文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 掌握Zookeeper的Canal消费组件;
⚪ 掌握Zookeeper的Dubbo分布式服务框架;
⚪ 掌握Zookeeper的Metamorphosis消息中间件;
⚪ 掌握Zookeeper的Otter分布式数据库同步系统;
一、Canal - 阿里
1. 概述
1. Canal是阿里巴巴于2013年1月正式开源的一个由纯Java语言编写的基于MySQL数据库Binlog实现的增量订阅和消费组件。
2. 目前项目主页地址为:https://github.Com/alibaba/canal 。由项目主要负责人,同时也是资深的开源爱好者agapple持续维护。
3. 项目名Canal取自“管道”的英文单词,寓意数据的流转,是一个定位为基于MySQL数据库的Binlog增量日志来实现数据库镜像、实时备份和增量数据消 费的通用组件。
4. 早期的数据库同步业务,大多都是使用MySQL数据库的触发器机制(即Trigger)来获取数据库的增量变更。不过从2010年开始,阿里系下属各公司开始 逐步尝试基于数据库的日志解析来获取增量变更,并在此基础上实现数据的同步,由此衍生出了数据库的增量订阅和消费业务——Canal项目也由此诞生。
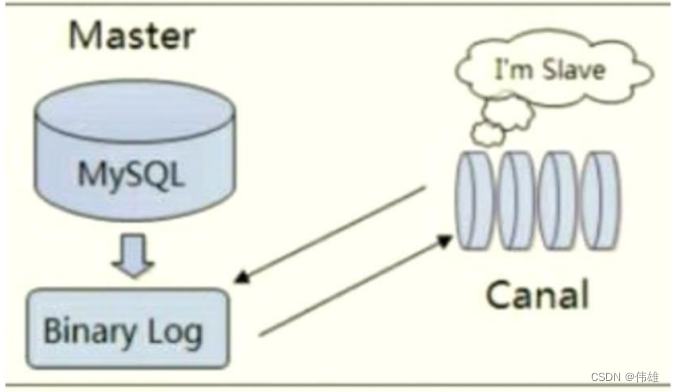
5. Canal的工作原理相对比较简单,其核心思想就是模拟MySQL Slave的交互协议,将自己伪装成一个MySQL的Slave机器,然后不断地向Master服务器发 送Dump请求。Master收到Dump请求后,就会开始推送相应的Binary Log给该Slave(也就是Canal)。Canal收到Binary Log,解析出相应的Binary Log对象后就可以进行二次消费了,其基本工作原理如下图所示。
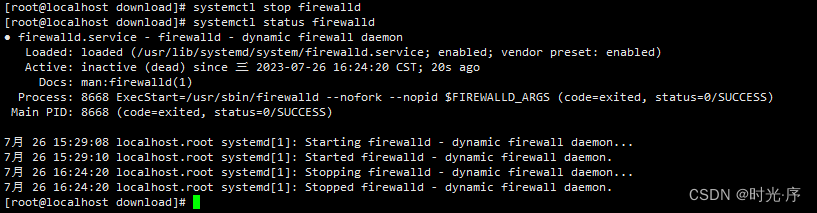
2. Canal Server主备切换设计
1. 在Canal的设计中,基于对容灾的考虑,往往会配置两个或更多个Canal Server来负责一个MySQL数据库实例的数据增量复制。
2. 另一方面,为了减少Canal Server的Dump请求对MySQLMaster所带来的性能影响,就要求不同的Canal Server上的instance在同一时刻只能有一个处于 Running状态,其他的instance都处于Standby状态,这就使得Canal必须具备主备自动切换的能力。
3. 在Canal中,整个主备切换过程控制主要是依赖于ZooKeeper来完成的,如下图所示:
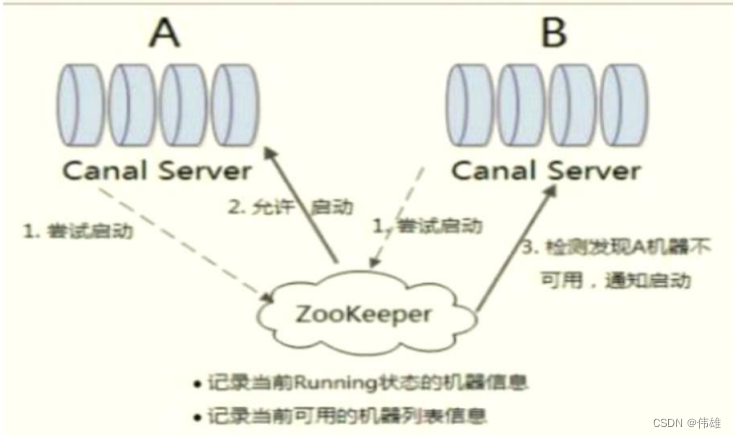
