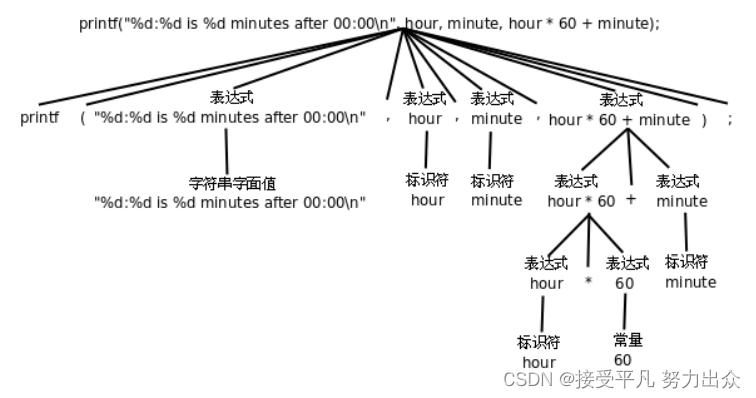
卡尔曼滤波器的过程
-
卡尔曼滤波器的过程分为:
-
状态方程:
x k = A x k − 1 + B u k − 1 + ω k − 1 z k = H x k + ν k 这 样 就 得 到 了 状 态 方 程 和 观 测 方 程 的 表 达 式 其 中 x k 是 状 态 向 量 , A 是 转 移 矩 阵 , B 是 输 入 转 换 为 状 态 的 矩 阵 , u k 是 系 统 输 入 , ω k 是 系 统 噪 声 z k 是 测 量 值 ( 不 一 定 为 标 量 ) , H 是 状 态 向 量 到 测 量 值 的 转 换 矩 阵 , ν k 是 测 量 噪 声 x_k=Ax_{k-1}+Bu_{k-1}+\omega_{k-1} \\ z_k=Hx_k+\nu_k \\ 这样就得到了状态方程和观测方程的表达式 \\ 其中 x_k 是状态向量,A是转移矩阵,B是输入转换为状态的矩阵,u_k是系统输入,\omega_{k}是系统噪声 \\ z_k是测量值(不一定为标量),H是状态向量到测量值的转换矩阵,\nu_k是测量噪声 xk=Axk−1+Buk−1+ωk−1zk=Hxk+νk这样就得到了状态方程和观测方程的表达式其中xk是状态向量,A是转移矩阵,B是输入转换为状态的矩阵,uk是系统输入,ωk是系统噪声zk是测量值(不一定为标量),H是状态向量到测量值的转换矩阵,νk是测量噪声 -
预测:
-
计算先验: x ^ k − = A x ^ k − 1 + B u k − 1 \hat{x}_k^-=A\hat{x}_{k-1}+Bu_{k-1} x^k−=Ax^k−1+Buk−1
-
计算先验误差协方差矩阵: P k − = A P k − 1 A T + Q P_k^-=AP_{k-1}A^T+Q Pk−=APk−1AT+Q
-
-
校正:
3. 计算卡尔曼增益: K k = P k − H T ( H P k − H T + R ) − 1 K_k=P_k^-H^T(HP_k^-H^T+R)^{-1} Kk=Pk−HT(HPk−HT+R)−1
4. 计算后验估计: x ^ k = x ^ k − + K k ( z k − H x ^ k − ) \hat{x}_k=\hat{x}_k^- + K_k(z_k-H\hat{x}_k^-) x^k=x^k−+Kk(zk−Hx^k−)
5. 更新先验误差协方差矩阵: P k = ( I − K k H ) P k − P_k=(I-K_kH)P_k^- Pk=(I−KkH)Pk−
-
加深理解
字数超出,参考 【【卡尔曼滤波器】1_递归算法_Recursive Processing】 https://www.bilibili.com/video/BV1ez4y1X7eR/?share_source=copy_web&vd_source=f888a64d6daca22a15191528d732f02a
卡尔曼滤波器详细推导
字数超出,参考 【【卡尔曼滤波器】1_递归算法_Recursive Processing】 https://www.bilibili.com/video/BV1ez4y1X7eR/?share_source=copy_web&vd_source=f888a64d6daca22a15191528d732f02a
卡尔曼滤波器的应用
python中使用
-
在 filterpy 这个包中已经实现了卡尔曼滤波器,其一般用法为:
# 首先从 filterpy 中导入卡尔曼滤波器 from filterpy.kalman import KalmanFilter # 创建实例 # dim_x 是状态向量的维度,dim_z 是测量向量的维度 kf = KalmanFilter(dim_x=*, dim_z=*) # 设置初始状态,即 \hat{x}_0,维度为 (dim_x, 1) kf.x = np.array([[*], [*], ...]) # 设置状态转移矩阵,即公式中的 A 矩阵,维度为 (dim_x, dim_x) kf.F = np.array() # 设置状态向量到测量值的转换矩阵,即前面公式中的 H 矩阵,维度为 (dim_z, dim_x) kf.H = np.array() # 设置过程噪声的协方差矩阵 Q,即公式中 \omega 的协方差矩阵,维度为 (dim_x, dim_x) # 该值往往不确定,需要根据场景自己设置,寻找一个能得到良好结果的值 kf.Q = np.array() # 设置测量噪声的协方差矩阵 R,即公式中 \nu 的协方差矩阵,维度为 (dim_z, dim_z) # 该值往往也不确定,需要自己确定 kf.R = np.array() # 设置先验误差的协方差矩阵 P,即公式中的 P,维度为 (dim_x, dim_x) # 由于该值后续会迭代更新,因此初值不影响,但如果给定的初始值 x 不可信,我们会将P中对应位置设置一个较大的数,来表示第一次先验值的不可信,默认是一个单位矩阵 kf.P = np.array() # 创建一个列表,记录所有过程中的估计值 x_estimate = [] # 开始迭代预测 for i in range(数据长度): kf.predict() # 先执行第一次预测 kf.update(z_i) # 然后根据当前测量值进行更新,测量值z的维度为 (dim_z, 1) x_estimate.append(kf.x) # 保存估计值 -
我们来用它模拟一个二维平面上的物体轨迹跟踪
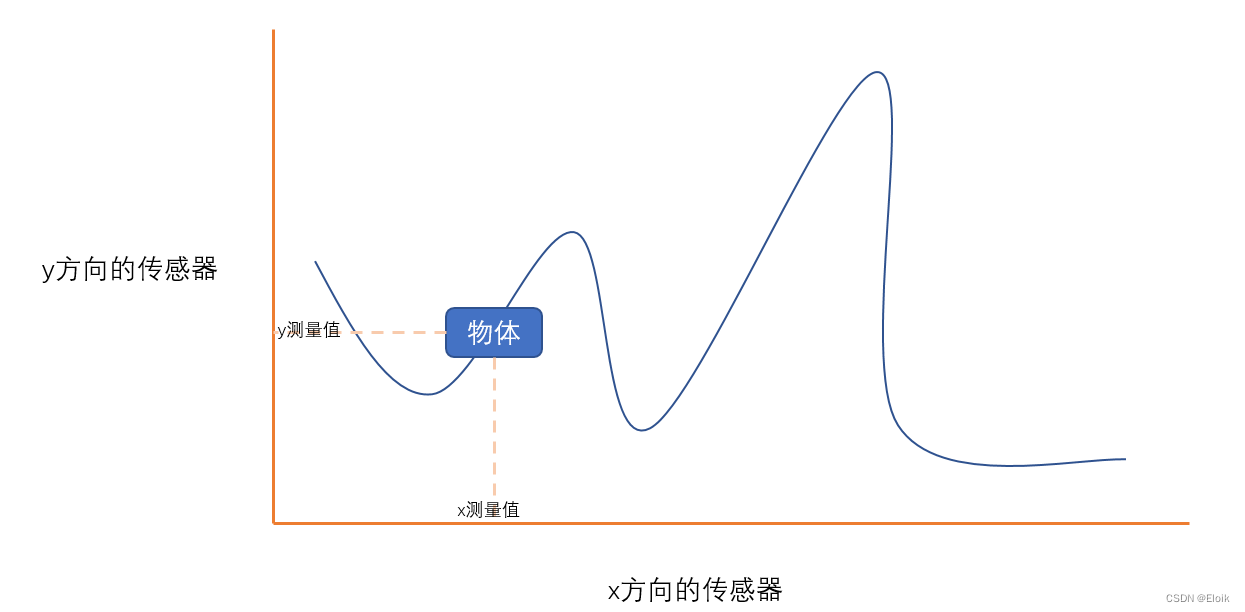
假如在一个平面上有一个运动的物体,它的轨迹如上图所示
在
x
和
y
方
向
各
有
一
个
定
位
传
感
器
,
每
隔
一
个
时
间
间
隔
就
会
得
到
物
体
当
前
的
x
和
y
位
置
的
测
量
值
因
此
我
们
的
测
量
值
向
量
就
是
z
=
(
x
y
)
而
对
于
物
体
来
说
,
它
本
身
的
状
态
包
括
x
和
y
方
向
的
位
置
以
及
x
和
y
方
向
的
速
度
因
此
我
们
可
以
定
义
状
态
向
量
x
=
(
x
y
v
x
v
y
)
,
此
时
我
们
可
以
计
算
出
状
态
向
量
到
测
量
向
量
的
转
移
矩
阵
H
显
然
有
z
=
(
x
y
)
=
(
1
0
0
0
0
1
0
0
)
(
x
y
v
x
v
y
)
,
因
此
H
=
(
1
0
0
0
0
1
0
0
)
假
如
上
一
个
状
态
向
量
x
k
−
1
=
(
x
k
−
1
y
k
−
1
v
x
k
−
1
v
y
k
−
1
)
假
如
速
度
不
变
,
那
么
显
然
有
{
x
k
=
x
k
−
1
+
v
x
k
−
1
Δ
t
y
k
=
y
k
−
1
+
v
y
k
−
1
Δ
t
v
x
k
=
v
x
k
−
1
v
y
k
=
v
y
k
−
1
即
x
k
=
(
1
0
Δ
t
0
0
1
0
Δ
t
0
0
1
0
0
0
0
1
)
x
k
−
1
故
状
态
转
移
矩
阵
A
=
(
1
0
Δ
t
0
0
1
0
Δ
t
0
0
1
0
0
0
0
1
)
,
过
程
输
入
一
项
为
0
在x和y方向各有一个定位传感器,每隔一个时间间隔就会得到物体当前的x和y位置的测量值 \\ 因此我们的测量值向量就是 z=\begin{pmatrix}x\\y\end{pmatrix} \\ 而对于物体来说,它本身的状态包括x和y方向的位置以及x和y方向的速度 \\ 因此我们可以定义状态向量 x=\begin{pmatrix}x\\y\\v_x\\v_y\end{pmatrix},此时我们可以计算出状态向量到测量向量的转移矩阵 H \\ 显然有 z=\begin{pmatrix}x\\y\end{pmatrix}=\begin{pmatrix}1&0&0&0\\0&1&0&0\end{pmatrix}\begin{pmatrix}x\\y\\v_x\\v_y\end{pmatrix},因此 