Windows下安装Hadoop(手把手包成功安装)
- Windows下安装Hadoop(手把手包成功安装)
- 一、环境准备
- 1.1、查看是否安装了java环境
- 二、下载Hadoop的相关文件
- 三、解压Hadoop安装包
- 四、替换bin文件夹
- 五、配置Hadoop环境变量
- 六、检查环境变量是否配置成功
- 七、配置Hadoop的配置文件
- 7.1、配置 core-site.xml 文件
- 7.2、配置 mapred-site.xml 文件
- 7.3、配置 yarn-site.xml 文件
- 7.4、新建namenode文件夹和datanode文件夹
- 7.4.1、在D:\hadoop-3.1.0创建data文件夹(这个也可以是别的名字,但后面配置要对应修改)
- 7.4.2、在data文件夹中(D:\hadoop-3.1.0\data)创建datanode和namenode文件夹
- 7.5、配置 hdfs-site.xml 文件
- 7.6、配置 hadoop-env.sh 文件
- 7.7、配置 hadoop-env.cmd 文件
- 八、启动Hadoop服务
- 8.1、namenode格式化:hdfs namenode -format
- 8.2、开启hdfs:start-dfs.cmd
- 8.3、开启yarn:start-yarn.cmd
- 8.4、或者直接开启所有服务:start-all.cmd
- 8.5、查看Hadoop运行的进程:jps
- 8.6、hadoop启动报错“ org/apache/hadoop/yarn/server/timelineservice/collector/TimelineCollectorManager”处理办法
- 8.7、namenode重新格式化注意事项
- 8.8、访问namenode和HDFS的页面以及resourcemanager的页面来观察集群是否正常
- 8.9、关闭Hadoop集群:stop-all.cmd
Windows下安装Hadoop(手把手包成功安装)
一、环境准备
1.1、查看是否安装了java环境
java -version,这里要安装java1.8版本,注意java安装的目录不要有空格
安装包链接:https://pan.baidu.com/s/1UU9rDSxro7ifUv1USsV-6g?pwd=yyds

二、下载Hadoop的相关文件
- Hadoop3.1.0版本的安装包:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.0/hadoop-3.1.0.tar.gz
- Windows环境安装所需的bin文件包(我们这里选择3.1.0):
- 1、可以打开地址:https://gitee.com/nkuhyx/winutils ,里面选 3.1.0。
- 2、或者直接下载:https://gitee.com/tttzzzqqq/apache-hadoop-3.1.0-winutils
三、解压Hadoop安装包
四、替换bin文件夹
替换到Hadoop安装目录下
可以发现apache-hadoop-3.1.0-winutils-master这个文件夹解压后里面只有bin这一个文件夹,我们将这个bin文件夹复制到hadoop-3.1.0文件夹中替换原有的bin文件夹
