文章目录
- 前言
- urllib介绍
- urllib发送请求
- urllib编码与解码
- urllib异常处理
- urllib使用IP代理
- urllib使用cookie
前言
快期末了,有个数据挖掘的大作业需要用到python的相关知识(这太难为我这个以前主学C++的人了,不过没办法还是得学😂),下面是我在学习爬虫相关知识时总结的一些东西,我对于python不是很熟悉,如果下面的一些知识点有哪里出问题或者有不同理解的,请一定一定要在评论区提出来,让我这个菜鸡学习学习~~/(ㄒoㄒ)/~~

urllib介绍
-
urllib是Python自带的标准库中用于网络请求的库,无需安装,直接引用即可
-
通常用于爬虫开发、API(应用程序编程接口)数据获取和测试
-
urllib库的4大模块
urllib.request :用于打开和读取URL urllib.error:包含提出的例外(异常)urllib.request urllib.parse:用于解析URL urllib.robotparser:用于解析robots.txt文件
urllib发送请求
- urllib.request厍
①模拟浏览器发起一个HTTP请求,并获取请求响应结果 - urllib.request.urlopen的语法格式
①urlopen(url,data=None,[timeout,], cafile=None, capath=None,cadefault=False, context=None) - 参数说明
①url: url参数是str类型的地址,也就是要访问的URL,例如:https:7/www.baidu.com
②data:默认值为None,urllib判断参数data是否为None从而区分请求方式。或参数data为None,则代表请求方式为Get,反之请求方式为Post,发送Post请求。
参数data以字典的形式存储数据,并将参数data由字典类型转换成字节类型才能完成Post请求 - urlopen函数返回的结果是一个http.client.HTTPResponse对象
1、发送Get请求示例
