解密C++ STL:深入理解并使用queue容器
- 引言
- 一、queue容器概述
- 二、queue容器的底层实现原理
- 三、queue容器常用API
- 四、queue的使用案例
- 4.1、使用queue容器实现一个高效的算法
- 4.2、实现生产者-消费者模型
- 总结
引言
💡 作者简介:一个热爱分享高性能服务器后台开发知识的博主,目标是通过理论与代码实践的结合,让世界上看似难以掌握的技术变得易于理解与掌握。技能涵盖了多个领域,包括C/C++、Linux、Nginx、MySQL、Redis、fastdfs、kafka、Docker、TCP/IP、协程、DPDK等。
👉
🎖️ CSDN实力新星、CSDN博客专家
👉
🔔 专栏介绍:从零到c++精通的学习之路。内容包括C++基础编程、中级编程、高级编程;掌握各个知识点。
👉
🔔 专栏地址:C++从零开始到精通
👉
🔔 博客主页:https://blog.csdn.net/Long_xu
🔔 上一篇:【041】从零开始:逐步学习使用C++ STL中的stack容器
一、queue容器概述
queue是一种常见的容器数据结构,它可以用来存储一组元素,遵循先进先出(First-In-First-Out,FIFO)的原则。简单来说,最先进入队列的元素将会最先被移除,而最后进入队列的元素将会最后被移除。
queue容器的主要特点包括:
-
先进先出原则:队列是按照元素的进入顺序进行处理的。新元素被添加到队列的尾部,而从队列中移除元素是从队列的头部进行的。
-
有限大小:通常情况下,queue容器的大小是有限的。当队列已满时,试图向队列中添加新元素将会失败,或者在特定的实现中可能会覆盖旧元素。
常见操作:queue容器通常支持以下基本操作:
- 入队(enqueue):向队列尾部添加一个新元素。
- 出队(dequeue):从队列头部移除一个元素。
- 队头元素(front):获取队列头部的元素,但不会移除它。
- 队尾元素(back):获取队列尾部的元素,但不会移除它。
底层实现:queue容器的底层实现可以使用不同的数据结构,例如链表或数组。具体的实现可能会影响操作的时间复杂度。
queue容器在很多情况下都很有用,特别是在需要按照先后顺序处理数据的场景,比如任务调度、广度优先搜索等。
queue容器有两个口,允许从一端新增元素,从另一端移除元素。
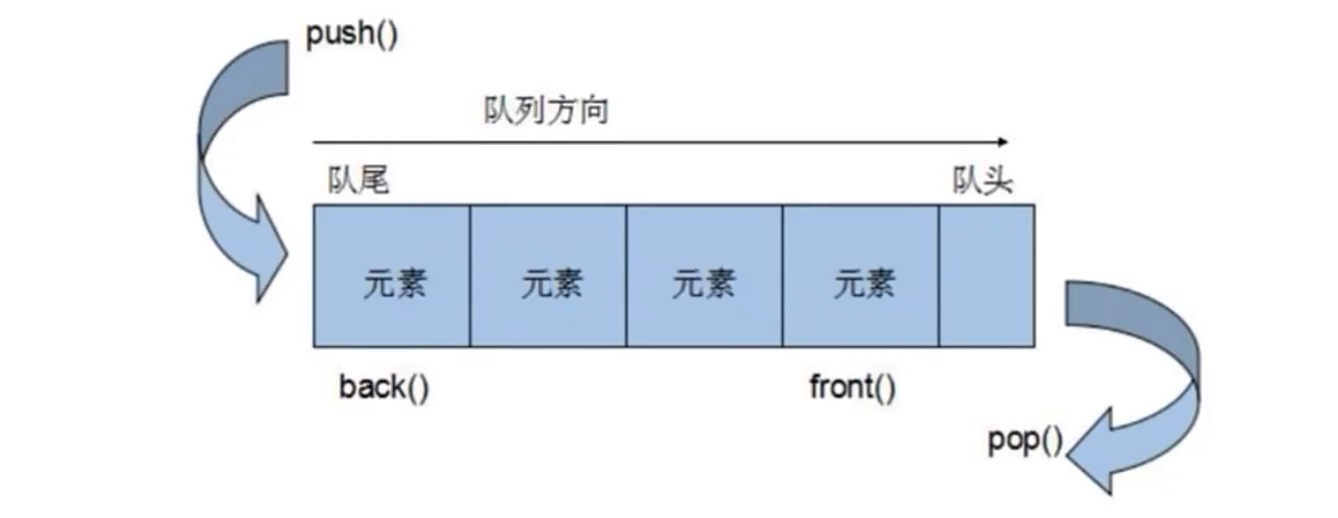
queue所有元素的进出都必须符合"先进先出"的条件,只有queue的顶端元素,才有机会被外界取用。queue不提供遍历功能,也不提供迭代器。
二、queue容器的底层实现原理
queue容器是一种先进先出(FIFO)的数据结构,其底层实现原理基于队列模型。队列模型类似于现实生活中排队的情景,最先进入队列的元素将首先被处理,而最后进入队列的元素将在队尾等待。
常见的queue实现方式包括数组、链表和环形缓冲区,每种实现方式都有其优劣势:
数组实现:
- 原理:使用数组作为底层数据结构,通过指针或索引来跟踪队头和队尾元素。
- 优势:随机访问的时间复杂度为O(1),因此可以快速访问队头和队尾元素。内存连续分配,利于CPU缓存命中,性能相对较好。
- 劣势:插入和删除元素时,可能需要移动其他元素以保持连续性,导致时间复杂度为O(n)。当队列元素数量较大时,频繁的内存搬移可能会影响性能。
链表实现:
- 原理:使用链表作为底层数据结构,通过指针来连接节点,并使用指针跟踪队头和队尾元素。
- 优势:插入和删除元素时,只需调整指针指向,时间复杂度为O(1)。不会有数组的内存搬移问题。
- 劣势:随机访问的时间复杂度为O(n),需要从头节点开始遍历到指定位置,效率较低。每个节点都需要额外的指针存储空间,可能会占用更多内存。
环形缓冲区实现:
- 原理:使用固定大小的循环数组作为底层数据结构,利用取模运算实现环形特性。
- 优势:没有链表的指针开销,可以更高效地使用内存。插入和删除元素的时间复杂度为O(1)。
- 劣势:由于固定大小,当队列满时,需要进行额外的处理,如扩展队列大小。
三、queue容器常用API
使用<queue>头文件,C++中的队列容器通常使用std::queue模板类来表示。
(1)push():向队列尾部添加一个元素。
#include <iostream>
#include <queue>
int main() {
std::queue<int> myQueue;
myQueue.push(10);
myQueue.push(20);
return 0;
}
(2)pop():从队列头部移除一个元素。
#include <iostream>
#include <queue>