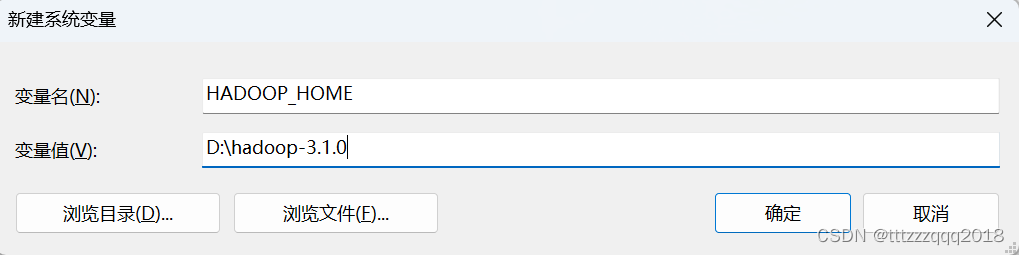
五、配置Hadoop环境变量
HADOOP_HOME
D:\hadoop-3.1.0
path里面加上 %HADOOP_HOME%\bin
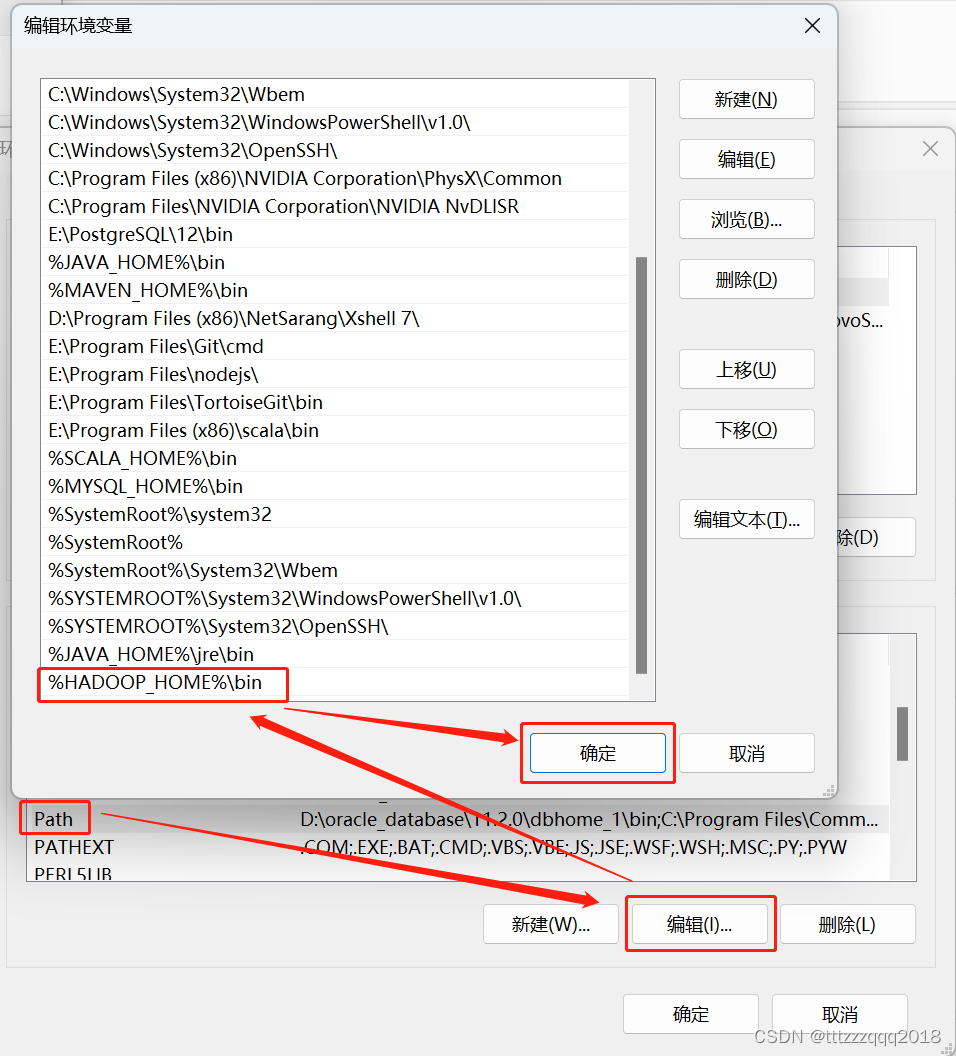
六、检查环境变量是否配置成功
hadoop version

七、配置Hadoop的配置文件
7.1、配置 core-site.xml 文件
先在 D:/hadoop-3.1.0/data/ 目录下建 tmp 文件夹
配置 core-site.xml 文件,文件路径:\hadoop-3.1.0\etc\hadoop\core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/hadoop-3.1.0/data/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
7.2、配置 mapred-site.xml 文件
文件路径:\hadoop-3.1.0\etc\hadoop\mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9001</value>
</property>
</configuration>
7.3、配置 yarn-site.xml 文件
文件路径:\hadoop-3.1.0\etc\hadoop\yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hahoop.mapred.ShuffleHandler</value>
</property>
</configuration>
7.4、新建namenode文件夹和datanode文件夹
7.4.1、在D:\hadoop-3.1.0创建data文件夹(这个也可以是别的名字,但后面配置要对应修改)
7.4.2、在data文件夹中(D:\hadoop-3.1.0\data)创建datanode和namenode文件夹

7.5、配置 hdfs-site.xml 文件
文件路径:\hadoop-3.1.0\etc\hadoop\hdfs-site.xml
<configuration>
<!-- 这个参数设置为1,因为是单机版hadoop -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/hadoop-3.1.0/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/hadoop-3.1.0/data/datanode</value>
</property>
</configuration>
7.6、配置 hadoop-env.sh 文件
文件路径:\hadoop-3.1.0\etc\hadoop\hadoop-env.sh
使用查找功能(ctrl+f)查找export JAVA_HOME,找到相应的位置:
在#export JAVA_HOME=下面一行配置自己电脑上对应的JAVA_HOME/bin路径,注意是以bin结尾的!!