a. 尝试启动:每个Canal Server在启动某个Canal instance的时候都会首先向ZooKeeper进行一次尝试启动判断。具体的做法是向ZooKeeper创建一 个相同的临时节点,哪个Canal Server创建成功了,那么就让哪个Server启动。以 “example”这个instance为例来说明,所有的Canal Server在 启动的时候,都会去创建 /otter/canal/destinations/example/running 节点,并且无论有多少个Canal Server同时并发启动,ZooKeeper都会保 证最终只有一个Canal Server能够成功创建该节点。
b. 启动instance:假设最终IP地址为10.20.144.51的Canal Server成功创建了该节点,那么它就会将自己的机器信息写入到该节点中去: {"active":true,"address":"10.20.144.51:11111","cid":1}并同时启动instance。而其他Canal Server由于没有成功创建节点,于是就会将自己的状态 置为Standby,同时 /otter/canal/destinations/example/running节点注册Watcher监听,以监听该节点的变化情况。
c. 主备切换:Canal Server在运行过程中,难免会发生一些异常情况导致其无法正常工作,这个时候就需要进行主备切换了。基于ZooKeeper临时节 点的特性,当原本处于Running状态的Canal Server因为挂掉或网络等原因断开了与ZooKeeper的连接,那么 /otter/canal/destinations/example/running节点就会在一段时间后消失 。由于之前处于Standby状态的所有Canal Server已经对该节点进行了 监听,因此它们在接收到ZooKeeper发送过来的节点消失通知后,会重复进行步骤1——以此实现主备切换。
4. 在主备切换设计过程中最容易碰到的一个问题,就是“假死”。所谓假死状态是指,Canal Server所在服务器的网络出现闪断,导致ZooKeeper认为其会 话失效,从而释放了Running节点——但此时Canal Server对应的JVM并未退出,其工作状态是正常的。
5. 在Canal的设计中,为了保护假死状态的Canal Server,避免因瞬间Running节点失效导致instance重新分布带来的资源消耗,所以设计了一个策略:
a. 状态为Standby的Canal Server在收到Running节点释放的通知后,会延迟一段时间抢占Running节点,而原本处于Running状态的instance,即 Running节点的拥有者可以不需要等待延迟,直接取得Running节点。
b. 这样就可以尽可能地保证假死状态下一些无谓的资源释放和重新分配。
c. 目前延迟时间的默认 值为5秒,即Running节点针对假死状态的保护期为5秒。
3. Canal Client的HA设计
1. Canal Client在进行数据消费前,首先当然需要找到当前正在提供服务的Canal Server,即Master。
2. 在上面“主备切换”部分中,针对每一个数据复制实例,例如example,都会 /otter/canal/destinations/example/running节点中记录下当前正在运行 的Canal Server。因此,Canal Client只需要连接ZooKeeper,并从对应的节点上读取Canal Server信息即可。