H=\begin{pmatrix}1&0&0&0\\0&1&0&0\end{pmatrix} \\ 假如上一个状态向量 x_{k-1} = \begin{pmatrix}x_{k-1}\\y_{k-1}\\v_{x_{k-1}}\\v_{y_{k-1}}\end{pmatrix} \\ 假如速度不变,那么显然有 \begin{cases} x_k=x_{k-1}+v_{x_{k-1}}\Delta t \\ y_k=y_{k-1}+v_{y_{k-1}}\Delta t \\ v_{x_k} = v_{x_{k-1}} \\ v_{y_k} = v_{y_{k-1}} \end{cases} \\ 即 x_k = \begin{pmatrix} 1&0& \Delta t &0 \\ 0&1& 0 &\Delta t \\ 0&0&1&0 \\ 0&0&0&1 \end{pmatrix} x_{k-1} \\ 故状态转移矩阵 A=\begin{pmatrix} 1&0& \Delta t &0 \\ 0&1& 0 &\Delta t \\ 0&0&1&0 \\ 0&0&0&1 \end{pmatrix},过程输入一项为 0
在x和y方向各有一个定位传感器,每隔一个时间间隔就会得到物体当前的x和y位置的测量值因此我们的测量值向量就是z=(xy)而对于物体来说,它本身的状态包括x和y方向的位置以及x和y方向的速度因此我们可以定义状态向量x=⎝⎜⎜⎛xyvxvy⎠⎟⎟⎞,此时我们可以计算出状态向量到测量向量的转移矩阵H显然有z=(xy)=(10010000)⎝⎜⎜⎛xyvxvy⎠⎟⎟⎞,因此H=(10010000)假如上一个状态向量xk−1=⎝⎜⎜⎛xk−1yk−1vxk−1vyk−1⎠⎟⎟⎞假如速度不变,那么显然有⎩⎪⎪⎪⎨⎪⎪⎪⎧xk=xk−1+vxk−1Δtyk=yk−1+vyk−1Δtvxk=vxk−1vyk=vyk−1即xk=⎝⎜⎜⎛10000100Δt0100Δt01⎠⎟⎟⎞xk−1故状态转移矩阵A=⎝⎜⎜⎛10000100Δt0100Δt01⎠⎟⎟⎞,过程输入一项为0
上面我们已经得到了
A
A
A 和
H
H
H 的值,还有
Q
Q
Q,
R
R
R,
P
P
P 未知,因为我们使用正态分布对真实值添加噪声,因此正态分布的方差就是
R
R
R 矩阵对角线的值,则
R
R
R 矩阵也为已知,
P
P
P 矩阵会随迭代过程更新,初始值并不重要,我们使用默认的单位矩阵,而对于
R
R
R 的设置,详见下面的代码
import numpy as np
from scipy import stats
from filterpy.kalman import KalmanFilter
import matplotlib.pyplot as plt
# 采样1000次
size = 1000
# 定义真实的轨迹值,其中 x 轴匀速变化,y轴按函数变化
x_true = np.linspace(0, 100, size)
y_true = (np.sin(np.pi * np.sqrt(x_true)) + np.log(x_true + 1)) * (np.sqrt(x_true) - 7)
# 定义每一步的观测值,在真实值上添加测量噪声作为测量值
sigma_x2 = 0.5 # x方向上测量噪声的方差
sigma_y2 = 0.5 # y方向上测量噪声的方差
x_mea = x_true + stats.norm.rvs(loc=0, scale=sigma_x2, size=size)
y_mea = y_true + stats.norm.rvs(loc=0, scale=sigma_y2, size=size)
# 创建实例
kf = KalmanFilter(dim_x=4, dim_z=2)
# 设置采样时间间隔,与前面 x_true=np.linspace 的采样间隔相等,即每隔0.1个单位采样一次
t = 100 / size
# 设置初始状态为 x方向位置0,y方向位置0,x方向速度1,y方向速度1
kf.x = np.array([[0], [0], [1], [1]])