JAVA_HOME的具体路径在环境变量中查找到

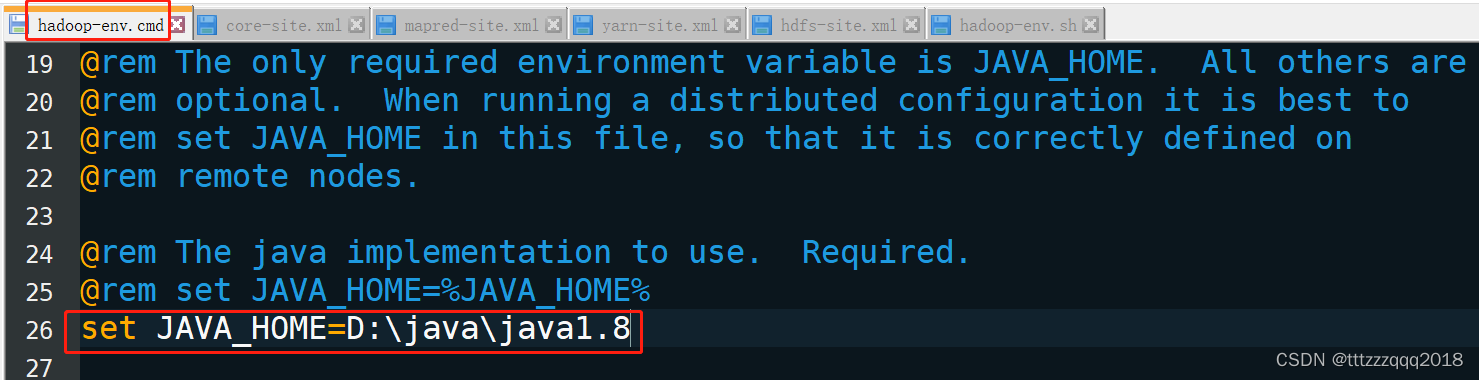
7.7、配置 hadoop-env.cmd 文件
文件路径:\hadoop-3.1.0\etc\hadoop\hadoop-env.cmd
打开后使用查找功能(ctrl+f),输入@rem The java implementation to use查找到对应行
在set JAVA_HOME那一行将自己的JAVA_HOME路径配置上去