3. 从ZooKeeper中读取出当前处于Running状态的Server。Canal Client在启动的时候,会首先从/otter/canal/destinations/example/running节点上读取出当前处于Running状态的Server。同时,客户端也会将自己的信息注册到ZooKeeper的 /otter/canal/destinations/example/1001/running节点上, 其中“1001”代表了该客户端的唯一标识,其节点内容如下: {"active":true,"address":"10.12.48.171:50544","clientId":1001}
4. 注册Running节点数据变化的监听。由于Canal Server存在挂掉的风险,因此Canal Client还会对/otter/canal/destinations/example/running节点注册 一个节点变化的监听,这样一旦发生Server的主备切换,Client就可以随时感知到。
5. 连接对应的Running Server进行数据消费。
4. 数据消费位点记录
1. 由于存在Canal Client的重启或其他变化,为了避免数据消费的重复性和顺序错乱,Canal必须对数据消费的位点进行实时记录。
2. 数据消费成功后,Canal Server会在ZooKeeper中记录下当前最后一次消费成功的Binary Log位点,一旦发生Client重启,只需要从这最后一个位点继续 进行消费即可。
3. 具体的做法是在ZooKeeper的/otter/canal/destinations/example/1001/cursor节点中记录下客户端消费的详细位点信息: {"@type":"com.alibaba.otter.canal.protocol.position.LogPosition","identity":{"slaveId":-1,"sourceAddress":{"address":"10.20.144.15","port":330 6}},"postion":"included":false,"journalName":"mysqlbin.002253","position":2574756,"timestamp":1363688722000}}
二、Dubbo - 阿里
1. 概述
1. Dubbo是阿里巴巴于2011年10月正式开源的一个由Java语言编写的分布式服务框架,致力于提供高性能和透明化的远程服务调用方案和基于服务框架展 开的完整SOA服务治理方案。
2. 目前项目主页地址为:https://github.com/alibaba/dubbo。
2. 核心组成
1. 远程通信:提供对多种基于长连接的NIO框架抽象封装,包括多种线程模型、序列化,以及“请求-响应”模式的信息交换方式。
2. 集群容错:提供基于接口方法的远程过程透明调用,包括对多协议的支持,以及对软负载均衡、失败容错、地址路由和动态配置等集群特性的支持。