# 设置状态转移矩阵
kf.F = np.array([[1, 0, t, 0], [0, 1, 0, t], [0, 0, 1, 0], [0, 0, 0, 1]])
# 设置状态向量到测量值的转换矩阵
kf.H = np.array([[1, 0, 0, 0], [0, 1, 0, 0]])
# 设置过程噪声的协方差矩阵 Q,该值参考了 《Bayesian Filtering and Smoothing》,Simo Sarkka著
# https://zhuanlan.zhihu.com/p/148046908
qc1, qc2 = 1, 1
kf.Q = np.array([[qc1 * t ** 3 / 3, 0, qc1 * t ** 2 / 2, 0],
[0, qc2 * t ** 3 / 3, 0, qc2 * t ** 2 / 2],
[qc1 * t ** 2 / 2, 0, qc1 * t, 0],
[0, qc2 * t ** 2 / 2, 0, qc2 * t]])
# 设置测量噪声的协方差矩阵 R,使用了前面人为制造噪声时的方差
kf.R = np.array([[sigma_x2, 0], [0, sigma_y2]])
# 设置先验误差的协方差矩阵 P,按默认的单位矩阵进行初始化
kf.P = np.eye(4)
# 记录估计过程
x_pred = []
y_pred = []
for i in range(size):
kf.predict()
kf.update(np.array([[x_mea[i]], [y_mea[i]]]))
# 将预测结果保存
x_pred.append(kf.x[0])
y_pred.append(kf.x[1])
# 绘制结果
plt.plot(x_true, y_true, color='red', label="true value")
plt.plot(x_mea, y_mea, alpha=0.2, color='green', label='measurement value')
plt.plot(x_pred, y_pred, color='blue', label="estimate value")
plt.legend()
plt.show()
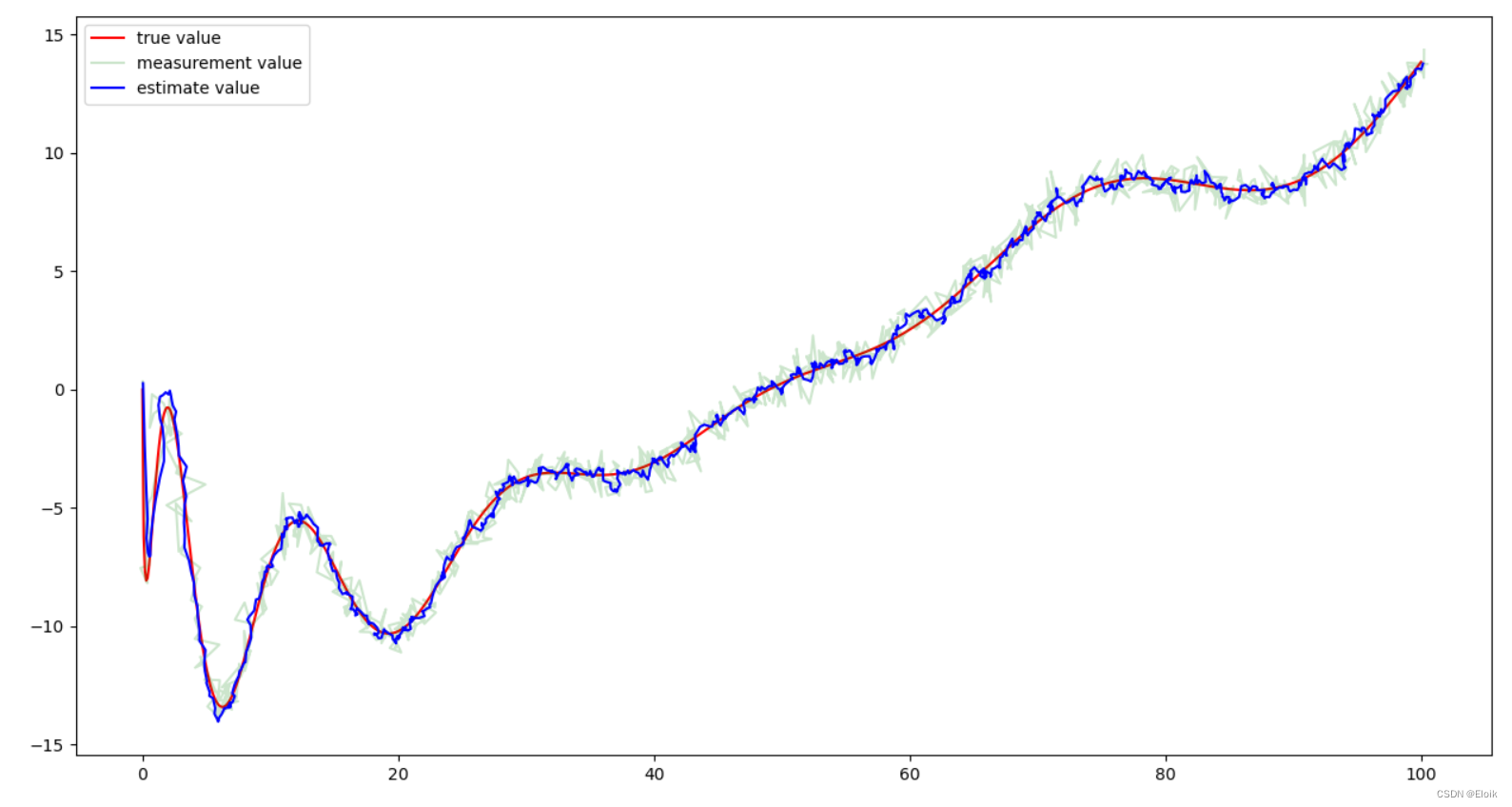
从图中可以看出,蓝色的估计值相较于绿色的观测值来说,更加靠近红色的真实值,这说明卡尔曼滤波器在本例中确实减小了测量噪声的影响。
单目标追踪
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JwaPBrnz-1670688580090)(./assets/1.gif)]](https://img-blog.csdnimg.cn/0826ece88f6e41168047709d5fea9e2a.gif)
-
现在我们将目光放在单目标的追踪上面,以上面的只因为例,我们想要对其脸部进行追踪,如果使用
RetinaFace模型对每一帧进行预测,将会在每一帧得到一个预测框,下面我们将预测框绘制在视频中![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mBM0cBO0-1670688580091)(./assets/pred.gif)]](https://img-blog.csdnimg.cn/0d604ac75f1146d985eaf7c609994d4b.gif)
可以看出预测框精度虽好,但放在视频中会出现不平滑的现象,为了将框变得更加平滑,我们可以使用卡尔曼滤波来完成这项任务