八、启动Hadoop服务
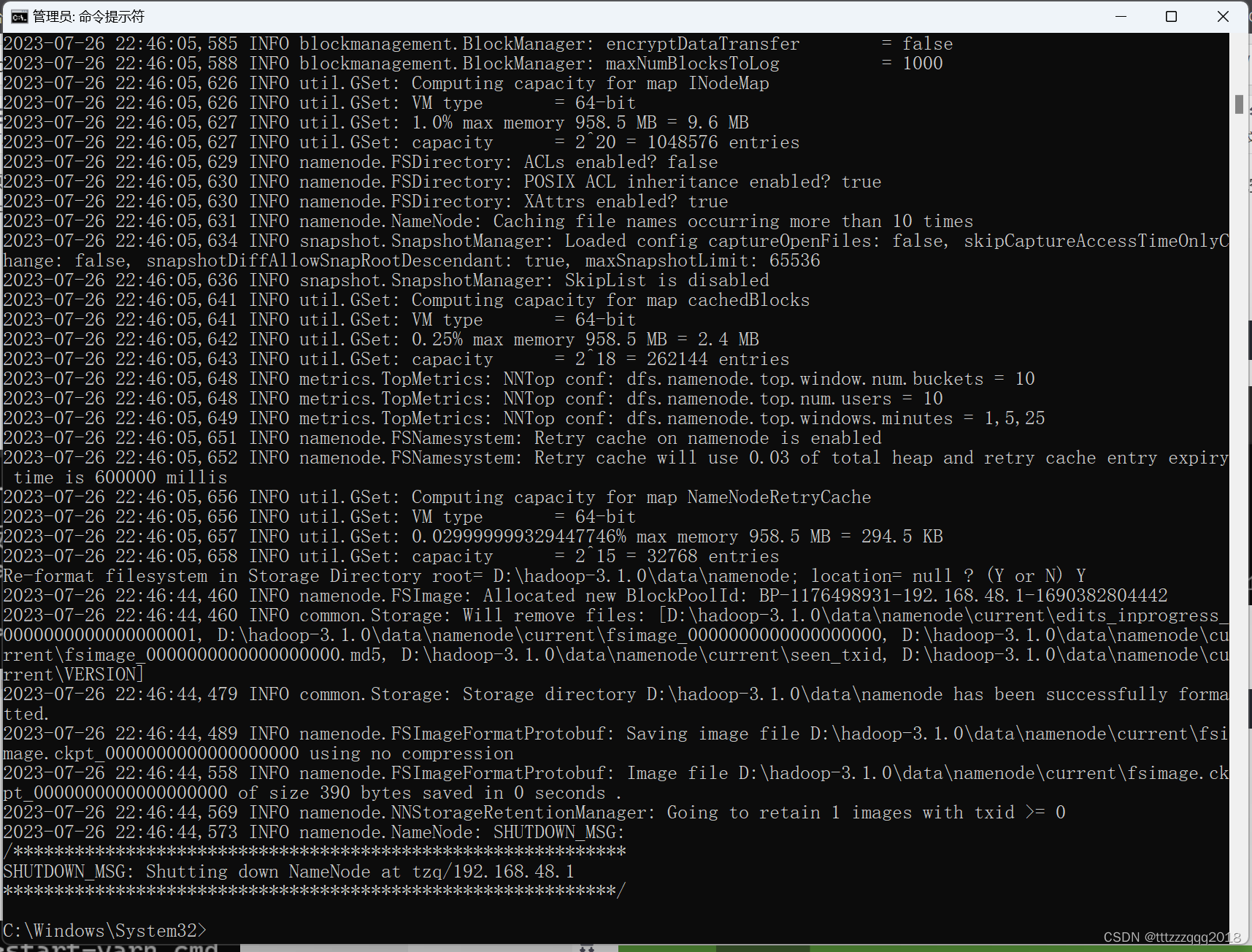
8.1、namenode格式化:hdfs namenode -format
以管理员模式打开命令窗口
在cmd中进入到D:\hadoop-3.1.0\bin路径
或者直接在对应的文件夹里面输入cmd进入
输入命令:
hdfs namenode -format
如果没报错的话,证明配置文件没出问题!