3. 自动发现:提供基于注册中心的目录服务,使服务消费方能动态地查找服务提供方,使地址透明,使服务提供方可以平滑地增加或减少机器。
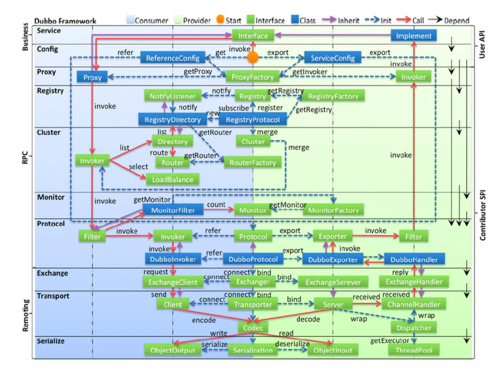
4. Dubbo框架还包括负责服务对象序列化的Serialize组件、网络传输组件Transport、协议层Protocol以及服务注册中心Registry等,其整体模块组成和协作方式如下图所示:
3. 注册中心
1. 注册中心是RPC框架最核心的模块之一,用于服务的注册和订阅。
2. 在Dubbo的实现中,对注册中心模块进行了抽象封装,因此可以基于其提供的外部接口来实现各种不同类型的注册中心,例如数据库、 ZooKeeper和 Redis等。
3. 在Dubbo注册中心的整体架构设计中,ZooKeeper上服务的节点设计如下图所示
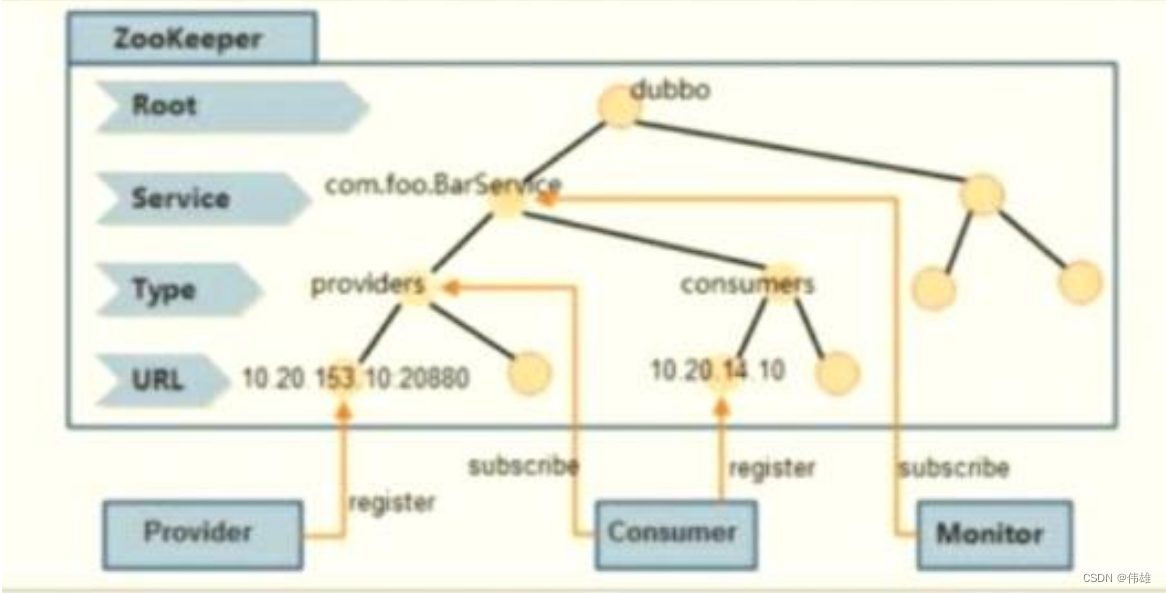
/dubbo:这是Dubbo在ZooKeeper上创建的根节点。
/dubbo/com.foo.BarService:这是服务节点,代表了Dubbo的一个服务。
/dubbo/com.foo.BarService/providers:这是服务提供者的根节点,其子节点代表了每一个服务的真正提供者。
/dubbo/com.foo.BarService/conssumers:这是服务消费者的根节点,其子节点代表了每一个服务的真正消费者。
4. 以“com.foo.BarService”这个服务为例,来说明Dubbo基于ZooKeeper实现的注册中心的工作流程:
a. 服务提供者:服务提供者在初始化启动的时候,会首先在ZooKeeper的/dubbo/com.foo.BarService/providers节点下创建一个子节点,并写入自 己的URL地址,这就代表了“com.foo.BarService”这个服务的一个提供者。
b. 服务消费者:服务消费者会在启动的时候,读取并订阅ZooKeeper上/dubbo/com.foo.BarService/providers节点下的所有子节点,并解析出所有 提供者的URL地址来作为该服务地址列表,然后开始发起正常调用。同时,服务消费者还会在ZooKeeper的 /dubbo/com.foo.BarService/consumers节点下创建一个临时节点,并写入自己的URL地址,这就代表了“com.foo.BarService”这个服务的一个 消费者。
c. 监控中心:监控中心是Dubbo中服务治理体系的重要一部分,其需要知道一个服务的所有提供者和订阅者,及其变化情况。因此,监控中心在启动 的时候,会通过ZooKeeper的/dubbo/com.foo.BarService节点来获取所有提供者和消费者的URL地址,并注册Watcher来监听其子节点变化。
d. 另外需要注意的是,所有提供者在ZooKeeper上创建的节点都是临时节点,利用的是临时节点的生命周期和客户端会话相关的特性,因此一旦提供 者所在的机器出现故障导致该提供者无法对外提供服务时,该临时节点就会自动从ZooKeeper上删除,这样服务的消费者和监控中心都能感知到服 务提供者的变化。