对 于 预 测 框 来 说 , 它 形 如 ( x m i n , y m i n , x m a x , y m a x ) , 代 表 了 框 的 左 上 角 坐 标 和 右 下 角 坐 标 在 追 踪 任 务 中 , 我 们 一 般 将 其 变 成 另 一 种 表 达 形 式 : ( c x , c y , s , r ) 其 中 c x 、 c y 表 示 框 的 中 心 坐 标 , s 表 示 框 的 面 积 , r 表 示 框 的 宽 高 比 在 此 基 础 上 , 对 中 心 坐 标 和 框 的 面 积 增 加 变 化 速 度 , 那 么 框 的 状 态 向 量 表 示 为 x = ( c x c y s r c x v c y v s v ) 此 时 我 们 可 以 计 算 出 状 态 向 量 到 测 量 向 量 的 转 移 矩 阵 H 显 然 有 z = ( c x c y s r ) = ( 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 ) ( c x c y s r c x v c y v s v ) , 因 此 H = ( 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 0 0 0 ) 假 设 上 一 个 状 态 向 量 x k − 1 = ( c x k − 1 c y k − 1 s k − 1 r k − 1 c x v k − 1 c y v k − 1 s v k − 1 ) , 假 如 速 度 不 变 , 显 然 有 { c x k = c x k − 1 + c x v k − 1 Δ t c y k = c y k − 1 + c y v k − 1 Δ t s k = s k − 1 + s v k − 1 Δ t r k = r k − 1 c x v k = c x v k − 1 c y v k = c y v k − 1 s v k = s v k − 1 即 x k = ( 1 0 0 0 0 Δ t 0 0 0 1 0 0 0 0 Δ t 0 0 0 1 0 0 0 0 Δ t 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 ) x k − 1 , 在 本 例 中 , Δ t 是 一 帧 , 因 此 这 里 Δ t = 1 故 状 态 转 移 矩 阵 A = ( 1 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 1 0 0 0 0 1 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 ) 对于预测框来说,它形如\space (x_{min}, y_{min}, x_{max}, y_{max}),代表了框的左上角坐标和右下角坐标 \\ 在追踪任务中,我们一般将其变成另一种表达形式:(cx, cy, s, r) \\ 其中\space cx、cy \space表示框的中心坐标,s \space表示框的面积,r \space表示框的宽高比 \\ 在此基础上,对中心坐标和框的面积增加变化速度,那么框的状态向量表示为\space x=\begin{pmatrix} cx \\cy \\s \\r \\cx_v \\cy_v \\s_v\end{pmatrix} \\ 此时我们可以计算出状态向量到测量向量的转移矩阵\space H \\ 显然有\space z=\begin{pmatrix}cx\\cy\\s\\r \end{pmatrix} =\begin{pmatrix} 1&0&0&0&0&0&0 \\ 0&1&0&0&0&0&0 \\ 0&0&1&0&0&0&0 \\ 0&0&0&1&0&0&0 \end{pmatrix} \begin{pmatrix} cx \\cy \\s \\r \\cx_v \\cy_v \\s_v\end{pmatrix},因此\space H=\begin{pmatrix} 1&0&0&0&0&0&0 \\ 0&1&0&0&0&0&0 \\ 0&0&1&0&0&0&0 \\ 0&0&0&1&0&0&0 \end{pmatrix} \\ 假设上一个状态向量 \space x_{k-1} = \begin{pmatrix} cx_{k-1} \\cy_{k-1} \\s_{k-1}\\r_{k-1}\\cx_{v_{k-1}}\\cy_{v_{k-1}} \\s_{v_{k-1}}\end{pmatrix},假如速度不变,显然有 \begin{cases} cx_k = cx_{k-1} + cx_{v_{k-1}} \Delta t \\ cy_k = cy_{k-1} + cy_{v_{k-1}} \Delta t \\ s_k = s_{k-1} + s_{v_{k-1}} \Delta t \\ r_k = r_{k-1} \\ cx_{v_k} = cx_{v_{k-1}} \\ cy_{v_k} = cy_{v_{k-1}} \\ s_{v_k} = s_{v_{k-1}} \end{cases} \\ 即\space x_k = \begin{pmatrix} 1&0&0&0&0&\Delta t&0&0 \\ 0&1&0&0&0&0&\Delta t&0 \\ 0&0&1&0&0&0&0&\Delta t \\ 0&0&0&1&0&0&0&0 \\ 0&0&0&0&1&0&0&0 \\ 0&0&0&0&0&1&0&0 \\ 0&0&0&0&0&0&1&0 \\ 0&0&0&0&0&0&0&1 \end{pmatrix} x_{k-1},在本例中,\Delta t \space是一帧,因此这里\space \Delta t = 1 \\ 故状态转移矩阵\space A = \begin{pmatrix} 1&0&0&0&0&1&0&0 \\ 0&1&0&0&0&0&1&0 \\ 0&0&1&0&0&0&0&1 \\ 0&0&0&1&0&0&0&0 \\ 0&0&0&0&1&0&0&0 \\ 0&0&0&0&0&1&0&0 \\ 0&0&0&0&0&0&1&0 \\ 0&0&0&0&0&0&0&1 \end{pmatrix} 对于预测框来说,它形如 (xmin,ymin,xmax,ymax),代表了框的左上角坐标和右下角坐标在追踪任务中,我们一般将其变成另一种表达形式:(cx,cy,s,r)其中 cx、cy 表示框的中心坐标,s 表示框的面积,r 表示框的宽高比在此基础上,对中心坐标和框的面积增加变化速度,那么框的状态向量表示为 x=⎝⎜⎜⎜⎜⎜⎜⎜⎜⎛cxcysrcxvcyvsv⎠⎟⎟⎟⎟⎟⎟⎟⎟⎞此时我们可以计算出状态向量到测量向量的转移矩阵 H显然有 z=⎝⎜⎜⎛cxcysr⎠⎟⎟⎞=⎝⎜⎜⎛1000010000100001000000000000⎠⎟⎟⎞⎝⎜⎜⎜⎜⎜⎜⎜⎜⎛cxcysrcxvcyvsv⎠⎟⎟⎟⎟⎟⎟⎟⎟⎞,因此 H=⎝⎜⎜⎛1000010000100001000000000000⎠⎟⎟⎞假设上一个状态向量 xk−1=⎝⎜⎜⎜⎜⎜⎜⎜⎜⎛cxk−1cyk−1sk−1rk−1cxvk−1cyvk−1svk−1⎠⎟⎟⎟⎟⎟⎟⎟⎟⎞,假如速度不变,显然有⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧cxk=cxk−1+cxvk−1Δtcyk=cyk−1+cyvk−1Δtsk=sk−1+svk−1Δtrk=rk−1cxvk=cxvk−1cyvk=cyvk−1svk=svk−1即 xk=⎝⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎛1000000001000000001000000001000000001000Δt00001000Δt00001000Δt00001⎠⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎞xk−1,在本例中,Δt 是一帧,因此这里 Δt=1故状态转移矩阵 A=⎝⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎛1000000001000000001000000001000000001000100001000100001000100001⎠⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎞
关于噪声协方差矩阵 R , P , Q R,P,Q R,P,Q 的设置,对于追踪任务来说,往往使用经验数值,详见下方的代码
import numpy as np
from filterpy.kalman import KalmanFilter
import cv2
def load_pred_boxes(path):
"""
加载 RetinaFace 模型预测的每一帧图像中人脸方框的坐标,`#`表示该帧没有检测到人脸
:param path: 文件路径,该文件通过 RetinaFace 模型预测生成
:return: 预测框列表
"""
with open(path, 'r') as f:
pred_boxes = f.readlines()
pred_boxes = [i.strip() for i in pred_boxes]
pred_boxes = [
None if box == '#'
else [float(i) for i in box.split(',')]
for box in pred_boxes
]
return pred_boxes
def save_video(video_path, save_path, draw_pred=False, pred_boxes=None,
draw_opt=False, opt_boxes=None):
"""
保存视频,可以在视频上绘制预测框和估计框
:param video_path: 视频路径
:param save_path: 视频保存位置,以 .avi 结尾
:param draw_pred: 是否绘制预测框
:param pred_boxes: 每一帧的预测框
:param draw_opt: 是否绘制卡尔曼滤波器的估计框
:param opt_boxes: 每一帧的估计框
"""
cap = cv2.VideoCapture(video_path) # 从指定路径加载视频
fourcc = cv2.VideoWriter_fourcc(*'XVID') # 保存格式为 .avi
out = cv2.VideoWriter(save_path, fourcc, 25, (852, 480)) # 保存视频文件
frame = 0
while True:
success, img = cap.read()
if not success:
break
# 决定是否绘制预测框
if draw_pred:
if pred_boxes[frame] is not None:
box = [round(i) for i in pred_boxes[frame]]
cv2.rectangle(img, box[:2], box[2:], color=(218, 69, 0), thickness=2)
# 决定是否绘制估计框
if draw_opt:
if opt_boxes[frame] is not None:
box = [round(i) for i in opt_boxes[frame]]
cv2.rectangle(img, box[:2], box[2:], color=(81, 154, 218), thickness=2)
out.write(img) # 保存视频文件
frame += 1
cv2.imshow('1', img)
cv2.waitKey(1)
cap.release()
out.release()
cv2.destroyAllWindows()
def convert_bbox_to_z(bbox):
"""
将预测框从格式为 [x_min, y_min, x_max, y_max] 变换为 [cx, cy, s, r] 形式,
其中 cx, cy 是预测框的中心坐标,s 是预测框的面积,r 是预测框的宽高比
:param bbox: 代表 [x_min, y_min, x_max, y_max] 的列表
:return: 改变格式后的列表
"""
w = bbox[2] - bbox[0]
h = bbox[3] - bbox[1]
x = bbox[0] + w / 2.