出现类似下图说明成功。如果出错,可能原因有如:环境变量配置错误如路径出现空格,或者winutils版本不对或hadoop版本过高等,或hadoop的etc下文件配置有误
8.2、开启hdfs:start-dfs.cmd
然后再进入到D:\hadoop-3.1.0\sbin路径
输入命令:
start-dfs.cmd
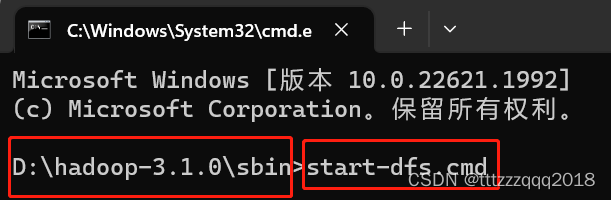
会跳出两个窗口,不要关闭!
8.3、开启yarn:start-yarn.cmd
再输入命令:
start-yarn.cmd
会跳出两个窗口,也不要关闭!

8.4、或者直接开启所有服务:start-all.cmd
也可以直接执行下面命令:(以管理员模式打开命令窗口)
start-all.cmd
然后回车,此时会弹出4个cmd窗口,分别是NameNode、ResourceManager、NodeManager、DataNode。检查4个窗口有没有报错。
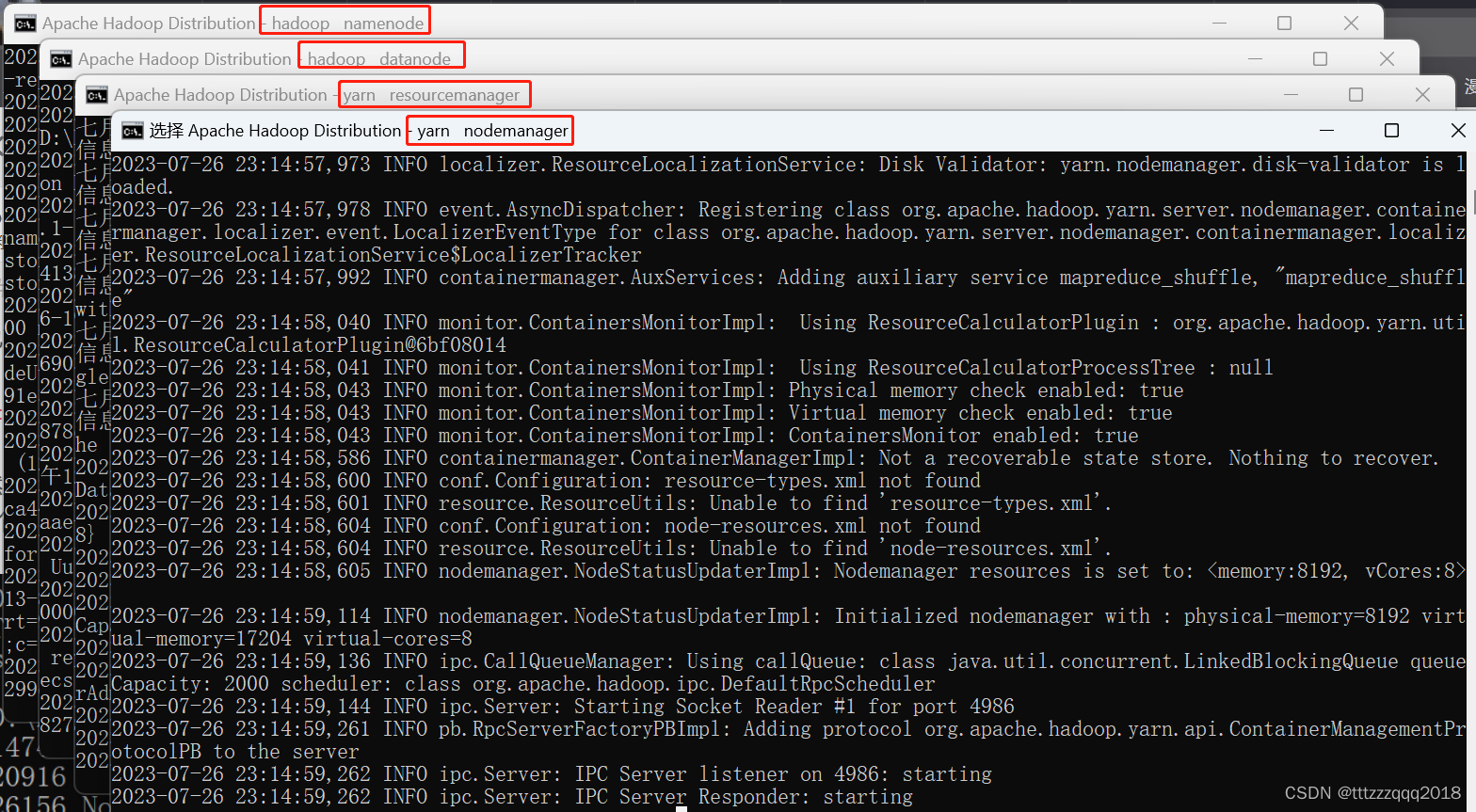
8.5、查看Hadoop运行的进程:jps
在CMD执行jps看到这4个进程,启动成功

8.6、hadoop启动报错“ org/apache/hadoop/yarn/server/timelineservice/collector/TimelineCollectorManager”处理办法
如果:hadoop启动报错“ org/apache/hadoop/yarn/server/timelineservice/collector/TimelineCollectorManager”,