5. 在ZooKeeper节点结构设计上,以服务名和类型作为节点路径,符合Dubbo订阅和通知的需求,这样保证了以服务为粒度的变更通知,通知范围易于控 制,即使在服务的提供者和消费者变更频繁的情况下,也不会对ZooKeeper造成太大的性能影响。
三、Metamorphosis - 阿里
1. 概述
1. Metamorphosis是阿里巴巴中间件团队的killme2008和wq163于2012年3月开源的一个Java消息中间件
2. 目前项目主页地址为:https://github.com/killme2008/Metamorphosis,由开源爱好者及项目的创始人killme2008和wq163持续维护
3. Metamorphosis是一个高性能、高可用、可扩展的分布式消息中间件,其思路起源于LinkedIn的Kafka,但并不是Kafka的一个简单复制
4. Metamorphosis具有消息存储顺序写、吞吐量大和支持本地XA事务等特性,适用于大吞吐量、顺序消息、消息广播和日志数据传输等分布式应用场景, 目前在淘宝和支付宝都有着广泛的应用,其系统整体部署结构如下图所示:
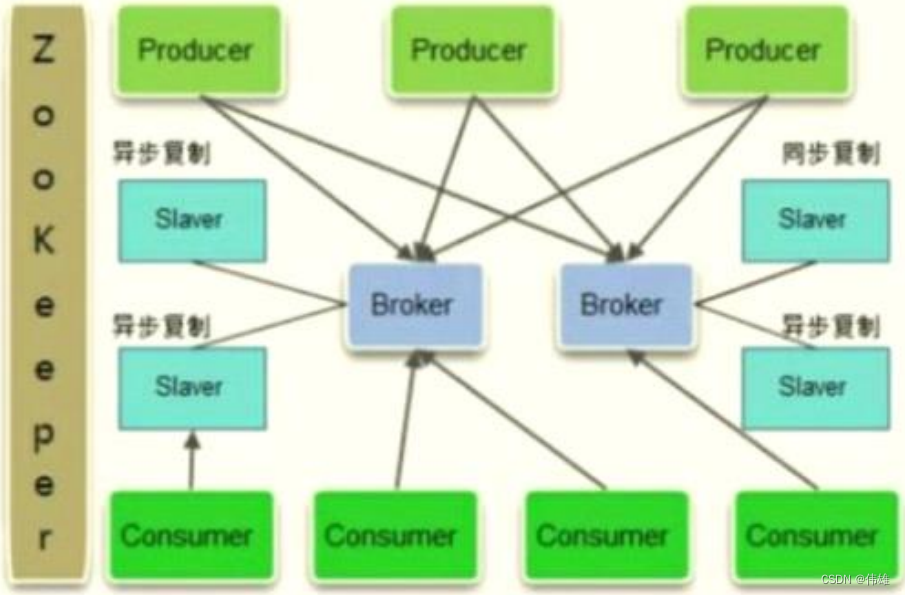
5. 和传统的消息中间件采用推(Push)模型所不同的是,Metamorphosis是基于拉(Pull)模型构建的,由消费者主动从Metamorphosis服务器拉取数据 并解析成消息来进行消费,同时大量依赖ZooKeeper来实现负载均衡和Offset的存储。
2. 生产者的负载均衡
1. 和Kafka系统一样,Metamorphosis假定生产者、 Broker和消费者都是分布式的集群系统。
2. 生产者可以是一个集群,多台机器上的生产者可以向相同的Topic发送消息。
3. 服务器Broker通常也是一个集群,多台Broker组成一个集群对外提供一系列的Topic消息服务。
4. 生产者按照一定的路由规则向集群里某台Broker发送消息,消费者按照一定的路由规则拉取某台Broker上的消息。
5. 每个Broker都可以配置一个Topic的多个分区,但是在生产者看来,会将一个Topic在所有Broker上的所有分区组成一个完整的分区列表来使用。
6. 在创建生产者的时候,客户端会从ZooKeeper上获取已经配置好的Topic对应的Broker和分区列表,生产者在发送消息的时候必须选择一台Broker上的一 个分区来发送消息,默认的策略是一个轮询的路由规则,如下图所示:
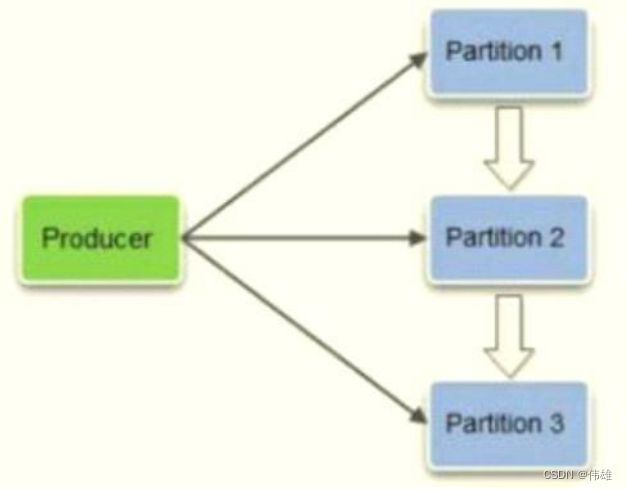
7. 生产者在通过ZooKeeper获取分区列表之后,会按照Broker Id和Partition的顺序排列组织成一个有序的分区列表,发送的时候按照从头到尾循环往复的方式选择一个分区来发送消息。
8. 考虑到Broker服务器软硬件配置基本一致,因此默认的轮询策略已然足够。
