API进行交互。所以这里点击SUBMIT按钮只会再执行一次查询,option task并不会生效。这里,我们会先用influx-cli创建一遍任务。先把 Flux 脚本复制出来,在 /opt/modules/examples 里创建一个文件,就叫example_task.flux吧。将之前写的脚本粘贴进去。
import "json"
import "http"
option task = { name: "example_task", every: 30s, offset:0m }
from(bucket: "test_init") |> range(start:-30s)
|> filter(fn: (r) => r["_measurement"] == "go_goroutines")
|> first(column: "_value")
|> map(
fn: (r) => {
status_code = http.post(url:"http://localhost:8080/", data:json.encode(v:r))
return {r with status_code:status_code}
}
)
2、使用下面的命令,创建FLUX任务。
./influx task create --org atguigu -f /opt/module/examples/example_task.flux
3、可以看到,我们的任务已经成功创建了。

13.2.9 在Web UI上查看定时任务
1、点击左侧工具栏的 按钮,查看任务列表。可以看到,任务已经成功创建。
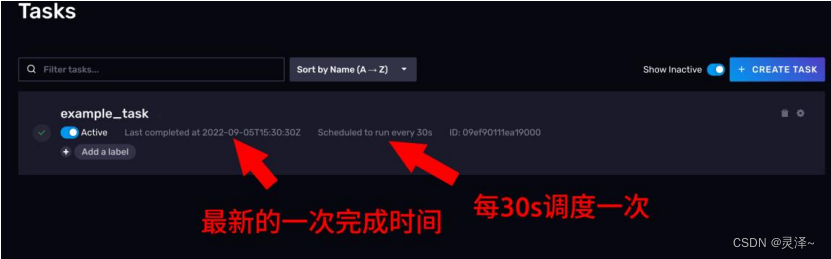
2、点一下任务的名称,可以进去看任务执行详情。
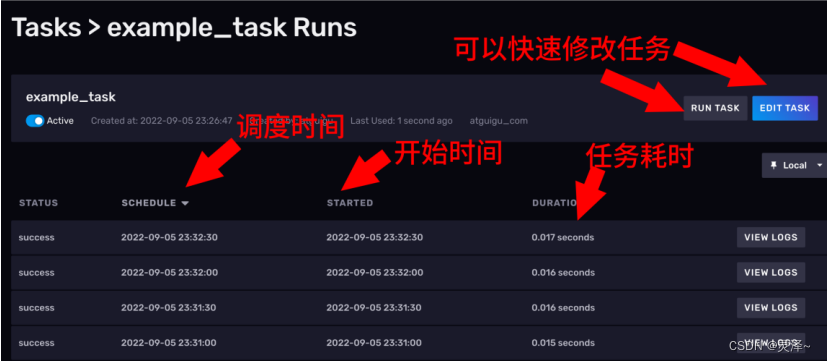