主要是缺少timelineCollectorManager的jar包。
解决方案:
将hadoop3.1.0 版本将share\hadoop\yarn\timelineservice\hadoop-yarn-server-timelineservice-3.1.0.jar放到share\hadoop\yarn\lib 下就可以。
8.7、namenode重新格式化注意事项
需要将 D:\hadoop-3.1.0\data 的
namenode、datanode、tmp这三个目录下的所有文件删除干净
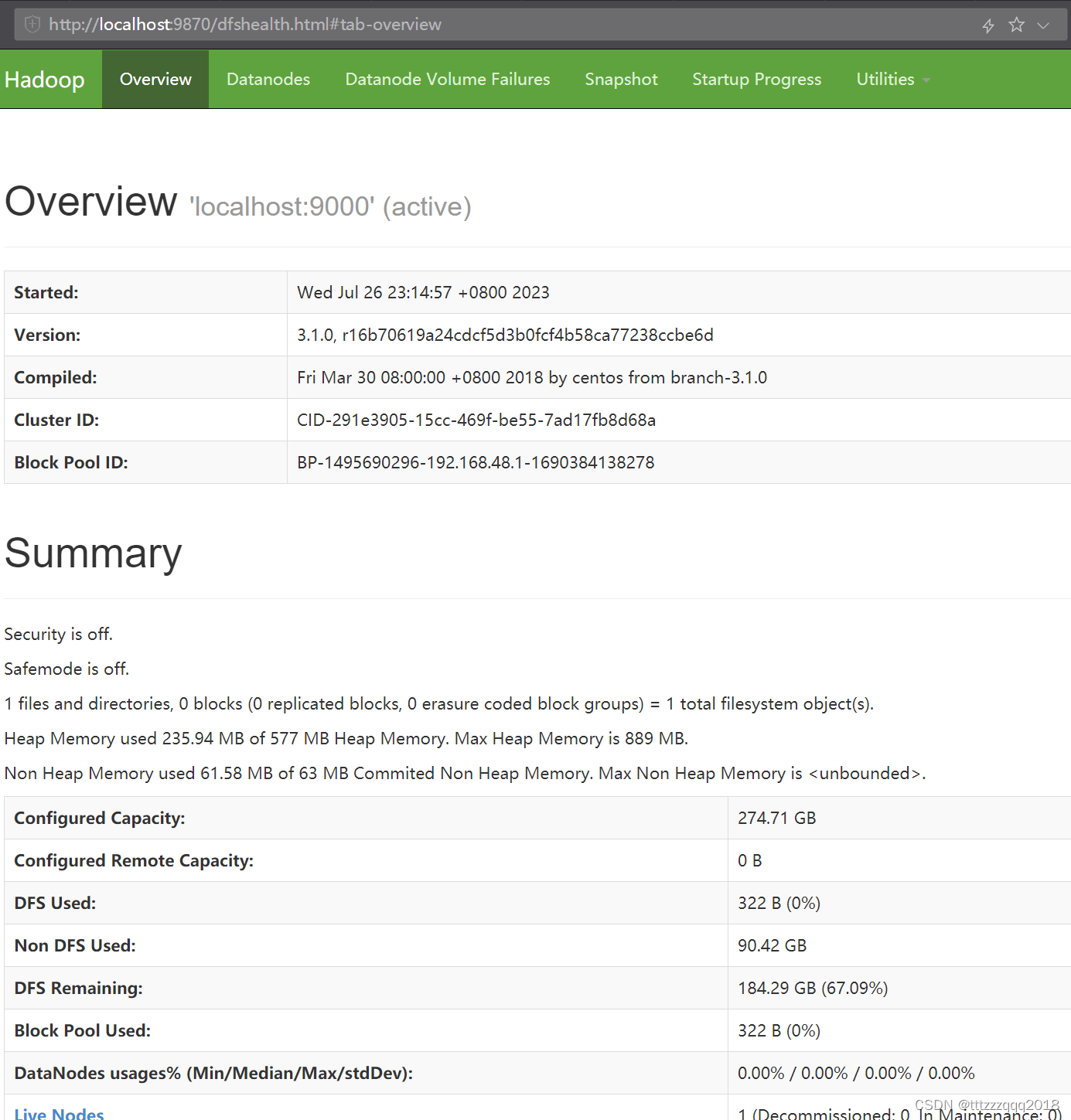
8.8、访问namenode和HDFS的页面以及resourcemanager的页面来观察集群是否正常