向http://www.biqugebook.la/发送请求
import urllib.request
url = "http://www.biqugebook.la/"
# 发送请求(GET请求)
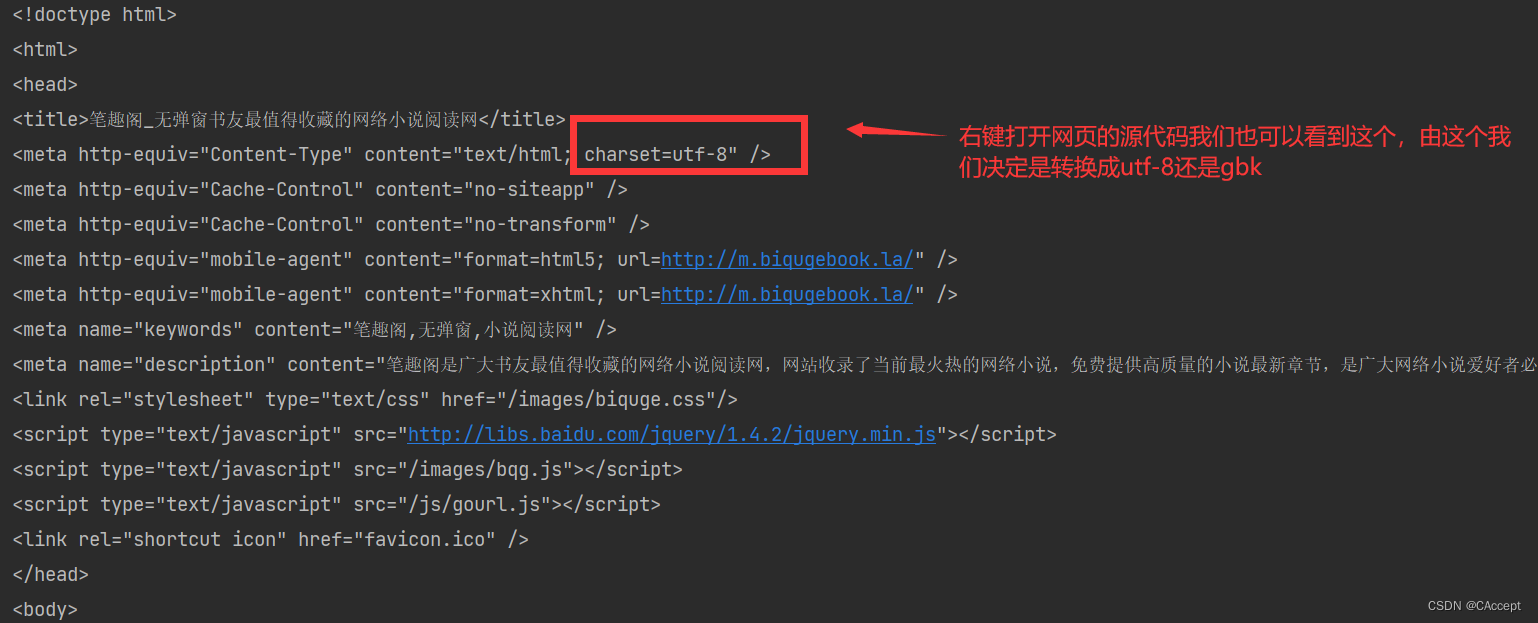
resp = urllib.request.urlopen(url)
# 通过查看网页的源代码选择是转换成gbk还是utf-8
html = resp.read().decode('utf-8')# 将bytes转成utf-8
print(html)
运行结果:
2、urllib请求中添加头部示例
为什么要这添加头部呢,那是因为有些网站有一些简单的反爬虫机制,所以在一些情况下我们在urllib的请求中添加一个头部就可以模拟是浏览器对网站进行访问,而不是爬虫,看示例👇
不加头部的情况
import urllib.request
url = "https://movie.douban.com/"
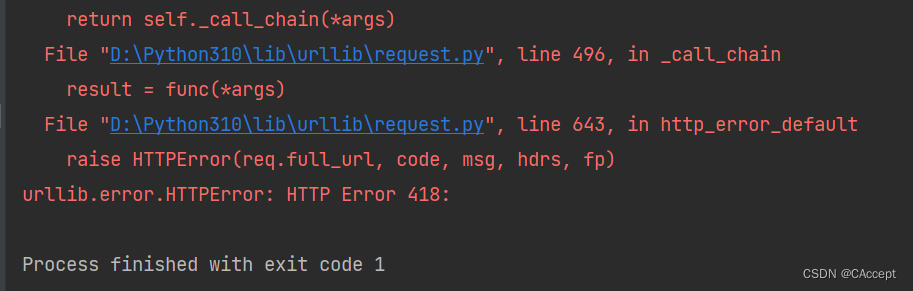
resp = urllib.request.urlopen(url)
# 从响应结果中读取数据
html = resp.read().decode("utf-8")
print(html)
运行结果:
加了头部的情况
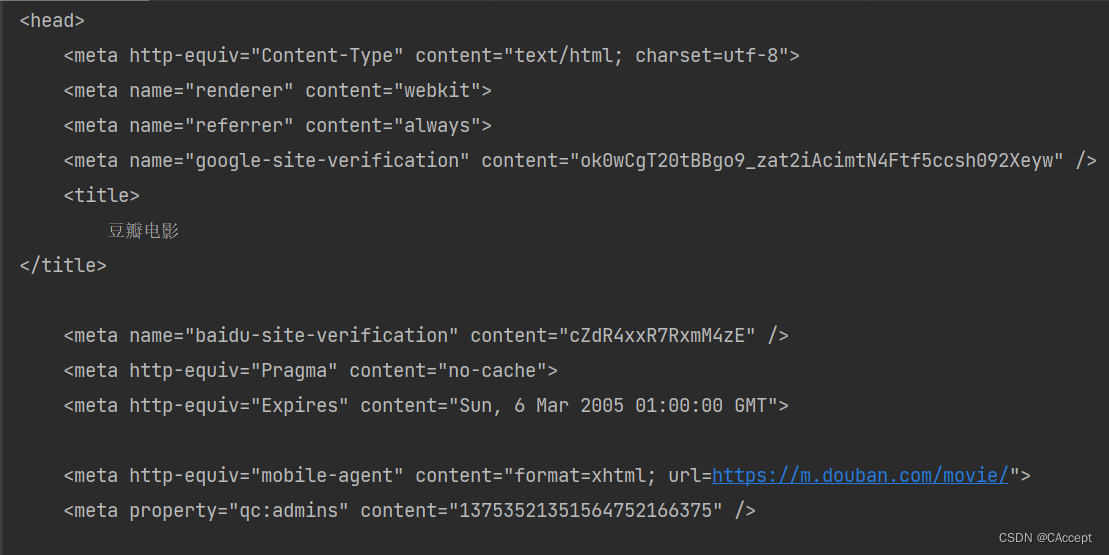
import urllib.request
url = "https://movie.douban.com/"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36'}
req = urllib.request.Request(url,headers=headers)
resp = urllib.request.urlopen(req)
# 从响应结果中读取数据
html = resp.read().decode("utf-8")
print(html)
urllib编码与解码
这个用在哪里呢,看这里👇