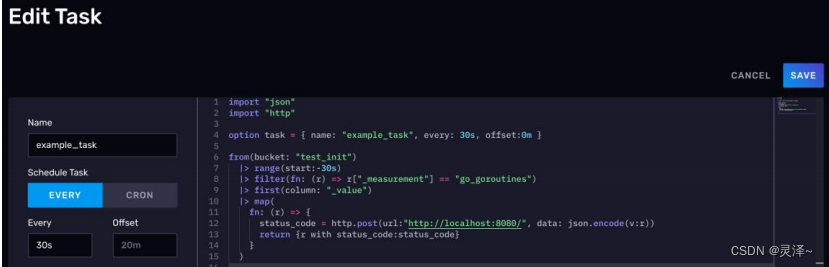
3、详情页面上,可以看到任务的调度时间、开始时间、任务耗时等信息。在最上方点击 EDIT TASK按钮,可以看到当时的任务定义。在这里,你也可以直接修改任务的定义。
13.2.10 在接收端查看定时任务效果
1、数据的接收端就是 simpleHttpPostServer。可以看到,我们的接收端目前就是每隔 30s收到一条json数据。

13.2.11 使用DataExplorer创建任务
1、这一次,我们用DataExplorer来创建任务。现在,我们先将已经存在的任务删除。
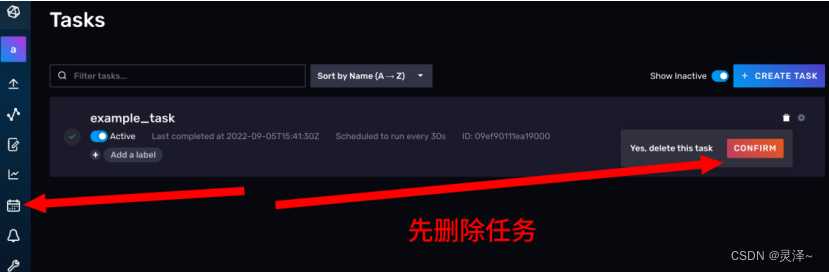
2、打开DataExplorer,编辑FLUX脚本,将我们之前写的查询脚本粘进去。注意,要删除option一行。如下图所示:
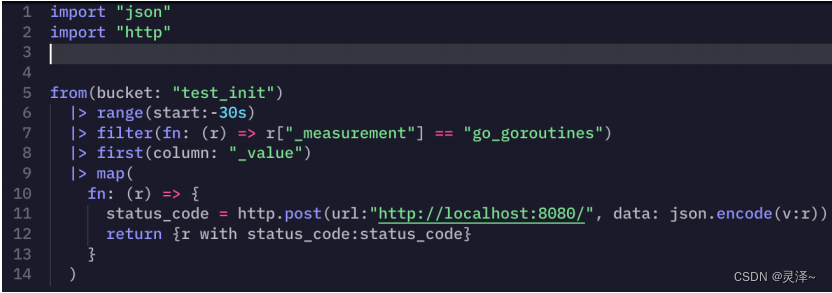
3、完成上面的操作后,点击DataExplorer页面右上方的SAVE AS按钮,在弹出的对话框中选择TASK选项卡。
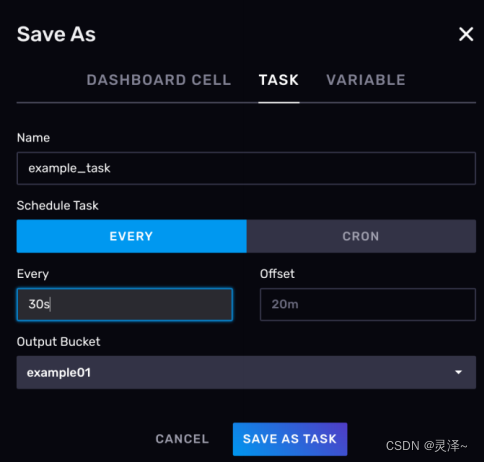
- Name,填写为example_task
- Every,填写 30 s
- Offset可以空着,这样默认就是 0 。此处显示的 20m是前端渲染效果,和具体的任务执行无关。
- 此处的OutputBucket的填写需要注意,本来我们自己编写的脚本并没有指定要把数据回写到InfluxDB,但是如果从Web UI创建定时任务的话,Output Bucket不能不设,这样会造成回写操作。这也是为什么我们之前不用Web UI创建任务的原因。
配置好后,点击SAVE AS TASK。
13.2.12 再次查看任务详情(注意Web UI的小动作)
1、现在,我们再次回到任务列表。可以看到,任务已经成功创建,并且已经正常运行。