可以通过访问namenode和HDFS的Web UI界面(http://localhost:9870)
以及resourcemanager的页面(http://localhost:8088)
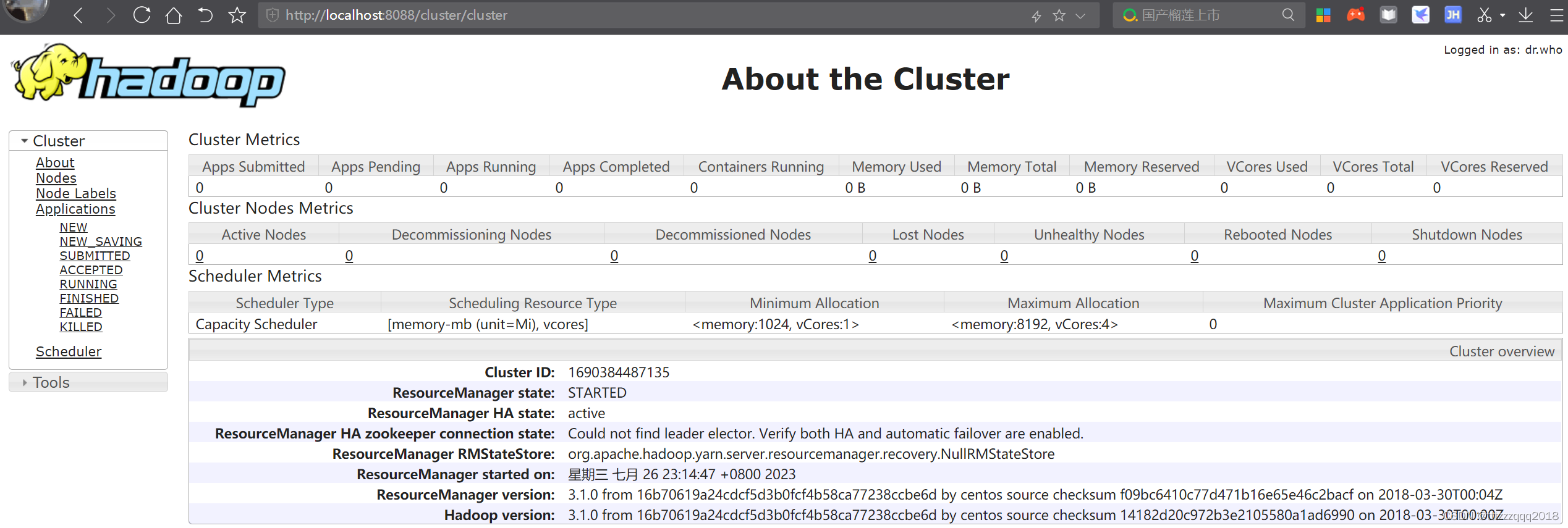
如果成功出现上面两个界面则代表Hadoop安装和配置完成。
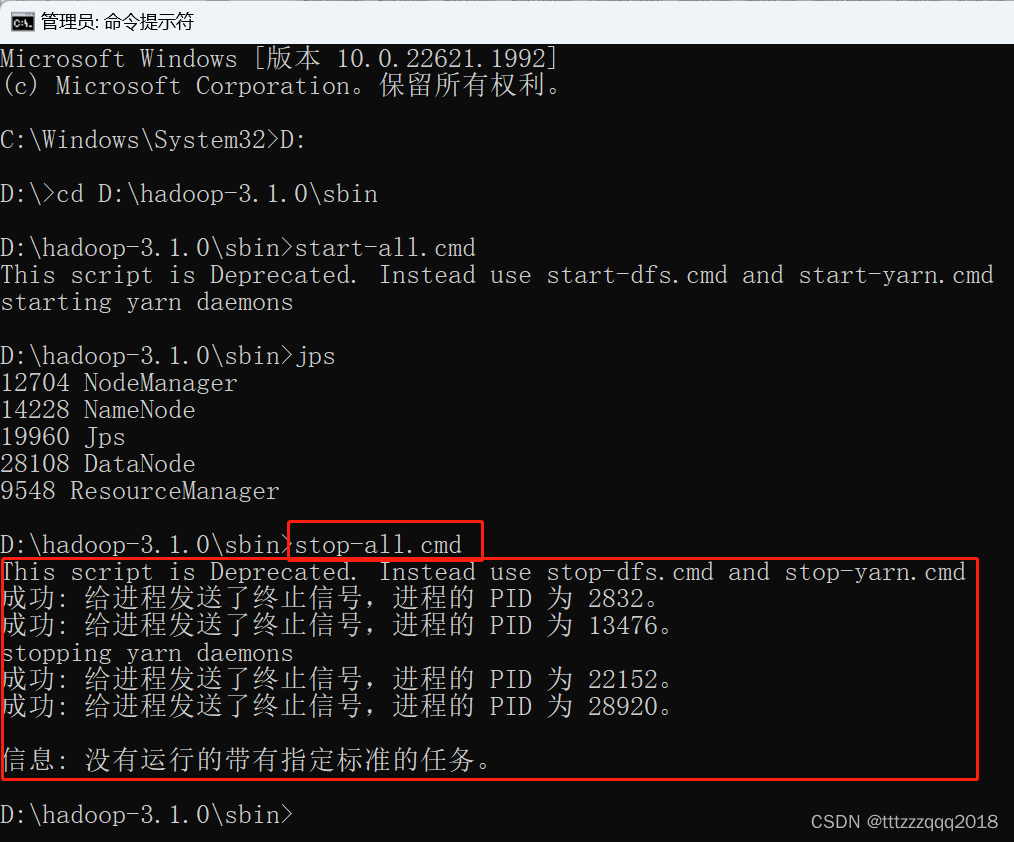
8.9、关闭Hadoop集群:stop-all.cmd
以管理员模式打开命令窗口
进入到hadoop的目录:D:\hadoop-3.1.0\sbin
执行命令:stop-all.cmd
D:\hadoop-3.1.0\sbin>stop-all.cmd