9. 在Broker因为重启或者故障等因素无法提供服务时,Producer能够通过ZooKeeper感知到这个变化,同时将失效的分区从列表中移除,从而做到Fail Over。
10. 需要注意的是,因为从故障到生产者感知到这个变化有一定的延迟,因此可能在那一瞬间会有部分的消息发送失败。
3. 消费者的负载均衡
1. 消费者的负载均衡则会相对复杂一些,这里讨论的是单个分组内的消费者集群的负载均衡,不同分组的负载均衡互不干扰。
2. 消费者的负载均衡跟Topic的分区数目和消费者的个数紧密相关,分以下几个场景来讨论:
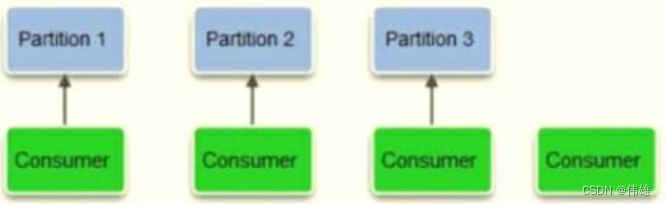
a. 消费者数和Topic分区数一致:如果单个分组内的消费者数目和Topic总的分区数目相同,那么每个消费者负责消费一个分区中的消息,一一对应,如下图所示:

b. 消费者数大于Topic分区数:如果单个分组内的消费者数目比Topic总的分区数目多,则多出来的消费者不参与消费,如下图所示:
c. 消费者数小于Topic分区数:如果分组内的消费者数目比Topic总的分区数目小,则有部分消费者需要额外承担消息的消费任务,具体如下图所示:
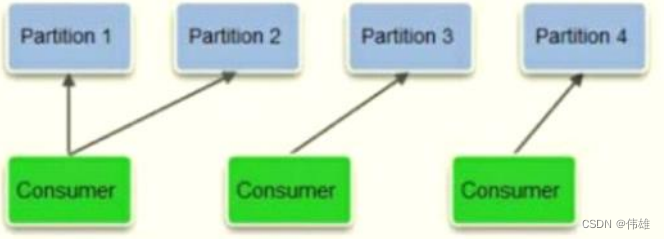
d. 当分区数目(n)大于单个Group的消费者数目(m)的时候,则有n%m个消费者需要额外承担1/n的消费任务,我们假设n无限大,那么这种策略还 是能够达到负载均衡的目的的。
3. 综上所述,单个分组内的消费者集群的负载均衡策略如下:
a. 每个分区针对同一个Group只能挂载一个消费者,即每个分区至多同时允许被一个消费者进行消费。
b. 如果同一个Group的消费者数目大于分区数目,则多出来的消费者将不参与消费。
c. 如果同一个Group的消费者数目小于分区数目,则有部分消费者需要额外承担消费任务。
4. Metamorphosis的客户端会自动处理消费者的负载均衡,将消费者列表和分区列表分别排序,然后按照上述规则做合理的挂载
5. 从上述内容来看,合理地设置分区数目至关重要。如果分区数目太小,则有部分消费者可能闲置;如果分区数目太大,则对服务器的性能有影响。
6. 在某个消费者发生故障或者发生重启等情况时,其他消费者会感知到这一变化(通过ZooKeeper的“节点变化”通知),然后重新进行负载均衡,以保证 所有的分区都有消费者进行消费。
4. 消息消费位点Offset存储
1. 为了保证生产者和消费者在进行消息发送与接收过程中的可靠性和顺序性,同时也是为了尽可能地保证避免出现消息的重复发送和接收,Metamorphosis 会将消息的消费记录Offset记录到 ZooKeeper上去,以尽可能地确保在消费者进行负载均衡的时候,能够正确地识别出指定分区的消息进度。
四、Otter - 阿里
1. 概述
1. Otter是阿里巴巴于2013年8月正式开源的一个由纯Java语言编写的分布式数据库同步系统,主要用于异地双A机房的数据库数据同步,致力于解决长距离 机房的数据同步及双A机房架构下的数据一致性问题。