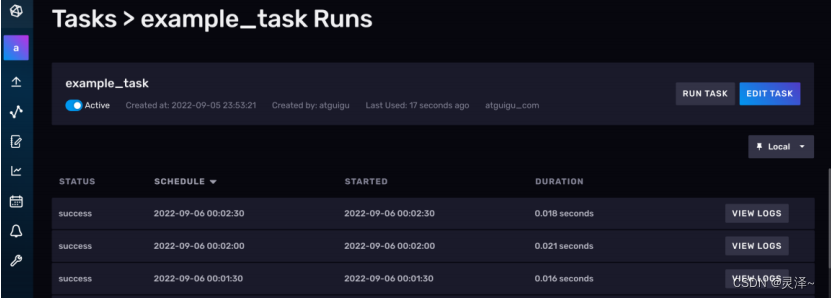
2、点击EDIT TASK按钮,查看我们的FLUX脚本。你会惊奇的发现,我们的FLUX代码居然被修改了,原本不回写数据库的操作被强制加上了一个to函数。另外,可以看到我们代码的前面也被加上了一个option task代码,这说明Web UI的页面点按操作只不过是帮我们完成了手敲代码的几个步骤。
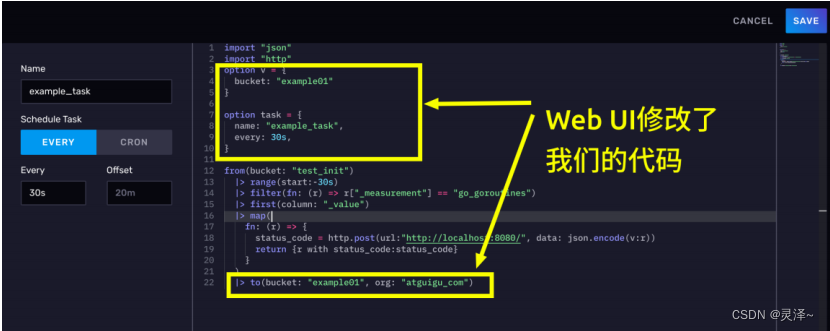
3、总的来说,看开发者能否接收代码被隐式修改。如果这种行为无法接受,那么强烈建议用influx-cli的方式去创建任务。
13.3 数据迟到问题
1、option中的offset是专门用来帮我们处理迟到问题的。首先,我们来关注一个迟到的场景,如下图所示。我们的定时任务每次查询最近 30 秒的数据。同时,调度的间隔设为每 30 秒执行一次。
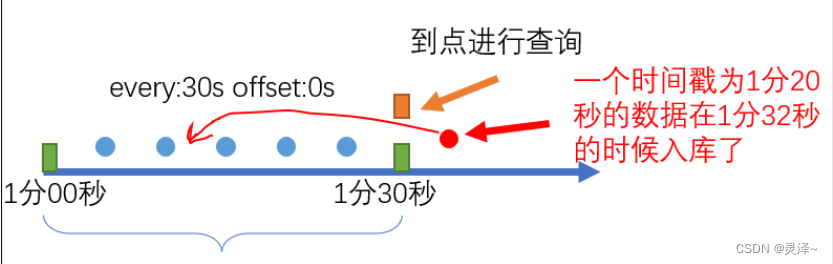
2、这个时候,由于网络的延迟,本该 1 分 20 秒入库的数据, 1 分 32 秒的时候才来。但在 1 分 30 秒的时候,我们的查询已经执行完了。这个时候我们错过了 1 分 20 秒的数据。这个时候,如果我们将offset设为 5 秒。如下图所示:
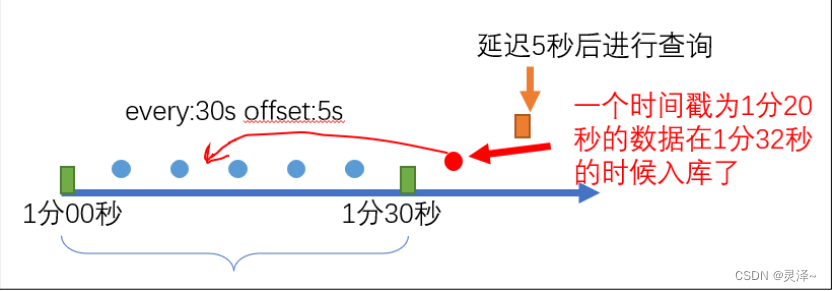
3、定时任务的执行时间向后延迟了 5 秒,但是查询的还是原来范围的数据。这个时候定时任务执行的时间是 1 分 35 秒。原先的迟到数据就能被我们查询到了。但是如果你的数据延迟了10秒,那又查不到了,所以这个参数的值需要根据你的业务的速度来考虑。
13.4 cron表达式
1、其实InfluxDB的定时任务还支持cron表达式。option的写法如下:
option task = {
// ...