以上的操作都是由urllib的编码解码来实现的,当我们在搜索引擎中输入中文"码农",它会将中文编码成特定的一串字符代表"码农"
1、urllib编码解码示例
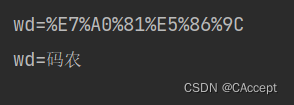
import urllib.parse
kw = {"wd":"码农"}
# 编码
result = urllib.parse.urlencode(kw)
print(result)
# 解码
res = urllib.parse.unquote(result)
print(res)
运行结果:
urllib异常处理
就和C++的异常处理的机制相似,当我们对网站发送一些请求或一些其他操作时,如果出现错误,那么就会抛出异常。
1、urllib异常处理示例
import urllib.request
import urllib.error
url = "http://www.google.com"
# 下面这才是正确的网站地址,如果url为上面那个则发送错误
# url = "http://www.google.cn"
try:
resp = urllib.request.urlopen(url)
# 接收异常
except urllib.error.URLError as e:
print(e)
运行结果:

urllib使用IP代理
这也是一种对抗反爬虫的方法,因为有些网站会检测一个IP是否在一段时间一直对网站进行访问,如果我们使用一些高匿的IP代理就可以解决这个问题
免费IP代理网站分享

from urllib.request import build_opener
from urllib.request import ProxyHandler
# 创建代理(服务器那边接收到的IP就是代理的IP,这也是为了避免反爬虫)
# 键是表示类型,值则是IP地址和端口号
proxy = ProxyHandler({"HTTP":"47.101.44.122:80"})
opener = build_opener(proxy)
url = "https://www.baidu.com"
resp = opener.open(url)
print(resp.read().decode("utf-8"))
urllib使用cookie
1、为什么需要cookie:解决http的无状态性,为了让服务器知道我们这次的请求和上次请求的关联
2、使用步骤
①实例化MozillaCookieJar(保存cookie)
②创建handle对象(cookie的处理器)
③创建opener对象
④打开网页(发送请求获取响应)
⑤保存cookie文件
1、获取cookie
import urllib.request
from http import cookiejar
filename = "cookie.txt"
# 获取cookie
def get_cookie():
# (1)实例化一个MozillaCookieJar(用于保存cookie)
cookie = cookiejar.MozillaCookieJar(filename)
# (2)创建handler对象
handler = urllib.request.HTTPCookieProcessor(cookie)
# (3)创建opener对象
opener = urllib.request.build_opener(handler)
# (4)请求网站
url = "https://tieba.baidu.com/index.html?traceid=#"
# (5)存储cookie文件
cookie.save()
运行结果:(生成一个cookie.file文件)

2、加载cookie
def use_cookie():
# 实例化MozillaCookieJar
cookie = cookiejar.MozillaCookieJar()
# 加载cookie文件
cookie.load(filename)
print(cookie)
运行结果:




![[附源码]计算机毕业设计基于SpringBt的演唱会购票系统论文2022Springboot程序](https://img-blog.csdnimg.cn/8a5ef33fbddb477ebbea397c9fa327c9.png)

![[附源码]Python计算机毕业设计SSM基于框架的旅游订票系统(程序+LW)](https://img-blog.csdnimg.cn/4bd710d325f3419282fffdd21cdfb466.png)