2. 目前项目主页地址为https://github.com/alibaba/otter,由项目主要负责人,同时也是资深的开源爱好者agapple持续维护。
3. 项目名Otter取自“水獭”的英文单词,寓意数据搬运工,是一个定位为基于数据库增量日志解析,在本机房或异地机房的MySQL/Oracle数据库之间进 行准实时同步的分布式数据库同步系统
4. Otter的第一个版本可以追溯到2004年,初衷是为了解决阿里巴巴中美机房之间的数据同步问题,从4.0版本开始开源,并逐渐演变成一个通用的分布式数 据库同步系统。其基本架构如下图所示。
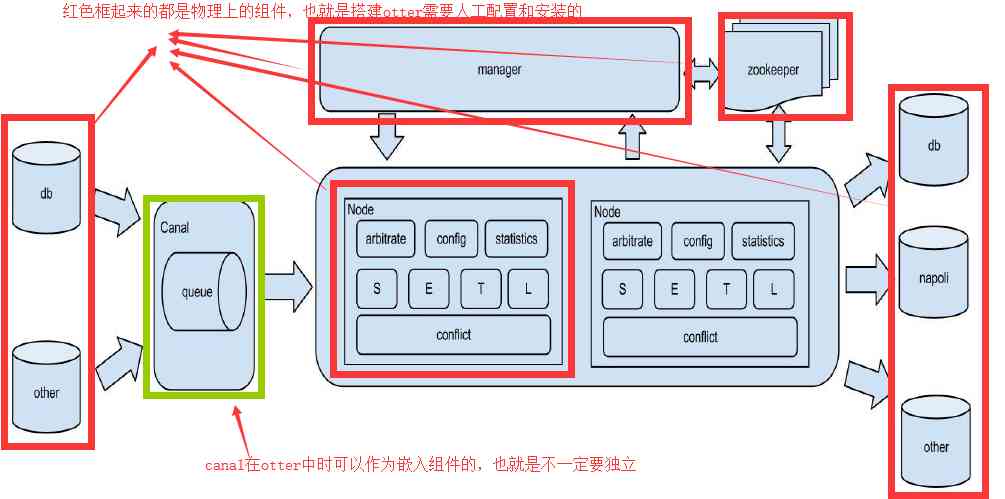
5. 在Otter中也是使用ZooKeeper来实现一些与分布式协调相关的功能。
2. 分布式SEDA模型调度
1. 概述
1. 为了更好地提高整个系统的扩展性和灵活性,在Otter中将整个数据同步流程抽象为类似于ETL的处理模型,具体分为四个阶段(Stage):
a. Select:数据接入
b. Extract:数据提取
c. Transform:数据转换
d. Load:数据载入
2. 其中Select阶段是为了解决数据来源的差异性,比如可以接入来自Canal的增量数据,也可以接入其他系统的数据源。 Extract/Transform/Load阶段则类 似于数据仓库的ETL模型,具体可分为 数据Join、数据转化和数据Load等过程。
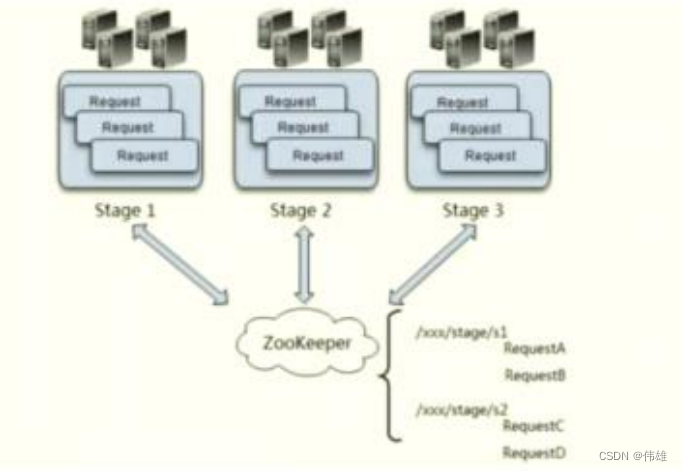
3. 同时,为了保证系统的高可用性,SEDA的每个阶段都会有多个节点进行协同处理。如下图所示是该SEDA模型的示意图:
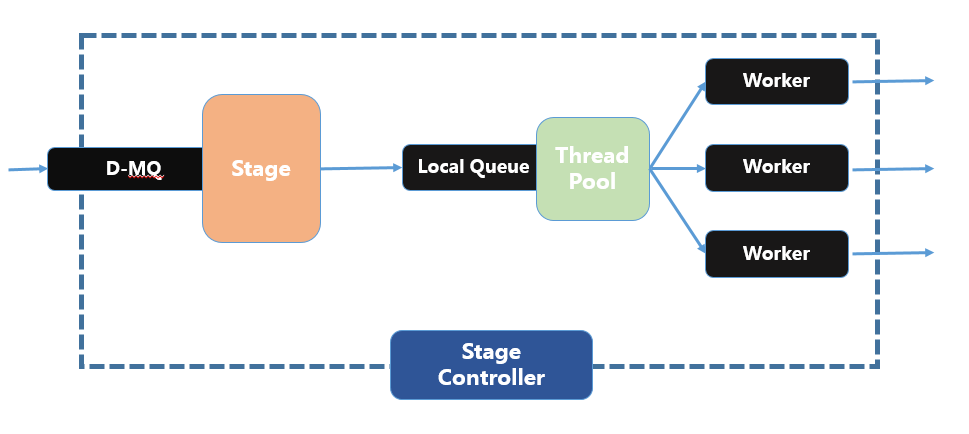
2. Stage管理
1. Stage管理主要就是维护一组工作线程,在接收到Schedule的Event任务信号后,分配一个工作线程来进行任务处理,并在任务处理完成后,反馈信息到 Schedule。
3. Schedule调度
1. Schedule调度主要是指基于ZooKeeper来管理Stage之间的任务消息传递
2. 具体实现逻辑:
a. 创建节点。Otter首先会为每个Stage在ZooKeeper上创建一个节点,例如/seda/stage/s1,其中s1即为该Stage的名称,每个任务事件都会对应于 该节点下的一个子节点,例如/seda/stage/s1/RequestA。
b. 任务分配。当s1的上一级Stage完成RequestA任务后,就会通知“Schedule调度器”其已完成了该请求。根据预先定义的Stage流程,Schedule调 度器便会在Stage s1的目录下创建一个RequestA的子节点,告知s1有一个新的请求需要其处理——以此完成一次任务的分配。
c. 任务通知。每个Stage都会有一个Schedule监听线程,利用ZooKeeper的Watcher机制来关注ZooKeeper中对应Stage节点的子节点变化,比如关 注s1就是关注/seda/stage/s1的子节点的变化情况。此时,如果步骤2中调度器在s1的节点下创建了一个RequestA,那么ZooKeeper就会通过 Watcher机制通知到该Schedule线程,然后Schedule就会通知Stage进行任务处理——以此完成一次任务的通知。