cron: "0 * * * *",
}
2、本文就不做详细演示了。
13.4.1 参考资料
1、crontab是linux上一个可以设置定时执行命令的工具。cron表达式就是最早在就是在crontab中使用的一种表示时间间隔的表达式。相关资料可以参考菜鸟教程开源的cron教程。 https://www.runoob.com/linux/linux-comm-crontab.html
13.4.2 cron辅助开发工具
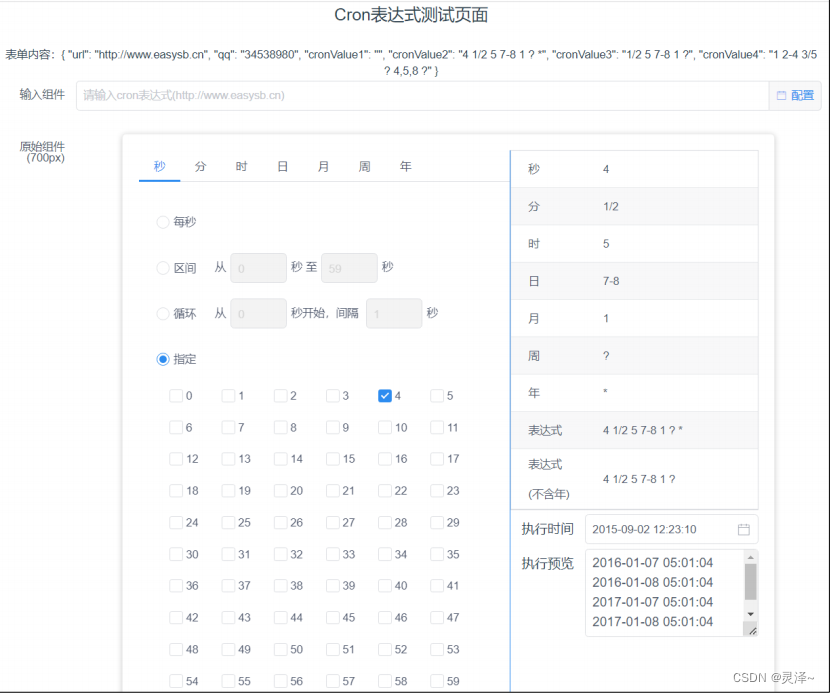
1、如果是对cron非常熟练,一口气能直接写对那当然是很好的。如果开发时一次写不准可以百度一些在线的cron生成工具作为辅助。不 过 , 这 里 我 更 推 荐 gitee 上 的 开 源 cron 生 成 器 项 目 。 比 如 :https://gitee.com/toktok/easy-cron 这一个基于node.js的corn生成工具。你可以把代码拉下来自己部署,也可以使用它的在线demo。http://www.easysb.cn/open/easy-cron/index.html>
2、这个工具可以同时支持 5 、 6 、 7 字段的cron表达式。
13.5 补充:InfluxDB抓取任务的本质
1、之前我们在Web UI里设置的抓取任务,其背后其实就是定时执行的FLUX脚本。只不过InfluxDB在API上将他们分开了。
2、在当前的FLUX版本中,experimental/prometheus库为我们提供了采集prometheus格式数 据 的 能 力 。详 细 可 以 参 考 https://docs.influxdata.com/flux/v0.x/prometheus/scrape-prometheus/



![#P1108. [NOIP2008提高组] 双栈排序](https://kedaoi.cn/p/1108/file/R45JnYQx2HuERggK93QcZ.png)