int main() {
std::queue<int> myQueue;
myQueue.push(10);
myQueue.push(20);
myQueue.pop(); // Removes the element 10 from the front
return 0;
}
(3)front():访问队列头部元素的值(但不删除它)。
#include <iostream>
#include <queue>
int main() {
std::queue<int> myQueue;
myQueue.push(10);
myQueue.push(20);
int frontElement = myQueue.front(); // frontElement will be 10
return 0;
}
(4)back():访问队列尾部元素的值(但不删除它)。
#include <iostream>
#include <queue>
int main() {
std::queue<int> myQueue;
myQueue.push(10);
myQueue.push(20);
int backElement = myQueue.back(); // backElement will be 20
return 0;
}
(5)size():获取队列中元素的数量。
#include <iostream>
#include <queue>
int main() {
std::queue<int> myQueue;
myQueue.push(10);
myQueue.push(20);
size_t queueSize = myQueue.size(); // queueSize will be 2
return 0;
}
(6)empty():检查队列是否为空。
#include <iostream>
#include <queue>
int main() {
std::queue<int> myQueue;
if (myQueue.empty()) {
std::cout << "Queue is empty." << std::endl;
} else {
std::cout << "Queue is not empty." << std::endl;
}
return 0;
}
四、queue的使用案例
4.1、使用queue容器实现一个高效的算法
使用queue容器可以实现许多高效的算法,例如广度优先搜索(BFS)算法和任务调度等。
#include <iostream>
#include <queue>
#include <vector>
using namespace std;
void bfs(vector<vector<int>>& graph, int start) {
int n = graph.size();
vector<bool> visited(n, false);
queue<int> q;
q.push(start);
visited[start] = true;
while (!q.empty()) {
int node = q.front();
q.pop();
cout << "Visited: " << node << endl;
for (int neighbor : graph[node]) {
if (!visited[neighbor]) {
q.push(neighbor);
visited[neighbor] = true;
}
}
}
}
int main() {
// 以邻接表形式表示图
vector<vector<int>> graph = {
{1, 2},
{0, 2, 3},
{0, 1, 3},
{1, 2}
};
bfs(graph, 0); // 从节点0开始进行BFS
return 0;
}
使用queue容器实现了基于邻接表的BFS算法。该算法通过队列的先进先出特性,在遍历节点时按照广度优先的顺序遍历其邻居节点。
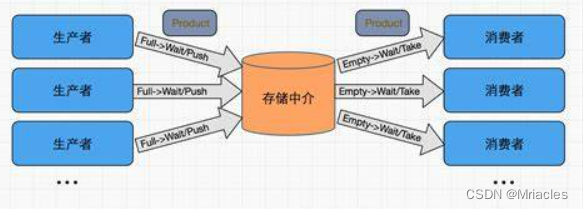
4.2、实现生产者-消费者模型
生产者-消费者模型是一种常见的并发编程模式,其中有一个或多个生产者将数据放入共享的缓冲区(队列),而一个或多个消费者从队列中获取数据并进行处理。这种模型可以很好地解决生产者和消费者之间的数据传递和协调问题。
在这个模型中,queue容器可以被用来实现共享的缓冲区。生产者将数据放入队尾,而消费者从队首获取数据。queue的FIFO特性非常适合这种场景,确保了数据按照插入顺序进行处理。
使用queue容器来实现生产者-消费者模型:
#include <iostream>
#include <queue>
#include <thread>
#include <mutex>
#include <condition_variable>
const int MAX_QUEUE_SIZE = 5; // 缓冲区的最大容量
std::queue<int> dataQueue;
std::mutex mtx;
std::condition_variable cv;
void producer() {
for (int i = 1; i <= 10; ++i) {
std::unique_lock<std::mutex> lock(mtx);
cv.wait(lock, [] { return dataQueue.size() < MAX_QUEUE_SIZE; }); // 等待缓冲区不满
dataQueue.push(i);
std::cout << "Producer produced: " << i << std::endl;
lock.unlock();
cv.notify_all(); // 通知消费者可以消费数据了
}
}
void consumer() {
for (int i = 1; i <= 10; ++i) {
std::unique_lock<std::mutex> lock(mtx);
cv.wait(lock, [] { return !dataQueue.empty(); }); // 等待缓冲区不空
int data = dataQueue.front();
dataQueue.pop();
std::cout << "Consumer consumed: " << data << std::endl;
lock.unlock();
cv.notify_all(); // 通知生产者可以继续生产数据
}
}
int main() {
std::thread producerThread(producer);
std::thread consumerThread(consumer);
producerThread.join();
consumerThread.join();
return 0;
}
有一个最大容量为5的缓冲区,生产者和消费者都会执行10次生产和消费操作。当缓冲区满时,生产者会等待,直到消费者取走数据,从而腾出空间。同样地,当缓冲区为空时,消费者会等待,直到生产者放入新的数据。
通过queue容器和互斥锁(std::mutex)以及条件变量(std::condition_variable)的结合使用,我实现了一个简单的线程安全的生产者-消费者模型。这样可以确保生产者和消费者之间的操作不会发生竞态条件(race condition),从而实现了数据的安全传递和处理。
总结
头文件包含: 要使用queue容器,需要包含<queue>头文件。
声明: 在C++中声明一个queue容器可以使用如下语法:
std::queue<数据类型> queue_name;
这里的数据类型可以是任何C++支持的数据类型,例如int、double、char等。
插入元素: 使用push()成员函数将元素添加到队列的末尾。例如:
std::queue<int> myQueue;
myQueue.push(10);
myQueue.push(20);
myQueue.push(30);
此时,myQueue中的元素为10, 20, 30。
访问队首元素: 使用front()成员函数可以访问队列的第一个元素(队首元素),但不会将其从队列中移除。例如:
int firstElement = myQueue.front();
在上面的示例中,firstElement将获得值10。
移除队首元素: 使用pop()成员函数可以将队列的第一个元素(队首元素)移除。例如:
myQueue.pop();
现在,myQueue中的元素为20, 30。
判断队列是否为空: 使用empty()成员函数可以检查队列是否为空,如果为空则返回true,否则返回false。例如:
if (myQueue.empty()) {
// 队列为空
} else {
// 队列不为空
}
获取队列中元素的个数: 使用size()成员函数可以获取队列中元素的个数。例如:
int queueSize = myQueue.size();
在上面的示例中,queueSize将获得值2。
特性:
queue容器是一个FIFO(First-In-First-Out)数据结构,即先进先出。队首元素是最先被插入的元素,队尾元素是最后被插入的元素。
queue不允许直接访问中间或随机位置的元素。只能访问队首和队尾元素,并且只能从队首删除元素。