d. 任务完成。 当s1完成了RequestA任务后,会删除s1目录下的RequestA任务,代表处理完成,然后继续步骤2,分配下一个Stage的任务。
3. 在上面的第3步中,还有一个需要注意的细节是,在真正的生产环境部署中,往往都会由多台机器共同组成一个Stage来处理Request,因此就涉及多个机 器节点之间的分布式协调。如果s1有多个节点协同处理,每个节点都会有该Stage的一个Shedule线程,其在s1目录变化时都会收到通知。在这种情况 下,往往可以采取抢占式的模式,尝试在RequestA目录下创建一个lock节点,谁创建成功就可以代表当前谁抢到了任务,而没抢到该任务的节点,便会 关注该lock节点的变化(因为一旦该lock节点消失,那么代表当前抢到任务的节点可能出现了异常退出,没有完成任务),然后继续抢占模型。
4. 中美跨机房ZooKeeper集群的部署
1. 由于Otter主要用于异地双A机房的数据库同步,致力于解决长距离机房的数据同步及双A机房架构下的数据一致性问题,因此其本身就有面向中美机房服 务的需求,也就会有每个机房都要对ZooKeeper进行读写操作的需求。于是,希望可以部署一个面向全球机房服务的ZooKeeper集群,保证读写数据一 致性。这里就需要使用ZooKeeper的Observer功能。
2. 从3.3.0版本开始,ZooKeeper新增了Observer模式,该角色提供只读服务,且不参与事务请求的投票,主要用来提升整个ZooKeeper集群对非事务请求 的处理能力。因此,借助ZooKeeper的Observer特性,Otter将ZooKeeper集群进行了三地部署。杭州机房部署Leader/Follower集群,为了保障系统高 可用,可以部署3个机房。每个机房的部署实例可为1/1/1或者3/2/2的模式。美国机房部署Observer集群,为了保证系统高可用,可以部署2个机房,每 个机房的部署实例可以为1/1。青岛机房部署Observer集群。 下图所示是ZooKeeper集群三地部署示意图。
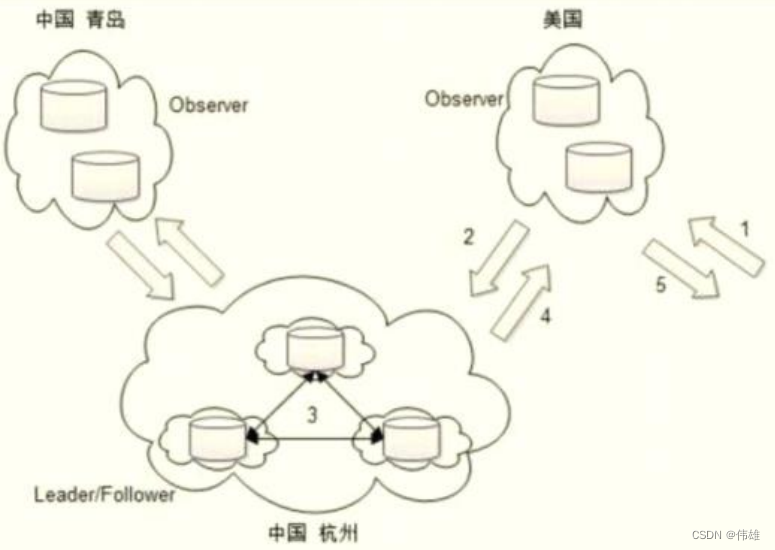
3. 当美国机房的客户端发起一个非事务请求时,就直接从部署在美国机房的Observer ZooKeeper读取数据即可,这将大大减少中美机房之间网络延迟对 ZooKeeper操作的影响。而如果是事务请求,那么美国机房的Observer就会将该事务请求转发到杭州机房的Leader/Follower集群上进行投票处理,然后 再通知美国机房的Observer,最后再由美国机房的Observer负责响应客户端。
4. 上面这个部署结构,不仅大大提升了ZooKeeper集群对美国机房客户端的非事务请求处理能力,同时,由于对事务请求的投票处理都是在杭州机房内部完 成,因此也大大提升了集群对事务请求的处理能力。