y = bbox[1] + h / 2.
s = w * h # 面积
r = w / float(h)
return np.array([x, y, s, r]).reshape((4, 1))
def convert_x_to_bbox(x):
"""
将方框从 [cx, cy, s, r] 的格式转变为 [x_min, y_min, x_max, y_max] 的形式,
该函数与 convert_bbox_to_z 相反
:param x: 代表 [cx, cy, s, r, ...] 的列表,只会用到前面4个值
:return: 改变格式后的列表
"""
w = np.sqrt(x[2] * x[3])
h = x[2] / w
return np.array(
[x[0] - w / 2., x[1] - h / 2., x[0] + w / 2., x[1] + h / 2.]
).reshape((1, 4))
class KalmanBoxTracker(object):
"""
使用卡尔曼滤波对预测框进行优化
"""
def __init__(self, bbox):
self.kf = KalmanFilter(dim_x=7, dim_z=4)
# 设置状态转移矩阵
self.kf.F = np.array(
[[1, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 1, 0],
[0, 0, 1, 0, 0, 0, 1],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 0, 1]]
)
# 设置状态向量到测量值的转换矩阵
self.kf.H = np.array(
[[1, 0, 0, 0, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0]]
)
# 设置测量噪声的协方差矩阵 R
self.kf.R[2:, 2:] *= 10.
# 设置先验误差的协方差矩阵 P
self.kf.P[4:, 4:] *= 1000. # 对不可观测的初始速度给予高度不确定性
self.kf.P *= 10.
# 设置过程噪声的协方差矩阵 Q
self.kf.Q[-1, -1] *= 0.01
self.kf.Q[4:, 4:] *= 0.01
# 设置初始状态,即使用初始预测框作为初始状态
self.kf.x[:4] = convert_bbox_to_z(bbox)
def update(self, bbox):
# 跟预测框(测量值)进行更新
self.kf.update(convert_bbox_to_z(bbox))
def predict(self):
# 面积是大于0的,如果小于0,就将面积的改变速度置为0
if self.kf.x[6] + self.kf.x[2] <= 0:
self.kf.x[6] = 0
# 预测阶段
self.kf.predict()
return convert_x_to_bbox(self.kf.x)
def get_state(self):
# 获取当前的估计框
return convert_x_to_bbox(self.kf.x)
def kalman_opt(boxes):
opt_boxes = [] # 保存每一帧的估计框
kbt = KalmanBoxTracker(boxes[0])
for i in range(len(boxes)):
# 如果该帧没有检测到,则估计框也为None
if boxes[i] is None:
opt_boxes.append(None)
continue
kbt.predict()
kbt.update(boxes[i])
# 保存当前帧的估计值
opt_boxes.append(list(kbt.get_state()[0]))
return opt_boxes
if __name__ == '__main__':
pred_boxes = load_pred_boxes('../assets/boxes.txt')
opt_boxes = kalman_opt(pred_boxes)
# 仅在视频上绘制预测框
# save_video('../assets/1.mp4', '../assets/pred.avi',
# draw_pred=True, pred_boxes=pred_boxes,
# draw_opt=False, opt_boxes=None)
# 仅在视频上绘制估计框
# save_video('../assets/1.mp4', '../assets/opt.avi',
# draw_pred=False, pred_boxes=None,
# draw_opt=True, opt_boxes=opt_boxes)
# 在视频上同时绘制预测框(蓝色)和估计框(橙色)
save_video('../assets/1.mp4', '../assets/cmp.avi',
draw_pred=True, pred_boxes=pred_boxes,
draw_opt=True, opt_boxes=opt_boxes)
下面看一下使用卡尔曼滤波后的结果,看起来似乎平滑了许多
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1EW03HCw-1670688580091)(./assets/opt.gif)]](https://img-blog.csdnimg.cn/573e24a99551498aac93c32f9375aa66.gif)
我们将预测框和估计框都显示出来,可以看出估计框更加平滑,这说明卡尔曼滤波起到了一定的作用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BTybryZu-1670688580092)(./assets/cmp.gif)]](https://img-blog.csdnimg.cn/9a8e66d9c2b9439790a630b50dd798d0.gif)
附视频和 RetinaFace 的预测框结果:https://alokia.lanzouo.com/izLZl0idavfi



![[附源码]JAVA毕业设计雅博书城在线系统(系统+LW)](https://img-blog.csdnimg.cn/a49585fcaac94571852daf6db7862064.png)